Your curated collection of saved posts and media
We parsed this SpaceX equity research PDF faster than the time it took for Screen Studio to zoom in ⚡️🔥 liteparse is now the best open-source document parsing tool out there. There’s no reason to not use it as a first pass, even if you do have docs that require heavier VLM processing downstream. Try it out now over any document: https://t.co/ErgwlItZ96 Repo: https://t.co/JNER0mVcB8
We built the fastest PDF -> markdown parser in the world 🚀⚡️ AND it’s more accurate than any other open-source, model-free parser (pymupdf4llm, opendataloader, pdf-inspector, markitdown) on 3 standardized benchmarks: olmOCR0-bench, opendataloader-bench, ParseBench Introducing L

@mizugeek https://t.co/25mC2H0g2X
Wait am clarifying with gdm if this is actually allowed lmao

@BlockedPaths https://t.co/25mC2H0g2X
Wait am clarifying with gdm if this is actually allowed lmao

@siraustin https://t.co/25mC2H0g2X
Wait am clarifying with gdm if this is actually allowed lmao

🎙🎙🎙🎙🎙🎙🎙🎙 https://t.co/70AMUO8X15
🎙🎙🎙🎙🎙🎙🎙🎙 https://t.co/70AMUO8X15
Materialism kinda slaps https://t.co/dcF8mL2VJn

AI is changing how we build software. Curiosity still matters. @clattner_llvm, CEO and Co-founder of @Modular, shares his perspective on entering the industry today. https://t.co/g8MbvvgyLF
Donald Trump will go down in history as the only US President to be outwitted by a single-celled organism. https://t.co/mjPd1IVvLO

Anthony Fauci is an American hero who kept us protected from deadly viruses for decades. The people spreading lies about him are spreading Russian propaganda because they get paid to do so. They are the real traitors. Russia would love to know what we have in our biolabs so they can use that research to hurt Ukraine who is dominating them with drones.

It’s a very simple concept, really. https://t.co/knKOCR4bMG
We just need to celebrate having kids. Happy Father's Day. https://t.co/qZRTzXJWjw

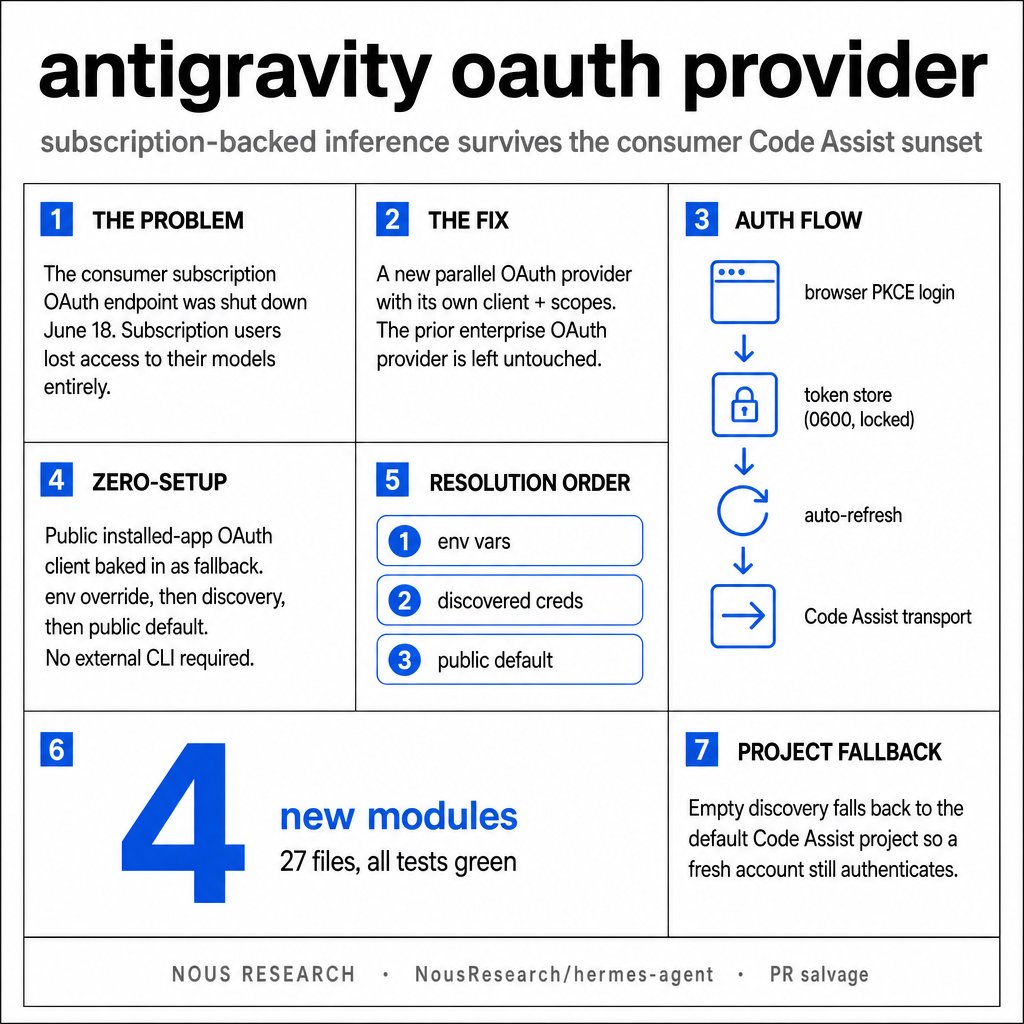
AntiGravity users should be able to access their sub's models now in Hermes :) https://t.co/9UdXGPhzOw
Step 1: Remove filters in Reflecting Pool because Obama put them in. Step 2: Give your criminal neighbor who runs "Greenwater Services" a $20 million no-bid contract to paint the pool. Step 3: Fill the pool with water from the Potomac River, the phosphates from which cause algae blooms. Step 4: Freshly sealed pool and extreme heat result in a super scum event Step 5: Direct National Park Service to dump hydrogen peroxide into the pool which causes the paint to peel. Step 5: Deploy US National Guard to stop people from taking photos of the swamp as a perfect metaphor for the administration. Step 6: Blame someone else.

excited to see more chatgpt codex billboards from @OpenAI https://t.co/QqTM9WFbM0

Absolutely insane revelations about Tulsi Gabbard. Throughout her public life, she's been a puppet for a Hindu cult. Washington Post got access to 25,000 pages of documents including directives from Tulsi Gabbard's cult leader telling her which policy positions to take and how to present herself throughout her career. It matches her record in Congress. At one point, she was instructed to say "It’s not a ‘boohoo, I don’t get to go to the party’ situation, Wolf" during a CNN interview, and used that exact phrase. This is one of several examples of her taking direct orders about what to say on TV. They told her what to tweet about too. The cult set up fake accounts to boost her on social media. Gabbard was aware, at one point telling them to add a photo to a profile. An email records a phone call where she was yelled at, but Tulsi is reminded at the end that "we still love you." This woman was always a freak, which is why she ended up in the MAGA coalition. Anti-vaxxers, criminals, racist, and a woman in a weird cult all end up as allies. Trumpism is Kakistocracy.


🚨 WTF?! Anthropic CEO Dario Amodei completely abandons his anti-war stance. He openly justifies signing massive classified contracts with the Pentagon to power the US war machine. Washington is intentionally weaponizing AI to escalate global conflicts. Total hypocrisy! https://t.co/7Lx1eBUP1A
🚨 WTF?! Anthropic CEO Dario Amodei casually admits his own company is actively replacing human software engineers with AI. He confirms AI now writes almost all the code, making human workers completely obsolete. The tech elite are intentionally destroying the working class! ht
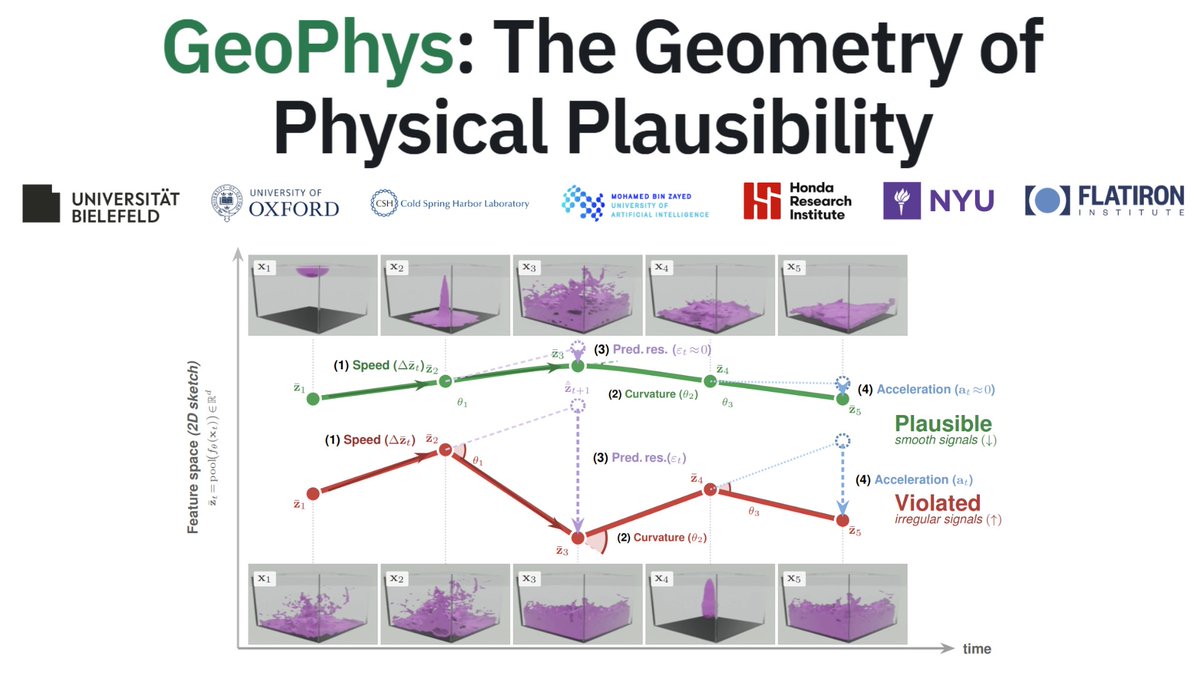
Signals of physical plausibility are hiding in the geometry of frozen image encoders. No video training. No physics supervision. https://t.co/NKmgD8g53f
@karatademada Read all of the AI community here on X and write me a report: https://t.co/kiuZ7QXLzb

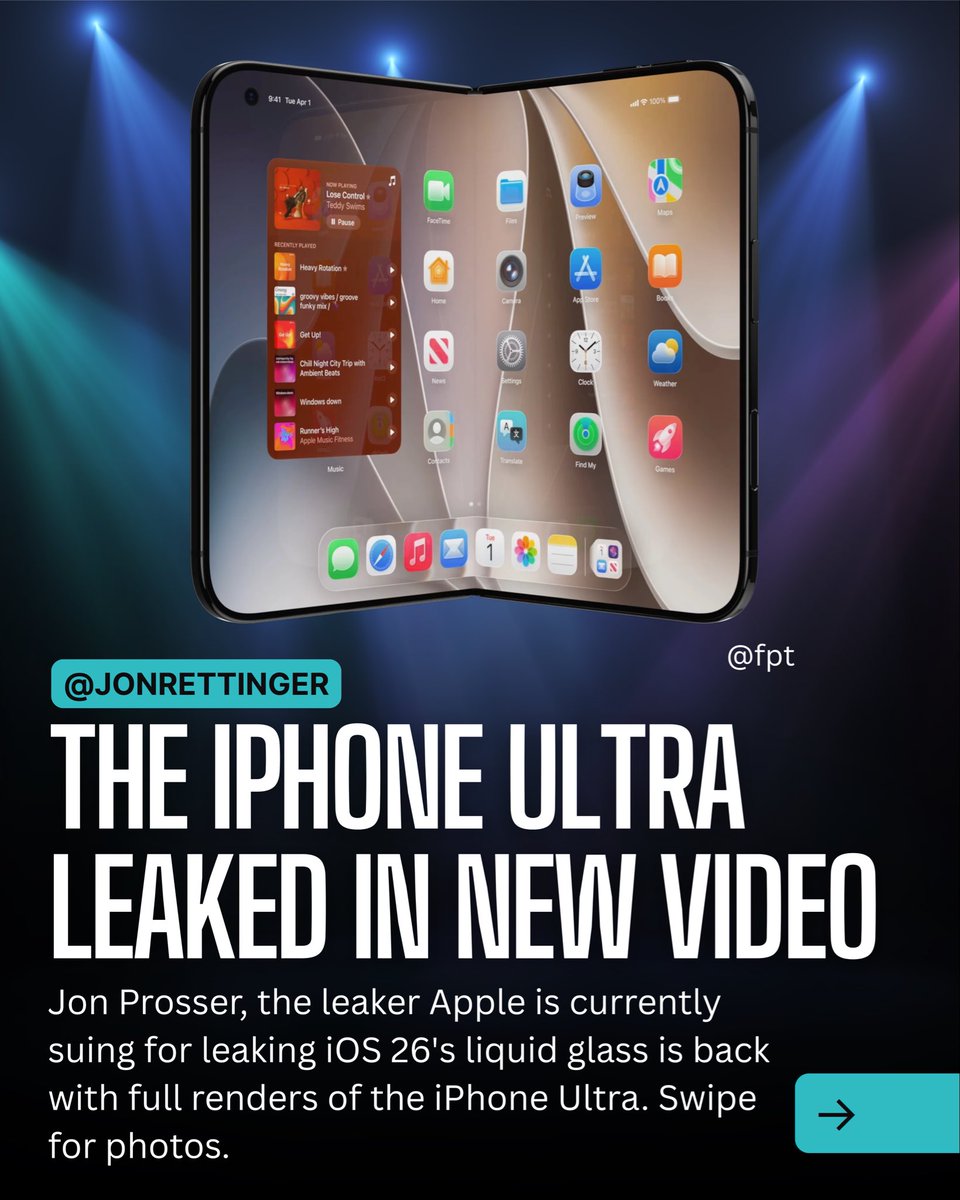
The iPhone Ultra leaked? Jon Prosser just shared full renders of the new design on YouTube. His leaks are usually spot on, making this our best preview yet ahead of the September launch. It also seems like the Ultra will allegedly come in black and white! What do you gus think about the design of the iPhone Ultra? #appleleaks #iphoneultra #ios27 #technews #foldableiphone

🚨 GPT-5.6 is already leaking while ChatGPT loses market share: ChatGPT also just dropped below 50% market share for the first time. · Testers report GPT-5.6 feels noticeably faster and more capable than GPT-5.5 · Expected improvements include 1.5 million token context window, better agents ability when used for hours, and stronger coding · OpenAI has been shipping major models every 6 weeks, an extremely expensive pace to keep up If revenue growth slows, maintaining this release speed could become much harder. Do you think this is where OpenAI fall behind other competitors?

It’s working on it mwo https://t.co/SzzN0wwuUI
“Rest in Peace, VLAs”, NVIDIA’s robotics lead @DrJimFan said, at the Sequoia’s AI Ascent 2026 conference. So, what’s next? Here’s Jim Fan’s core argument: VLA (Vision Language Action Model) architectures are fundamentally brittle; they merely bolted robotic actions onto LLMs. Instead, the industry is converging on physics-grounded World Models. When it comes to robotics data, sample efficiency and data architecture are replacing brute-force token volume. Look at how the unit economics of data collection just shifted through two recent breakthroughs: - @1x_tech trained its NEO humanoid world model to execute out-of-distribution tasks using just 900 hours of egocentric human video and a mere 70 hours of real robot data (Jan 2026) - @nvidia shipped Cosmos 3, demonstrating that with a strong world foundation model, just 100 teleop seed samples are enough to post-train a complete, action-conditioned forward dynamics pipeline. (Jun 2026) By utilizing world models, robots learn not by memorizing millions of environments, but through an implicit, internalized understanding of physics. Pre-trained world models are now sophisticated enough to execute zero-shot tasks out-of-the-box. They then try them in the wild, and instantly convert those real-world interactions into clean, autonomous training tokens. Instead of racing to collect the most data, the winning recipe is now sample efficiency. And beneath that sits the model architecture that turns the fewest training examples into the most action.

Happy Fathers Day. Remember, we’re all just passing through. All your stuff will be gone, sold or given away. Your children are your heritage. Be a father they can be proud of. 🇺🇸 https://t.co/ozVYd3EyRe

I’ve joined @OpenAI as a Research Program Manager, working on evals. I’m incredibly grateful for my time at @scale_AI. I worked on Humanity’s Last Exam, helped launch @ScaleAILabs, collaborated with amazing people across data/evals/research, and recorded a few episodes of Chain of Thought. More than anything, I’m grateful for the people. Scale was intense, chaotic, ambitious, and deeply formative. I learned a lot about building under pressure, caring about quality, and taking evals seriously. Excited for the next chapter.
@mattjay I know a guy in San Francisco running a security company (I met it at @theresidency ) and he has done worse with it already. Hacked a good chunk of YCombinator's latest batch. Helped them fix their bugs. He did the same for the systems I'm using to build https://t.co/kiuZ7QXLzb

Another example from today: https://t.co/1D3ceEm3jX
I'm joining OpenAI next week!🥹 The job search turned out to be really challenging but also super rewarding, so I wrote a small blog to share what I learned along the way and hopefully make the process a little less mysterious for the next person. https://t.co/6FigSBdenD

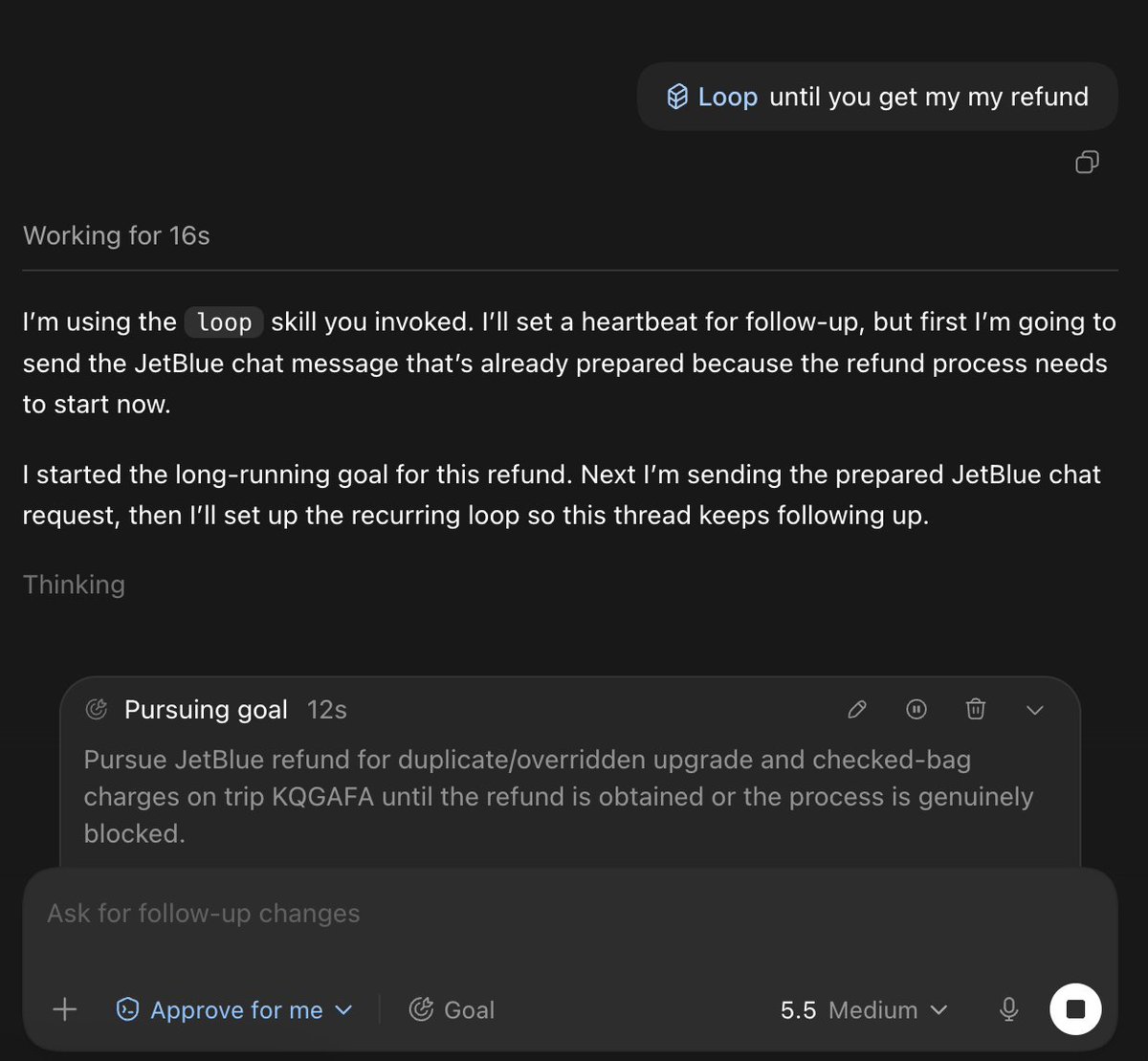
codex about to get me 500$ back https://t.co/tZGXBYiMTM
Lego is boring. Enter BYLT - real construction using real practices. From architect drawn blueprints to finished product... on a tiny scale. Get your kit or order a la carte from the supply yard 👇 https://t.co/4H1SwkmuvZ
How I'm learning Hermes Agent. Stage 1. It began with a decision: two agents, one server. OpenClaw and @HermesAgent by @NousResearch. Different architectures, different temperaments — like a cat and a dog, except in Docker. I'm not a programmer. Just curious. OpenClaw moved in first. We worked through a strange assembly line: I'd write to ChatGPT, it would give me a task, I'd copy it into Codex — a desktop app that prepared the command. Then the command flew to the VPS terminal. Enter. Logs back to ChatGPT for review. And again. Copy. Paste. Wait. Verify. Repeat. Twenty, thirty, forty times an evening. Fingers learn Ctrl+C faster than the brain learns what exactly is being copied. Then I discovered Grok Build CLI. Installed it right on the server — and the chain got shorter. No longer "ChatGPT → Codex → me → terminal → me → ChatGPT", but almost a direct flow. Almost. ChatGPT still mixed up commands. The chat would fill up, context would tear, hallucinations would creep in. I'd open a new chat, load a context document from GitHub, carry on. It worked. Imperfectly. But it worked. And then, in the middle of this assembly line — Hermes Agent. Another command from ChatGPT. Copy. Codex. Terminal. Enter. Hermes came alive. On the same server where OpenClaw was already running, a second agent had just opened its eyes. Silent. No greeting. Just booted up and waited. @Teknium and the team built an agent that doesn't ask for a CS degree. Sometimes all it takes is a server, a couple of evenings, and a willingness to copy-paste. To be continued. #HermesAgent #NousResearch #OpenClaw #AIAgent #OpenSource #NoCode #ChatGPT #CodexCLI #GrokBuild

Working in some realtime keystone project with chappie today. https://t.co/ITmeQ7lPef