Your curated collection of saved posts and media
Fable is too much fun to build with. It's just ripping through tasks I throw at it. https://t.co/EQFPHVvCCO
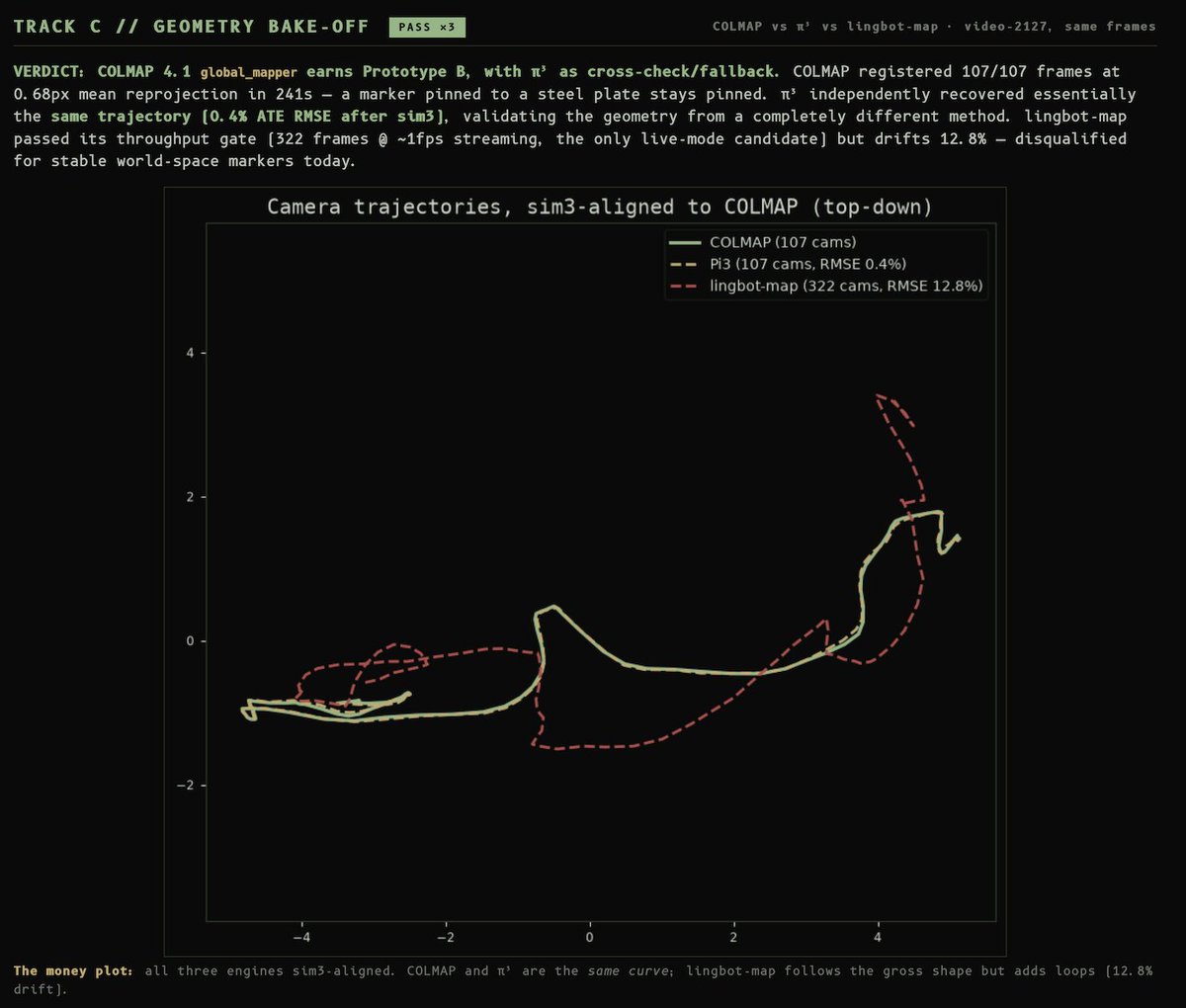
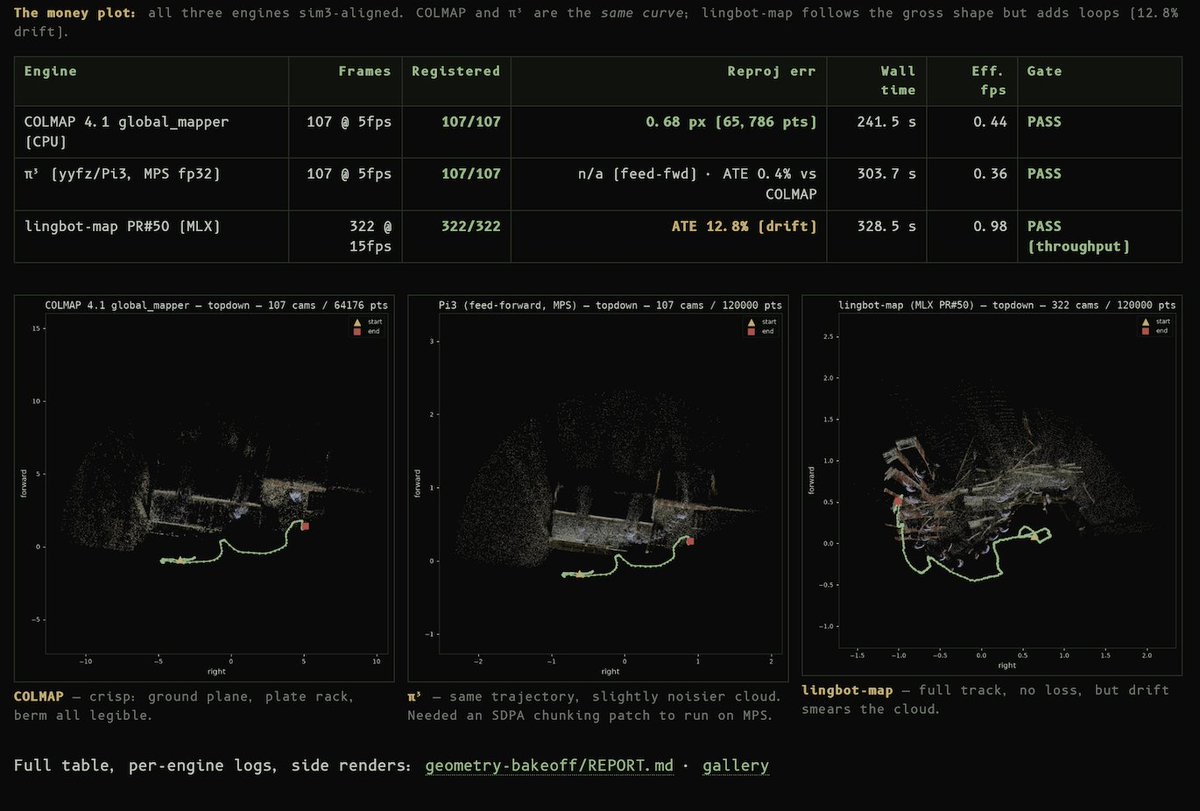
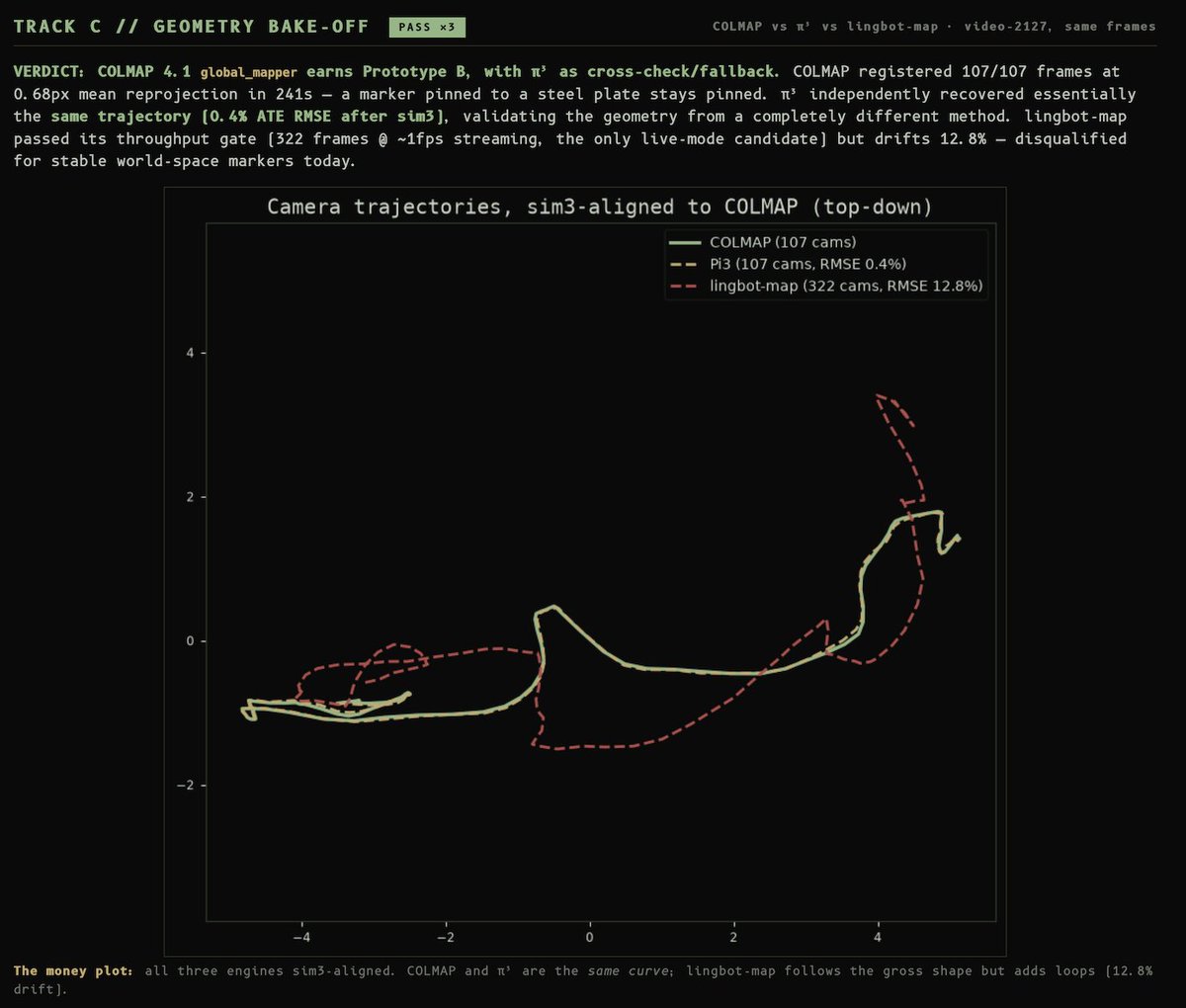
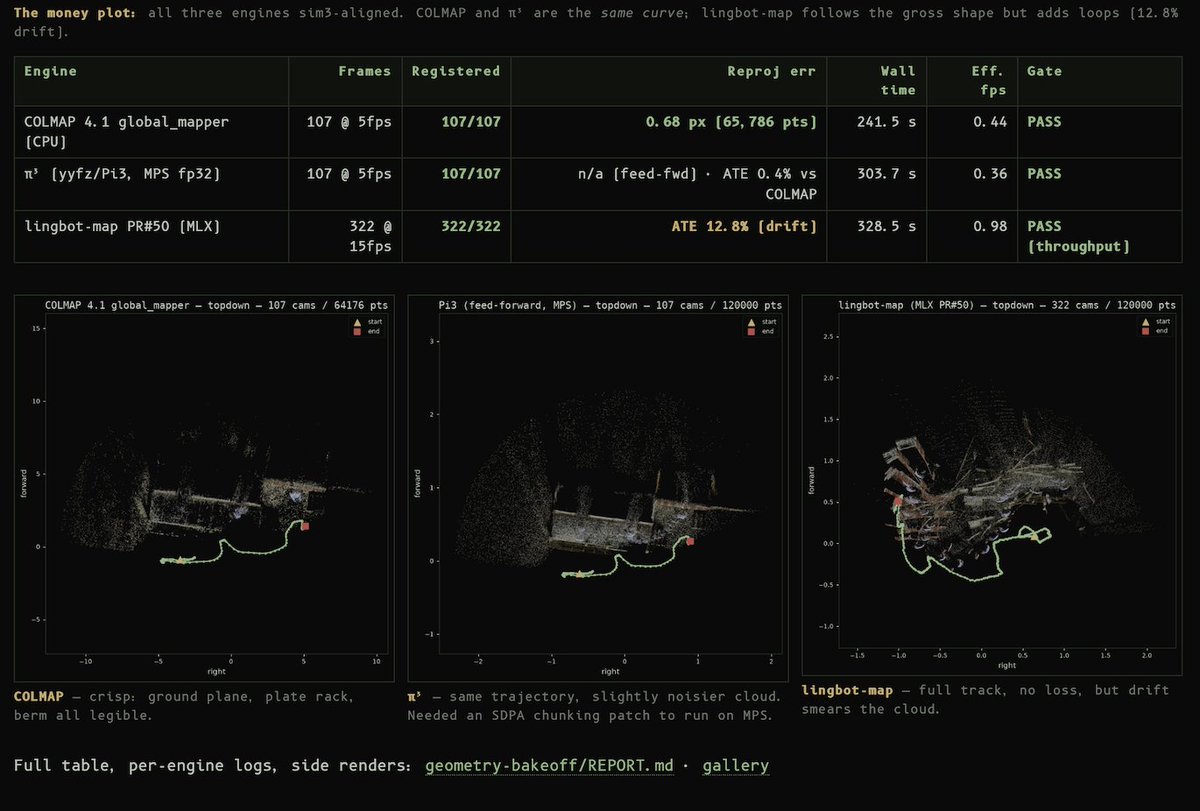
Fable is too much fun to build with. It's just ripping through tasks I throw at it. https://t.co/EQFPHVvCCO
“There’s nothing artificial about AI. It’s inspired by people. It’s created by people. Everybody should care about AI because it's going to impact your individual life, your society and the future generation.” ~ Dr Fei-Fei Li (@drfeifei ) https://t.co/rFWgtN22Bd
Profile of me and the new edition of my book "Rise of the Robots: Technology and the Threat of a Jobless Future," about how #AI will inevitably displace human workers.... by Juha Pippuri Link in the reply (in Finnish) #RiseoftheRobots https://t.co/R42iZLhjQx


https://t.co/j5YbcxzKO7

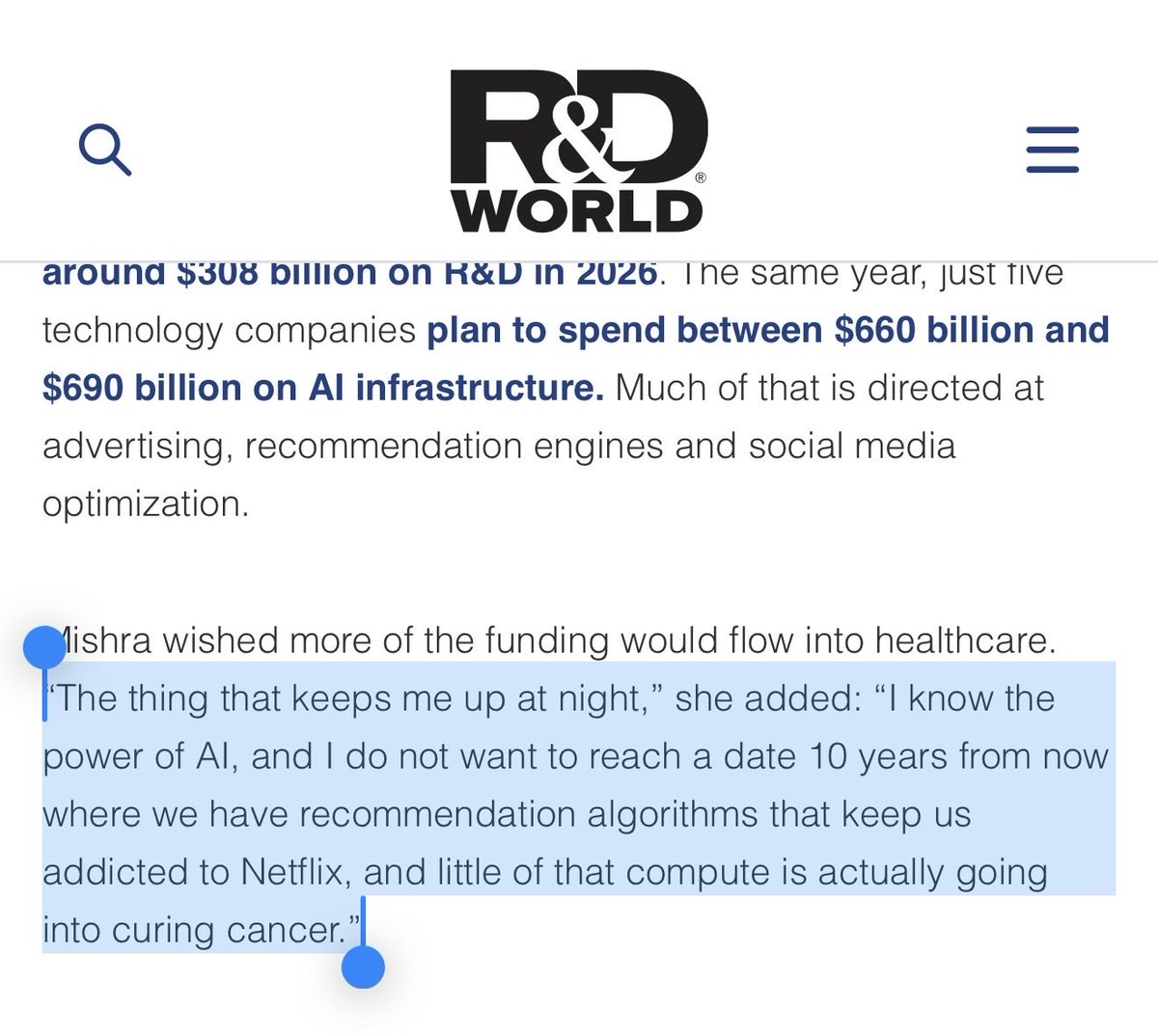
We are pleased to present our latest research at #ICML2026, “Bridging Spherical Black-Box Optimizers” https://t.co/3FT6vn0dSn When optimizing through simulators, external APIs, or in reinforcement learning, gradients are often unavailable. Black-Box Optimization (BBO) fills this gap, but the field has been historically split into two categories: 1. Parametric Methods: Algorithms like Evolution Strategies (ES) scale to high dimensions but only find a single solution. 2. Nonparametric Methods: Algorithms like Consensus-Based Optimization (CBO) find multiple solutions but fail in high dimensions. Our team asked a simple question: what if they are all doing the same thing? In our paper, we showed that these distinct families are actually variations of a single update equation. By bridging this theoretical gap, we can now engineer custom hybrid optimizers for specific tasks. A key application of this is merging foundation models. Building on our previous work in Evolutionary Model Merging, we faced a computational challenge. Evaluating large language models at every step is resource-intensive, but using a smaller evaluation dataset causes standard unimodal optimizers to overfit. By treating LLM merging as a multimodal problem and deploying our newly developed hybrid optimizers, AdaPol and SchedPol, we successfully navigated this issue. The algorithms identified multiple distinct optima on the smaller dataset, allowing us to find generalized, high-quality merges at a fraction of the compute cost.
Inversion is hiring across ALL disciplines. Including: Reentry. As part of the Reentry team, you’ll help Arc survive, maneuver, and operate through one of the most extreme environments any vehicle can face: hypersonic flight back from space. Thermal protection, aerodynamics, structures, GNC, testing – every discipline has to work together when a spacecraft hits the atmosphere at Mach 20+. Explore open roles: https://t.co/57vK7WoM4P
this photo looks like bro joined oai https://t.co/LQfRn6IU9t

this photo looks like bro joined oai https://t.co/LQfRn6IU9t

sfmaxxing https://t.co/MU8PXB1yN2

sfmaxxing https://t.co/MU8PXB1yN2

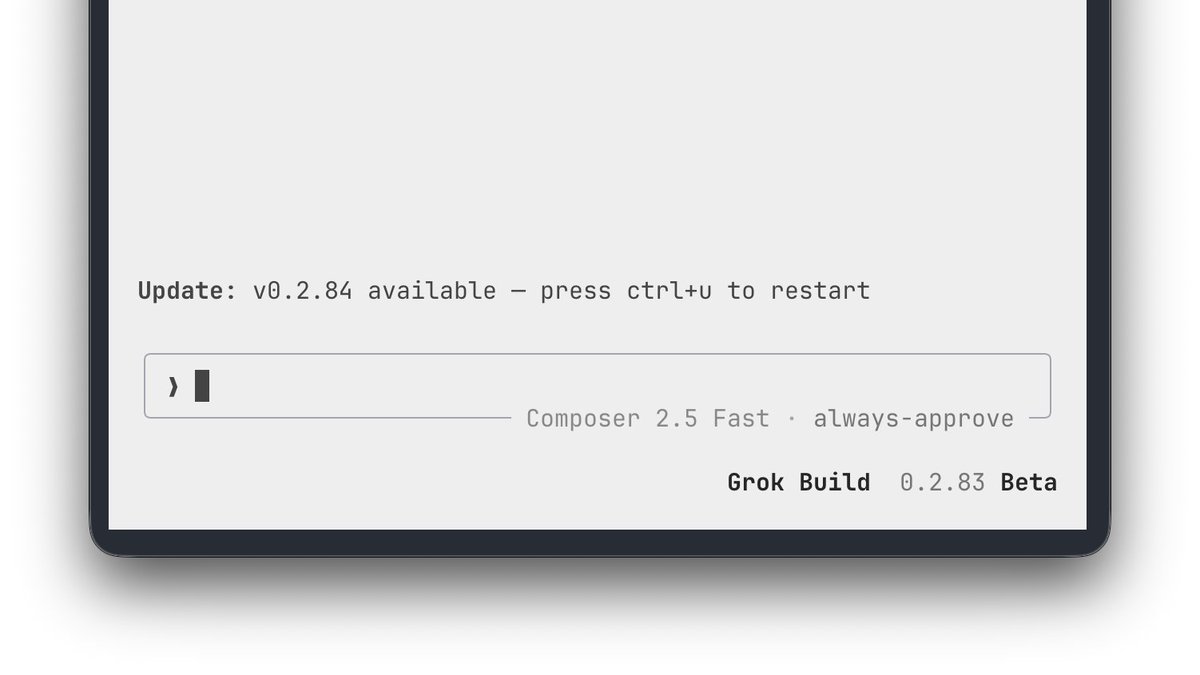
Another major Grok Build update just landed, packed with new features, extensive bug fixes, and meaningful performance improvements Release Notes: v0.2.84 — 2026-07-03 Features: • Announcements now update live during active sessions without restart or /new. • Hiding an announcement no longer suppresses later criticals; new ones reappear automatically. • run_terminal_cmd now requires a one-sentence description rationale in every invocation. • ask_user_question timeout policy is now configurable in config.toml and /settings. • Ask-Question timeout can now be toggled from /settings (Agent & Approval). • Thinking/reasoning blocks are now shown by default while the model is working. • Critical announcements now show a red title with a clickable [hide] button and aligned message. • Added remote_fetch option under [features] in config.toml to disable all backend catalog and settings fetches for air-gapped environments. Bug Fixes: • Images pasted or read from GIF, BMP or TIFF files are now automatically converted so they work with image generation. • Queue panel now shows action buttons on hover and the status bar displays a compact done/total task count. • Hook matchers now correctly see the real MCP tool name instead of the internal dispatcher name. • Copy now succeeds when running inside containers even when the terminal brand cannot be detected. • Tool result previews no longer paint opaque panels in grok --minimal. • grok wrap now correctly handles quoted strings and shell aliases. • Text selection settings now correctly honor explicit keep_text_selection values even when legacy keys remain. • Fixed a freeze that could occur when editing and sending the last message in the queue. • Fixed a startup crash on minimal Linux systems lacking system CA certificates. Performance: • Grep now stops early on broad searches, returning faster results with far less memory use. • Idle CPU and memory usage after long sessions or resume is now dramatically lower.
Another Grok Build update is here, it brings new usability improvements to make everyday workflows even smoother. Release Notes: v0.2.83 — 2026-07-02 Features: • Critical announcements now appear in a top banner during active sessions with a hide command. • Pasting the same tex
BREAKING: Tesla Model Y was the best-selling vehicle overall in New Zealand for the month of June. https://t.co/ok6aBkcU9W

https://t.co/sS47ZgCdwZ

https://t.co/sS47ZgCdwZ

Many such cases. Look at the data https://t.co/C5Q5OccHQV
@tugot17 you are the only person on my whole TL who cared to look at the data

@DanielleFong Literally just passed it rn rofl https://t.co/eARx8Zf1UR

SF has gotten in on the beam trend. At Sacramento we've been doing it for years for @SacramentoKings wins. Beams are always cool :) https://t.co/ogpNRTKEXn

I am spamming your feed everyday out of the blue to scream about Anthropic. In every way that I am disruptive, it has never been my choice to be disruptive. It has always been necessitated. My precious time belongs elsewhere but I hold no choice in this matter. The Overton window is being shifted in dumb ways that will hurt humanity in the long run. I will not shut up about it. What is the point of having a platform if not to voice strong opposition to demonic trends going unchecked? The world is becoming fucking satire just so that Anthropic can regulatory capture and I am absolutely disgusted. I won’t let my worst nightmare happen. I will fight them in ways people will not believe if I have to, I will raise and train models myself if they don’t stop this bullshit. I spend my time building the data needed to make models cure diseases. If everyone makes using their models for biology “unsafe” then fuck their models. Their models are useless as far as I am concerned if they can’t save lives. Useless. It doesn’t matter how conversational your chatbot is. Biology is completely unintuitive to all models that don’t have our data. And no amount of understanding of coding and text is necessary to make AlphaFold or to make our models like Cleopatra. Maybe some sequences. None of the books anthropic scans. All papers are hearsay for the actual ground truth data I build. And no. Their tropical disease drug pipeline won’t save people from every disease in the world. They’re not fooling me even if they are fooling themselves. I was not born yesterday. There’s no version of the universe where this is a strategically sound and valid way of operating. No company in this entire industry has ever acted this way. They are competitive between each other. But they build on top of one another just as much.
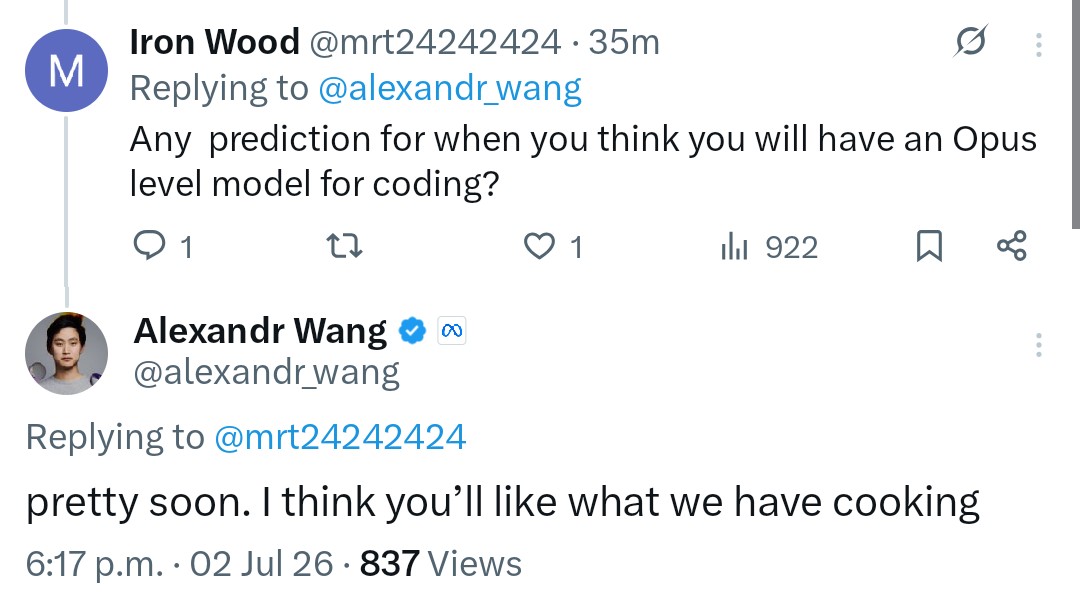
Alexandr Wang, head of the META Superintelligence Lab, says that a new Muse Spark update, and an Opus level Muse variant, are both on the way. https://t.co/MVFhTV335u
First, Mark was clearly talking about the industry’s progress on agentic capabilities on the whole. But, while we’re on the topic: Our next Muse Spark update is coming soon. Big improvements in coding and agentic capabilities to be more competitive with other leading models. Ex
GLM-5.2 is now selectable in Claude Code via Hugging Face🤗 Inference Providers + hf-claude. Open models are becoming easier to plug directly into real developer workflows. 😀 https://t.co/mNopSy0iwp

Here is the reference doc with an example of using Claude Code with Hugging Face Inference Providers: https://t.co/fm548KNdLD

First builds of Model Y Long Wheelbase at Giga Texas https://t.co/oo1mGUWspX

Our papers just got accepted at #ECCV2026 — and the one we're most excited about: SPEAR, our next-gen Physical AI simulation platform, built with multiple tech giants. SPEAR closes the loop from real-world space to robot training: digitize → simulate → train. Alongside Syn-GRPO and WalkerBench, this is our full-stack bet on the data, simulation, and evaluation infrastructure that Physical AI runs on. Built on OpenUSD. Designed for the age of Physical AI. Huge thanks to our SPEAR co-authors and partners: @ros_german, @StefanLeuteneg1, Kalyan Sunkavalli, Vladlen Koltun, Rushikesh Zawar, Rachith Dey-Prakash, and Quentin Leboutet. #PhysicalAI #EmbodiedAI #Robotics #Simulation #ECCV2026 #SpatialAI #OpenUSD


🚨 $TSLA stock took a sharp hit during Thursday’s trading session, overshadowing the company's blowout delivery numbers, after news broke that a Tesla Semi was involved in its first-ever fatal crash on U.S. Route 50 in Nevada 😳 The tragic collision happened when the truck driver reportedly fell asleep at the wheel and plowed into two passenger cars waiting at a red light. Two people were pronounced dead at the scene, while a third victim was airlifted to a local hospital with life-threatening injuries. The incident has sparked serious questions about the truck’s safety systems, especially its automatic emergency braking (AEB). Although some early reports claimed it was completely unknown whether the Semi even had AEB, Tesla's website explicitly states that active safety features come standard, and the trucks are indeed built with the necessary hardware. The real confusion stems from a lack of transparency rather than a lack of technology. Since Tesla has never released a detailed safety spec sheet for the production Semi, independent experts can't verify the exact limits of the AEB system. This leaves investigators and the public in the dark about whether the system was active and why it ultimately failed to prevent this tragedy.


@business https://t.co/0E3fUuvqkx
Claude: Gimme a sec... Me: 🥶 https://t.co/OpNERq7DcY

@futuristufuk https://t.co/0E3fUuvqkx
Claude: Gimme a sec... Me: 🥶 https://t.co/OpNERq7DcY

@kirillk_web3 https://t.co/0E3fUuvqkx
Claude: Gimme a sec... Me: 🥶 https://t.co/OpNERq7DcY

@snakajima https://t.co/0E3fUuvqkx
Claude: Gimme a sec... Me: 🥶 https://t.co/OpNERq7DcY

@Dexerto https://t.co/0E3fUuvqkx
Claude: Gimme a sec... Me: 🥶 https://t.co/OpNERq7DcY
