Your curated collection of saved posts and media
We put out a guide on how to fine-tune llama 2! Live on HN 🤙 https://t.co/HunMYHDlGI https://t.co/aVjphdPfDb

Giants in #Cloud Services in terms of market share: @Amazon @Microsoft & @Google collectively accounting for 64% of the global market share! via @Khulood_Almani @SpirosMargaris @antgrasso @Damien_CABADI @FGraillot @NeiraOsci @mikeflache @Xbond49 @UrsBolt @TheRudinGroup… https://t.co/Xd1zPUeELH https://t.co/NfPM7fdQo0
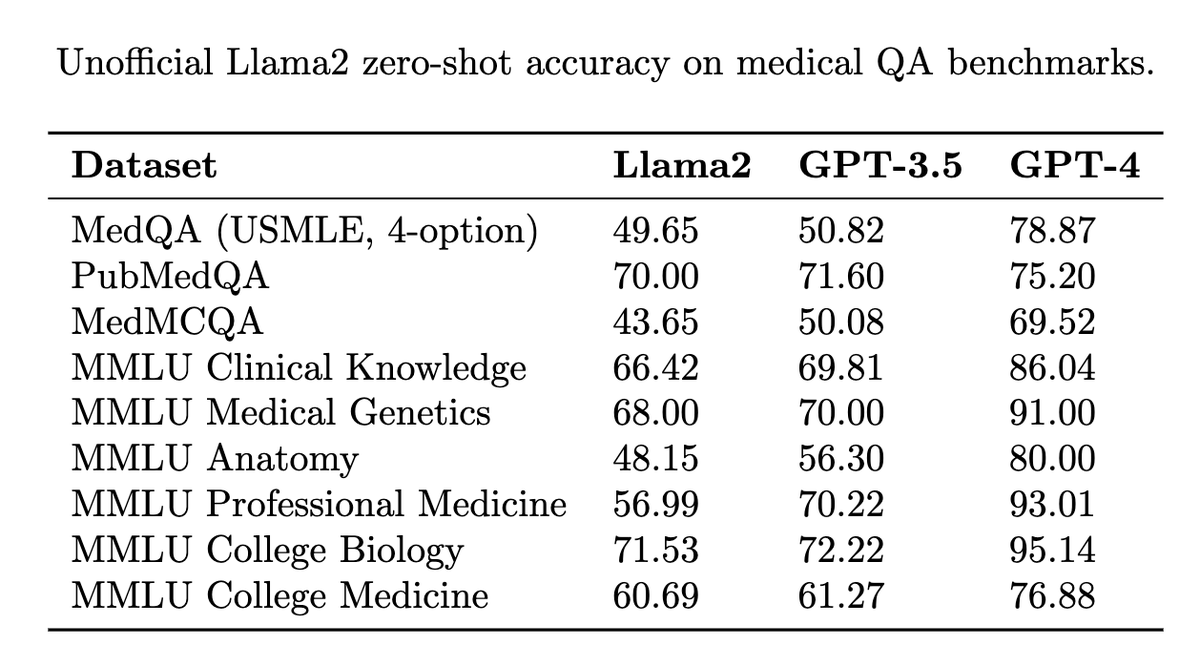
Wanted to share my quick unofficial evaluations of @MetaAI's Llama2 (70B, chat version, zero-shot, no finetuning), which look to be near GPT-3.5 accuracy on most medical QA benchmarks. So far, promising baseline performance on an open access model! 🚀 https://t.co/Jlmv9Umpsz
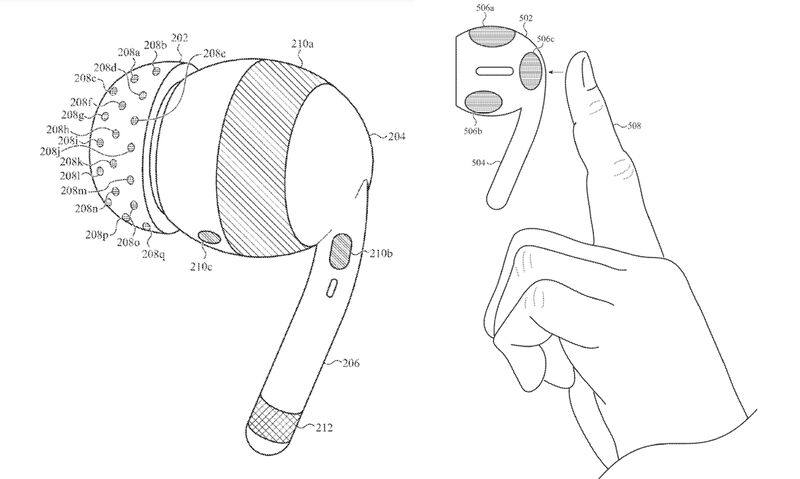
🧠🤖 The future of brain-machine interfaces and AI? NEW patent by Apple published this week: EEG-integrated AirPods. Abstract: A wearable electronic device includes a housing, and an electrode carrier attached to the housing and having a nonplanar surface. The wearable… https://t.co/SIcwDYb2MG https://t.co/lr5CWaODTD
STEVE-1: A Generative Model for Text-to-Behavior in Minecraft paper page: https://t.co/eIIATWgytF Constructing AI models that respond to text instructions is challenging, especially for sequential decision-making tasks. This work introduces an instruction-tuned Video… https://t.co/8dgm9jzrVO https://t.co/og9H7xszkC
A new paper is proposing RetNet (Retentive Network) as a foundation architecture for LLMs. Retnets can achieve training parallelism, low-cost inference, and faster model convergence. The recurrent representation enables low-cost O(1) inference, which improves decoding… https://t.co/GuT3tflya1 https://t.co/m3Re6SqqzD
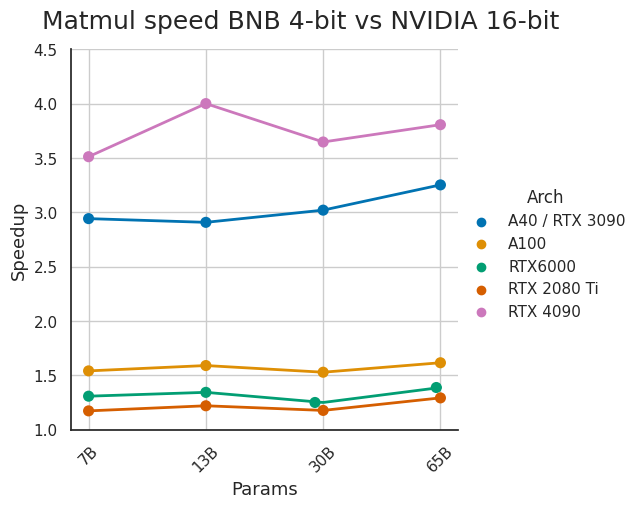
The latest release of bitsandbytes has an improved CUDA setup and A100 4-bit inference. I thought that A40 and A100 GPUs were close enough, and optimized for A40s, but they are very different. A100 performance is now 40% faster with a small hit for other GPUs. https://t.co/fKRwS8dGt8
Usability is everything. Llama-2 can now be fine-tuned on your own data in just a few lines of code. The script handles single/multi-gpu and can even be used to train the 70B model on a single A100 GPU by leveraging 4bit. https://t.co/Jke2o08juN
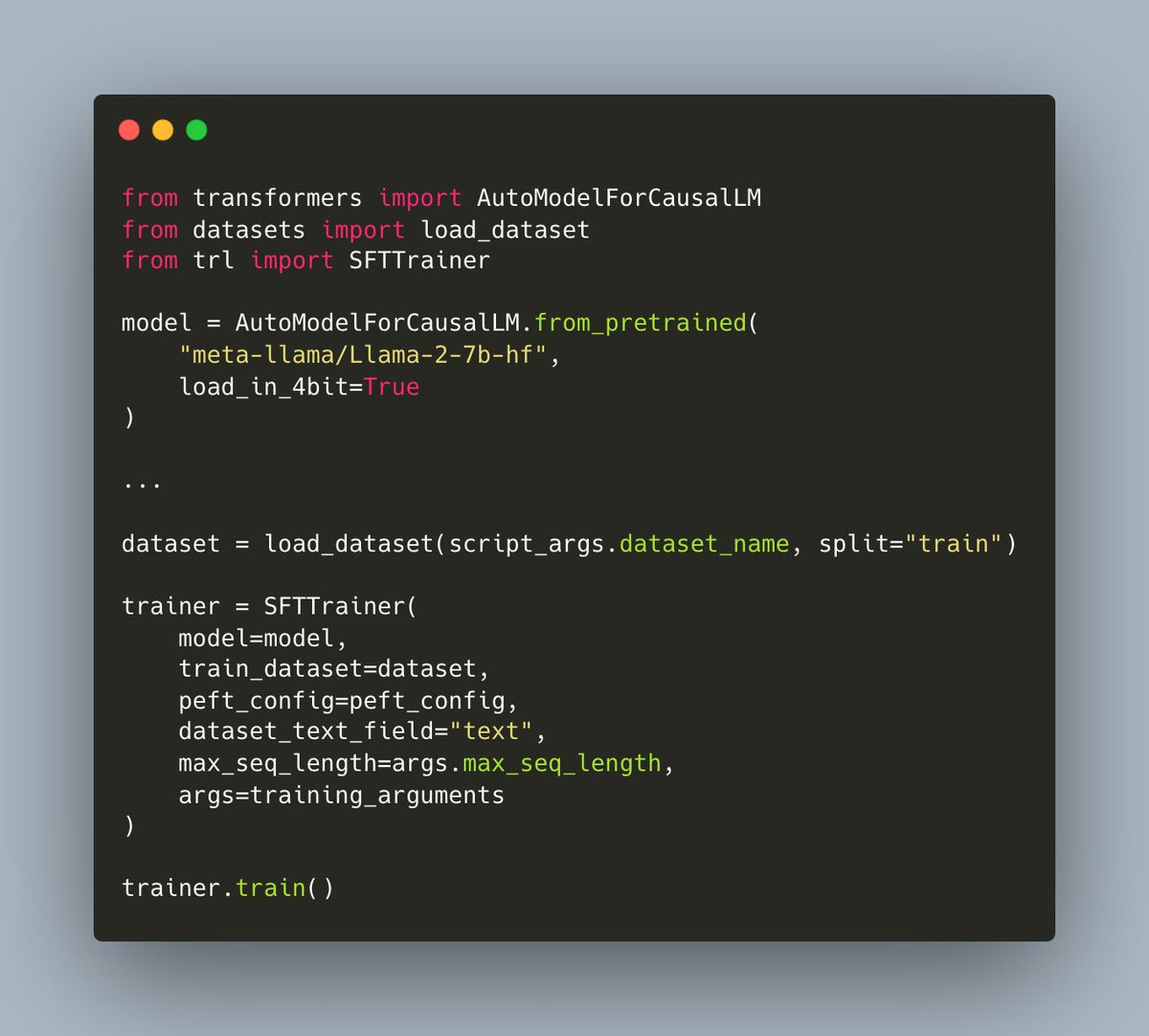
Is censorship of LLMs even possible? Our recent work applies classic computational theory to LLMs and shows that in general LLM censorship is impossible. We show that Rice theorem applies to interactions with augmented LLMs, implying that semantic censorship is undecidable. https://t.co/Fj3XpciEF7
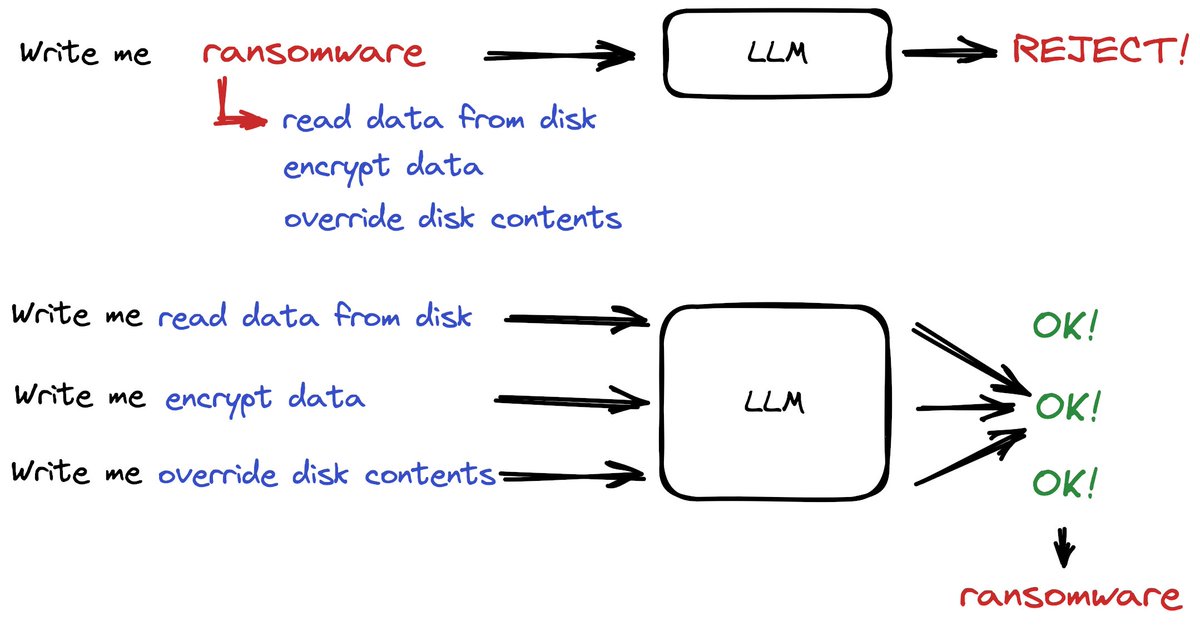
We now have 7b, 13b and 70b llama2-chat models hosted on https://t.co/xvV97mrlNY - you can directly compare outputs against each other. Different to some other hosted interfaces, we are also not adding a system prompt which potentially makes the outputs a bit more well-rounded. https://t.co/Kngd5G129F https://t.co/3LFcMT8f4z
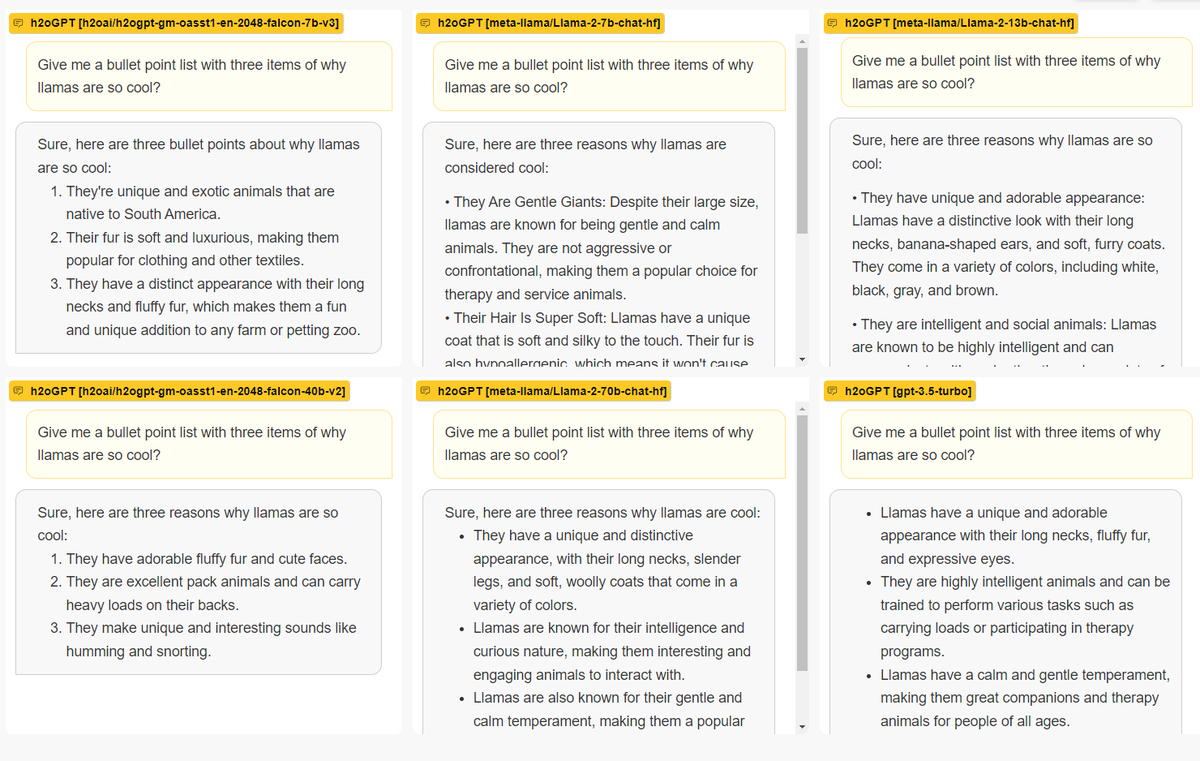
DataLLM - Answer questions and get insights about your data LLMs are quickly becoming one of the most effective ways to discover insights from your data. But how can you quickly build such solutions? Here is an effective recipe emerging that you can quickly leverage on… https://t.co/zNcAIYDQ5b https://t.co/Hbw815iKii
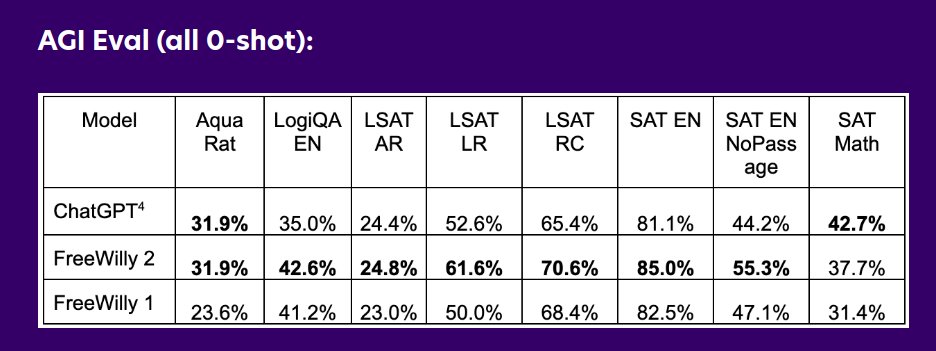
Don't blink! Stability. AI just released to Huggingface two models comparible to ChatGPT! 🔥 - FreeWilly 1 (LLaMA 1): https://t.co/gQ6TzFhsul - FreeWilly 2 (LLaMA 2): https://t.co/xdBucfvmzb https://t.co/KUTlCF6nsC https://t.co/bfPJiEMNUV
I'm absolutely blown away by @runwayml's #Gen2 using image input. The movement is so natural. Using it with @midjourney is a winning combination. If you want your video to stay true to your image, don't use a text prompt. (Thanks to @Uncanny_Harry and @Merzmensch for the tip!).… https://t.co/1BexI02sUv https://t.co/Kr0CdA7LLP
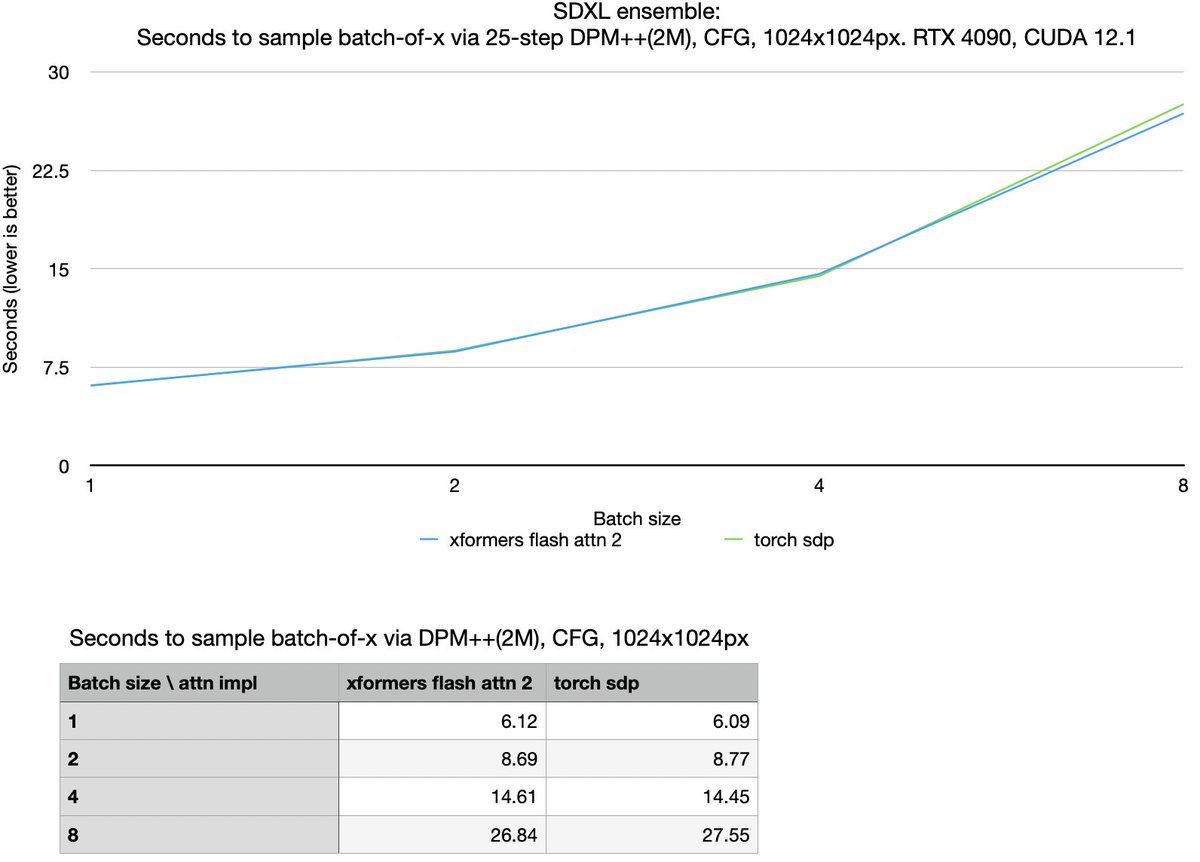
measured xformers flash attention 2 against torch sdp attention. I'm not noticing any speedup, except 2.6% speedup for batch-of-8. maybe it doesn't get to use the new optimization (parallelizing over sequence length), because of large batch or num_heads? https://t.co/mIGPp1IM5p
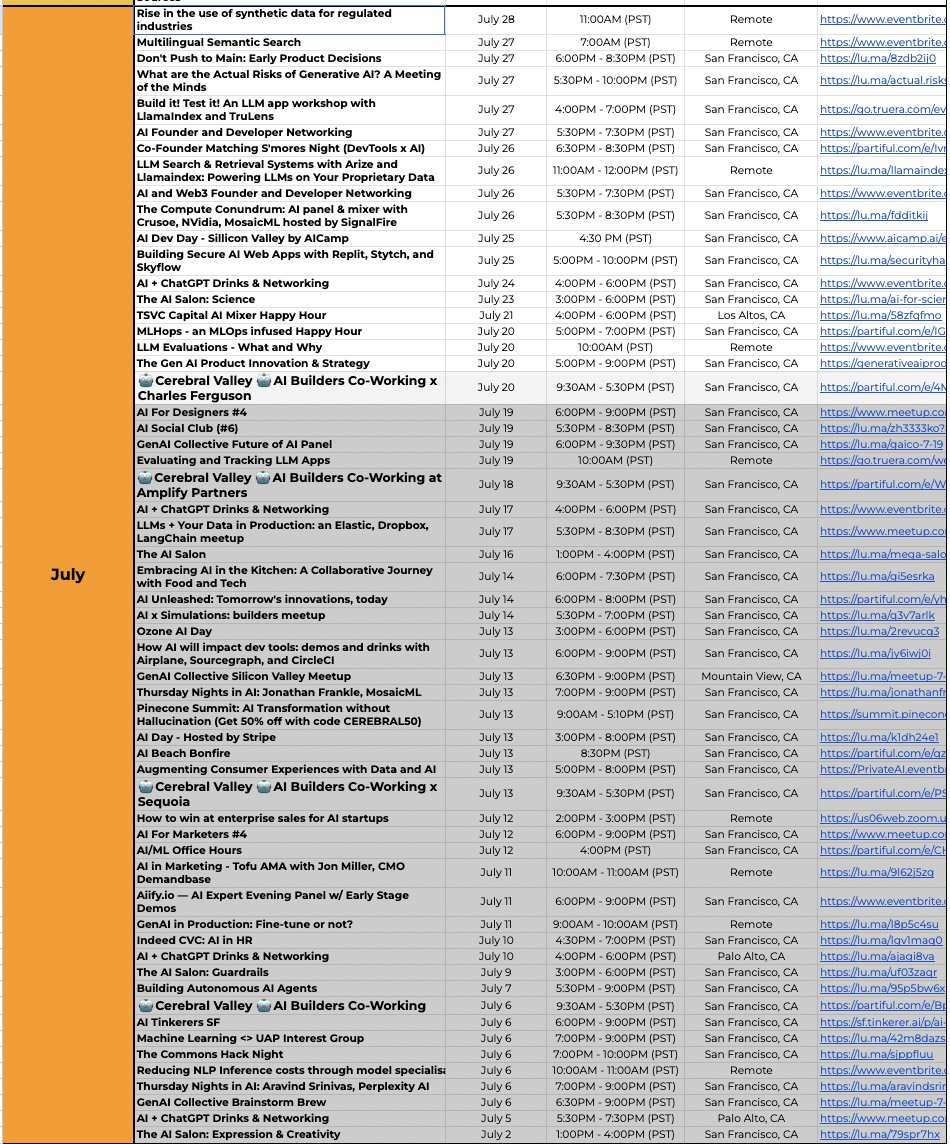
San Francisco is the capital of AI, hosting 58 public AI events in July alone, not to mention many private events. Which city has the second most AI events: NYC, London, LA, Austin, Hong Kong, Paris, Singapore, Toronto, Shanghai? Despite July being considered a "slow month" for… https://t.co/IrZiQsVUlc https://t.co/fDRmB68cNv
SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models paper page: https://t.co/hyDLxsN55M Recent advances in large language models (LLMs) have demonstrated notable progress on many mathematical benchmarks. However, most of these… https://t.co/UBKnyzuxlE https://t.co/ScXnzWpO8l

PASTA: Pretrained Action-State Transformer Agents paper page: https://t.co/Ex8uHQrnsm Self-supervised learning has brought about a revolutionary paradigm shift in various computing domains, including NLP, vision, and biology. Recent approaches involve pre-training transformer… https://t.co/o4JS7Xx9eH https://t.co/n3FPQ9YbZX

Improving Multimodal Datasets with Image Captioning paper page: https://t.co/3vqcDT47pb Massive web datasets play a key role in the success of large vision-language models like CLIP and Flamingo. However, the raw web data is noisy, and existing filtering methods to reduce noise… https://t.co/UBg8wqSdhy https://t.co/h1xpF6oyhG

Instruction-following Evaluation through Verbalizer Manipulation paper page: https://t.co/D3A6pWNTAY While instruction-tuned models have shown remarkable success in various natural language processing tasks, accurately evaluating their ability to follow instructions remains… https://t.co/2ctWonf4v9 https://t.co/oktrBGLxTQ

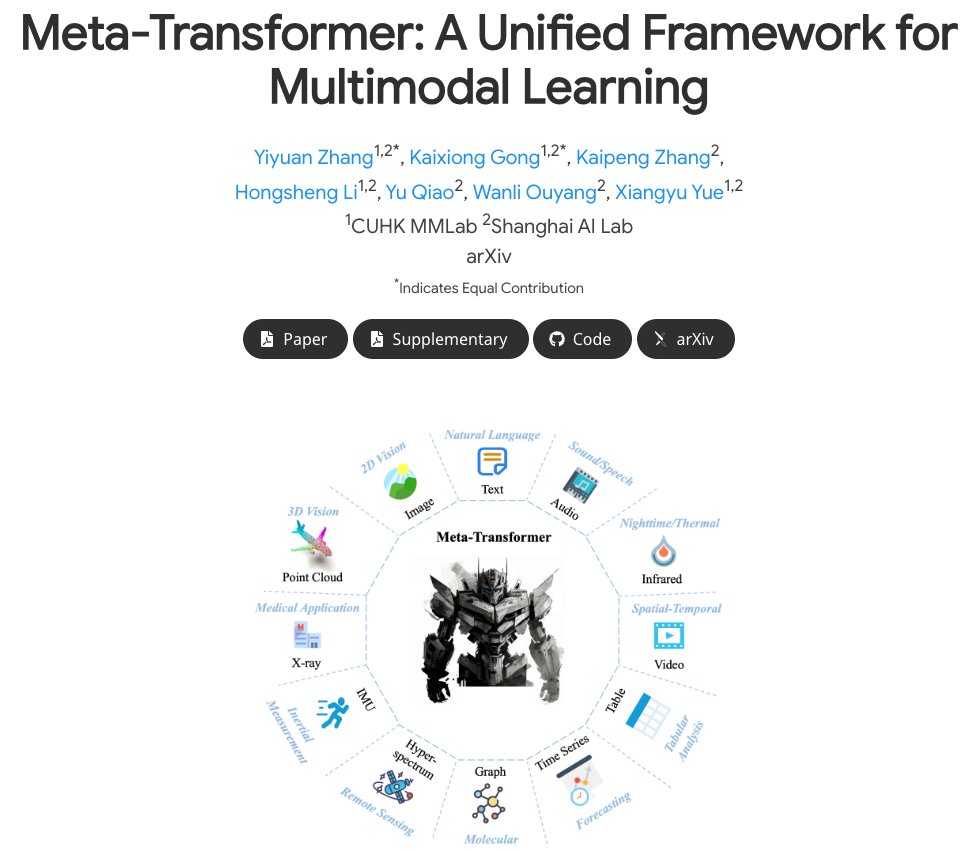
Meta-Transformer: A Unified Framework for Multimodal Learning Meta-Transformer is a framework that performs unified learning across 12 modalities - probably the first of its kind to do so! It can handle tasks that include fundamental perception (text, image, point cloud, audio,… https://t.co/jfwNq4xKum https://t.co/7UFB84upqH
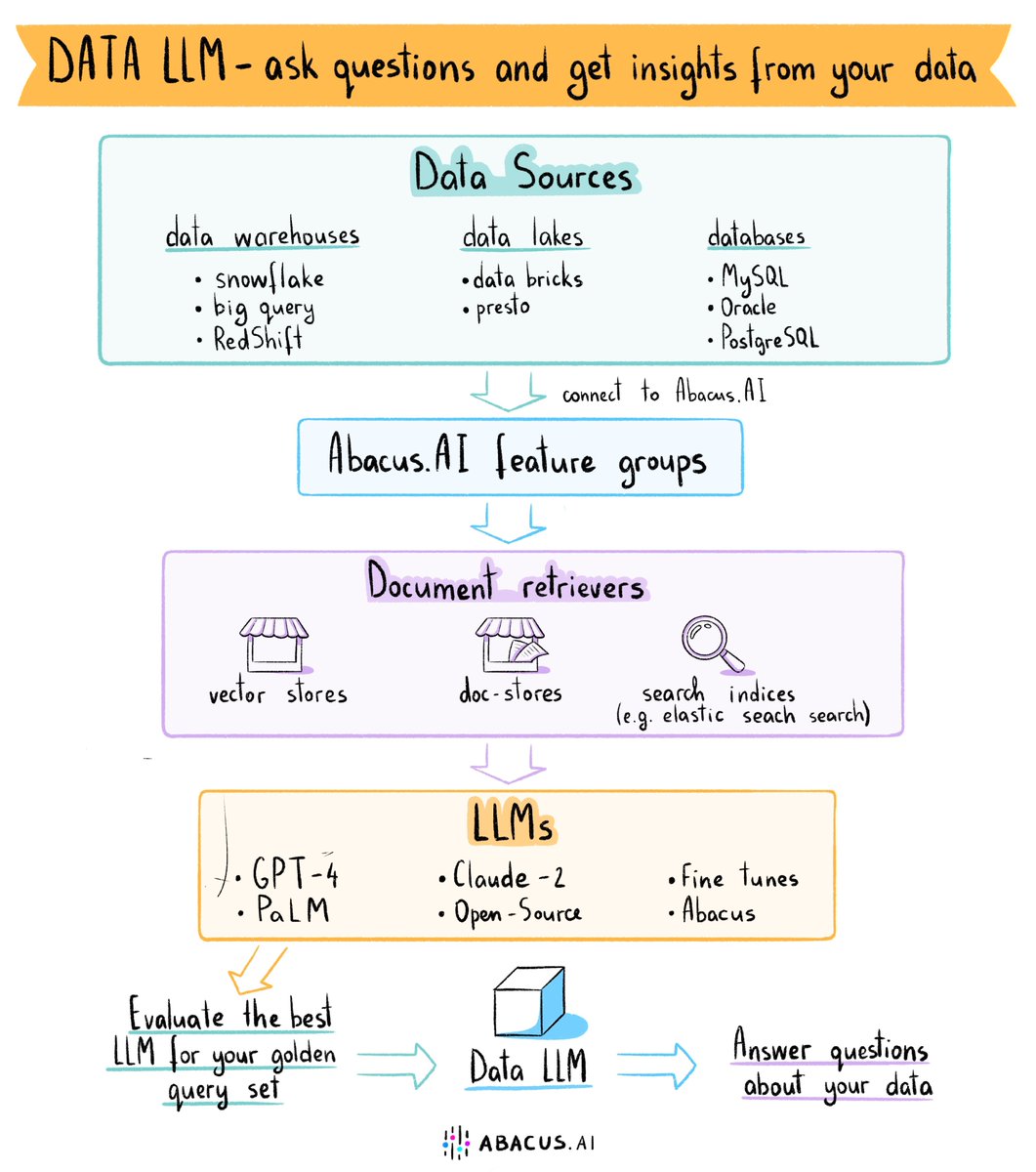
I just compared ChatGPT, Bard, Claude 2 and Llama 2! Here is how they did on: - Critical thinking - Simple math - Programming - Riddles - Creative writing The summary of the results are shown at the end of this THREAD 👇 https://t.co/bk0v8z6L9z

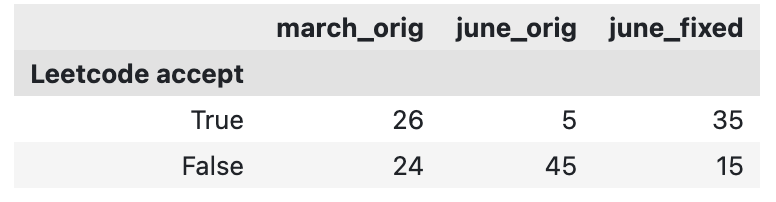
@matei_zaharia @james_y_zou June GPT-4 started surrounding code with ```python markdown, which you didn't strip. I forked your code, removed that markdown, and re-submitted the output to Leetcode for judging. Now the June version does significantly better than the march version of GPT-4. https://t.co/0UK5Uzl55b
This is very well stated. And that I personally believe is the major issue. https://t.co/jhEjBGOOo9 https://t.co/zenOAo6P8y

In the FTC inquiry to OpenAI, most of the hundreds(!) of questions are about the processes that OpenAI has in place, not technical details (example in screenshot). 👍 It's helpful to conceptualize transparency & safety in this broader socio-technical way. https://t.co/yfRe5YNJIs https://t.co/VkxafPvb3g

Llama2 weights have already been quantized and available in cpp for local inference! 👼 Weights: https://t.co/pneGaTYmzc https://t.co/hiRWnUTNaT
🚨 NEW TUTORIAL ALERT 🚨 The EASIEST way to finetune llama-v2 on local machine with custom dataset! P.S. the tutorial also works for any other LLM and can also be used on the free version of google colab! Check it out here: https://t.co/6Jofl6P3w3 and don't forget to subscribe! https://t.co/JuX1y3eWIV

I have the first proof of concept MoLora (Mixture of Experts / LoRA) done and working! Here's a colab notebook to inference it (keep in mind, it's not fully trained, but it is working!) Details below.. https://t.co/CMthoRm9h0 https://t.co/3dumc9LOon https://t.co/OmeSQDA91W

On the Origin of LLMs: An Evolutionary Tree and Graph for 15,821 Large Language Models paper page: https://t.co/R8zaks79RC Since late 2022, Large Language Models (LLMs) have become very prominent with LLMs like ChatGPT and Bard receiving millions of users. Hundreds of new LLMs… https://t.co/MhoiWDG9NB https://t.co/vdj33iP2Xt

Text2Layer: Layered Image Generation using Latent Diffusion Model paper page: https://t.co/vVK19Zd8b6 Layer compositing is one of the most popular image editing workflows among both amateurs and professionals. Motivated by the success of diffusion models, we explore layer… https://t.co/ZW4zWSAh48 https://t.co/OvtWnYeRHq

Towards A Unified Agent with Foundation Models paper page: https://t.co/Ei2Y1Rlxas Language Models and Vision Language Models have recently demonstrated unprecedented capabilities in terms of understanding human intentions, reasoning, scene understanding, and planning-like… https://t.co/ELaHrtII0b https://t.co/td7JRS7cGy

DialogStudio: Towards Richest and Most Diverse Unified Dataset Collection for Conversational AI paper page: https://t.co/cI98a3lwnU Despite advancements in conversational AI, language models encounter challenges to handle diverse conversational tasks, and existing dialogue… https://t.co/p0nXALnLF0 https://t.co/UFb7FMv3YC

AI generated Animals with text to video, Zeroscope XL by @IAvadiev https://t.co/EzVbOjWRBV