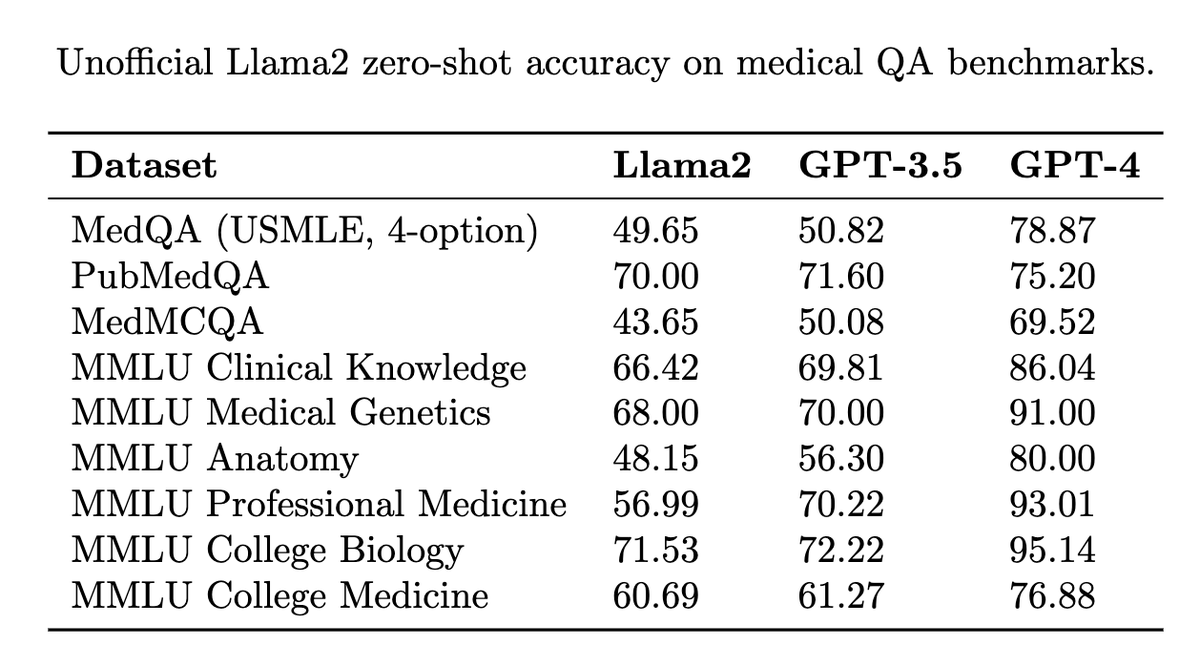
@katieelink
Wanted to share my quick unofficial evaluations of @MetaAI's Llama2 (70B, chat version, zero-shot, no finetuning), which look to be near GPT-3.5 accuracy on most medical QA benchmarks. So far, promising baseline performance on an open access model! 🚀 https://t.co/Jlmv9Umpsz