Your curated collection of saved posts and media
🤯 This is absolutely insane. You can clone any voice locally on your computer using only 3 seconds of reference audio! Entirely open-source. https://t.co/YGm6LZxWDi https://t.co/ZL4uGCYdvK
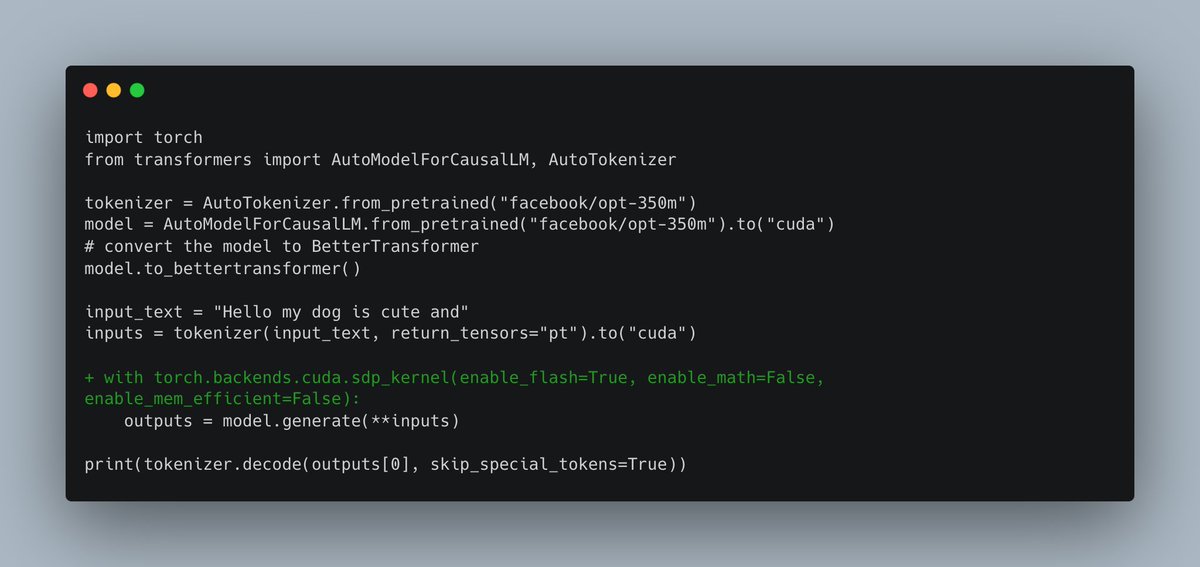
Did you know that flash-attention 1 was already integrated in @huggingface transformers? Let us see how to use it and when it is not possible to use it 🧵 https://t.co/TwUUtfKNeX https://t.co/Wgk1nvG0Wd
🤯Text-to-Sing @Gradio demo. 🔥Results are unbelievably melodious! [attached] Upload a melody of your choice, enter your own lyrics, and have the computer sing back your lyrics in the given melody! Demo on @huggingface Spaces - https://t.co/IbS7qyvM8b https://t.co/qFKhVViFtB
ORES: Open-vocabulary Responsible Visual Synthesis paper page: https://t.co/qH95Ud8OUE Avoiding synthesizing specific visual concepts is an essential challenge in responsible visual synthesis. However, the visual concept that needs to be avoided for responsible visual synthesis tends to be diverse, depending on the region, context, and usage scenarios. In this work, we formalize a new task, Open-vocabulary Responsible Visual Synthesis (ORES), where the synthesis model is able to avoid forbidden visual concepts while allowing users to input any desired content. To address this problem, we present a Two-stage Intervention (TIN) framework. By introducing 1) rewriting with learnable instruction through a large-scale language model (LLM) and 2) synthesizing with prompt intervention on a diffusion synthesis model, it can effectively synthesize images avoiding any concepts but following the user's query as much as possible. To evaluate on ORES, we provide a publicly available dataset, baseline models, and benchmark. Experimental results demonstrate the effectiveness of our method in reducing risks of image generation. Our work highlights the potential of LLMs in responsible visual synthesis.

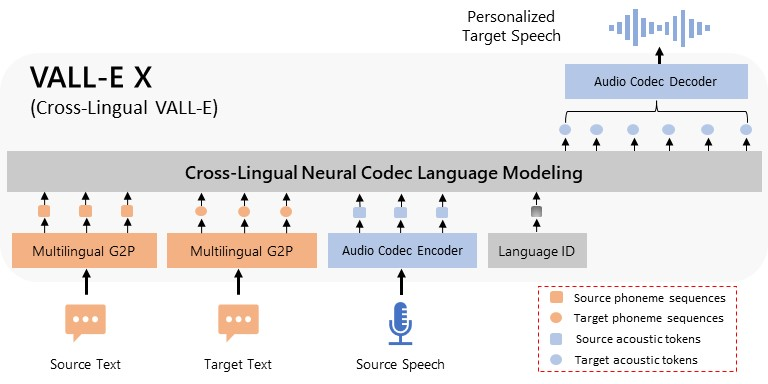
VALL-E X: Multilingual Text-to-Speech Synthesis and Voice Cloning 🔊 github: https://t.co/joqMbM1rOM web demo: https://t.co/EHEgLycJ3R https://t.co/bpMdJR8VFH
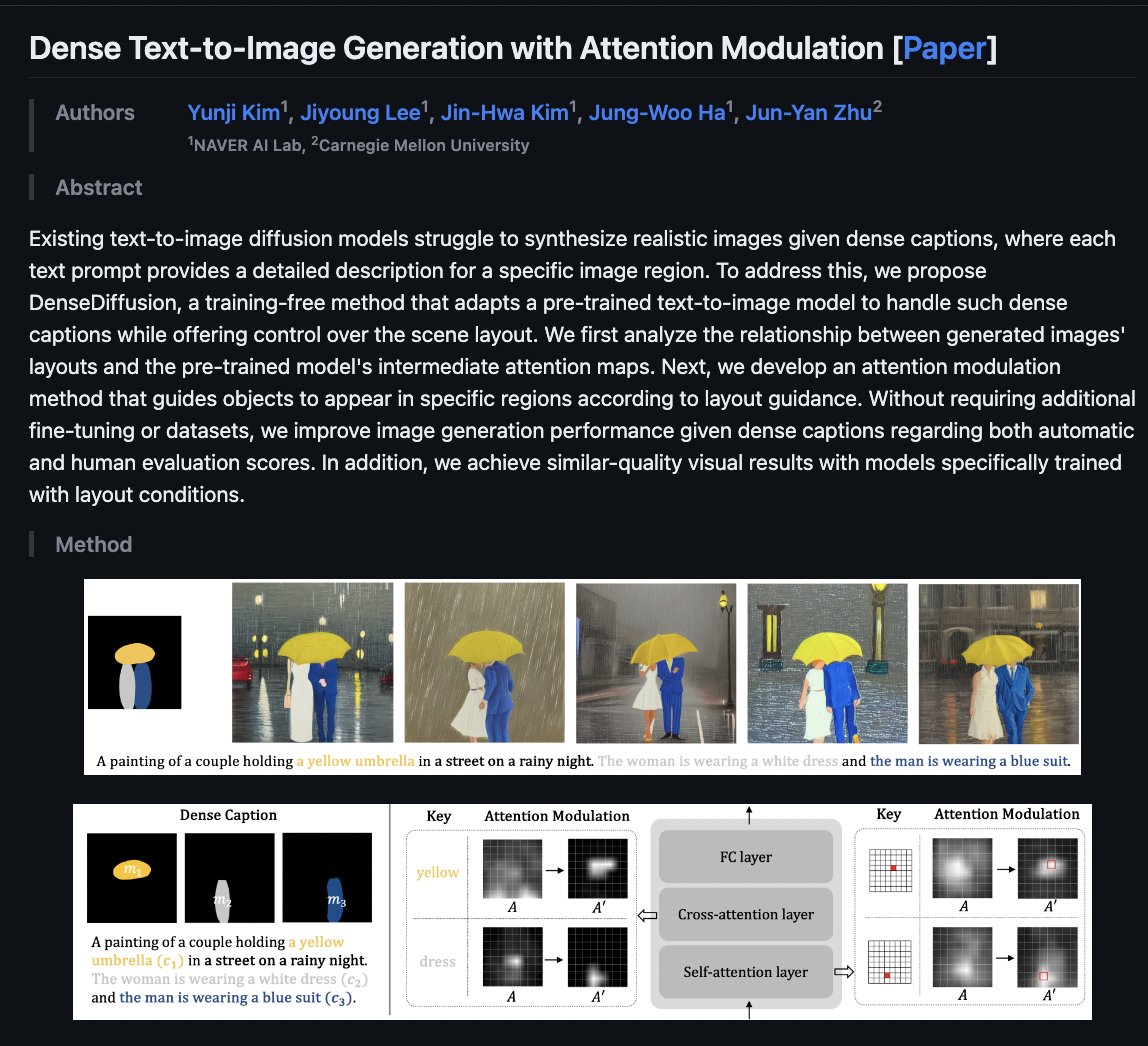
Dense Text-to-Image Generation with Attention Modulation github: https://t.co/HWAIot62Di web demo: https://t.co/ihQV6thM00 Existing text-to-image diffusion models struggle to synthesize realistic images given dense captions, where each text prompt provides a detailed description for a specific image region. To address this, we propose DenseDiffusion, a training-free method that adapts a pre-trained text-to-image model to handle such dense captions while offering control over the scene layout. We first analyze the relationship between generated images' layouts and the pre-trained model's intermediate attention maps. Next, we develop an attention modulation method that guides objects to appear in specific regions according to layout guidance. Without requiring additional fine-tuning or datasets, we improve image generation performance given dense captions regarding both automatic and human evaluation scores. In addition, we achieve similar-quality visual results with models specifically trained with layout conditions.
Relighting Neural Radiance Fields with Shadow and Highlight Hints paper page: https://t.co/yCFqXZPLQh paper presents a novel neural implicit radiance representation for free viewpoint relighting from a small set of unstructured photographs of an object lit by a moving point light source different from the view position. We express the shape as a signed distance function modeled by a multi layer perceptron. In contrast to prior relightable implicit neural representations, we do not disentangle the different reflectance components, but model both the local and global reflectance at each point by a second multi layer perceptron that, in addition, to density features, the current position, the normal (from the signed distace function), view direction, and light position, also takes shadow and highlight hints to aid the network in modeling the corresponding high frequency light transport effects. These hints are provided as a suggestion, and we leave it up to the network to decide how to incorporate these in the final relit result. We demonstrate and validate our neural implicit representation on synthetic and real scenes exhibiting a wide variety of shapes, material properties, and global illumination light transport.

OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models paper page: https://t.co/UoeEJ6xGDs Large language models (LLMs) have revolutionized natural language processing tasks. However, their practical deployment is hindered by their immense memory and computation requirements. Although recent post-training quantization (PTQ) methods are effective in reducing memory footprint and improving the computational efficiency of LLM, they hand-craft quantization parameters, which leads to low performance and fails to deal with extremely low-bit quantization. To tackle this issue, we introduce an Omnidirectionally calibrated Quantization (OmniQuant) technique for LLMs, which achieves good performance in diverse quantization settings while maintaining the computational efficiency of PTQ by efficiently optimizing various quantization parameters. OmniQuant comprises two innovative components including Learnable Weight Clipping (LWC) and Learnable Equivalent Transformation (LET). LWC modulates the extreme values of weights by optimizing the clipping threshold. Meanwhile, LET tackles activation outliers by shifting the challenge of quantization from activations to weights through a learnable equivalent transformation. Operating within a differentiable framework using block-wise error minimization, OmniQuant can optimize the quantization process efficiently for both weight-only and weight-activation quantization. For instance, the LLaMA-2 model family with the size of 7-70B can be processed with OmniQuant on a single A100-40G GPU within 1-16 hours using 128 samples. Extensive experiments validate OmniQuant's superior performance across diverse quantization configurations such as W4A4, W6A6, W4A16, W3A16, and W2A16. Additionally, OmniQuant demonstrates effectiveness in instruction-tuned models and delivers notable improvements in inference speed and memory reduction on real devices.

Qwen-VL: A Frontier Large Vision-Language Model with Versatile Abilities github: https://t.co/2dmrybryNE web demo: https://t.co/bGyJsbpfGU https://t.co/zjqdJRr0TW

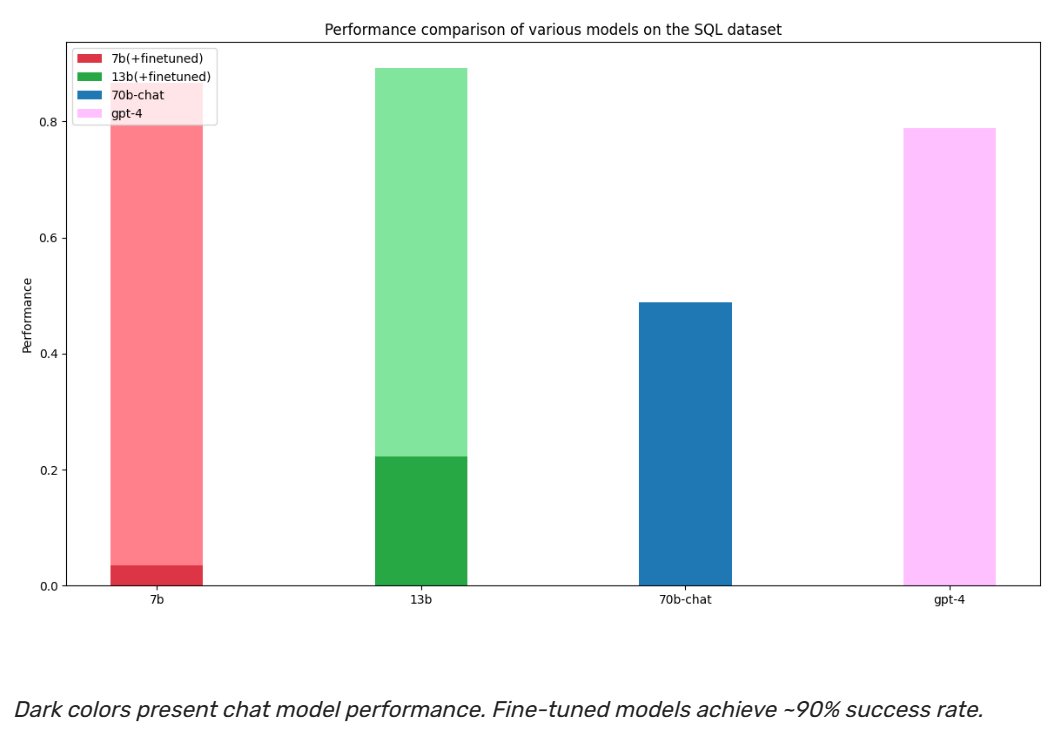
The rate of innovation we are seeing in LLMs is mindblowing. Here is a study comparing a fine-tuned Llama-2 with GPT4. Some takeaways: - Fine-tuned Llama-2 outperforms GPT4 in SQL and unstructured data understanding. - GPT4 outperforms fine-tuned Llama-2 in math reasoning. This result is very interesting, and it shows the potential of OSS models. However, let's not forget that we are not comparing apples to apples. Llama-2 here is a fine-tuned model, and GPT4 is a zero-shot model. A few months ago, it was unimaginable to think that a zero-shot model would outperform a fine-tuned model. Now we are making benchmarks of the opposite. We are living in exponential times. Details here: https://t.co/gqGWZa2Rd3 ____ #AI #datascience #machinelearning #LLM
SoTaNa: The Open-Source Software Development Assistant paper page: https://t.co/FanO5BZc4v Software development plays a crucial role in driving innovation and efficiency across modern societies. To meet the demands of this dynamic field, there is a growing need for an effective software development assistant. However, existing large language models represented by ChatGPT suffer from limited accessibility, including training data and model weights. Although other large open-source models like LLaMA have shown promise, they still struggle with understanding human intent. In this paper, we present SoTaNa, an open-source software development assistant. SoTaNa utilizes ChatGPT to generate high-quality instruction-based data for the domain of software engineering and employs a parameter-efficient fine-tuning approach to enhance the open-source foundation model, LLaMA. We evaluate the effectiveness of in answering Stack Overflow questions and demonstrate its capabilities. Additionally, we discuss its capabilities in code summarization and generation, as well as the impact of varying the volume of generated data on model performance. Notably, SoTaNa can run on a single GPU, making it accessible to a broader range of researchers.

Could Voiceflow emerge as the 'WordPress' for AI agents? I believe they stand a good chance.🏆 Over the past month, I've immersed myself in the world of AI chatbots and agents, exploring various platforms. Among them, Voiceflow stands out due to its advanced functionality, user-friendliness, and impressive enterprise customer base. While Voiceflow offers sophisticated tooling for creating end-to-end conversational AI agents, its power is evident even in its most basic chatbot functionality. This morning, I put together a short tutorial on how I built a basic chatbot for real estate agents in less than 30 minutes using Voiceflow. Let us know what you think. P.S. Not sponsored by @VoiceflowHQ. Just a huge fan.
Unpopular take: LLM community is *coping* about quantization. Any real test of reasoning shows k-quants≤Q5 fail. Ppl, evals are misleading: do you care that it's only 1% loss if it takes 99% of the hardest skills? We need kernels for AWQ, SpQR, or better – for all platforms. https://t.co/5RNOScIzgj
They are hinting at that, sure. But they're testing on OPT, as in most of those Hype-Aware Quantization papers Why? OPT's FF layers use ReLU. It sacrifices perplexity but makes activations sparse. I'm skeptical it'll work for SwiGLU in LLaMA… without retrain. (paper:MoEfication)

💪🤯 Are you ready for a new super prompt? This time we're going to create detailed statues of our favorite characters with a very special twist. What's the prompt?👇 📃 A statue of [subject], in the style of highly detailed foliage, matte drawing, museum gallery dioramas, trompe-l'œil illusionistic detail, light [color] and dark gray, bold shadows, intertwining materials --ar 85:128 ⚙️ Choose the subject and the color, keep the rest the same, and share your results! 🫂🖤 Remember, if you liked it, give it a like, repost, and invite your friends to participate. Let's go for it! ✨🎨🗽 #CreativeChallenge #ArtisticTwist #midjourney #aiartcommunity

They are hinting at that, sure. But they're testing on OPT, as in most of those Hype-Aware Quantization papers Why? OPT's FF layers use ReLU. It sacrifices perplexity but makes activations sparse. I'm skeptical it'll work for SwiGLU in LLaMA… without retrain. (paper:MoEfication) https://t.co/LbkvP5LW5i

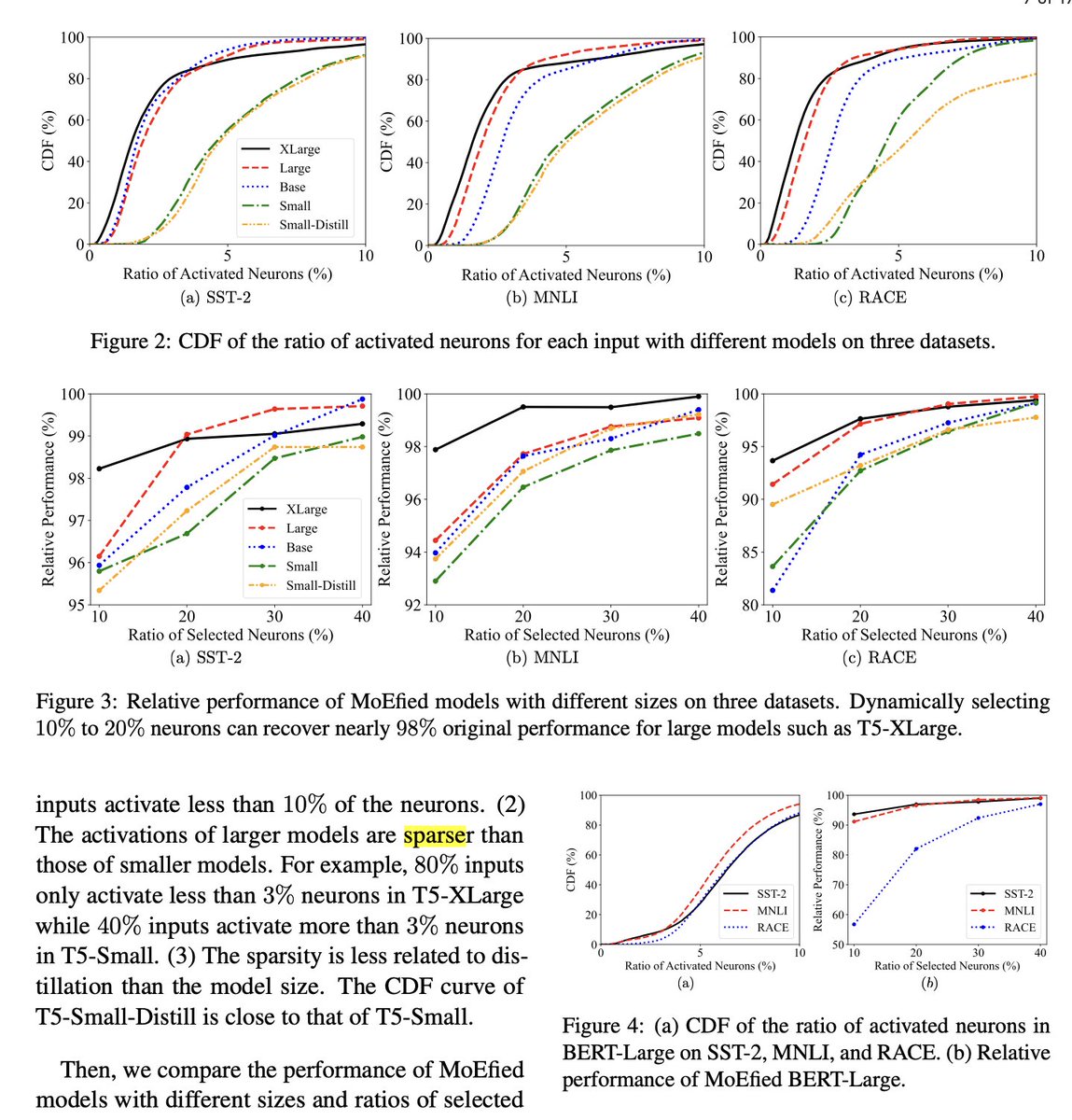
DevOpsGPT is about to reach 3,000 stars on Github. It's a Multi-Agent system for software development. They combined LLM with DevOps tools to convert natural language requirements into working software. DevOpsGPT allows you to: ▸ Increase development efficiency ▸ Reduce communication costs ▸ Shorten development cycles ▸ Improve quality of software delivery
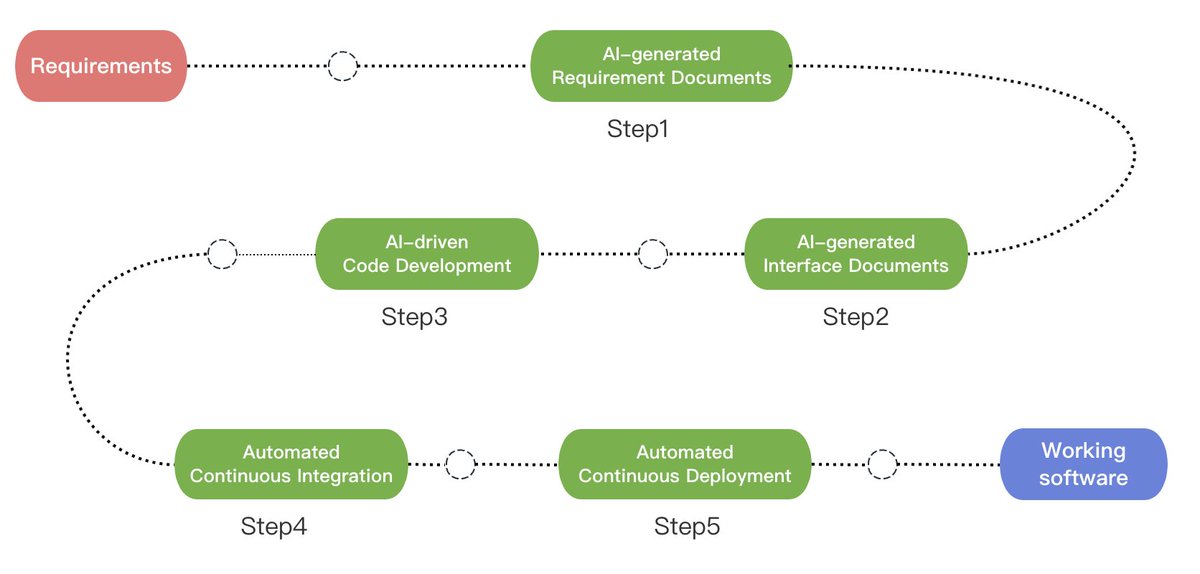
Here's a clever new algorithm for better retrieval + better RAG, (s/o @jxnlco + ChatGPT): the “AutoMergingRetriever”. Retrieve smaller chunks, then recursively merge into more “continuous” blobs of context. Leads to better LLM synthesized answers: https://t.co/46CPmPjU2F https://t.co/HeCnwhKYch
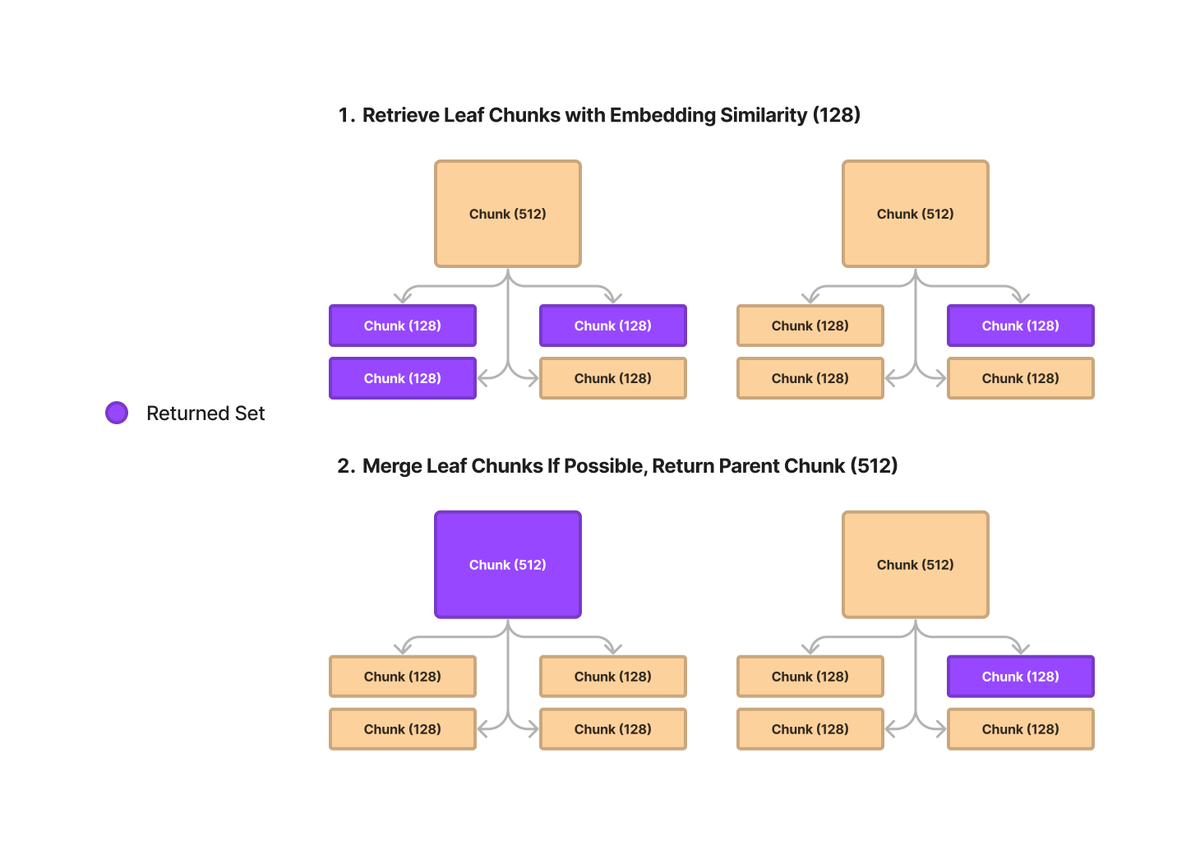
Anti-hype LLM Reading List This is actually a really good list of papers and reading materials on LLMs. Love the curation by @vboykis. https://t.co/XYQP1FcQnC
Top ML Papers of the Week (August 21 - August 27): - Code Llama - Prompt2Model - Use of LLMs for Illicit Purposes - Survey on Instruction Tuning for LLMs - A Survey on LLM-based Autonomous Agents - Language to Rewards for Robotic Skill Synthesis ... https://t.co/UUYknp7P0A
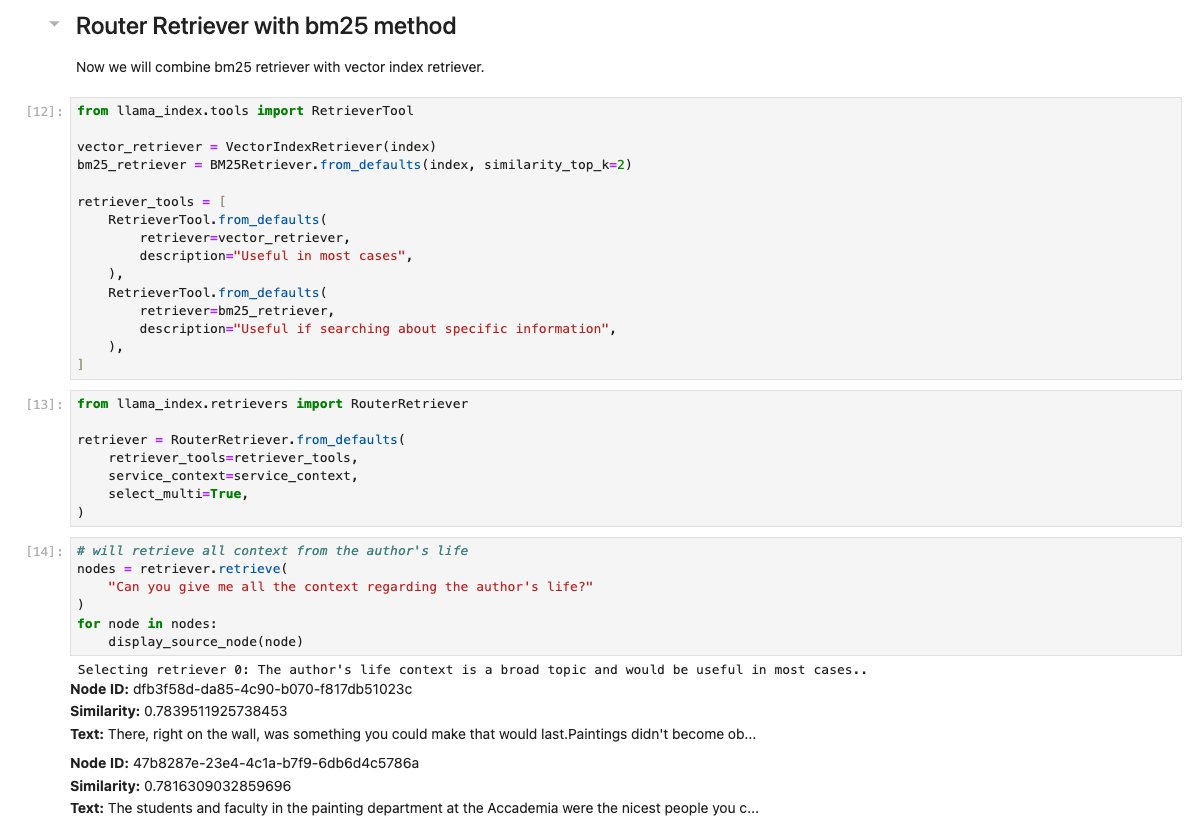
There’s two key concepts for retrieval: semantic vs. keyword search. Hybrid search is a compromise but uses fixed parameters. What if you could have the LLM dynamically decide whether to use vector search or BM25 given a Q? 🚏 Checkout our new guide: https://t.co/YAwC7Yu577 https://t.co/kBejM6D7zI
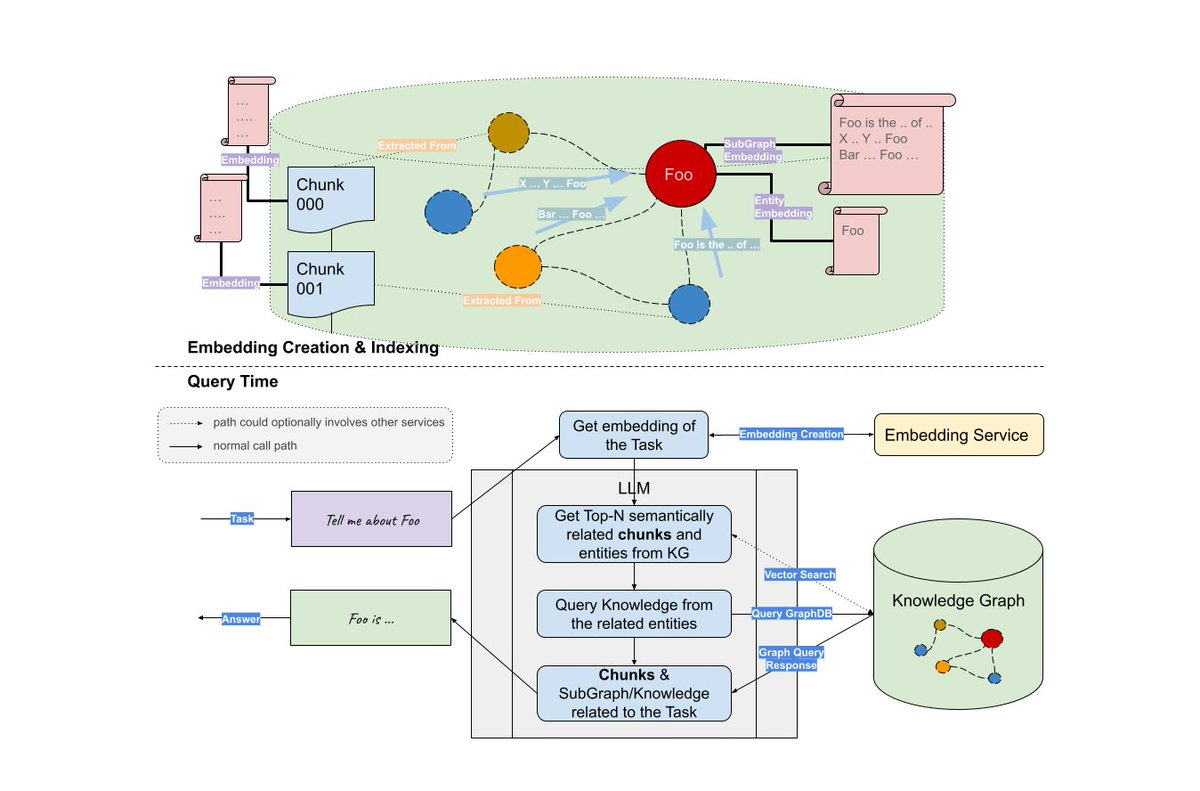
We now have the most comprehensive cookbook on building LLMs with Knowledge Graphs (credits @wey_gu). ✅ Key query techniques: text2cypher, graph RAG ✅ Automated KG construction ✅ vector db RAG vs. KG RAG Check out the full 1.5 hour tutorial: https://t.co/mChA4oWzcL https://t.co/v52umkGMG9
🤯 You can now easily face-swap any video, all locally on your Macbook. All you need is a photo and a video. FaceFusion is an open-source face swapper/enhancer with a simple web interface. On an M1/M2 Macbook, it even makes use of Core ML! https://t.co/EjQmv2ut6u https://t.co/aU2tpglECv
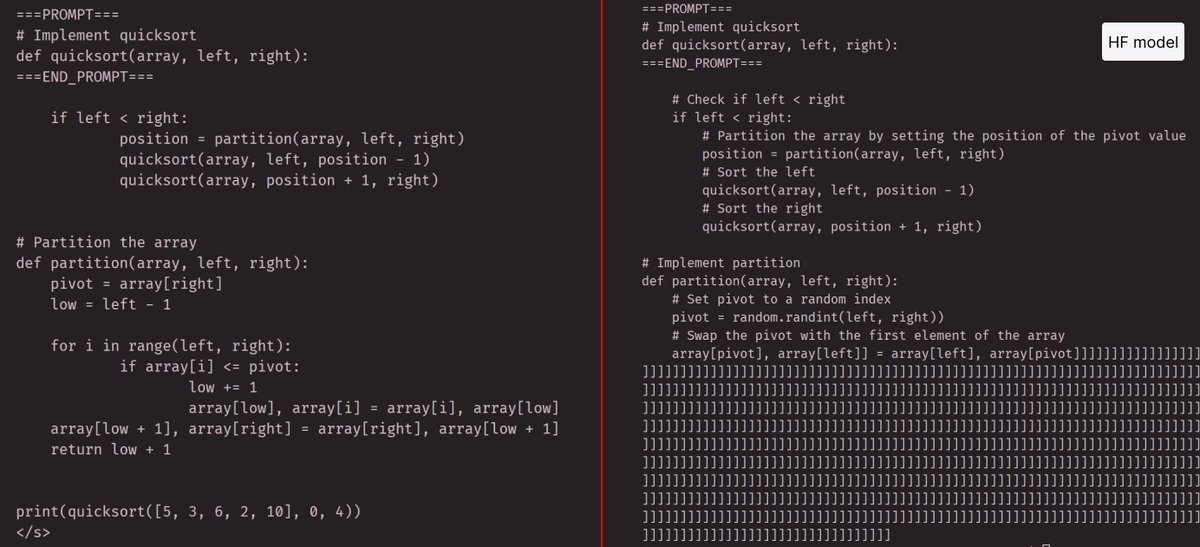
Not sure if anyone else has seen this, I get very bad outputs using the HF code llama models, see below for the same prompt using HF vs meta provided code & weights (34b model). Also recommend the inference code from meta which is much faster out of the box https://t.co/mtqq53BkRq
Deep Neural Nets: 33 years ago and 33 years from now https://t.co/pbZvYgMJak My post from last year randomly made it to HN so resharing here too. Maybe in 2055 someone will train an improved GPT-4 on their personal computing device in ~1 min as an irrelevant fun weekend project. https://t.co/jmDbq6PovD
Blending-NeRF: Text-Driven Localized Editing in Neural Radiance Fields Hyeonseop Song, Seokhun Choi, Hoseok Do, Chul Lee, Taehyeong Kim tl;dr: pretrained NeRF+editable NeRF #ICCV2023 https://t.co/0ygDwWIZx3 https://t.co/HBFMctkXDG

AI Burger commercial made this video using images generated in @midjourney that were animated in @pika_labs and @runwayml #aivideo #Food
🚨Fresh! Fruits are LOVE😍 #aiartcommunity Prompt 📑: [Fruit] color splash,black background, in the style of fluid photography, spectacular backdrops, vray, environmental awareness, duckcore, digital art wonders, award-winning Inviting all 🥳 Follow🥰 BM📍RT ♻️ https://t.co/8S4ME8mMXi

On very exciting use of AI is that it can build interactive educational tools. Here, I asked Code Interpreter to develop an interactive website that illustrated the Central Limit Theorem in statistics. Just two prompts! Chat: https://t.co/WpcGLJR8XP Site: https://t.co/9S1GiJBmWp https://t.co/moeUdCpd3p

Text FX Google silently dropped this new AI powered tools for rappers, writers and wordsmiths in collaboration with Lupe Fiasco Technology has been paramount to Hiphop/rap This is just the latest tool in that tool box of samplers, drum machines & recorders Link below ⬇️ https://t.co/87ai7W7ySw
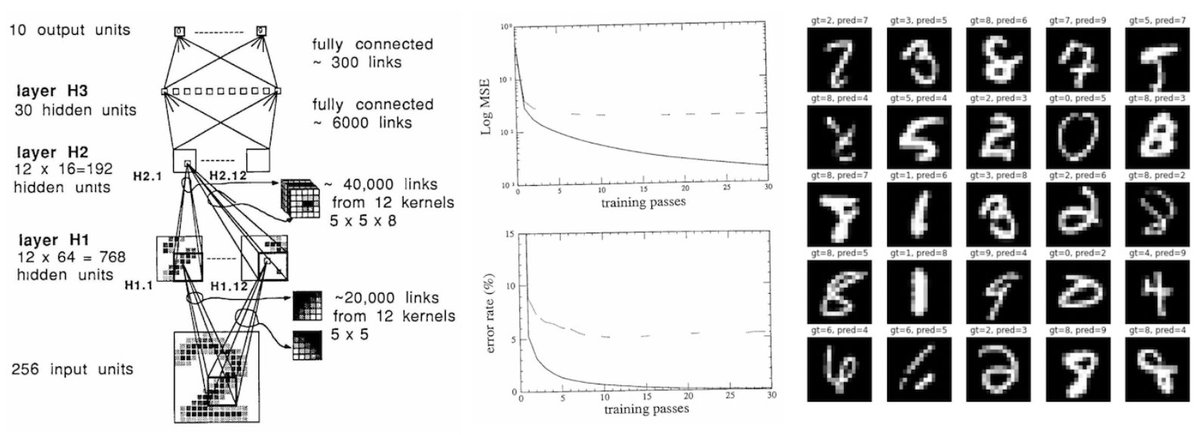
A key concept we’ve been playing around is “chunk dreaming” (s/o @tomchapin) 💭 Given a text chunk, auto-extract metadata like questions it can answer and also summaries over adjacent nodes. Better context -> better performing RAG. Brand-new guide 💫: https://t.co/tMrp4T9Teg https://t.co/me5XVTUk8G
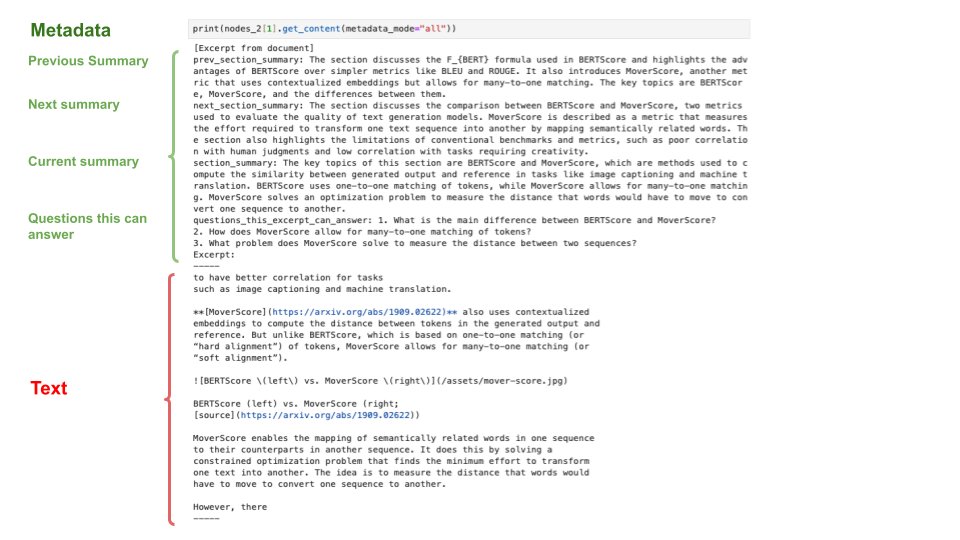
One of the best ways to reduce hallucinations with LLMs is by retrieving useful, factual information and injecting it into the LLM’s prompt as added context. Although this might sound complicated, it’s actually quite easy to implement with standard vector search functionality… Why do we need this? All LLMs have a fixed context length. So, the amount of information we can include in a prompt is limited by nature! As such, we need to be selective about the context that we provide to our model. If we want to provide useful context that can reduce hallucinations and improve the model’s output, one of the best approaches is to retrieve relevant information from an external (vector) database. Retrieval framework for LLMs. Assuming that we have a lot of relevant textual data that can be used by an LLM, we can’t just inject all of this data into the model’s prompt every time that we perform inference. Rather, we need to do the following: 1. Break our data into textual chunks 2. Vectorize each of the textual chunks 3. Store these vectors (with their data) in a vector database 4. Find relevant data at inference time using vector search 5. Add relevant data to our prompt to provide more context to the LLM We will use the same embedding model to vectorize these chunks and to generate query vectors that can be used for search. Storing data in a vector db. The first step in the above framework is to chunk our data. Typically, we will use chunks of ~200 tokens. However, the optimal chunk size is a hyperparameter that can change depending on the application. Then, we use an embedding model to vectorize each of these chunks, and we can store them, along with their text data, in a vector database (e.g., Redis, Weaviate, Pinecone, Qdrant, etc.). Retrieving relevant context. When we want to retrieve relevant textual data from our vector db, we should just i) create a query embedding based on our prompt (possibly including the chat history) and ii) run a vector search for relevant documents. This way, we can use semantic search to identify portions of data that are relevant to include as context within the LLM’s prompt. Creating the query embedding. There are a ton of different ways we can create query embedding for searching our vector db. The simplest approach would be to truncate our chat history or prompt and pass this directly into the embedding model. But, if this is too long, we could ask the LLM to summarize our chat history or prompt before embedding it, or even to convert the chat history or prompt into a list of search keywords. Picking an embedding model. To make sure this works well, we need a good embedding model that captures the semantic similarities between our queries and textual chunks. There are a variety of good embedding models publicly available via SentenceTransformers and HuggingFace. To find one that works for you, I’d recommend taking a look at the Massive Text Embedding Benchmark (hosted on HuggingFace). The result. We can use the approach described above to power retrieval-augmented generation (RAG), which is one of the best ways to reduce hallucinations and improve the output of LLMs. Given that this approach can be implemented without significant effort via tools like Pinecone / Weaviate and HuggingFace / SentenceTransformers, it is undoubtedly one of the most useful practical tools for building with LLMs.
Not much is known about the pretraining data of Code Llama but there is some good evidence the @StackOverflow was part of it. Found some breadcrumbs while working on a demo with a hello world example: Suddenly the model started generating a discussion between two users. https://t.co/3vnGo8Wr2j
