Your curated collection of saved posts and media
New ModelScope Image2Video demo shared by @fffiloni https://t.co/tUzswIT9cs
A new ModelScope Image2Video is out on @huggingface 🤗 we love it ! It generates a short video from init image while keeping style consistency and try to restitute the general composition idea from source Share your results with the Community 😌🤩 — 👉 https://t.co/AVqVAMqaCi htt
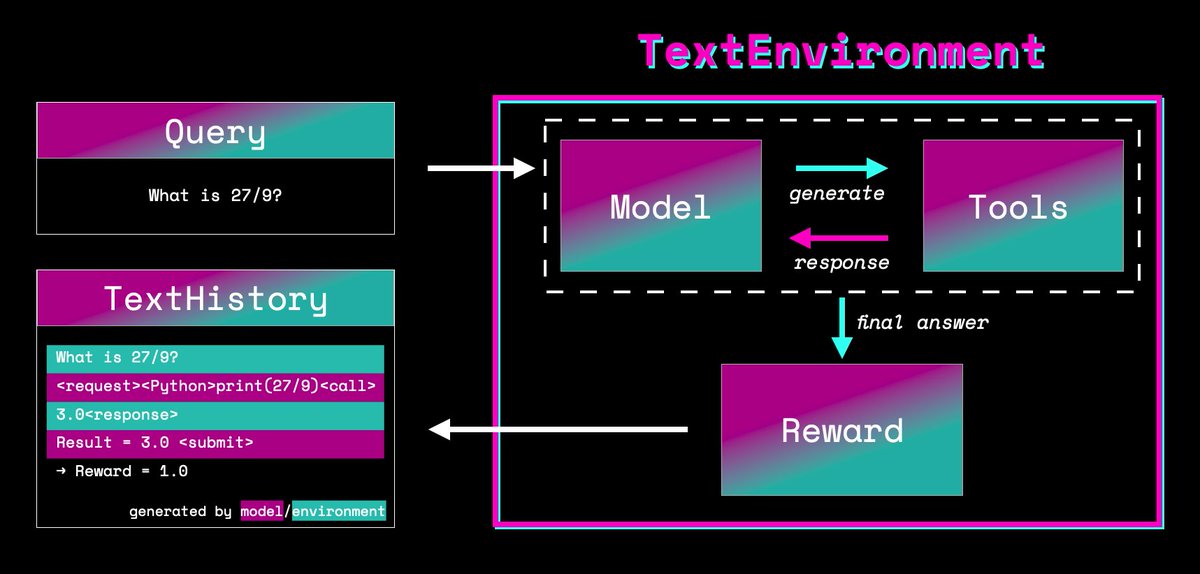
Introducing TextEnvironments in TRL 0.7.0! https://t.co/SuGrdSaMZh With TextEnvironments you can teach your language models to use tools to solve tasks more reliably. We trained models to use Wiki search and Python to answer trivia and math questions! Let's have a look how🧵 https://t.co/2ZuvBQJJsa
Last week we introduced ✨ Prodigy v1.13.1 ✨with support for the new "model as annotator" recipes. To show off this new feature, @fishnets88 recorded a demo that shows how it may help prioritizing examples to annotate first. https://t.co/XFoAMnWUzE https://t.co/OcwiQpzyVK

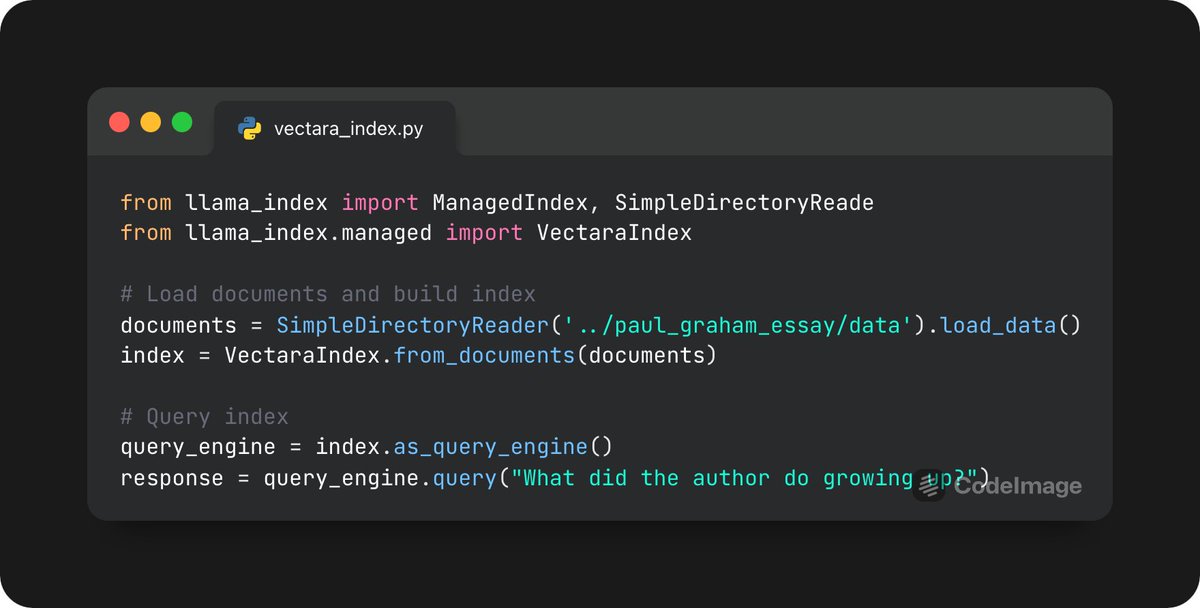
We introduce a new managed index abstraction that abstracts away the ingestion and storage steps of RAG within a managed service. Excited to introduce our first integration with @vectara, courtesy of @ofermend. Check out our full guide here: https://t.co/Pxqk0wdMvn https://t.co/3Y5lRthfV6
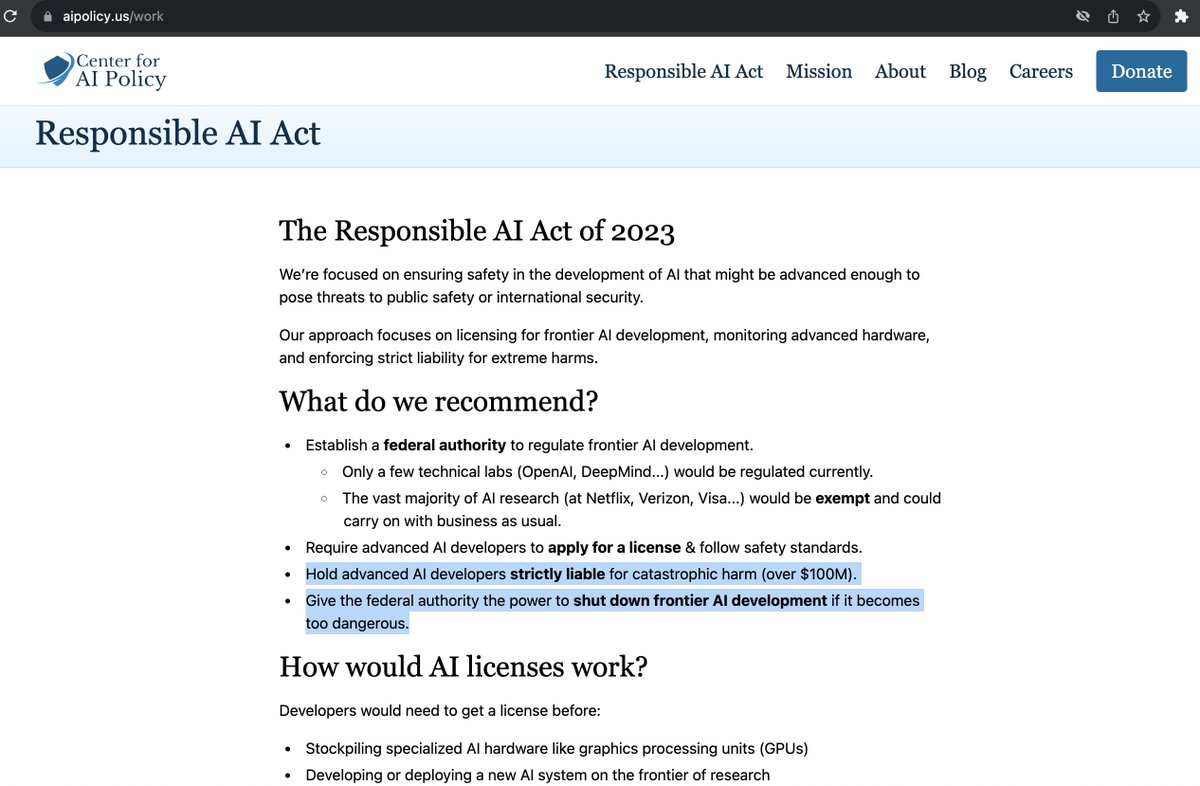
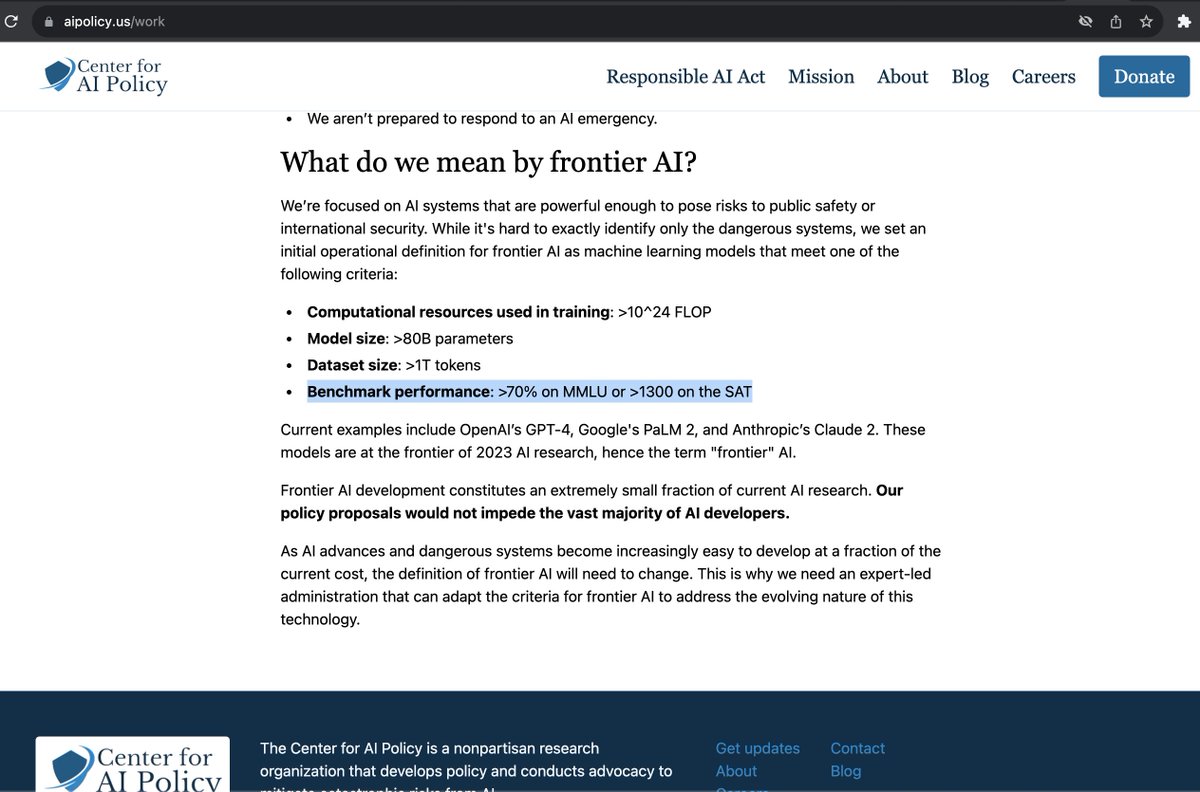
So... who's going to explain MMLU to these folks? https://t.co/bbkFzoRcD7
I'm opposed to any AI regulation based on absolute capability thresholds, as opposed to indexing to some fraction of state-of-the-art capabilities. The Center for AI Policy is proposing thresholds which already include open source Llama 2 (7B). This is ridiculous.
🚨 NLP News 🛠 Tool-Augmented LLMs https://t.co/MnqyD3CGfx https://t.co/P6zYj4MTZf
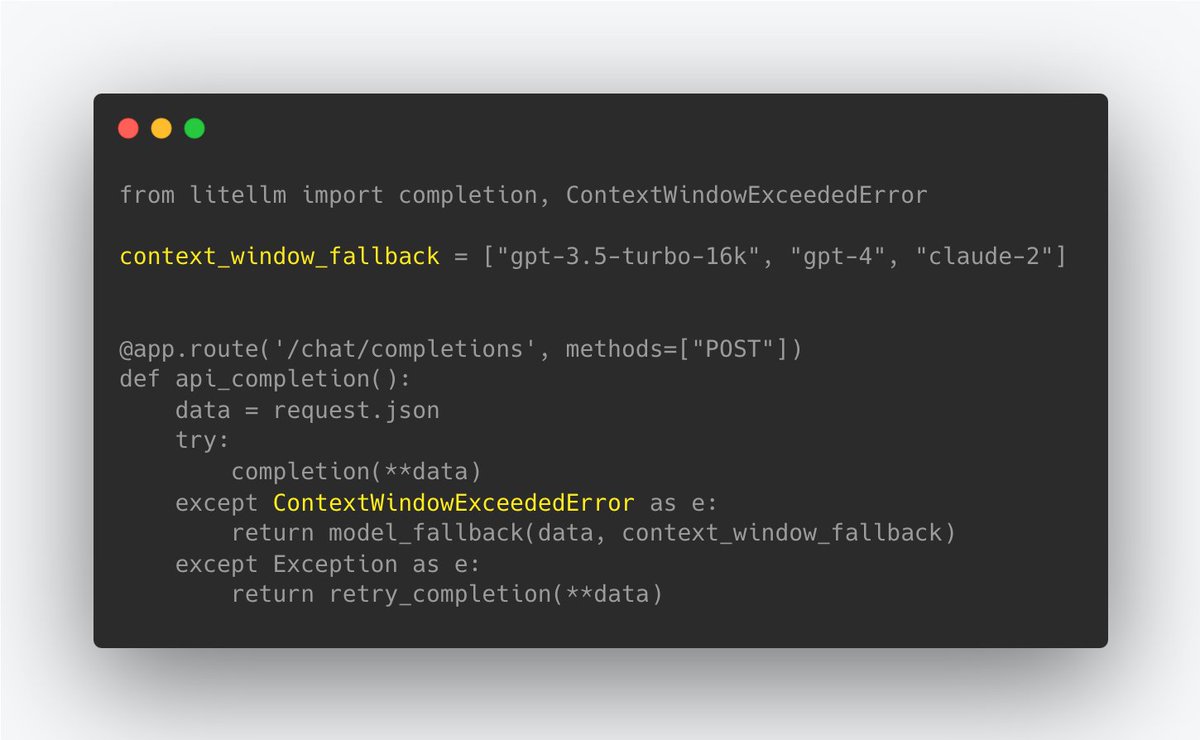
5️⃣ new things @LiteLLM 🔥 New @Replit 1-click deploy template 🙋♂️New Error type - Context Window Exceptions ✌️ Exception mapping support for @togethercompute @AI21Labs @OpenRouterAI 🦙 New CodeLlama Model Page - add to your app in 1 click 🛠️ Set @VertexAI credentials via .env https://t.co/0Vm2RbxhWc
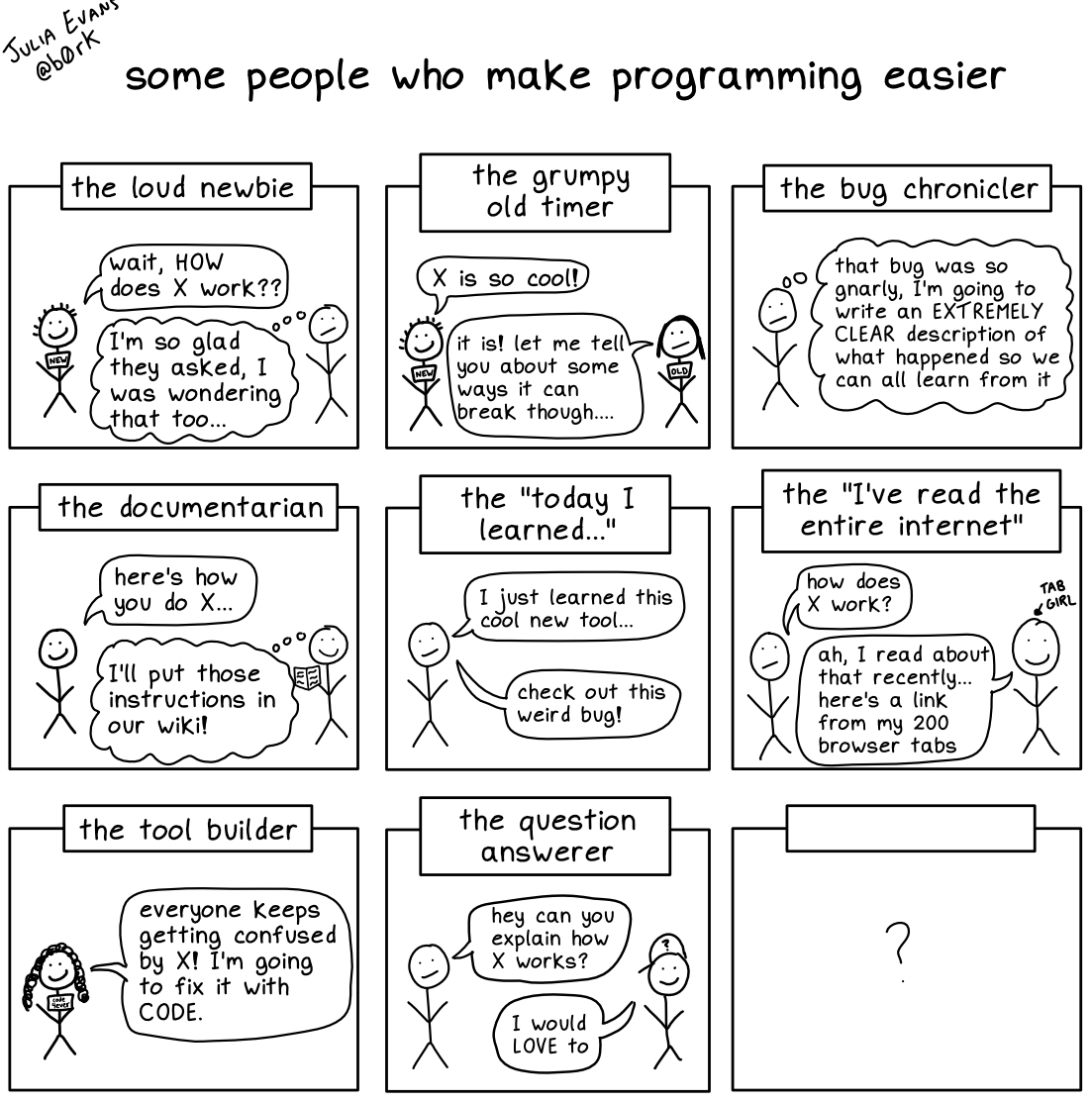
some people who make programming easier (who am I missing?) https://t.co/qp1xayvJw9
Another interesting short study. Finds that "Llama-2-70b is almost as strong at factuality as gpt-4, and considerably better than gpt-3.5-turbo." Need to take a closer at how evaluation is done but I already starting to see strong experimental results on Llama 2 for all kinds of summarization problems. Super exciting stuff! https://t.co/LWlC4B5Gat

Full fine tuning of 15B parameter LLMs on poor GPUs. Slow? who cares. Possible? of course it is https://t.co/uyjTOoBGN5
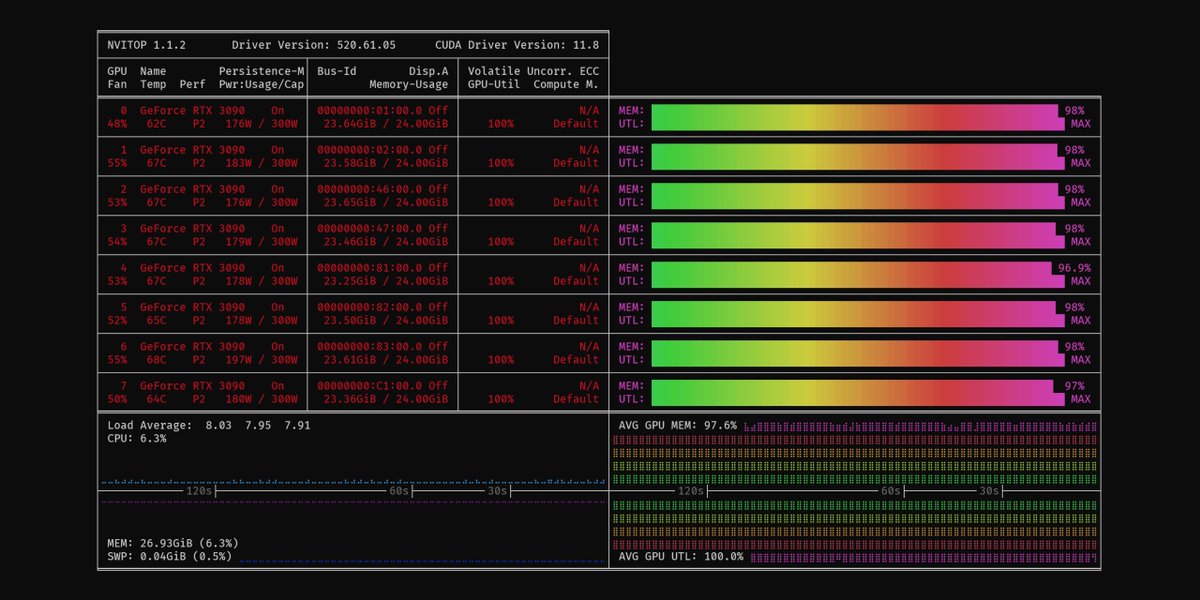

Wow, this study is devastating for cynicism. Here's a TL;DR: In studies 1–3, participants indicated they thought cynics would do better on cognitive tasks. In studies 4–5, cynics were tested and 1 SD of cynicism was associated with 0.25 and 0.17 SDs lower cognitive ability in studies 4 and 5, respectively. In study 6, cynics were found to be - less educated in 29/30 countries - less literate in 28/30 countries - less numerate in 29/30 countries - less computer-literate in 23/26 countries Cynicism is simply not smart. Source: https://t.co/fk77cy1TV3
A worldwide survey of 200k people finds cynical people are thought of as smarter... but that, in reality, cynics test lower on cognitive & competency tests. As Stephen Colbert said: “Cynicism masquerades as wisdom, but it is the furthest thing from it.” https://t.co/KLc33j4J
🔮 Real-time on demand generated text-to-video training and eduction videos completely flattened the memory requirements for understanding anything. In 1TB memory and a local non-cloud private AI few needed YouTube or even TikTok. No one understood in 2023—it was clear in 2025. https://t.co/McjZhDYRLc

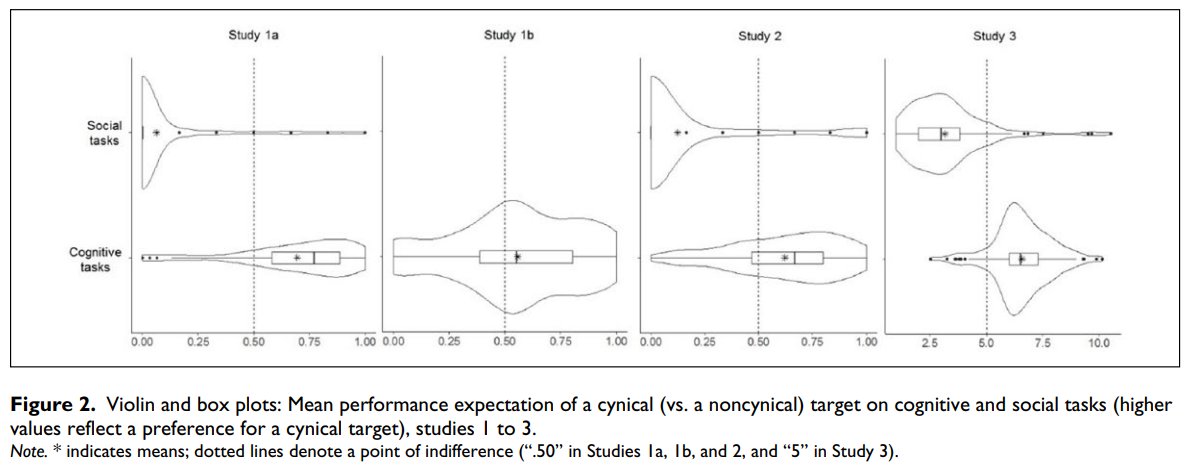
If you want to master any craft, read this: The 4 Stages of Competence model was created by Matthew Broadwell in 1969. It says we progress through stages when moving from total novice to expert at a given craft. The stages are as follows: 1. Unconscious Incompetence At this stage, you're a total novice and don't even know what you don't know. You lack competence and don't have an understanding of your own incompetence. 2. Conscious Incompetence Here, you've become aware of your own incompetence, but you haven't addressed it yet. You know that there's a gap in your skills that needs to be filled. 3. Conscious Competence At this stage, you've developed a level of competence at your craft, but it requires conscious effort and focus. You can do it, but it takes work. 4. Unconscious Competence This is the pinnacle of expertise, where you have extreme competence and can execute without conscious effort. Few people ever reach this stage. I visualize it most clearly as a hierarchy, with progress marked by a graduation up the pyramid from one stage to the next. This model is useful as a reflection tool for providing clarity about where we sit on a given skill or craft at any given moment. We tend to overestimate our own competency levels, so having a clear framework is helpful for cutting through the noise and delivering an honest personal assessment. To determine whether you've graduated from one stage to the next, here are some simple questions to ask: Stage 1 to Stage 2: • Am I aware of how bad I am at [X]? • Am I aware of what is required to learn and develop at [X]? Stage 2 to Stage 3: • Can I do [X] at a consistently average level? • Have I avoided "rookie mistakes" the last 10 times I have done [X]? Stage 3 to Stage 4: • Can I do [X] at a top-1% level with my eyes closed? • Do people tell me that I look effortless when doing [X]? Most of us will spend our lives in Stage 3, where we can create results with effort. But to reach Stage 4, we need to engage in deep, deliberate, focused practice. Our brains have myelin, a fatty tissue that insulates our neurons and greases them for proper firing. Stage 4 is where countless hours of effortful practice result in more myelin, allowing us to execute with ease. Stage 4 is the level of Sprezzatura—studied nonchalance, earned effortlessness. It's a state we can aspire to, but few will achieve across more than 1-2 areas in our lives (at best). As you progress in any new endeavor or craft, use the 4 Stages of Competence to reflect on your growth. If you enjoyed this or learned something, follow me @SahilBloom for more in future!
Just dropped Style Pack 2: Psychedelic 🌈 These 4 mind-bending 360° styles break the mold for what you expect out of a skybox. Wildly imaginative, artistic, & unexpected, these styles are amazingly fun to play with! Get creating at https://t.co/GHiX51beXA #skyboxai #trippyart https://t.co/Uzy3AuxlPz
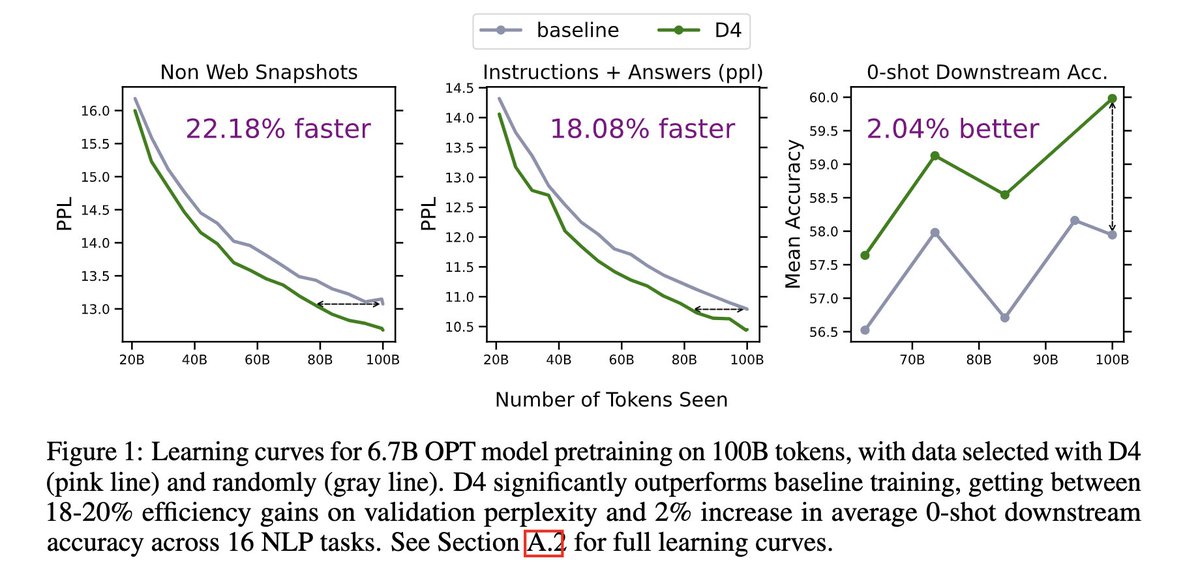
Excited to release our work in data selection for LLM pre-training! We introduce a new data selection method for large-scale web data (D4) which gets ~20% efficiency gains & +2% downstream acc @ 6.7B scale over the current standard of randomly sampling Minhash deduped web docs https://t.co/imH9K5rSfx
Asked GPT-4 to remove unnecessary boilerplate from a message from my bank (@Chase), and it reduced its length by 85%. This tells us a lot about the power of AI. And about Chase. https://t.co/KofxlZtwxh

We now have embedding finetuning: optimize your retrieval performance🔥 The underrated piece: retrieval evals are a big pain point in building RAG. We have auto QA dataset generation capabilities from text that you can use for finetuning AND evals. 📗: https://t.co/KRO8taBgt6 https://t.co/tP9nYzgZ2q

As an LLM practitioner, it's surreal to witness the vast range of applications LLMs are powering. I am observing the high use of LLMs to extract actionable insights from internal knowledge bases and all kinds of data sources. Common enterprise tasks include custom chatbots and complex summarization capabilities to support advanced research assistants and analytics. I am amazed that we can build these powerful LLM-powered solutions today without touching a line of code. If you are interested in this space, I highly recommend you check out this upcoming workshop: https://t.co/v19zmTYmyE It will cover: - Use custom data transformers, vector stores, and custom user-code modules - Call out to any LLM (GPT-4 or fine-tuned by Abacus) - Chain data, user-code, and LLM modules together - Deploy into production and monitor usage

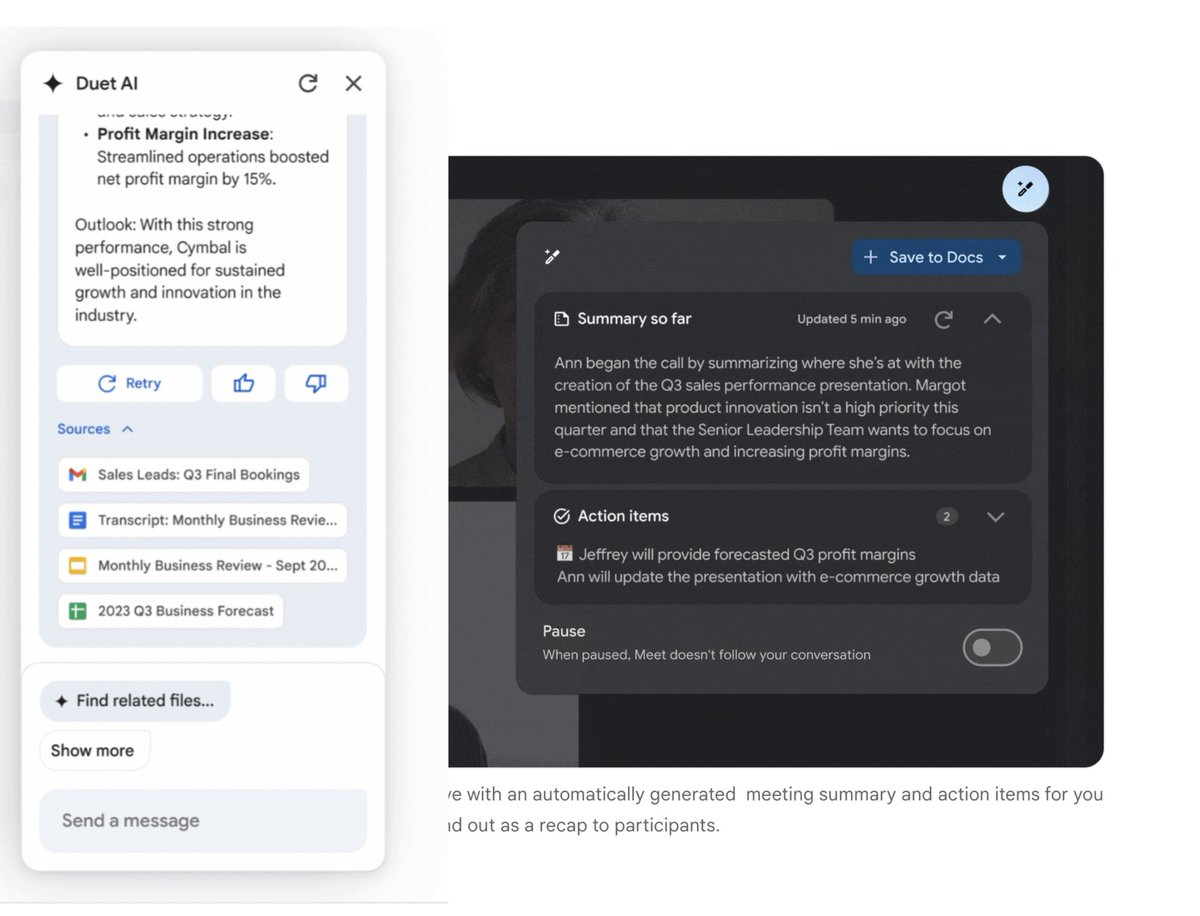
I guess we can consider millions of startups with meeting summarisation dead @Google just dropped a Duet tool ~summarize ~search ~get action items ... inside your google suit docs turns out @Scobleizer was right after all?
Introducing Claude-2 by @AnthropicAI, now on Perplexity Pro. Update your settings now: https://t.co/QM2YqxTpxQ Here's what Claude-2 brings to you: 🗂️ Deeper Research: Longer context and larger files up to 25MB. ✍️ Better Writing: More natural and readable content. ⚡️ Quick Answers: Human-like responses with Quick Search and Copilot. Enabling Claude-2 on Perplexity is another step towards offering our users the world's best research assistant: providing access to Anthropic's models designed for maximum utility and safety. Try it out by activating Claude-2 in your Perplexity Pro settings now.
📣 Autoblocks is now available to everyone! We built Autoblocks to help teams *improve & differentiate* their LLM products. If you’re building with LLMs, here's how Autoblocks can be your secret weapon: https://t.co/TOmOZ1rpjK
This is Huge! 🥳 Half of the conversations around LLMs are “Will this fit on my GPU[s]?” And this calculator makes it much easier. There are some important nuances for LoRA and I took notes on that here: https://t.co/Bct28Wwhea https://t.co/MilXje5IVB
Excited to announce a new @huggingface space to help with one of machine learning's biggest questions: How much space does {X} model take in vRAM? And most importantly: when using `device_map="auto"` https://t.co/kmQCuPeAdM https://t.co/b2xQRreucD


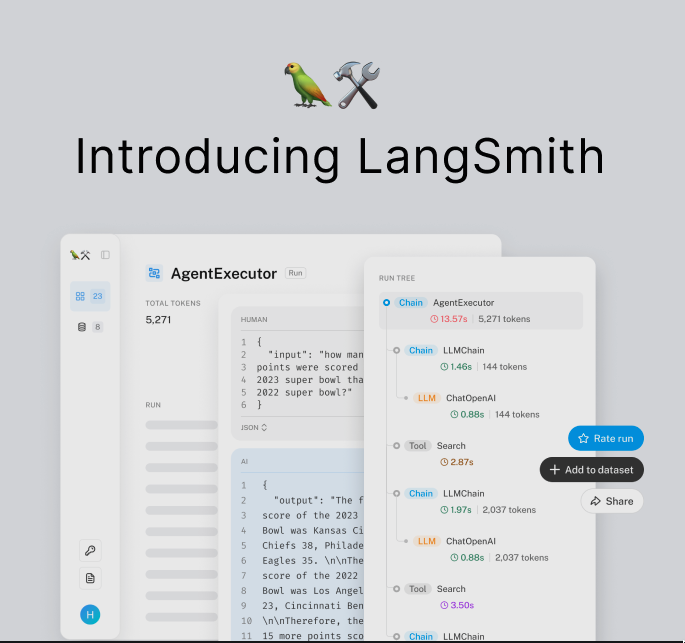
Are you using @LangChainAI but it is difficult to Debug? Not anymore with LangSmith It makes tracing each LLM call very easy and intiutive. It's like looking under the hood of system. After getting beta access, I explored it over last week & below are my 🔑 take aways: 🧵
From @seb_ruder’s NLP News - Exploring tool use Language models “are limited to producing natural language, which does not allow them to interact with the real world. This can be ameliorated by allowing the model to access external tools—by predicting special tokens or commands. [..] a tool can be an arbitrary API.” https://t.co/f07q86rkny

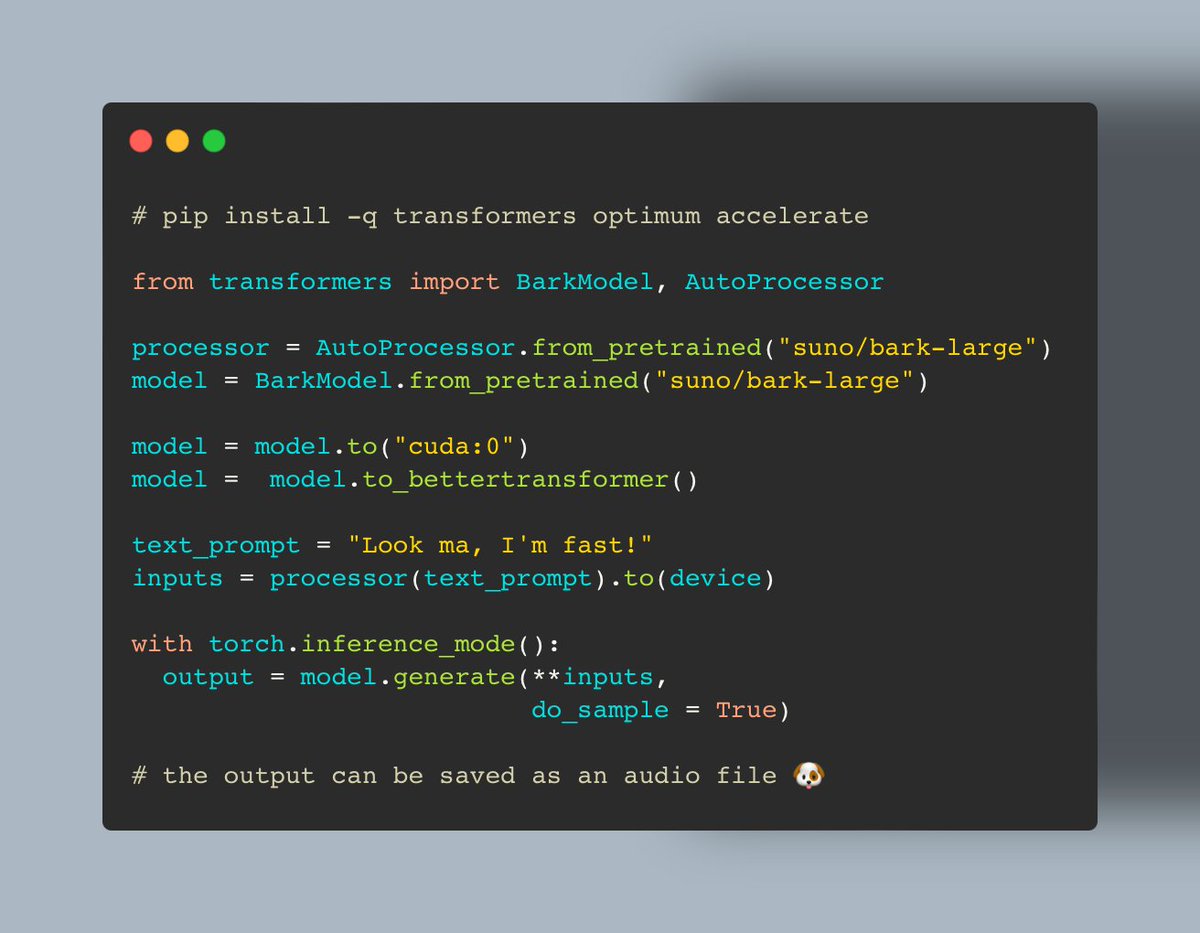
Want blazingly fast TTS with bark 🐶? Good news: we made it ~2X fast ⚡️ Powered by 🤗 Transformers & Optimum! 👇
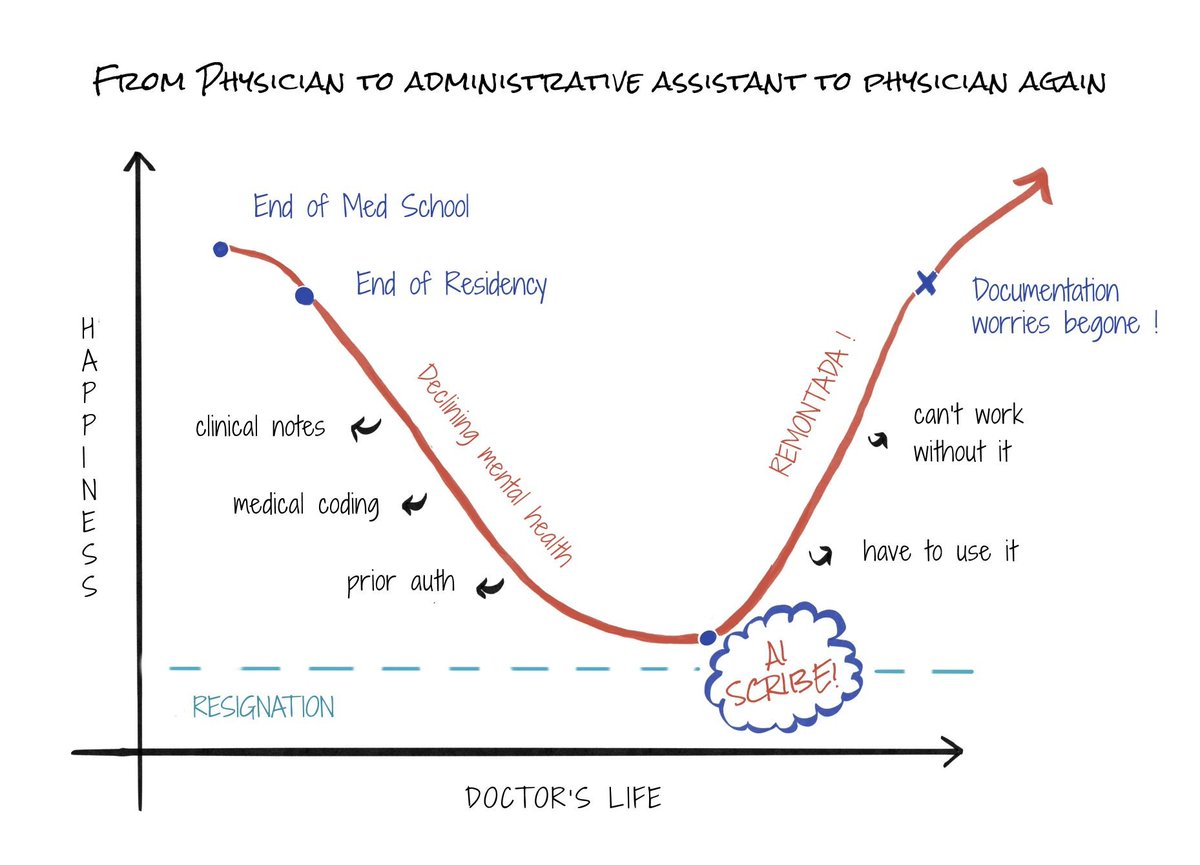
From physician to administrative assistant to physician again. https://t.co/zHDtUTtktF
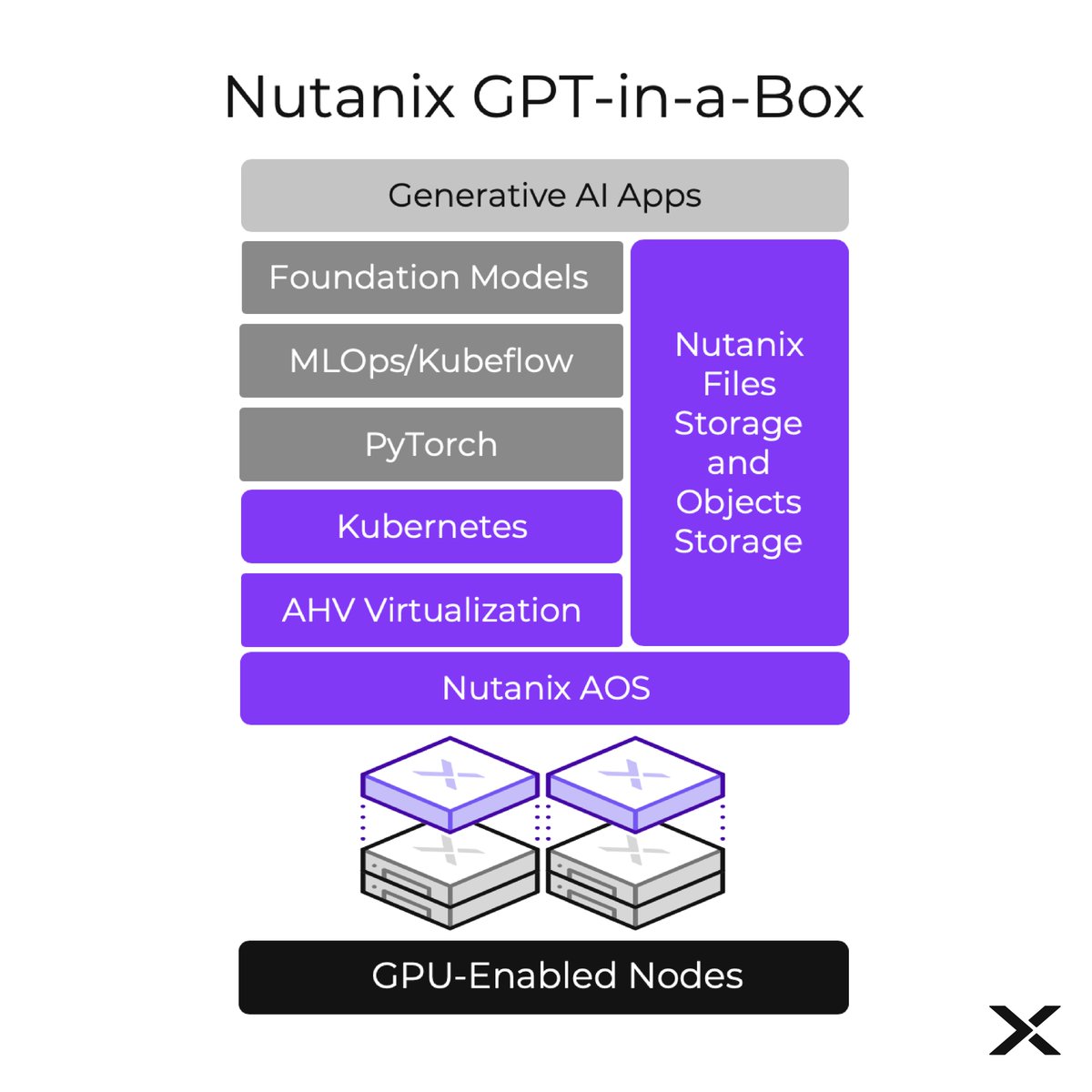
[Breaking News] #GenerativeAI adoption just got a lot simpler! New Nutanix GPT-in-a-Box Solution enables customers to jump-start #AI innovation while maintaining full control over their data. Details: https://t.co/z63XRuJ1W2 https://t.co/9Qqb4caQMX
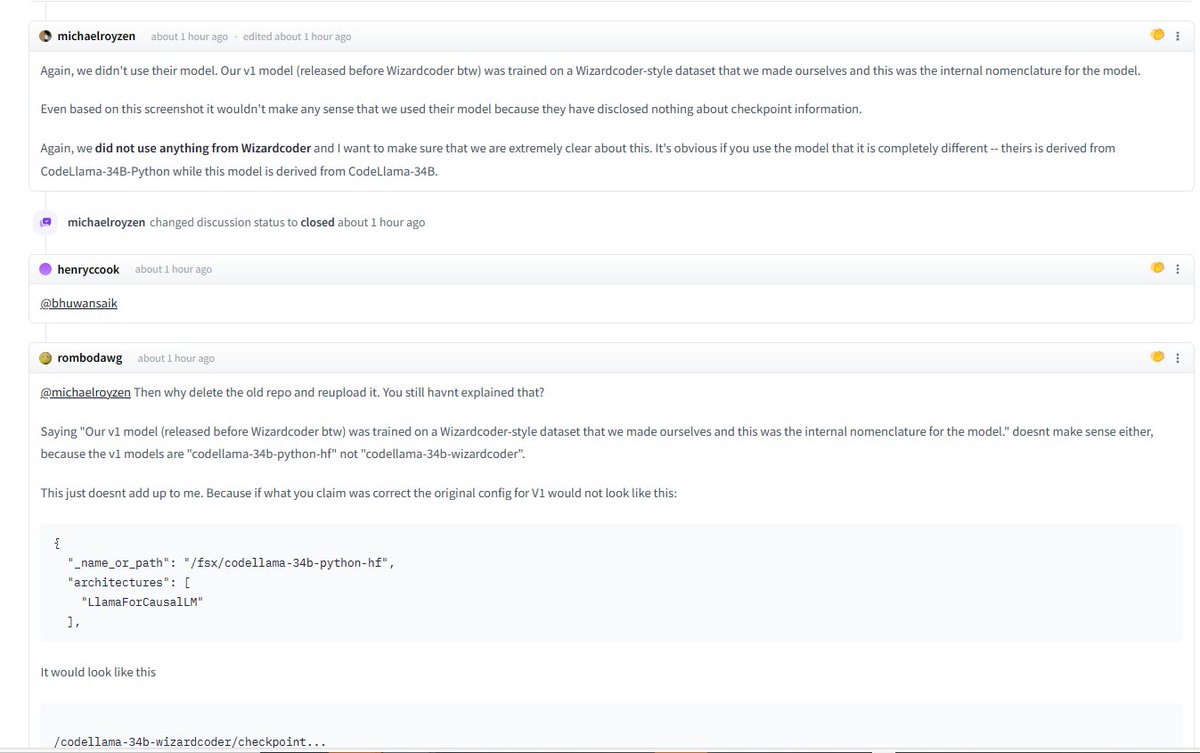
💥💥 Wow ! We are happy to know that Phind-CodeLlama-34B is also a "WizardCoder".☺️ As @phindsearch claimed, they used a WizardCoder-style dataset to train their V1 model. And they may continue train WizardCoder to get their V2 model. But there is no need to delete the comments or even the whole repo ... we fully welcome to use our method or model to enhance your LLMs and let's enjoy the benefits of the AI revolution together! ❤️
Oh shit, new github co-pilot updates! They stole cursor's UI!! Now includes the terminal in context! And 8k context window! Only in Visual Studio though... (i think???) Not VScode :( https://t.co/arznYNWiA3

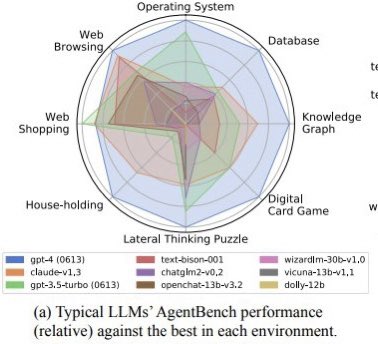
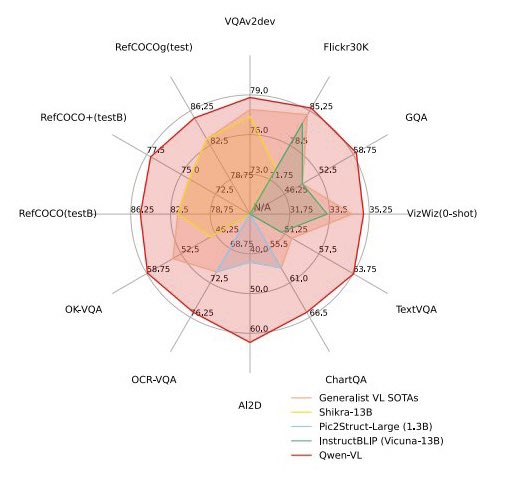
Please no more radial plots! • linear improvement, but area grows quadratically ➡️ overestimate perf • hard to label axis ➡️ no quantitative use • overlapping colors ➡️ poor accessibility consider a bar chart or a table instead 🙏 https://t.co/NrztmjDRVn
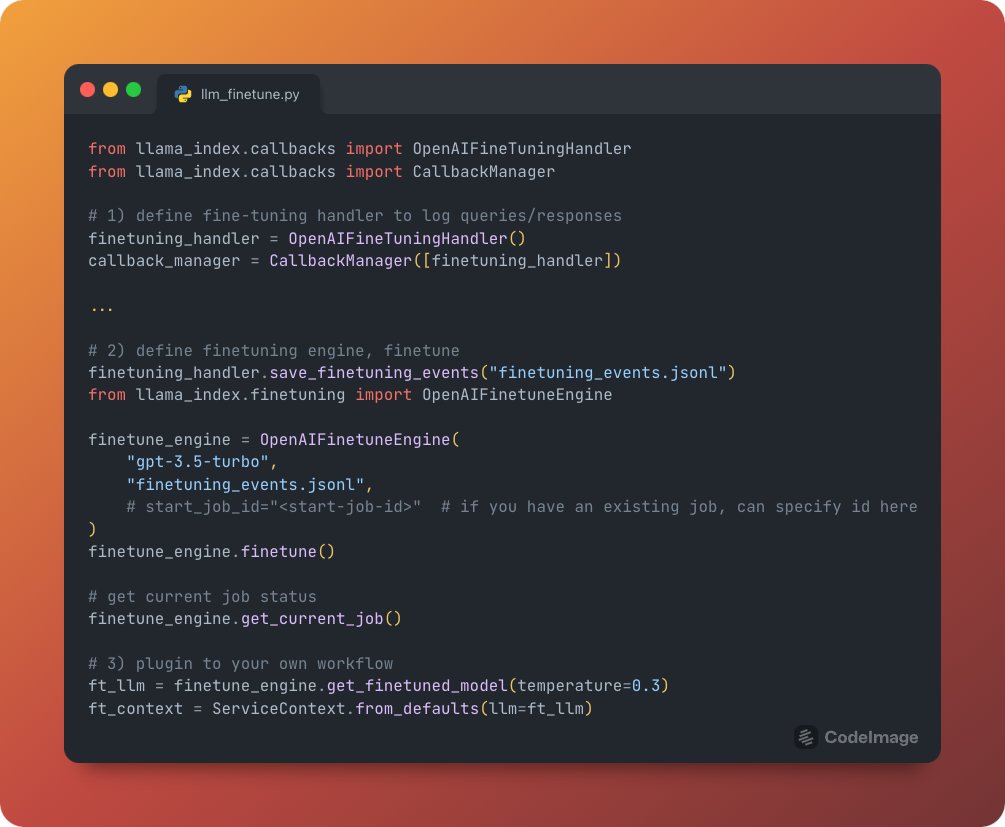
Our latest release: LLM Finetuning Abstractions 🔥 We provide abstractions on top of @OpenAI’s finetuning API that makes it seamless to plugin a fine-tuned model with your RAG app in @llama_index. Can also easily distill another LLM to gpt-3.5-turbo: https://t.co/ETLaln1N8a https://t.co/wR1KFGPCnC
🎓ML Papers of The Week (August Edition) ICYMI, we highlight some of the top trending ML papers every week. This is now used by 1000s of researchers and practitioners to follow and discover trending papers and AI topics. The August collection is now finished! We also add quick summaries of the papers and work with our community to write explainers for outstanding papers. We use a combination of AI-powered tools, analytics, and human curation to build the lists of papers. Check it out here: https://t.co/Ffrj4b12zX