Your curated collection of saved posts and media
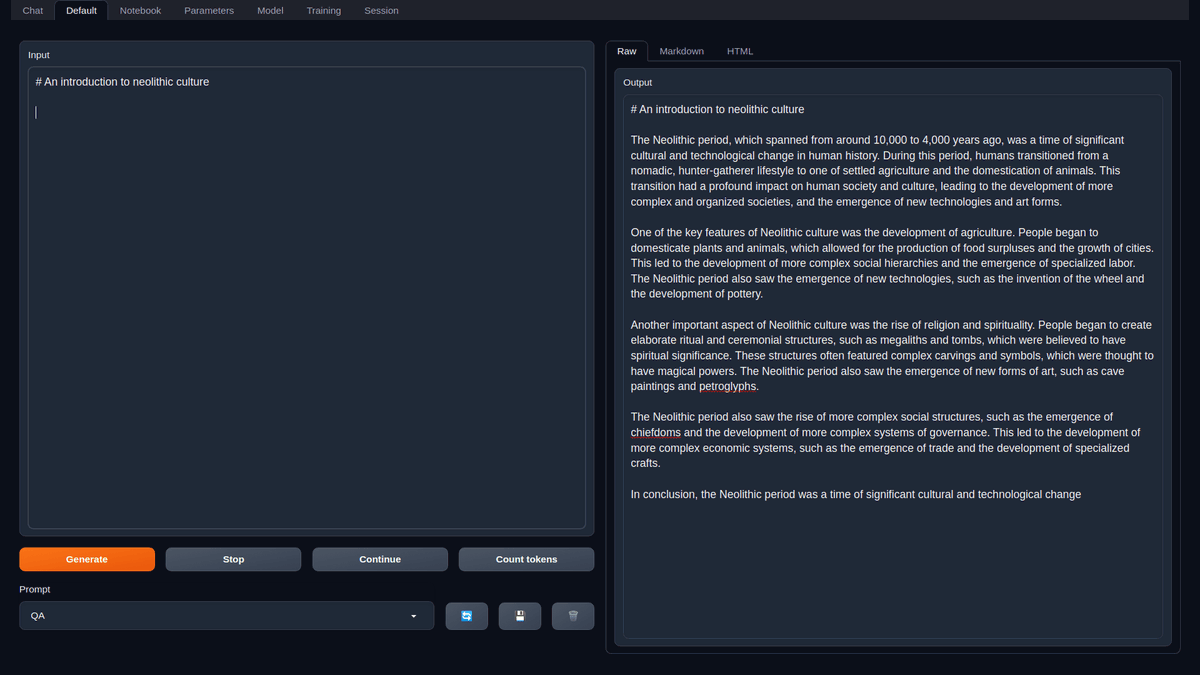
When do you *really* need to use a vector database? 🤔 To try answer that question, I recreated my semantic image search application to run 100% in-browser with Transformers.js (no server). After loading the model and database, it only takes ~50ms to compute text embeddings and perform similarity search across 25k images. No vector DB, just plain old JavaScript. I think @karpathy was onto something... 👀 What do you think? 🔗 Demo site: https://t.co/CQSmghjdqd ⌨️ Source code: https://t.co/cOBDFni0k7
@sinclanich np.array people keep reaching for much fancier things way too fast these days
I'm starting a curated list of interactive machine learning demos: https://t.co/mILPILzSX9. Looking for more suggestions! My plan is to incorporate some into the ML modules of Cambridge's new MPhil in Data Intensive Science, as a way to hone students' intuition. https://t.co/Ab5LKiYCQM
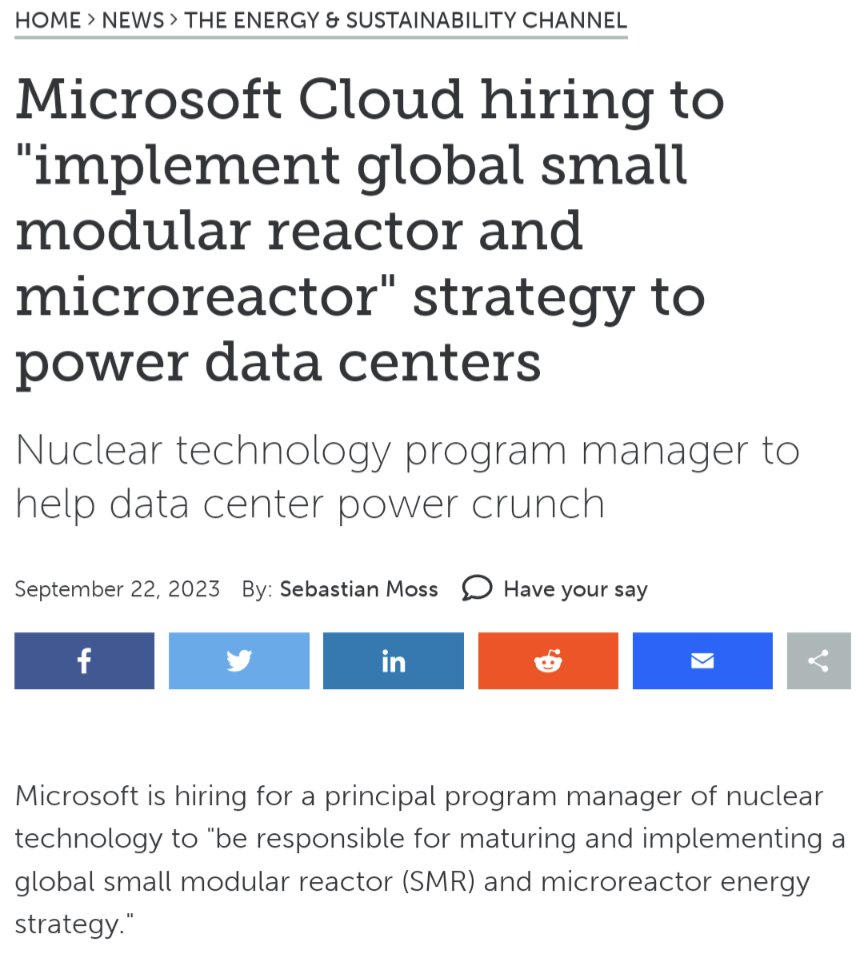
Word is out: Microsoft is plunging ahead on nuclear energy. They want a fleet of reactors powering new data centers. And now they're hiring people from the traditional nuclear industry to get it done. Why? Lack of stable long-term power, whether clean or dirty, is constraining Microsoft's growth. They need to build big data centers that consume electricity all the time and the old assumption that somebody else's reliable plants will always be around to firm up your wind and solar is falling apart. It certainly helps that founder Bill Gates was one of the earliest big business converts to nuclear energy, investing his own money to develop new reactors. But Microsoft, like many companies, was held back by what we might consider "Enron-ism" infecting its energy thinking: renewable energy credits plus markets plus cute little lies to the public about how electricity works. Greenwashed fossil/hydro/nuclear with the ESG stamp of approval. The problem? Eventually you run out of other people's cheap firm power. So Microsoft has recently become a leader in openly asserting that nuclear energy counts as clean energy, as opposed to the ongoing cowardice we see from the other big tech companies who lie to the public about being "100% renewable powered." Sure, the lawyers said it was okay to lie, but the lie doesn't give you a permanent supply of cheap reliable energy. That comes from nuclear. A world is coming where only the tech companies willing to become nuclear power developers may get to keep expanding their cloud businesses, and only countries open to new reactors get to host this expansion. A world where tech companies with 50% margins become the only survival hope for traditional industrial concerns with 5% margins who need someone else to bootstrap a proper electricity supply. Where diesel backup generators are replaced with microreactors reliable enough to be trusted to keep a cluster of facilities secure in the case of public grid failure. The race is on.
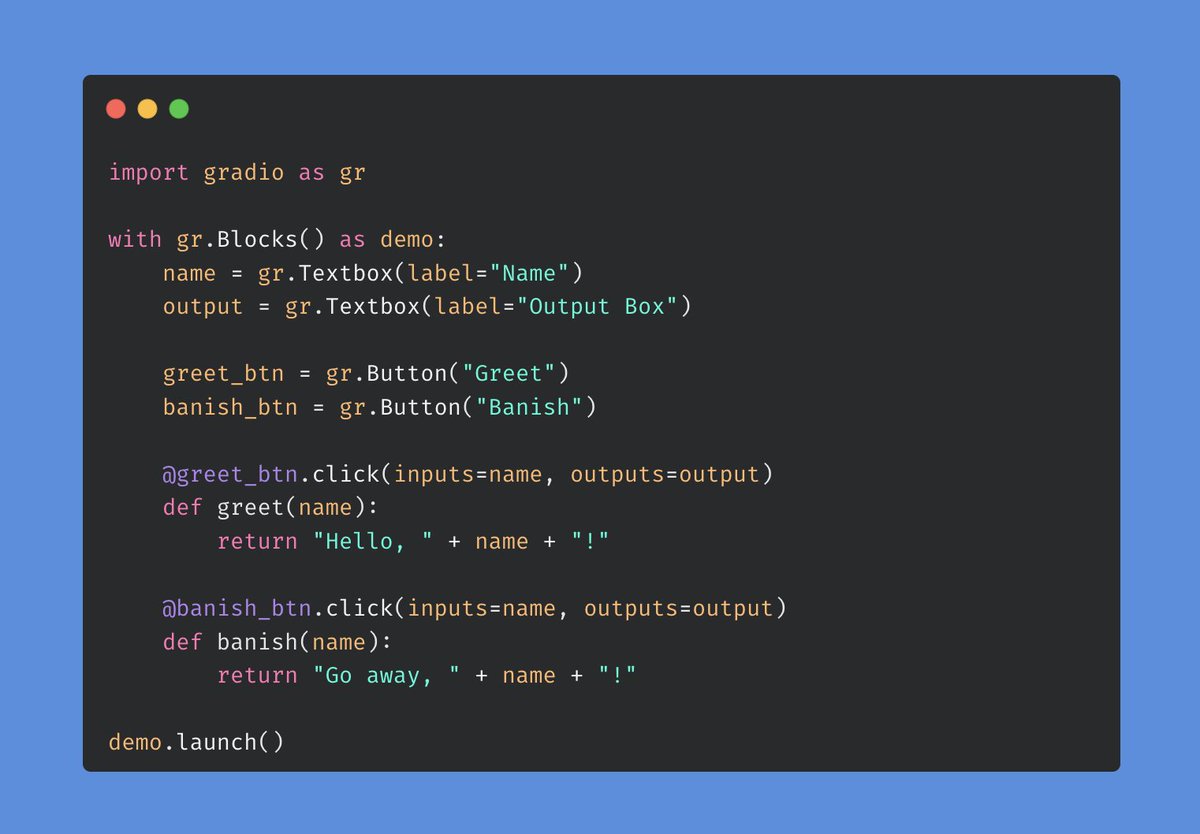
💥 3.42.0 💥 Lots in this release, so we wanted to get it out before the weekend for y'all ⚒️ 🤖 Upvote / downvote Chatbot messages (and many other chatbot improvements...) 🤳 New controls for Model3D component 🎆 A new decorator syntax for events (see below)! much more! https://t.co/gdBDl8sqhA
🌪️ Despite the ongoing super Typhoon Saola in Hong Kong, I'm excited to introduce PointLLM! 🌈🔍 It's a multi-modal large language model that understands point clouds. 1/4🧵 🔗 Demo: http://101.230.144.196 📄 Paper: https://t.co/nSbUkqUaV4 💻 Code: https://t.co/SX7r3ClzX3 https://t.co/qvoCBdyqOB
🤖 Produce realistic movements with #AI Avatars. 🍵 Stay CALM and code on. 📥 The #NVIDIAResearch paper and code are now available. https://t.co/g90tftbk07 https://t.co/JVjRlcJgmF
I think GPT 4 does OK -- I mean, it's not Provost, but it's probably better than me (and I'm not bad; I've been published in a few notable places). I asked for "what it's like to be stuck in a tree, from the point of view of a cat who once found themselves in that predicament" https://t.co/o6kQ3nzhVd
A good test for AI is whether it can write something of this quality. Not just monotonic information conveyance, but taking the reader on a journey. https://t.co/hVBv7Runbs

Happy 2nd birthday to ChatGPT's knowledge cutoff! 🎂 https://t.co/O1cgRPSP3l

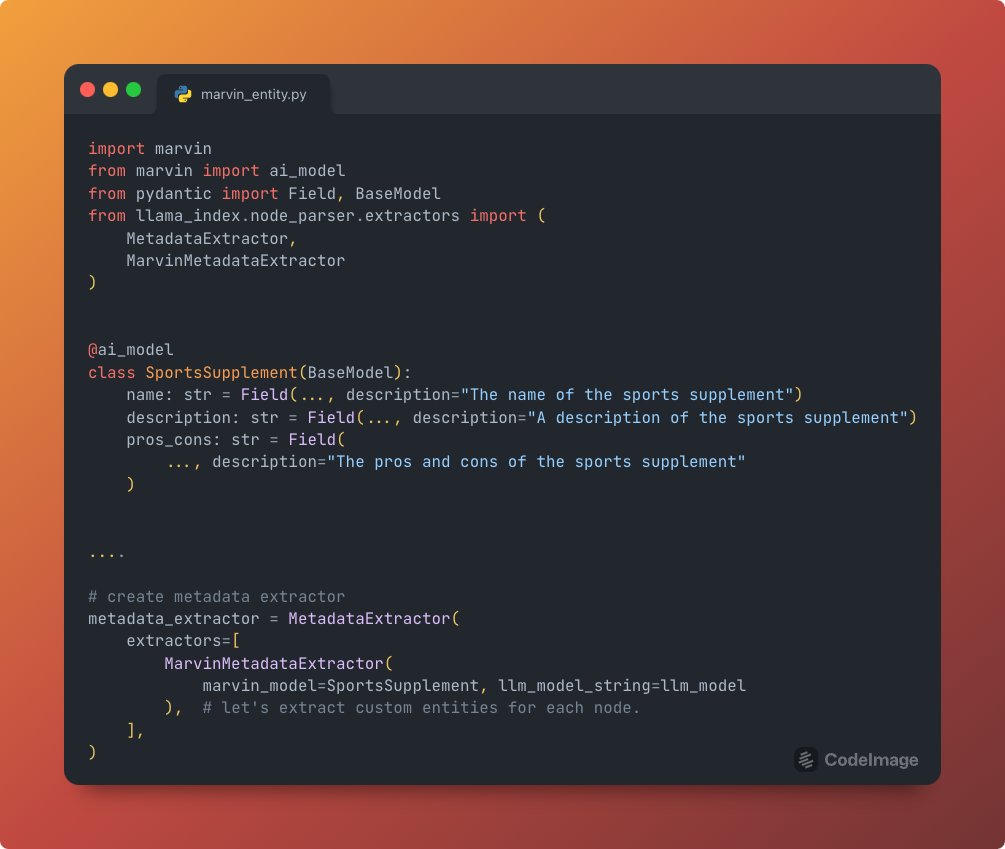
We’re excited to integrate @AskMarvinAI for automated metadata extraction from any text corpus. Simply add an annotation to a Pydantic model, and log metadata from *all* text chunks with that schema. Can use on its own or e2e for better RAG pipelines: https://t.co/jVLi64RB5G https://t.co/2CSW17jP9f
ChatGPT for Research 🤯 ChatGPT now has Consensus plugin which can answer any questions from its database of 200 miilion+ research papers. Now don't just rely on any answer, get logical answers backed by research directly within the ChatGPT interface. https://t.co/uoO1jmiaQB
The Belebele Benchmark: a Parallel Reading Comprehension Dataset in 122 Language Variants paper page: https://t.co/IdwalRMXUq present Belebele, a multiple-choice machine reading comprehension (MRC) dataset spanning 122 language variants. Significantly expanding the language coverage of natural language understanding (NLU) benchmarks, this dataset enables the evaluation of text models in high-, medium-, and low-resource languages. Each question is based on a short passage from the Flores-200 dataset and has four multiple-choice answers. The questions were carefully curated to discriminate between models with different levels of general language comprehension. The English dataset on its own proves difficult enough to challenge state-of-the-art language models. Being fully parallel, this dataset enables direct comparison of model performance across all languages. We use this dataset to evaluate the capabilities of multilingual masked language models (MLMs) and large language models (LLMs). We present extensive results and find that despite significant cross-lingual transfer in English-centric LLMs, much smaller MLMs pretrained on balanced multilingual data still understand far more languages. We also observe that larger vocabulary size and conscious vocabulary construction correlate with better performance on low-resource languages. Overall, Belebele opens up new avenues for evaluating and analyzing the multilingual capabilities of NLP systems.

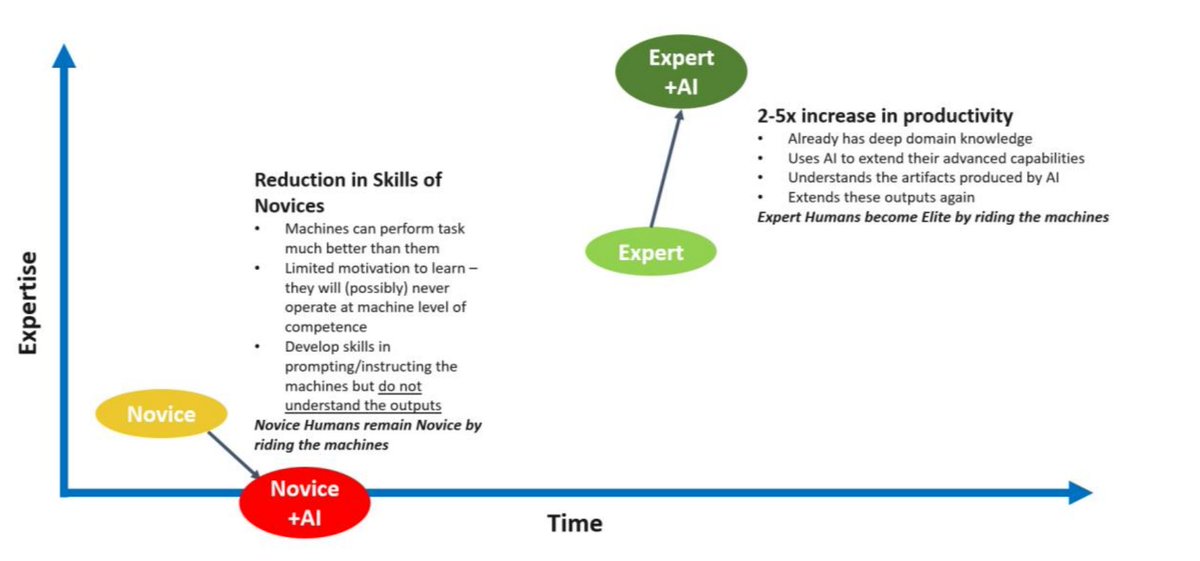
This is THE most important graph in AI right now. I was talking to a CEO who said we shouldn't teach persuasive writing because AI will write for us. He couldn't be more wrong. Without skilful input and wise curation, AI won't take you anywhere worth going. Want to use AI to write? You need to learn about writing. Read books. Watch videos. Listen to podcasts. Level up. Build your skill. Become an expert. You will be unstoppable with AI. Graph from The Future of AI in Education: 13 Things We Can Do to Minimize the Damage Arran Hamilton @dylanwiliam @john_hattie
Nature scenes, text to video AI by @morphaistudio https://t.co/XfDG3UlHR5
BioCoder: A Benchmark for Bioinformatics Code Generation with Contextual Pragmatic Knowledge paper page: https://t.co/4iLlIsjCZo Pre-trained language models like ChatGPT have significantly improved code generation. As these models scale up, there is an increasing need for the output to handle more intricate tasks. Moreover, in bioinformatics, generating functional programs poses additional notable challenges due to the amount of domain knowledge, the need for complicated data operations, and intricate functional dependencies between the operations. Here, we present BioCoder, a benchmark developed to evaluate existing pre-trained models in generating bioinformatics code. In relation to function-code generation, BioCoder covers potential package dependencies, class declarations, and global variables. It incorporates 1026 functions and 1243 methods in Python and Java from GitHub and 253 examples from the Rosalind Project. BioCoder incorporates a fuzz-testing framework for evaluation, and we have applied it to evaluate many models including InCoder, CodeGen, CodeGen2, SantaCoder, StarCoder, StarCoder+, InstructCodeT5+, and ChatGPT. Our detailed analysis of these models emphasizes the importance of domain knowledge, pragmatic code generation, and contextual understanding.

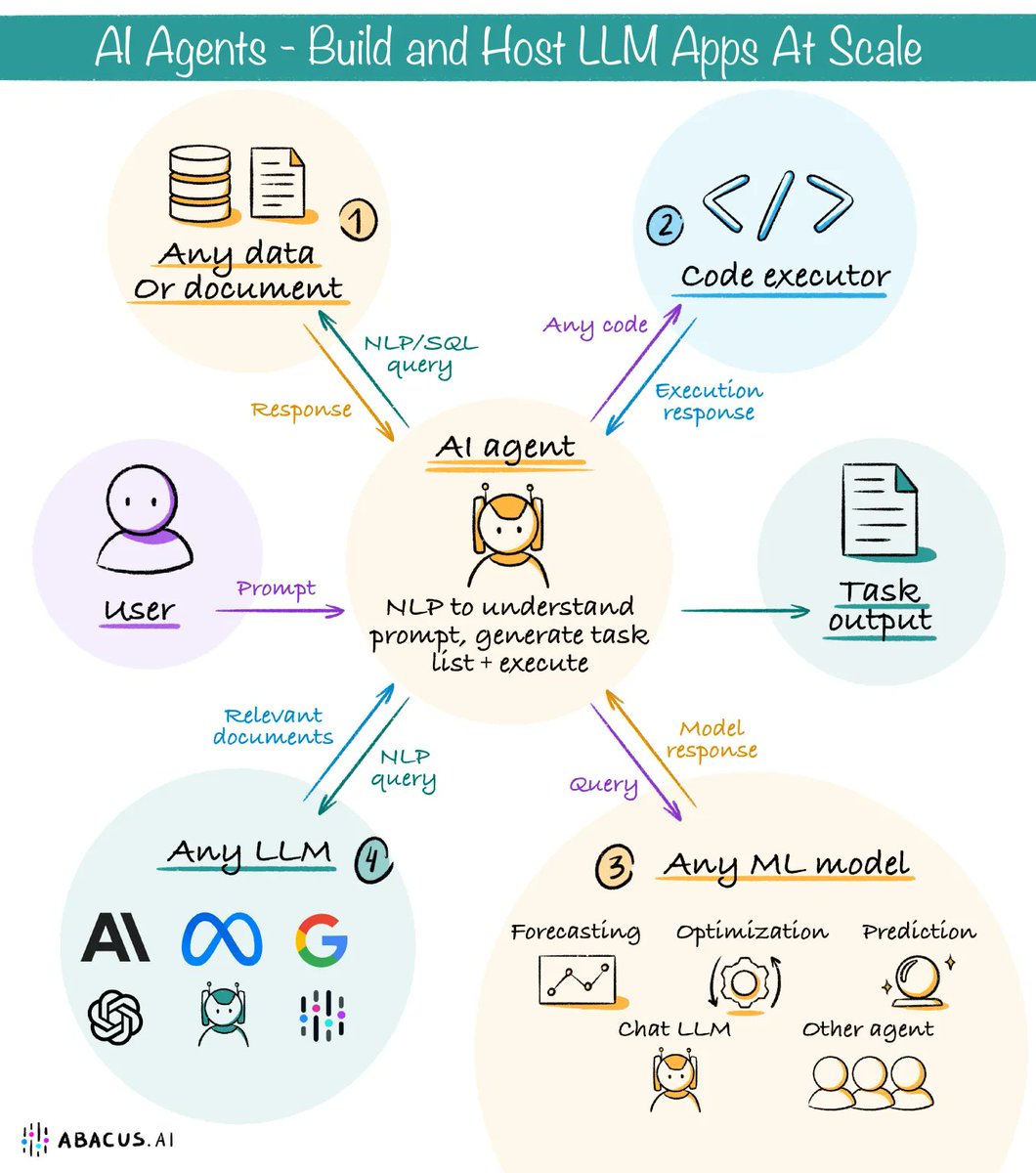
LLM-based Autonomous Agents - LLM Apps that perform Human-like Tasks The real promise of Large Language Models is their decision-making, reasoning, and human-level cognition skills. AI agents are LLM apps that can be used to perform a specific task - e.g. respond to customer service queries or summarize and extract key terms in a contract To create and run an AI agent, you need a robust platform that ideally has all of these modules Data connectors: You will need to access your data so the LLMS can analyze it and make decisions. Ideally, you need connectors to Snowflake, BigQuery, Salesforce, Confluence, Sharepoint, and such. Data transformations and processing: Every data scientist knows that the raw data is useless and there is always data pre-processing and data cleaning involved. With text documents, OCR (object character recognition) and document chunking are essential steps before you can feed the data into LLMs Prompt engineering: Unfortunately today's LLMs need a significant amount of prompt engineering to perform a particular operation. For example, you will need to prompt it to "think step by step" or "act like you are an expert data scientist". Code execution: It's impossible to write a complex application without writing and executing code. You will want to write Python functions to parse LLM output, engineer LLM context, or apply some routing logic Chaining and Pipelines: Most of these apps will require a pipeline. As an example - a simple app that "extracts key terms from all contracts and stores them in a database table" involves a process that picks up new contracts on a regular basis, applies OCR, chunks the contracts, sends them to the LLM, parses the output and then updates the database. There are a number of steps involved and they can be automated with a pipeline Simpler agents won't require a pipeline but may require chaining multiple LLM calls and executing code to process their outputs. Machine learning models: This is an optional step but you may want to train ML models on some of your data. For example, you may train a forecasting model and then process the forecasts using an LLM UX interface: Some agents (e.g. customer service agents) may be deployed as chatbots. In this case, you need a ChatGPT-like interface for each of your users. You need to save, thread, and collect feedback from chats. To create and deploy these AI agents, we need connectors, data transformers, code execution machines, pipelines, multiple system prompts, and a chatbot interface. An end-to-end LLMOps platform like Abacus, helps you create powerful Agents in a couple of hours. Read more here - https://t.co/NcUcS2YZba
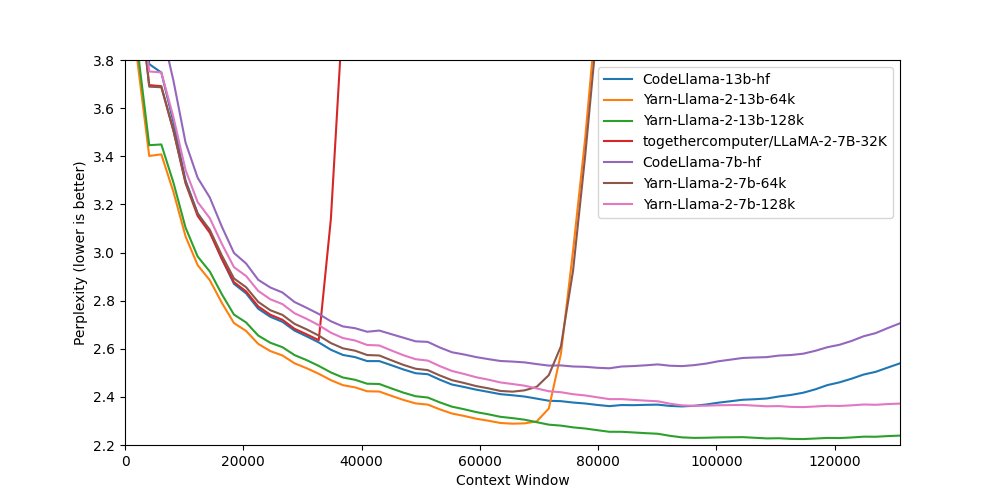
Releasing Yarn-Llama-2-13b-128k, a Llama-2 model, trained for 128k context length using YaRN scaling. The model was trained in collaboration with u/bloc97 and @theemozilla of @NousResearch and @Void13950782 of @AiEleuther. https://t.co/CmvZgHdJEF
This is amazing. PanoHead is a new model that generates 3D textured models from a single image. Github: https://t.co/KcrPxP3ga7 Paper: https://t.co/JGkIbLLIWx https://t.co/dnJFzyn4gm
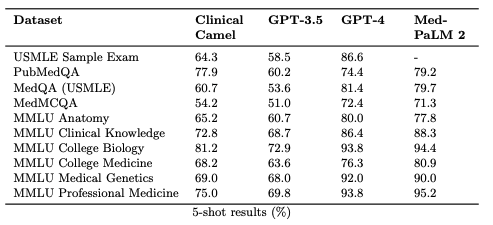
**Updating the best open-source medical LLM** 🚀 Introducing Clinical Camel-70B, one of the best open-source medical Large Language Models for clinical research! Based on the new #Llama2-70B model from @MetaAI, our Clinical Camel-70B can surpass proprietary models like GPT-3.5 in medical benchmarks! See our paper: https://t.co/MduOM2GcwP 💡 Developed with QLoRA, Clinical Camel-70B excels in medical Q/A benchmarks, and its 4096 token context limit opens doors to diverse applications. 🏥 Beyond Q/A, Clinical Camel automates clinical note generation from patient-doctor conversations, a game-changer for healthcare. 🌐 We're sharing Clinical Camel-70B to promote transparency and collaborative research, paving the way for safe LLM integration in healthcare. We're democratizing AI in healthcare. ⚠️ Challenges remain, including safety, outdated knowledge, and biases. But Clinical Camel bridges the gap between proprietary and open medical LLMs. 📥 Download Clinical Camel now on Hugging Face: https://t.co/2igB86nybr #AIinHealthcare #ClinicalCamel #HealthTech 🧬🏥🤖 Shoutout to the amazing student, Augustin (@ugustintoma) for leading this project! @drbarryrubin @VectorInst @UofTCompSci @UofT_LMP @UHNAIHUB @bradwouters @KevinSmithUHN @pmcc_ai
Introducing Kay -- Data API built for RAG 🕵️ We are curating the world's largest datasets as high-quality embeddings so your AI agents can retrieve context on the fly. Latest models, fast retrieval, and zero infra. Today, we are launching Company Embeddings 🏦 https://t.co/RPFktKYV7F
Transformed my photos into movie magic with #Image2Video by @fffiloni 🎬✨ Kudos to @huggingface ! Explore at https://t.co/gXCUz28Z2k https://t.co/L9NWqqTsO1

#MachineLearning Research How you feelin'? EmoTx: Learning Emotions and Mental States in Movie Scenes 👇 https://t.co/60QWFxmKxA ------------------------------------ Emotional #AI is making more and more progress and can prove beneficial depending on its use cases... but do we really want AI to control our emotions? #AIEthics Cc @psb_dc @Miad @SpirosMargaris @jblefevre60 @BroadenView @AkwyZ @roxananasoi @Nicochan33 @enilev @CurieuxExplorer @jeancayeux @ahier @data_nerd @sallyeaves @PawlowskiMario @ChrisGGarrod @kalydeoo @dcallahan2 @3itcom @efipm @dinisguarda

A Survey on LLM-based Autonomous Agents Great repository containing a collection of papers on LLM-based autonomous agents. The survey paper for this came out a few days ago as well. repo: https://t.co/M0tFQlMOS7 paper: https://t.co/21eU6JikFJ
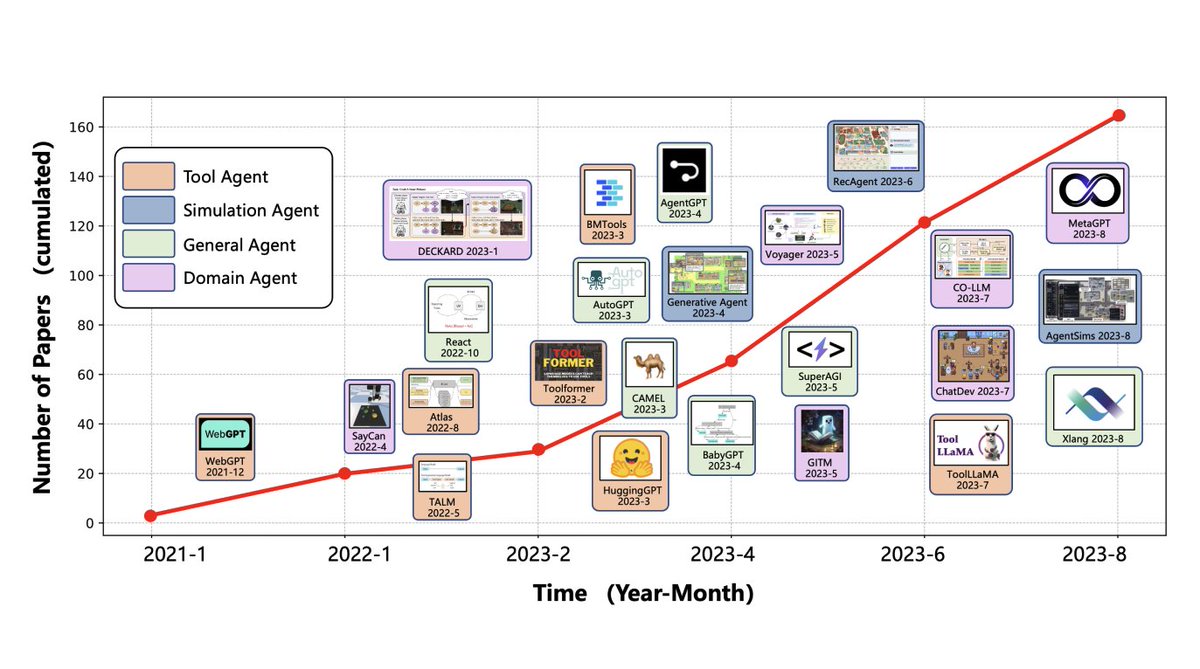
You made your own training script but don't have resources to train? No worries! Now you can train custom scripts on HuggingFace Spaces Backend using AutoTrain's SpaceRunner! 💥 The training starts instantly and upon completion, the space is paused saving lots of $ 🤑 1/N https://t.co/z0HSICLMcA
Learning Vision-based Pursuit-Evasion Robot Policies paper page: https://t.co/auY1DmnJ31 Learning strategic robot behavior -- like that required in pursuit-evasion interactions -- under real-world constraints is extremely challenging. It requires exploiting the dynamics of the interaction, and planning through both physical state and latent intent uncertainty. In this paper, we transform this intractable problem into a supervised learning problem, where a fully-observable robot policy generates supervision for a partially-observable one. We find that the quality of the supervision signal for the partially-observable pursuer policy depends on two key factors: the balance of diversity and optimality of the evader's behavior and the strength of the modeling assumptions in the fully-observable policy. We deploy our policy on a physical quadruped robot with an RGB-D camera on pursuit-evasion interactions in the wild. Despite all the challenges, the sensing constraints bring about creativity: the robot is pushed to gather information when uncertain, predict intent from noisy measurements, and anticipate in order to intercept.
LM-Infinite: Simple On-the-Fly Length Generalization for Large Language Models paper page: https://t.co/FUbIEu59vs In recent years, there have been remarkable advancements in the performance of Transformer-based Large Language Models (LLMs) across various domains. As these LLMs are deployed for increasingly complex tasks, they often face the needs to conduct longer reasoning processes or understanding larger contexts. In these situations, the length generalization failure of LLMs on long sequences become more prominent. Most pre-training schemes truncate training sequences to a fixed length (such as 2048 for LLaMa). LLMs often struggle to generate fluent texts, let alone carry out downstream tasks, after longer contexts, even with relative positional encoding which is designed to cope with this problem. Common solutions such as finetuning on longer corpora often involves daunting hardware and time costs and requires careful training process design. To more efficiently leverage the generation capacity of existing LLMs, we theoretically and empirically investigate the main out-of-distribution (OOD) factors contributing to this problem. Inspired by this diagnosis, we propose a simple yet effective solution for on-the-fly length generalization, LM-Infinite, which involves only a Lambda-shaped attention mask and a distance limit while requiring no parameter updates or learning. We find it applicable to a variety of LLMs using relative-position encoding methods. LM-Infinite is computational efficient with O(n) time and space, and demonstrates consistent fluency and generation quality to as long as 32k tokens on ArXiv and OpenWebText2 datasets, with 2.72x decoding speedup. On downstream task such as passkey retrieval, it continues to work on inputs much longer than training lengths where vanilla models fail immediately.

One of the most creative @llama_index use cases I’ve seen - @ravithejads’s app generates contextualized explanations for ALL modules in any codebase 🧑🏫, and stitches it together into a narrated video 🎬! Here’s my deepfake explaining our own codebase 👇: https://t.co/vVS7lgEdLn https://t.co/URGnIOKAej
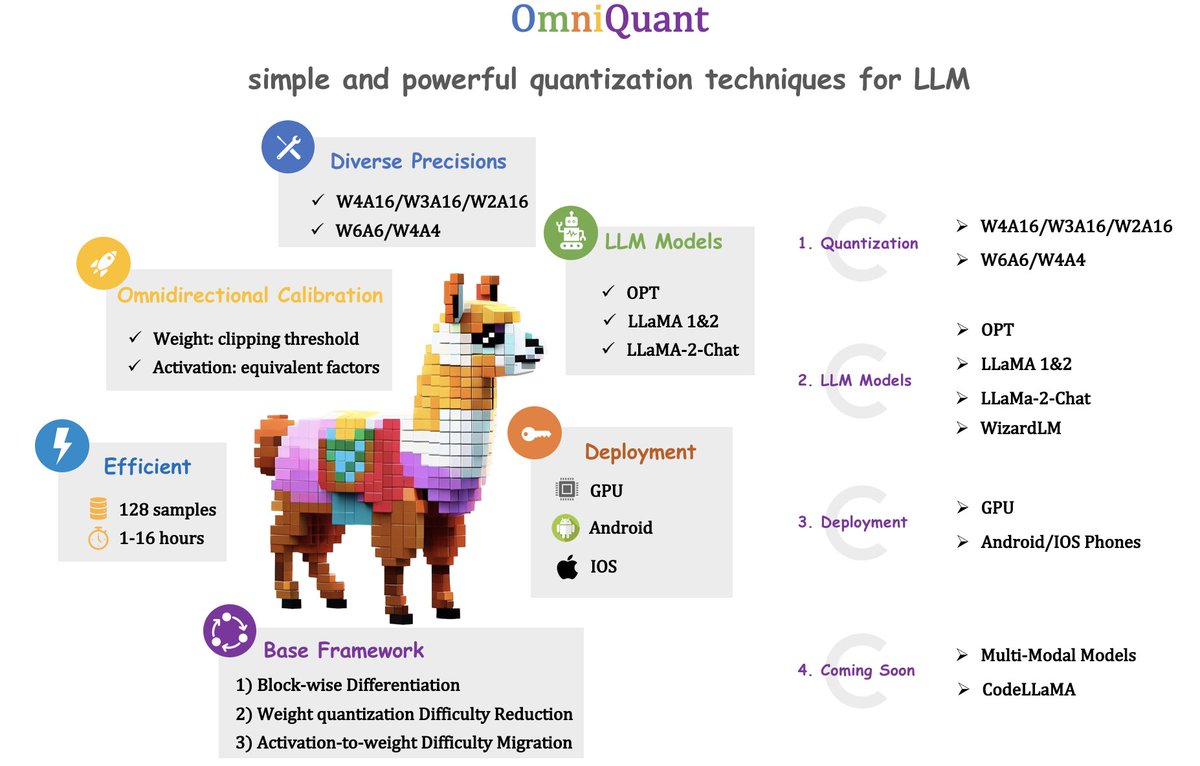
Thank AK @_akhaliq for the post. 🔥 Excited to introduce OmniQuant - An advanced open-source algorithm for compressing large language models! 📜 Paper: https://t.co/i62FV71HAg 🔗 Code: https://t.co/oPxDdySKtU 💡 Key Features: 🚀Omnidirectional Calibration: Enables easier weight and activation quantization through block-wise differentiation. 🛠 Diverse Precisions: Supports both weight-only quantization (W4A16/W3A16/W2A16) and weight-activation quantization (W6A6, W4A4). ⚡ Efficient: Quantize LLaMa-2 family (7B-70B) in just 1 to 16 hours using 128 samples. 🤖 LLM Models: Works with diverse model families, including OPT, WizardLM @WizardLM_AI, LLaMA, LLaMA-2, and LLaMA-2-chat. 🔑 Deployment: Offers out-of-the-box deployment cases for GPUs and mobile phones. 🏃Comming Soon: Multi-modal models and CodeLLaMa quantization!
OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models paper page: https://t.co/UoeEJ6xGDs Large language models (LLMs) have revolutionized natural language processing tasks. However, their practical deployment is hindered by their immense memory and com
WeatherBench 2: A benchmark for the next generation of data-driven global weather models paper page: https://t.co/aFQVm2hPwR WeatherBench 2 is an update to the global, medium-range (1-14 day) weather forecasting benchmark proposed by Rasp et al. (2020), designed with the aim to accelerate progress in data-driven weather modeling. WeatherBench 2 consists of an open-source evaluation framework, publicly available training, ground truth and baseline data as well as a continuously updated website with the latest metrics and state-of-the-art models: https://t.co/fBQwwe2iVM. This paper describes the design principles of the evaluation framework and presents results for current state-of-the-art physical and data-driven weather models. The metrics are based on established practices for evaluating weather forecasts at leading operational weather centers. We define a set of headline scores to provide an overview of model performance. In addition, we also discuss caveats in the current evaluation setup and challenges for the future of data-driven weather forecasting.

This was a lot harder than it looks. Hope you enjoy - ‘Glitch’. A full 4k YouTube link: https://t.co/ZLYwLU97jo Music by: Upbeat: What The Heart Sees - Jonny Easton & Youthful Pursuits - Aaron Paul Low. Created by Jeff Synthesized, this is a proof of concept animation for research and experimental purposes. No-one lost their jobs in the making of this film. Note: The studio is fictional, this is a personal film made by one individual.
There is a now a whole series of peer-reviewed papers finding that GPT is really good at answering complex medical questions in fields ranging from myopia to neurosurgery. The usual caveats apply (how much was in training data? what is the human comparison?) but its not nothing. https://t.co/dtwaoglf5X

How can business leaders, not just coders, build AI business applications with LLMs? Our new short course, created with Microsoft, is out! In How Business Thinkers Can Start Building AI Plugins With Semantic Kernel, taught by @johnmaeda, you'll learn to use Semantic Kernel and build an AI planner that can automatically select the plugins it needs to create multi-step plans with sophisticated logic. Please sign up here: https://t.co/YdW5fu1UIj
Congrats to oobabooga on the grant! Keep up the great stuff 💥 https://t.co/81IdnFuBiy https://t.co/Ez4wzEcnAy