@llama_index
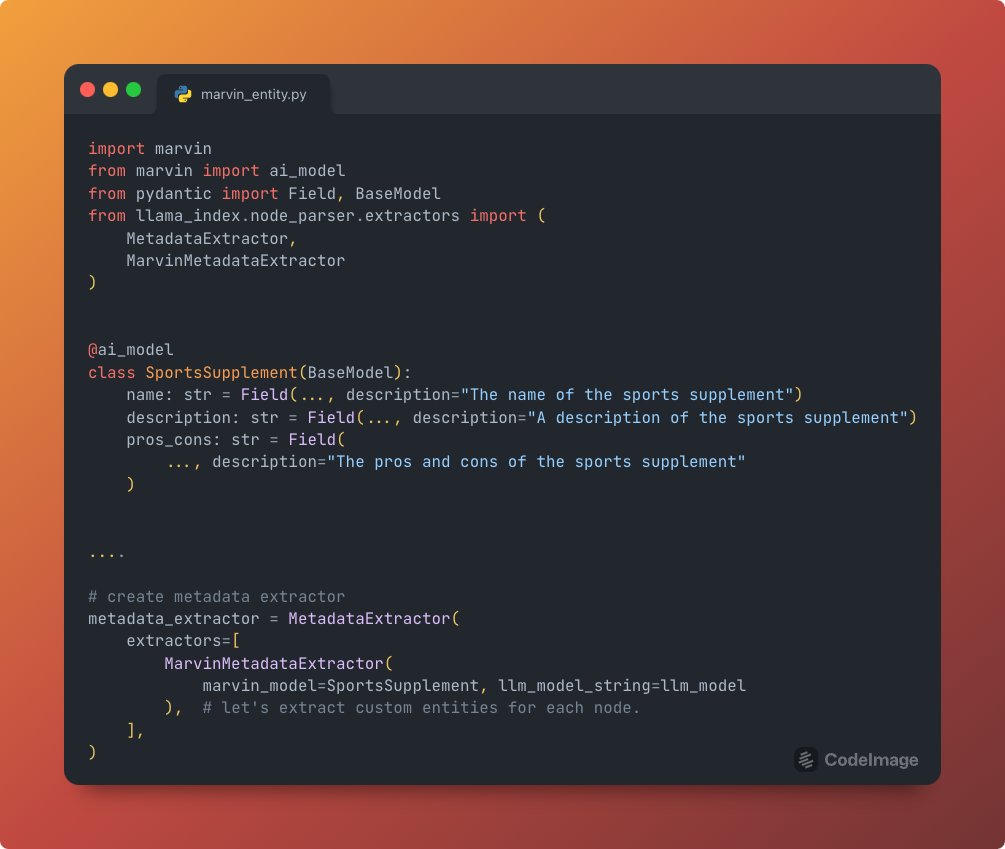
We’re excited to integrate @AskMarvinAI for automated metadata extraction from any text corpus. Simply add an annotation to a Pydantic model, and log metadata from *all* text chunks with that schema. Can use on its own or e2e for better RAG pipelines: https://t.co/jVLi64RB5G https://t.co/2CSW17jP9f