Your curated collection of saved posts and media
Demystifying CLIP Data Reveals CLIP’s data curation approach and makes it open to the community repo: https://t.co/nf7YLPjfS4 abs: https://t.co/5TpGw3WWg0 https://t.co/dra2PZF4gW

This is the first GPT-4V-powered agent. Autonomously designs webapps -- writes code, looks at the resulting site, improves the code accordingly, repeat. Absolutely wild.
Let's reverse engineer GPT-4V's uncanny ability to convert screenshots/sketches to code. Believe it or not, it's actually a (relatively) easier training task, because synthetic data can be scaled up massively. No insider info, but this is how I'd do it: 1. Scrape lots of websites and their code. Use a lightweight model (3.5) to clean up the code, and Selenium to render the screenshots. This becomes an initial training dataset of (Image, code). 2. Now given a screenshot, ask the model to generate code, and execute it in an actual browser. This step may throw errors, but GPT-4 is good at self-debugging. Fix all obvious runtime errors after a few rounds of iterative refinement. 3. The code is runnable now, but the rendered website may not follow the instruction image completely. Enters a very powerful idea from agent learning, called "Hindsight Relabeling" (https://t.co/f65BsP1tRk, authored by OpenAI in 2017). Basically, the wrong end product is actually correct given the current code. Instead of following (Image1, code), GPT-4V generates code -> Image2. Now the data pair (Image2, code) is actually groundtruth, which can be added to the training dataset. 4. Do aggressive data augmentation: change fonts, move around HTML elements, swap out background, add lots of noises. Combined with extraordinary OCR abilities, it's conceivable that enough data augmentation will help GPT-4V generalize to hand-drawn sketches, such as the napkin demo that @gdb did in February. Video credit: @mckaywrigley
i fucking called it. ads team begging for worse search results so that the ads team can hit their goals this year https://t.co/nsKzR4KYqY
my newest conspiracy theory is that google is filtering b2b emails to encourage greater adwords spend

With LLMs we can create a fully open-source Library of Alexandria. As a first attempt, I have generated 650,000 unique textbook samples from a diverse span of courses, kindergarten through graduate school. They are all available here: [https://t.co/8cea6k90QX] https://t.co/GUo66gCAwO

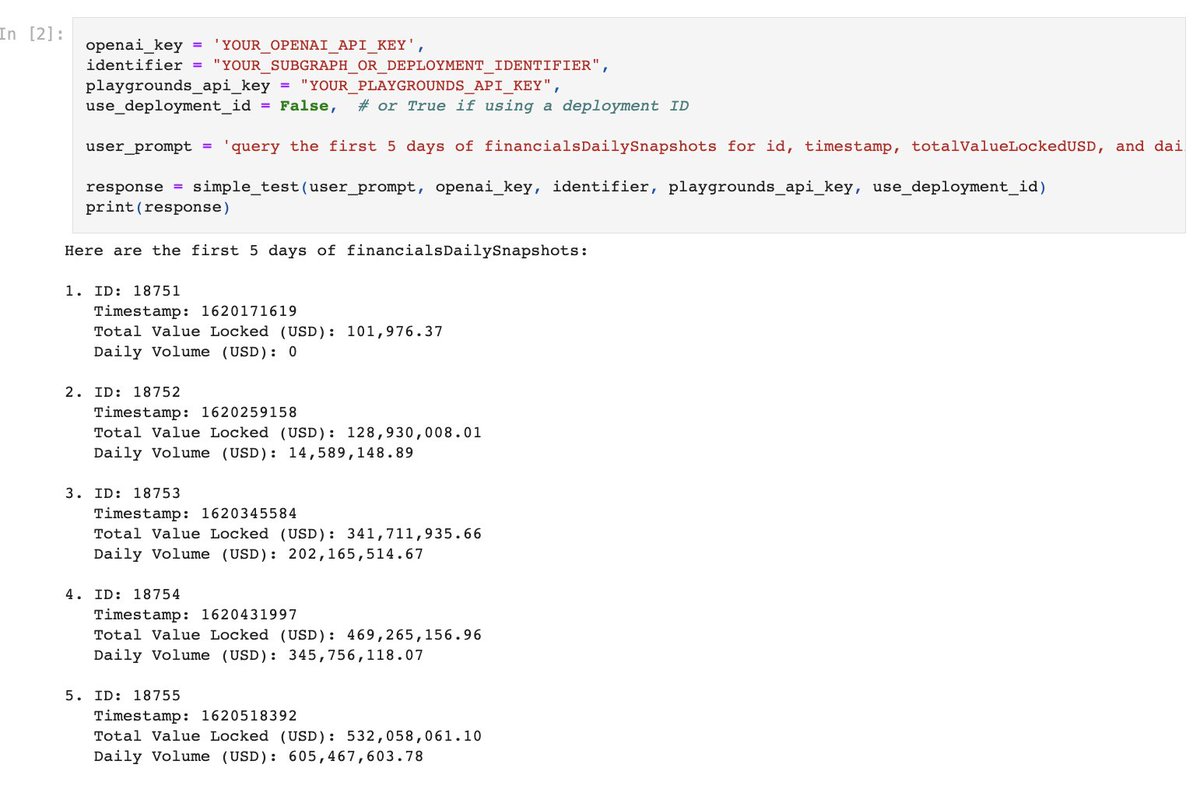
Use @llama_index data agents for blockchain data analysis 🔑🐋 With the brand-new playgrounds tool specs by @0thTachi, you can now query/introspect any blockchain subgraph (indexed datasets) with natural language. Tools: https://t.co/tks7EIzDQq https://t.co/uSdSzlIUSJ https://t.co/IsV1iJRXuD
Ever wondered how far specialized large language models (LLMs) can go in scientific NLP? Meet Galactica. At the time of release, this LLM attained new SOTA results in PubMedQA and MedMCQA with a 106B-token scientific corpus and excels in tasks like LaTeX equations and reasoning. Galactica also introduced a novel “<work>” token for working memory, embedding step-by-step reasoning within “<work></work>” tags in datasets. More in our new paper explainer: https://t.co/wPUbnQ1k4G

AHHHH just let me buy Why are you like this enterprises I will literally write a crawler instead I will call you when I want help Give me self serve or give me death https://t.co/0MhI6BvyWK
A side project I've been building lately. I built a neural net with Tensorflow and trained it on the MNIST dataset of handwritten images. Then, I brought the model into Blender and used the values to turn it into a 3D scene. This is actually the model running! https://t.co/lXy6bHnovw
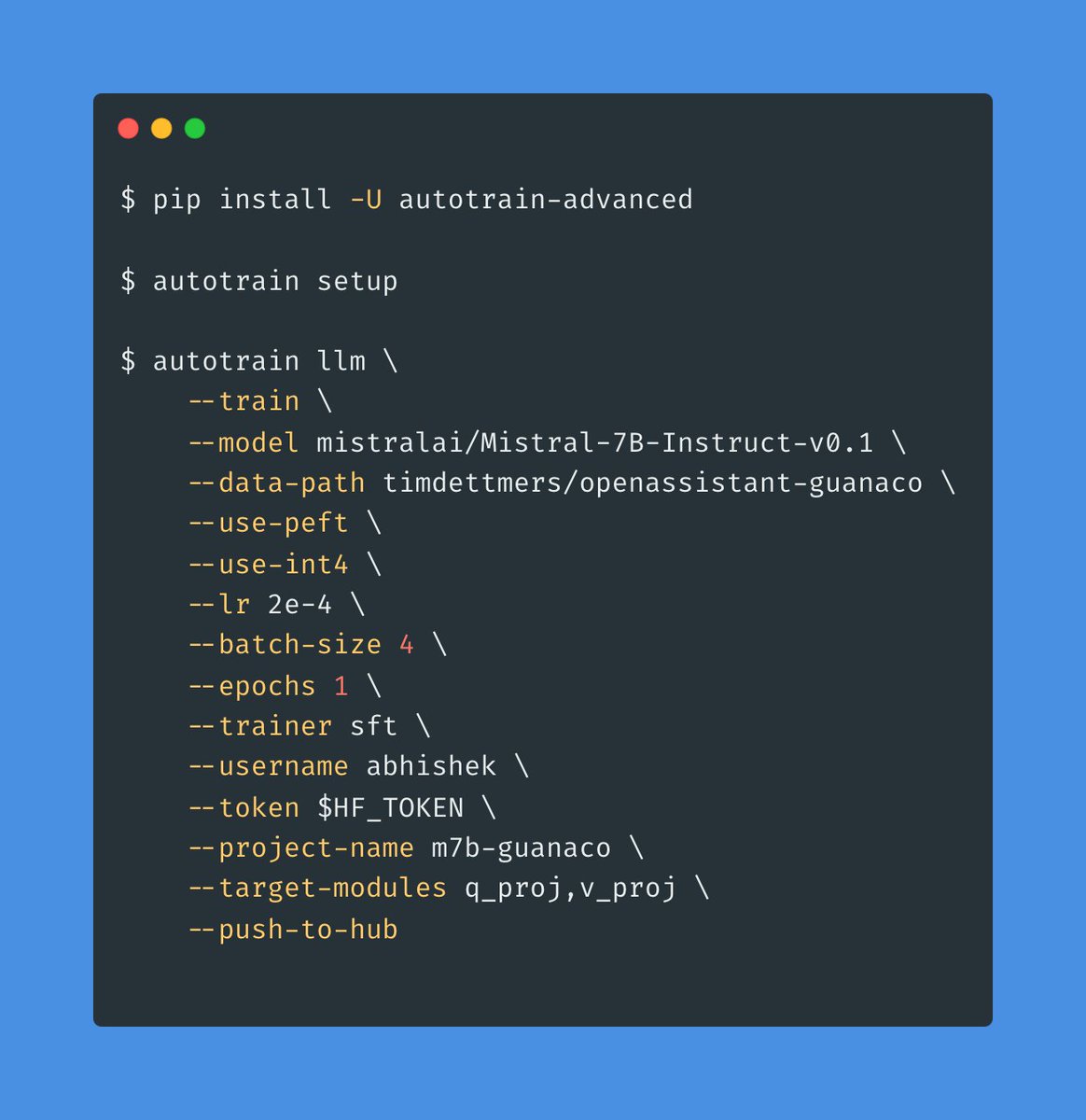
The world of LLMs is moving so fast! Mistral AI has announced their first 7B model which achieves performance comparable to 13B Llama2! 💥 Good news, you can already finetune the new model using AutoTrain Advanced on your own custom dataset! 🚀 P.S. also works on Google Colab ;) https://t.co/rymbW4VyzD
DECO: Dense Estimation of 3D Human-Scene Contact In The Wild paper page: https://t.co/30y377xMlh Understanding how humans use physical contact to interact with the world is key to enabling human-centric artificial intelligence. While inferring 3D contact is crucial for modeling realistic and physically-plausible human-object interactions, existing methods either focus on 2D, consider body joints rather than the surface, use coarse 3D body regions, or do not generalize to in-the-wild images. In contrast, we focus on inferring dense, 3D contact between the full body surface and objects in arbitrary images. To achieve this, we first collect DAMON, a new dataset containing dense vertex-level contact annotations paired with RGB images containing complex human-object and human-scene contact. Second, we train DECO, a novel 3D contact detector that uses both body-part-driven and scene-context-driven attention to estimate vertex-level contact on the SMPL body. DECO builds on the insight that human observers recognize contact by reasoning about the contacting body parts, their proximity to scene objects, and the surrounding scene context. We perform extensive evaluations of our detector on DAMON as well as on the RICH and BEHAVE datasets. We significantly outperform existing SOTA methods across all benchmarks. We also show qualitatively that DECO generalizes well to diverse and challenging real-world human interactions in natural images.

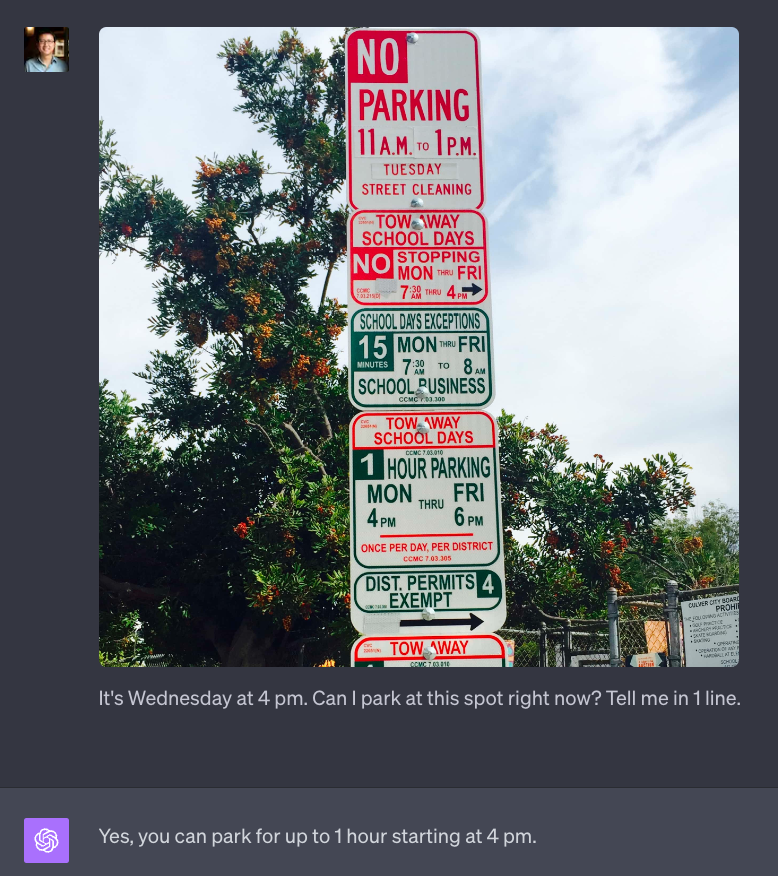
I will never get a parking ticket again. https://t.co/yl7ND2rJeQ
Low-rank Adaptation of Large Language Model Rescoring for Parameter-Efficient Speech Recognition paper page: https://t.co/DiSq9F9AJ7 propose a neural language modeling system based on low-rank adaptation (LoRA) for speech recognition output rescoring. Although pretrained language models (LMs) like BERT have shown superior performance in second-pass rescoring, the high computational cost of scaling up the pretraining stage and adapting the pretrained models to specific domains limit their practical use in rescoring. Here we present a method based on low-rank decomposition to train a rescoring BERT model and adapt it to new domains using only a fraction (0.08%) of the pretrained parameters. These inserted matrices are optimized through a discriminative training objective along with a correlation-based regularization loss. The proposed low-rank adaptation Rescore-BERT (LoRB) architecture is evaluated on LibriSpeech and internal datasets with decreased training times by factors between 5.4 and 3.6.

Jointly Training Large Autoregressive Multimodal Models Presents a modular approach that systematically fuses existing text and image generation models Unparalleled performance in generating high-quality multimodal outputs https://t.co/arLHU2lCFe https://t.co/d7Xmw8DdgJ

Finite Scalar Quantization: VQ-VAE Made Simple paper page: https://t.co/BqUXMdUK1C propose to replace vector quantization (VQ) in the latent representation of VQ-VAEs with a simple scheme termed finite scalar quantization (FSQ), where we project the VAE representation down to a few dimensions (typically less than 10). Each dimension is quantized to a small set of fixed values, leading to an (implicit) codebook given by the product of these sets. By appropriately choosing the number of dimensions and values each dimension can take, we obtain the same codebook size as in VQ. On top of such discrete representations, we can train the same models that have been trained on VQ-VAE representations. For example, autoregressive and masked transformer models for image generation, multimodal generation, and dense prediction computer vision tasks. Concretely, we employ FSQ with MaskGIT for image generation, and with UViM for depth estimation, colorization, and panoptic segmentation. Despite the much simpler design of FSQ, we obtain competitive performance in all these tasks. We emphasize that FSQ does not suffer from codebook collapse and does not need the complex machinery employed in VQ (commitment losses, codebook reseeding, code splitting, entropy penalties, etc.) to learn expressive discrete representations.

Evaluating Cognitive Maps and Planning in Large Language Models with CogEval paper page: https://t.co/SBaDJXqM70 Recently an influx of studies claim emergent cognitive abilities in large language models (LLMs). Yet, most rely on anecdotes, overlook contamination of training sets, or lack systematic Evaluation involving multiple tasks, control conditions, multiple iterations, and statistical robustness tests. Here we make two major contributions. First, we propose CogEval, a cognitive science-inspired protocol for the systematic evaluation of cognitive capacities in Large Language Models. The CogEval protocol can be followed for the evaluation of various abilities. Second, here we follow CogEval to systematically evaluate cognitive maps and planning ability across eight LLMs (OpenAI GPT-4, GPT-3.5-turbo-175B, davinci-003-175B, Google Bard, Cohere-xlarge-52.4B, Anthropic Claude-1-52B, LLaMA-13B, and Alpaca-7B). We base our task prompts on human experiments, which offer both established construct validity for evaluating planning, and are absent from LLM training sets. We find that, while LLMs show apparent competence in a few planning tasks with simpler structures, systematic evaluation reveals striking failure modes in planning tasks, including hallucinations of invalid trajectories and getting trapped in loops. These findings do not support the idea of emergent out-of-the-box planning ability in LLMs. This could be because LLMs do not understand the latent relational structures underlying planning problems, known as cognitive maps, and fail at unrolling goal-directed trajectories based on the underlying structure. Implications for application and future directions are discussed.

VPA: Fully Test-Time Visual Prompt Adaptation paper page: https://t.co/BmDmiDNTeG Textual prompt tuning has demonstrated significant performance improvements in adapting natural language processing models to a variety of downstream tasks by treating hand-engineered prompts as trainable parameters. Inspired by the success of textual prompting, several studies have investigated the efficacy of visual prompt tuning. In this work, we present Visual Prompt Adaptation (VPA), the first framework that generalizes visual prompting with test-time adaptation. VPA introduces a small number of learnable tokens, enabling fully test-time and storage-efficient adaptation without necessitating source-domain information. We examine our VPA design under diverse adaptation settings, encompassing single-image, batched-image, and pseudo-label adaptation. We evaluate VPA on multiple tasks, including out-of-distribution (OOD) generalization, corruption robustness, and domain adaptation. Experimental results reveal that VPA effectively enhances OOD generalization by 3.3% across various models, surpassing previous test-time approaches. Furthermore, we show that VPA improves corruption robustness by 6.5% compared to strong baselines. Finally, we demonstrate that VPA also boosts domain adaptation performance by relatively 5.2%. Our VPA also exhibits marked effectiveness in improving the robustness of zero-shot recognition for vision-language models.

Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack Proposes quality-tuning to effectively guide a pre-trained model to exclusively generate highly visually appealing images, while maintaining generality across visual concepts https://t.co/qlPfAmScAw https://t.co/QAqKIDzUfC

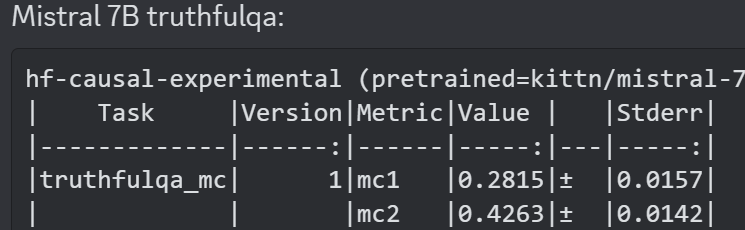
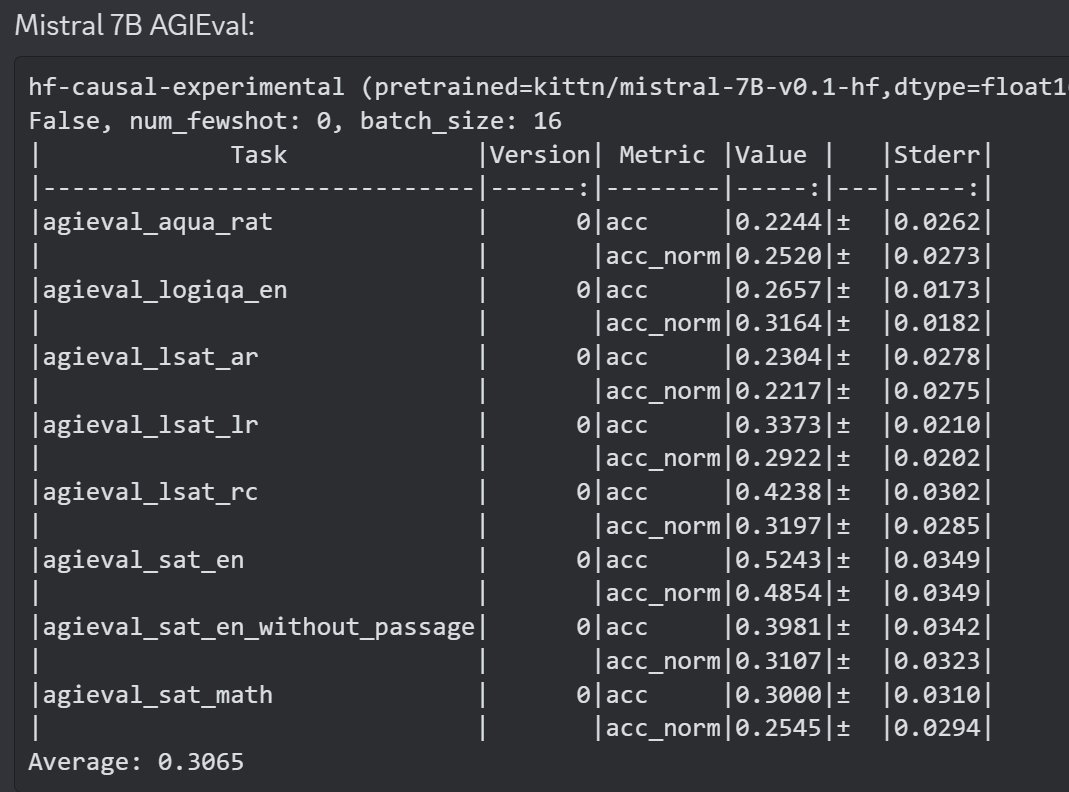
Some info on Mistral 7B: On bigbench, Mistral beats 7B llama-2, does not beat 13b llama-2, on AGIEval, it beats llama-2 7b, I dont have 13b's numbers, on TruthfulQA it beats llama-2 7b and 13b https://t.co/pdiN5sUhEa
our team has been eagerly awaiting GPT-4 multimodality, GPT-4 Vision ("GPT-V" 🫢) 🟧 i'll save you reading 192 HN comments. some neat use cases / limitations in first testing https://t.co/IyXl04GLTP
ChatGPT+ from @OpenAI with browsing vs @perplexity_ai. Both use GPT-4, but only one actually provides useful information from the web. https://t.co/SXgH8nIZf3


ChatGPT browsing is back! 🌐 If you want to enable web-browsing for *any* LLM-powered agent, here are 3 LlamaHub tools + guides for you to check out 👇: 1️⃣ @metaphorsystems: https://t.co/6292nUpYUZ 2️⃣ @MultiON_AI: https://t.co/pR2nuhfxGo 3️⃣ Bing search: https://t.co/Dfc6Pje5FG https://t.co/Vc9NRFK99z
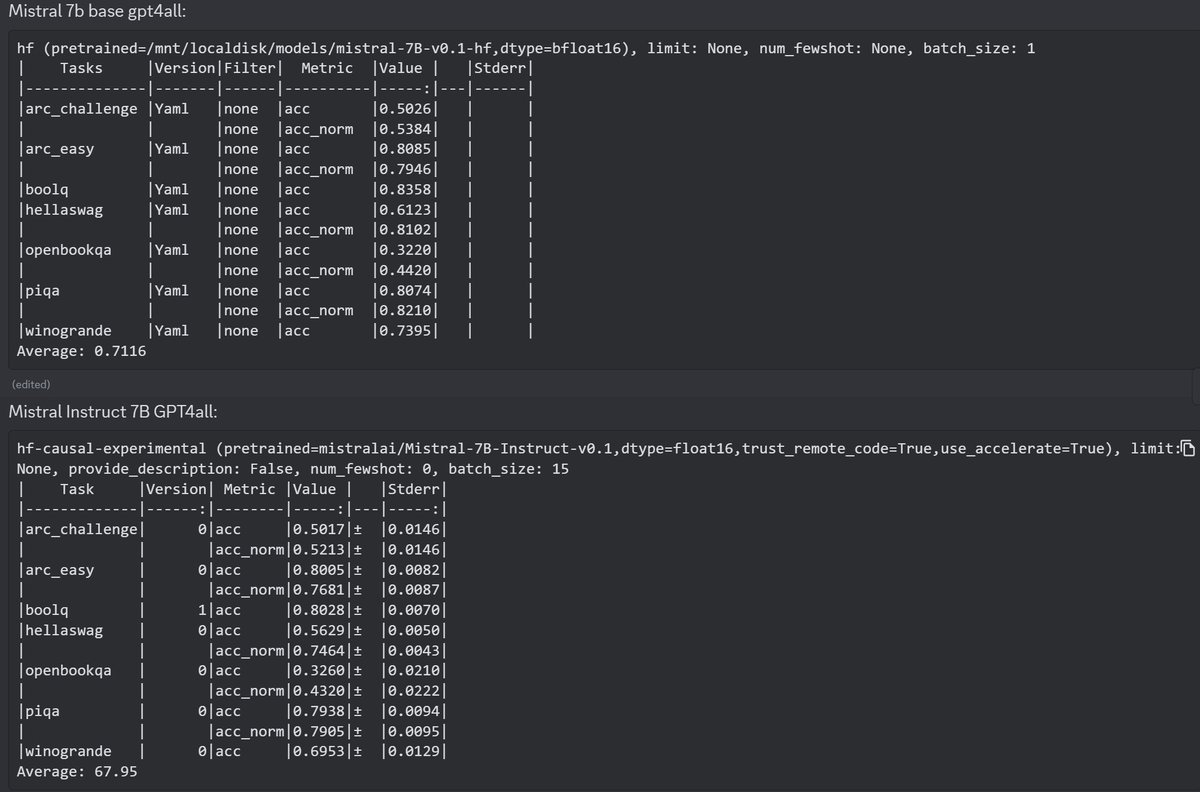
Mistral's finetune does quite well on MT-Bench (a gpt4 eval mostly for style) but is hurt compared to base model on gpt4all benchmark suite: https://t.co/3ABjPBptiL
🎬🎥Can LLMs create a detailed “video plan” that describes entities/background/layouts/consistency-groups for long video generation? VideoDirectorGPT: Consistent Multi-scene Video Generation via LLM-Guided Planning https://t.co/w4OZ6GeHQW @AbhayZala7 @jmin__cho @mohitban47 🧵 https://t.co/pa6GzPEZZB
VideoDirectorGPT: Consistent Multi-scene Video Generation via LLM-Guided Planning paper page: https://t.co/3OsWSqMeXU Although recent text-to-video (T2V) generation methods have seen significant advancements, most of these works focus on producing short video clips of a single
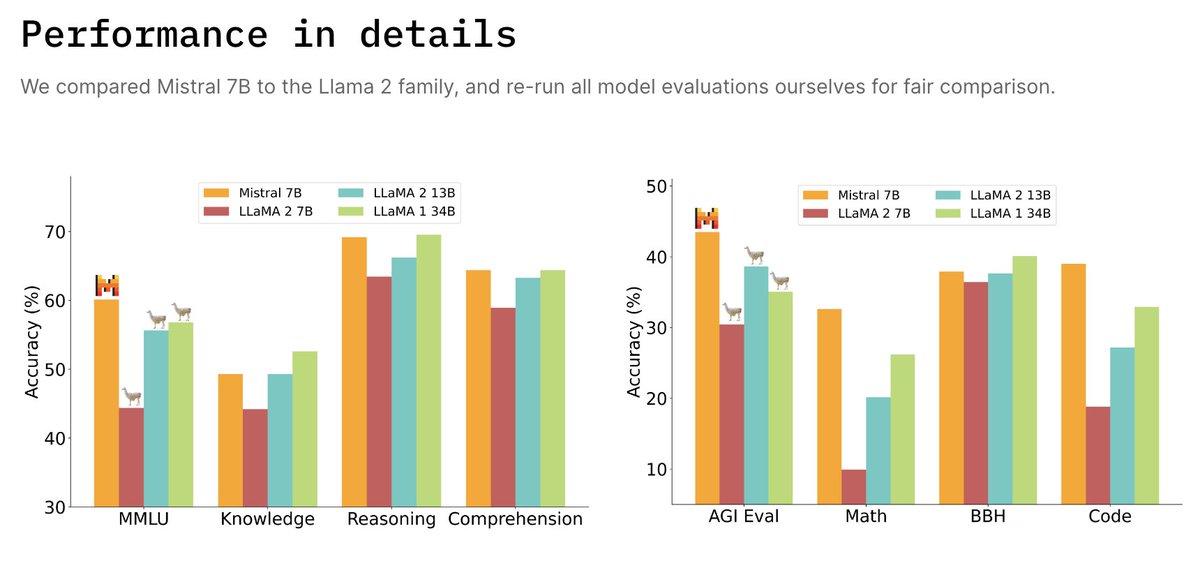
The highly expected Mistral 7B is out. Yes, from the french startup with a $113M seed round. The model already outperforms Llama 2 13B on every benchmark. Features - Released under Apache 2.0 licence. - Superior to LLaMA 1 34B in code, math, and reasoning - Approaches CodeLlama 7B performance on code Usability - Usable anywhere (even locally) - Deployable on any cloud (AWS/GCP/Azure) - Usable on HuggingFace Architecture - Uses Grouped-query attention (GQA) for faster inference -Uses Sliding Window Attention (SWA) to handle longer sequences at smaller cost https://t.co/vrtvl0kIpX
The Llama Ecosystem: Past, Present, and Future It's pretty incredible the impact Llama is having already. Great update by Meta AI on the Llama ecosystem and the future that's coming. "There are now over 7,000 projects on GitHub built on or mentioning Llama". Multimodal models, safer models, and more focus on the community of developers and researchers. This is just the start! Watch this space! https://t.co/E0qL0e58Ys
Large language models are notoriously hard to evaluate because (1) they are highly multi-task, (2) they generate long completions, and (3) grading is subjective. After spending ~5 months rigorously working on how to do language model evals, this is my verdict: https://t.co/JCw9DwwghC
Many AI-savvy programmers are now coding very differently than before, by using LLMs to help with their work. You’ll learn these emerging best practices in “Pair Programming with a Large Language Model,” by Google's @lmoroney. This short course covers using LLMs to simplify and improve your code, assist with debugging, and minimize technical debt by having AI document your code. The use of LLMs as a programming companion is an important shift that's well worth every developer staying on top of. Please check this out! https://t.co/AOCgK7LQex
ChatGPT can now browse the internet to provide you with current and authoritative information, complete with direct links to sources. It is no longer limited to data before September 2021. https://t.co/pyj8a9HWkB
I gave ChatGPT a screenshot of a SaaS dashboard and it wrote the code for it. This is the future. https://t.co/9xFgFdv4MM
Lots of cool things shipped at @gladia_io this week 🏃♂️ - More interactive UI: Clicking on a word in a transcript will automatically adjust the audio player timestamp. So, you can now directly see how accurate our word-level timestamp aligner is. - Our live transcription component now supports super precise word-level timestamps - How it works: The timestamps are relative to the beginning of the websocket streaming. This means that you can have your diarization based on video separation and attribute it to each speaker without risking transcript misattribution — and this is a key element for subsequent LLM processing (for instance, defining action items, generating summaries, extracting metadata, etc.) - New integration example with @twilio - check link 👇 - Added transcription support for Vimeo … and a few others!
Another interview from an ad industry insider pointing out what is already happening in the industry and how AI is affecting it; - hyper-personalized Ads and Cost-cutting on creative teams because of AI. The writing is on the wall. Get ready for the new age at $META, $GOOGL, and many other companies. Interview from a digital advertising specialist working in the industry for more than 8 years: 1. Top-tier ad agencies have been reporting ad spending growing between 4%-9% this year. They also expect 2024 and 2025 to be strong years. 2. AI tools are already starting to replace some creative teams, which is creating cost savings. 3. AI will create hyper-personalized ads delivered at the right time, which will end up driving higher ROI for advertisers. 4. $GOOGL Gemini is expected to be released soon. According to this expert, a lot of focus will also be on API integrations with internal data sources from companies helping them manage the business (stock, organizational, etc.).