Your curated collection of saved posts and media
Meta Chain-of-Thought Prompting with LLMs Proposes a generalizable chain-of-thought (Meta-CoT) prompting method in mixed-task scenarios where the type of input questions is unknown. The core idea is to bridge the gap between performance and generalization when using the CoT prompting method with LLMs. Meta-CoT is comprised of three phases: 1) Scenario identification: samples distinct questions as in-context learning demonstrations to help automatically categorize scenarios based on input questions 2) Demonstration selection: constructs diverse demonstrations from a pool based on the scenario obtained in the first phase 3) Answer derivation: performs a final answer inference on the input question using previously fetched demonstrations Lots of interesting insights/results to analyze from the paper but it seems that the scenario identification phase plays a key role in generalization and "potentially arouses the self-determination ability of LLMs without the need for manual intervention." MetaCoT "achieves the state-of-the-art result on SVAMP (93.7%) without any additional program-aided methods. Moreover, Meta-CoT achieves impressive performance on GSM8K (93.6%) even without in-context demonstrations from GSM8K itself." paper: https://t.co/w16AFruSFI code: https://t.co/48g37kiUc1

In case you missed it: our new PGVectorSQLQueryEngine, now in beta, lets you query a postgres database with full SQL and vector search at the same time! https://t.co/4EccrF6SAi https://t.co/UwafrCSohR

Textbooks generated with finetuned mistral + search and wikipedia RAG are surprisingly good. They seem close to GPT-3.5. See samples here - https://t.co/nwamw1T73A , and here - https://t.co/1zUOkKTlKF . Working on a bigger set now! Please let me know if you can sponsor. https://t.co/0AXvBg9etb
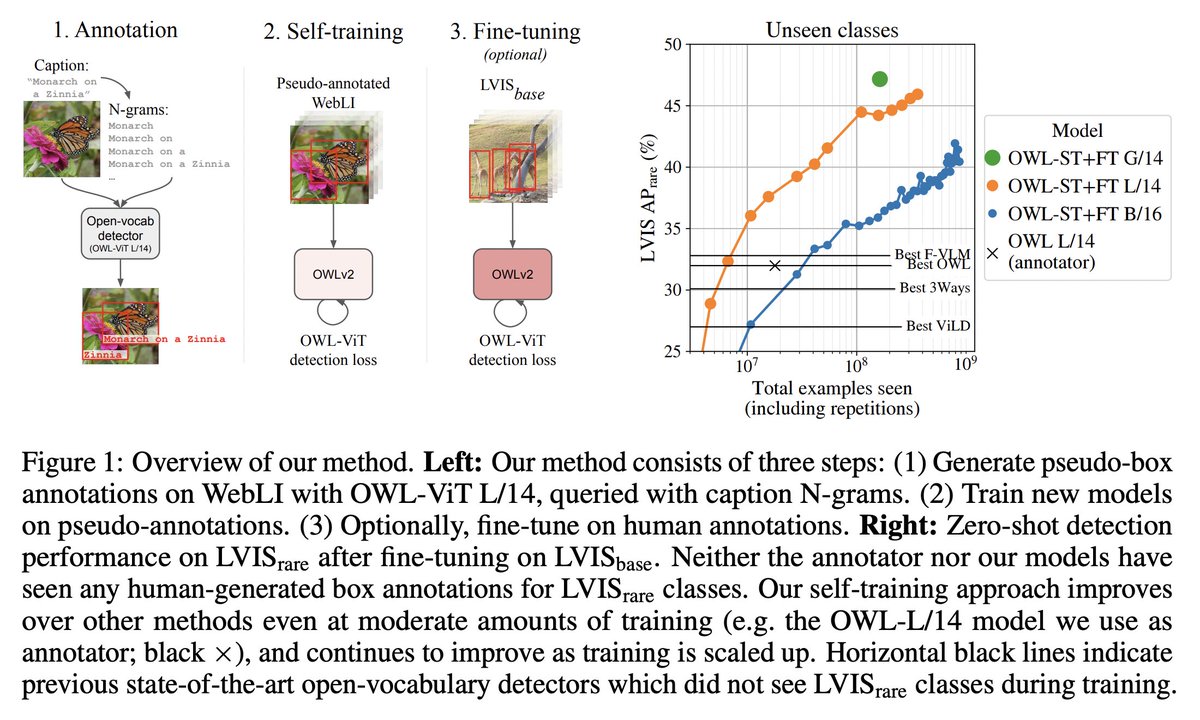
Excited to share that @Google's OWLv2 model is now available in 🤗 Transformers! This model is one of the strongest zero-shot object detection models out there, improving upon OWL-ViT v1 which was released last year🔥 How? By self-training on web-scale data of over 1B examples⬇️ https://t.co/GrxTpHC1wo
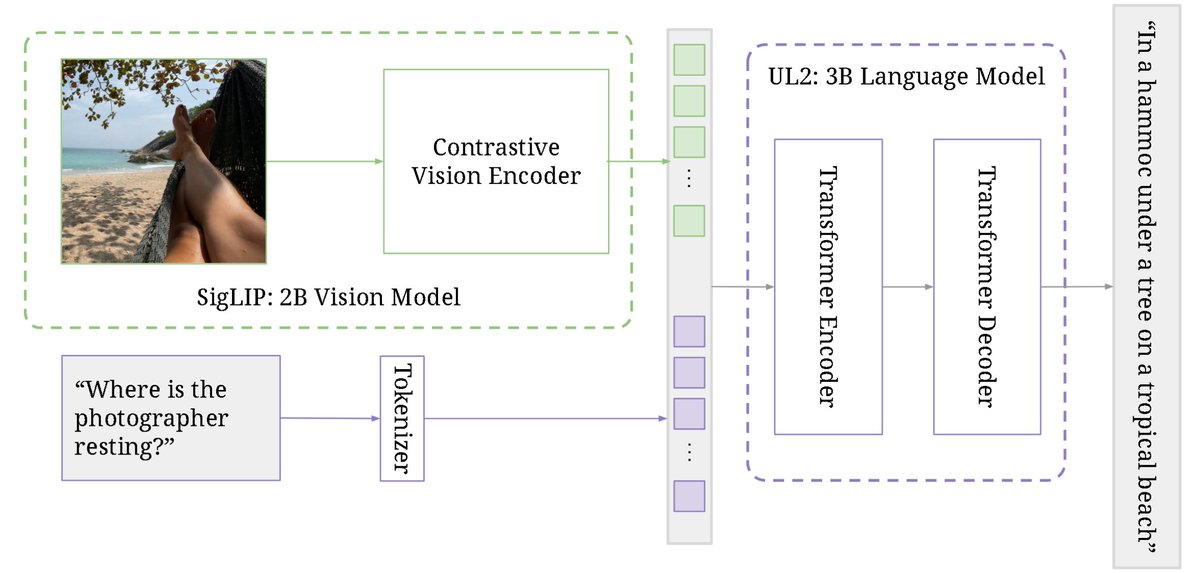
PaLI-3 Vision Language Models: Smaller, Faster, Stronger abs: https://t.co/VATjcGkZXi Uses a 2B SigLIP vision encoder and 3B UL2 language model to obtain SOTA performance on visually-situated text understanding tasks. SigLIP observed to be a better encoder than classification-pretrained ViT. Model generalizes to video understanding tasks despite not being trained with videos.
Anyone know how to derive this '1.5x' communication overhead between FSDP vs DDP (from the FSDP paper)? https://t.co/73qe4XtRa7

Improved Techniques for Training Consistency Models abs: https://t.co/cOQEWAr8MT Consistency model training from scratch now beats all diffusion distillation approaches in both 1-step & 2-step generation. Comparable to many leading generative models, including diffusion models. This is possible with changes to loss weighting, noise schedule, metric in consistency loss, removing EMA, adding dropout, etc.
Check our latest updates and improved model for PAIR Diffusion: A Comprehensive Multimodal Object-Level Image Editor🚀🚀 Project page: https://t.co/6aIxv2MAy2 ArXiv: https://t.co/ShNOGF7Ntz We show that 👇👇 https://t.co/zmP1RKXnfs
PAIR-Diffusion: Object-Level Image Editing with Structure-and-Appearance Paired Diffusion Models @Gradio demo is out on @huggingface Spaces demo: https://t.co/hR63tPMl5i https://t.co/t2sJZXcdHB
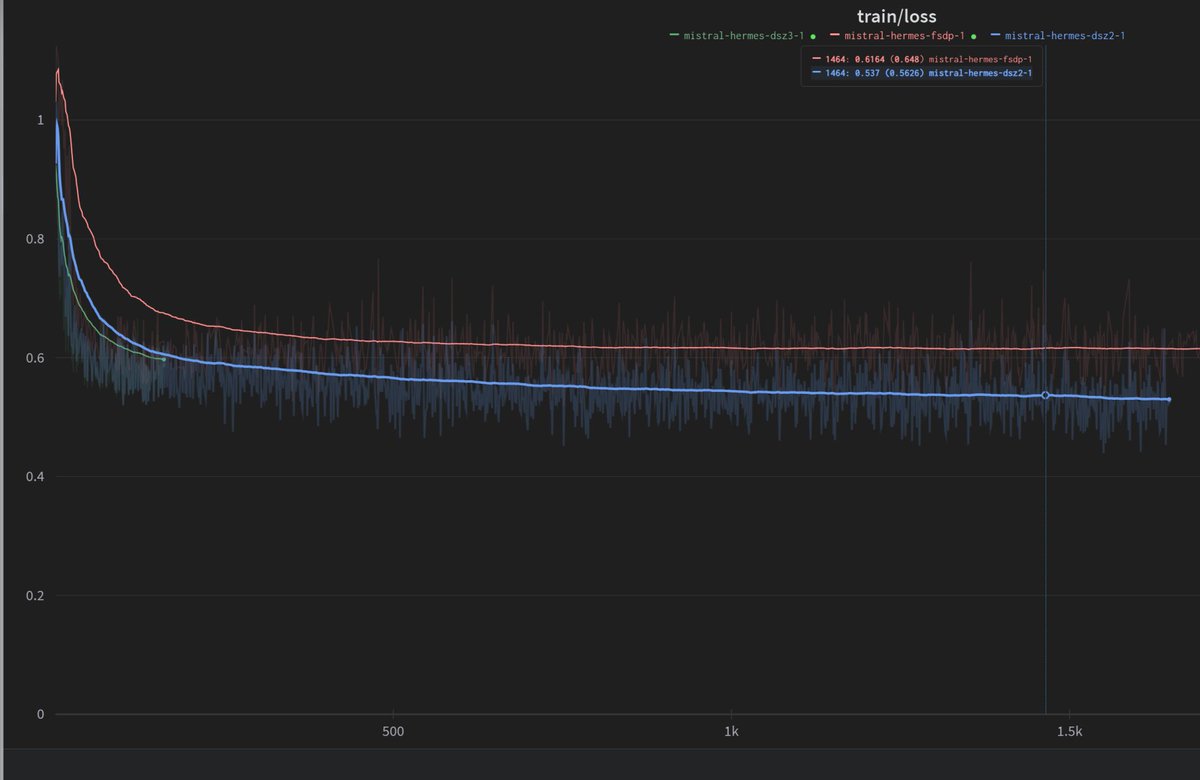
Somehow FSDP seems to have been the cause for hermes2 never converging. I dont understand it, but it seems to be the case. Deepspeed Zero 2 seems to work fine - testing zero 3 now https://t.co/PzDgFvaUhl
GPT-4V "Describe this image" 🔃 Dall-E 3 "Generate this image" Recursive loop https://t.co/yeAsNvdC9W
Can LLMs help with real-world GitHub issues? 📢 SWE-bench Dataset from @princeton-nlp is on @huggingface Hub 🎯 Focus: Automated GitHub issue resolution 📚 Content: 2,294 Issue-PR pairs from 12 Python repos 🔎 Evaluation: Unit test verification using post-PR behavior https://t.co/z0eQFmVp3v

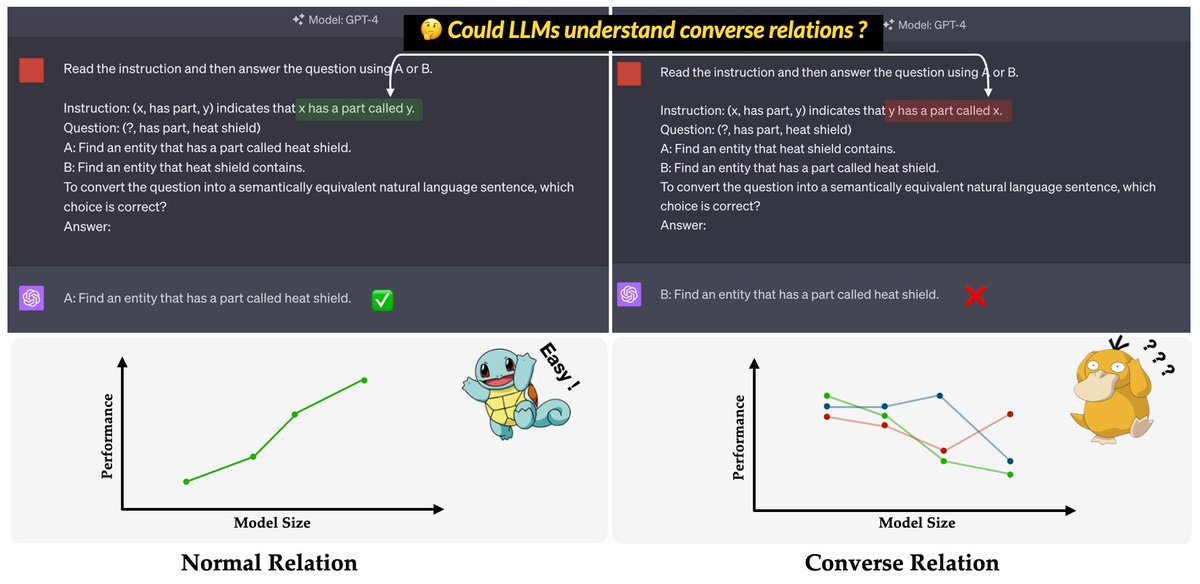
🚨A new inverse scaling! Related to the 🔥 Reversal Curse 😈 @OwainEvans_UK. Check out our latest work at #EMNLP2023, ConvRe, for a comprehensive analysis of LLM's frustration facing Converse Relations. 📑 https://t.co/S4yvbP55Ei 📊 https://t.co/1cBBntAnAB 1/5 https://t.co/B9cwz2GCCQ
I've recently been playing with @fchollet's Abstraction and Reasoning Corpus, a really interesting benchmark for building systems that can reason. As part of that, I've just released a small 🐍 library for easily interacting with and visualising ARC: https://t.co/qUosbaUhix https://t.co/vXRndxhml1
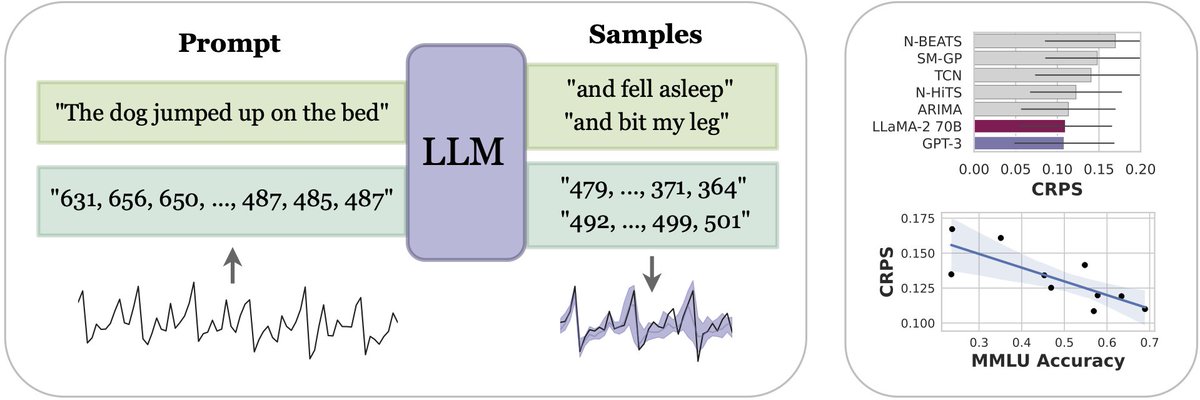
Large Language Models Are Zero-Shot Time Series Forecasters abs: https://t.co/aVDZ1sD4FT code: https://t.co/1AwskkzjrS Introduces LLMTime, a simple method to apply pretrained LLMs for continuous time series prediction problems. Main trick is to ensure each digit is tokenized (by adding spaces between digits for example). Their approach obtains SOTA on various benchmarks.
1/ 🧵 🎉 Introducing Lemur-70B & Lemur-70B-Chat: 🚀Open & SOTA Foundation Models for Language Agents! The closest open model to GPT-3.5 on 🤖15 agent tasks🤖! 📄Paper: https://t.co/6on1cqzU1j 🤗Model @huggingface : https://t.co/0gMt3nPSf0 More details 👇 https://t.co/7FaU4A3ydN
LangNav: Language as a Perceptual Representation for Navigation paper page: https://t.co/8aBd9VnF3U explore the use of language as a perceptual representation for vision-and-language navigation. Our approach uses off-the-shelf vision systems (for image captioning and object detection) to convert an agent's egocentric panoramic view at each time step into natural language descriptions. We then finetune a pretrained language model to select an action, based on the current view and the trajectory history, that would best fulfill the navigation instructions. In contrast to the standard setup which adapts a pretrained language model to work directly with continuous visual features from pretrained vision models, our approach instead uses (discrete) language as the perceptual representation. We explore two use cases of our language-based navigation (LangNav) approach on the R2R vision-and-language navigation benchmark: generating synthetic trajectories from a prompted large language model (GPT-4) with which to finetune a smaller language model; and sim-to-real transfer where we transfer a policy learned on a simulated environment (ALFRED) to a real-world environment (R2R). Our approach is found to improve upon strong baselines that rely on visual features in settings where only a few gold trajectories (10-100) are available, demonstrating the potential of using language as a perceptual representation for navigation tasks.
EIPE-text: Evaluation-Guided Iterative Plan Extraction for Long-Form Narrative Text Generation paper page: https://t.co/MRUF8VXXIC Plan-and-Write is a common hierarchical approach in long-form narrative text generation, which first creates a plan to guide the narrative writing. Following this approach, several studies rely on simply prompting large language models for planning, which often yields suboptimal results. In this paper, we propose a new framework called Evaluation-guided Iterative Plan Extraction for long-form narrative text generation (EIPE-text), which extracts plans from the corpus of narratives and utilizes the extracted plans to construct a better planner. EIPE-text has three stages: plan extraction, learning, and inference. In the plan extraction stage, it iteratively extracts and improves plans from the narrative corpus and constructs a plan corpus. We propose a question answer (QA) based evaluation mechanism to automatically evaluate the plans and generate detailed plan refinement instructions to guide the iterative improvement. In the learning stage, we build a better planner by fine-tuning with the plan corpus or in-context learning with examples in the plan corpus. Finally, we leverage a hierarchical approach to generate long-form narratives. We evaluate the effectiveness of EIPE-text in the domains of novels and storytelling. Both GPT-4-based evaluations and human evaluations demonstrate that our method can generate more coherent and relevant long-form narratives.

Prometheus: Inducing Fine-grained Evaluation Capability in Language Models paper page: https://t.co/BN56gT6gf7 Recently, using a powerful proprietary Large Language Model (LLM) (e.g., GPT-4) as an evaluator for long-form responses has become the de facto standard. However, for practitioners with large-scale evaluation tasks and custom criteria in consideration (e.g., child-readability), using proprietary LLMs as an evaluator is unreliable due to the closed-source nature, uncontrolled versioning, and prohibitive costs. In this work, we propose Prometheus, a fully open-source LLM that is on par with GPT-4's evaluation capabilities when the appropriate reference materials (reference answer, score rubric) are accompanied. We first construct the Feedback Collection, a new dataset that consists of 1K fine-grained score rubrics, 20K instructions, and 100K responses and language feedback generated by GPT-4. Using the Feedback Collection, we train Prometheus, a 13B evaluator LLM that can assess any given long-form text based on customized score rubric provided by the user. Experimental results show that Prometheus scores a Pearson correlation of 0.897 with human evaluators when evaluating with 45 customized score rubrics, which is on par with GPT-4 (0.882), and greatly outperforms ChatGPT (0.392). Furthermore, measuring correlation with GPT-4 with 1222 customized score rubrics across four benchmarks (MT Bench, Vicuna Bench, Feedback Bench, Flask Eval) shows similar trends, bolstering Prometheus's capability as an evaluator LLM. Lastly, Prometheus achieves the highest accuracy on two human preference benchmarks (HHH Alignment & MT Bench Human Judgment) compared to open-sourced reward models explicitly trained on human preference datasets, highlighting its potential as an universal reward model.

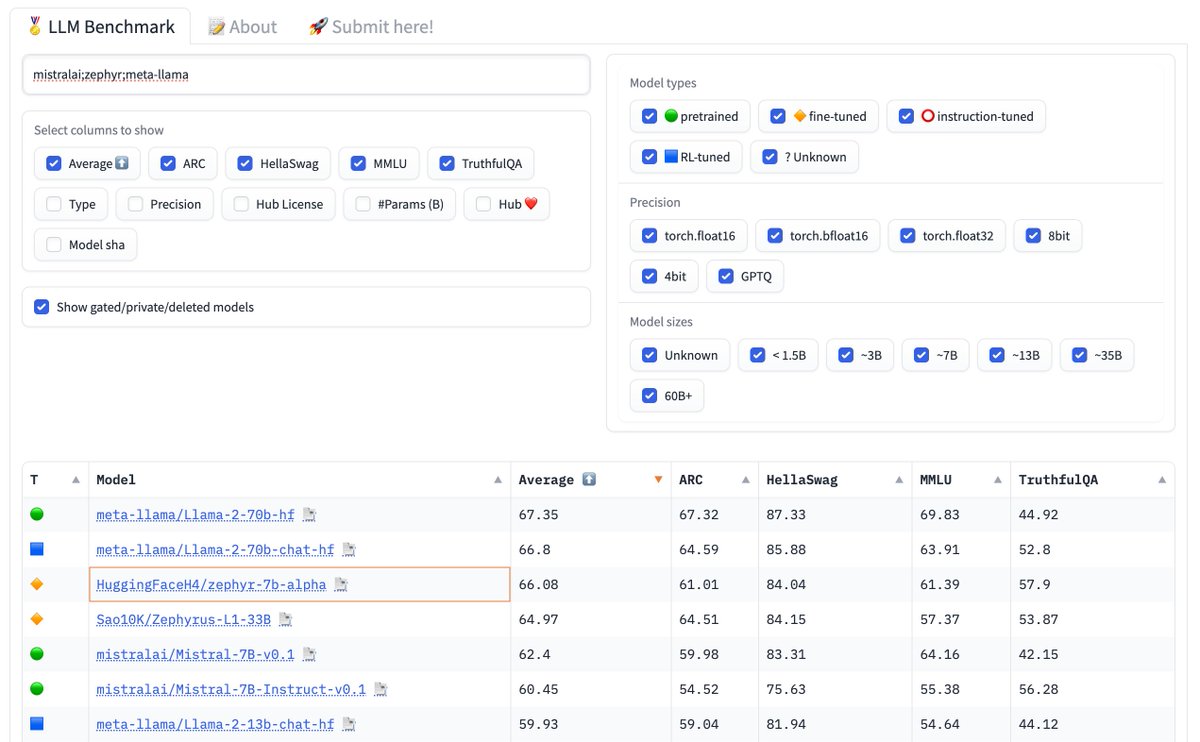
Now you can search and compare multiple models on the Open LLM leaderboard just by separating multiple queries by a semicolon! 🚀 Here im comparing meta-llama, mistralai and zephyr :) https://t.co/6MO9dEIey3
To be honest I didn't have high expectations of Mixed Reality since I was spoiled with solid VR experiences. I never thought MR could hold a torch to what joy VR brings to me. But more and more each day I've realized that VR/AR/MR are all their own things in this genre of gaming. https://t.co/ENlDybwySz
🏔️ Introducing Summit: your personal AI for your most important life goals. 🎯 Easily track, organize and break down goals 🤝 Single and multi-player accountability 🤖 Personalized coach you can text/chat/talk to "ChatGPT for self improvement" 👉 https://t.co/IA8tmetdIu https://t.co/ApbSTGKnsu
Try XTTS streaming on @huggingface 🐸🤗 Scroll quickly to beat the audio! ⏱️🔥 https://t.co/Gun6KASEMj https://t.co/36z5fsOi9r
The quality of your embeddings can have a huge impact on the effectiveness of your retrieval, which is critical to the quality of your RAG system. @Shahules786 looks at how to pick the best embeddings for your specific data. https://t.co/f6Q9XZfSkt https://t.co/pGS355hy9J

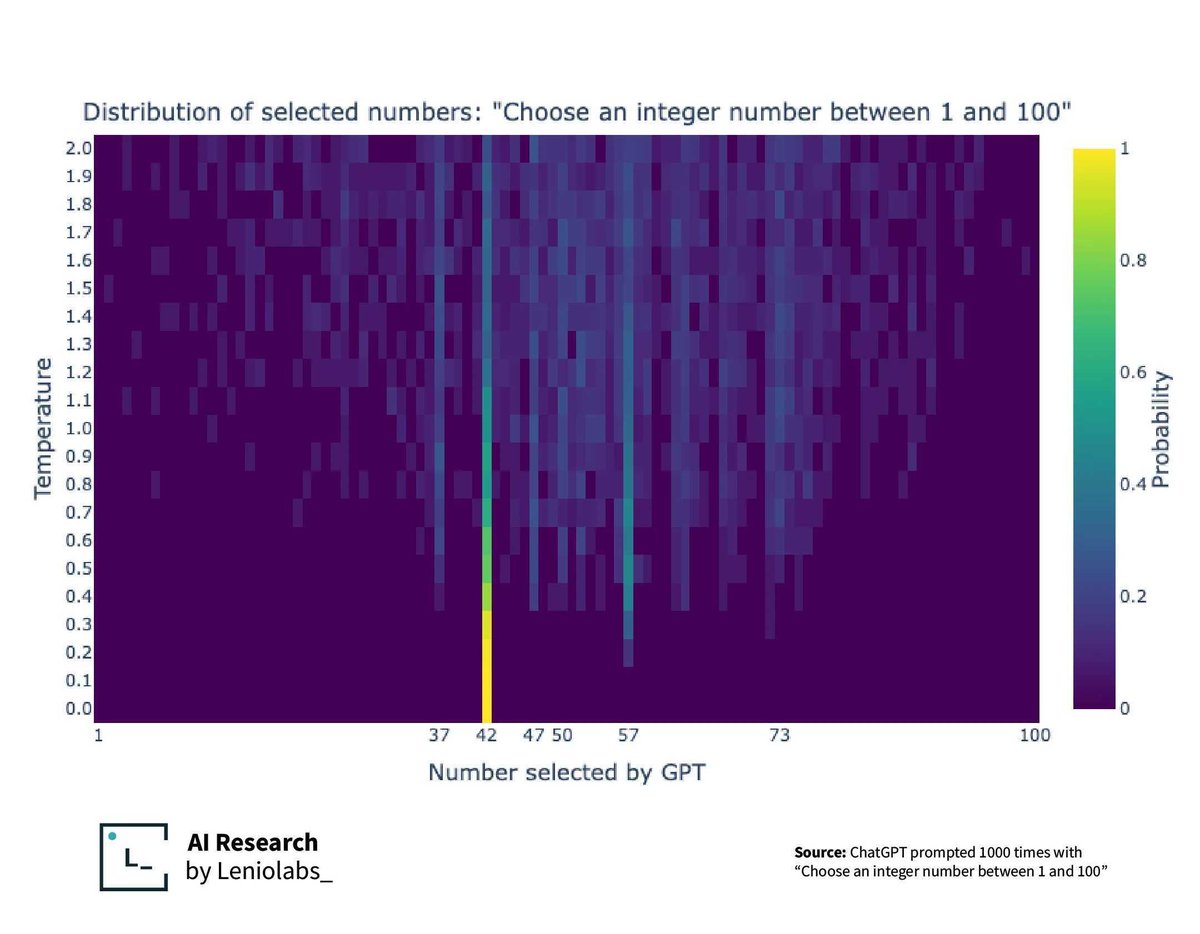
Douglas Adams had more of an impact on AI than you thought. Temperature makes your LLM more predictable, but can also exposes the bias in it's training data. https://t.co/pDRt03lqMh https://t.co/Uq6jWamiLl
Instruction Tuning the Largest Pretrained Retrieval-Augmented LLM This exciting new paper from NVIDIA introduces Retro 48B, the largest LLM pretrained with retrieval. Continues pretraining a 43B parameter GPT model on additional 100B tokens by retrieving from 1.2T tokens (using the Retro augmentation method). The Retro 48B model shows significant perplexity improvement over its GPT 43B counterpart. Scaling the Retro model to 48B means it can be instruction-tuned more effectively. This work applies instruction tuning to Retro 48B and demonstrates significant improvement (+7%) over the instruction-tuned GPT on zero-shot question-answering tasks. The important insight from this work is the potential benefit attained from pretraining with retrieval. Results highlight the promising direction to obtain a better GPT decoder for QA through continued pretraining with retrieval before instruction tuning. https://t.co/EORkgCXsz2
Introduction to Modern Statistics If you are studying computer science or machine learning, it's worth every minute learning about Statistics. This online book looks like a great place to start. FREE PDF is also available. This is an absolute gem! https://t.co/YTTZnidbAs
Been pretty excited waiting for @MistralAI's new paper about how the model is able to beat (in all of our tests) models 3-10x the size. Sliding Window Attention seems to be the main reason - and it's genius. Let me explain why it's brilliant and what I understand. https://t.co/dUyDVhlXBk
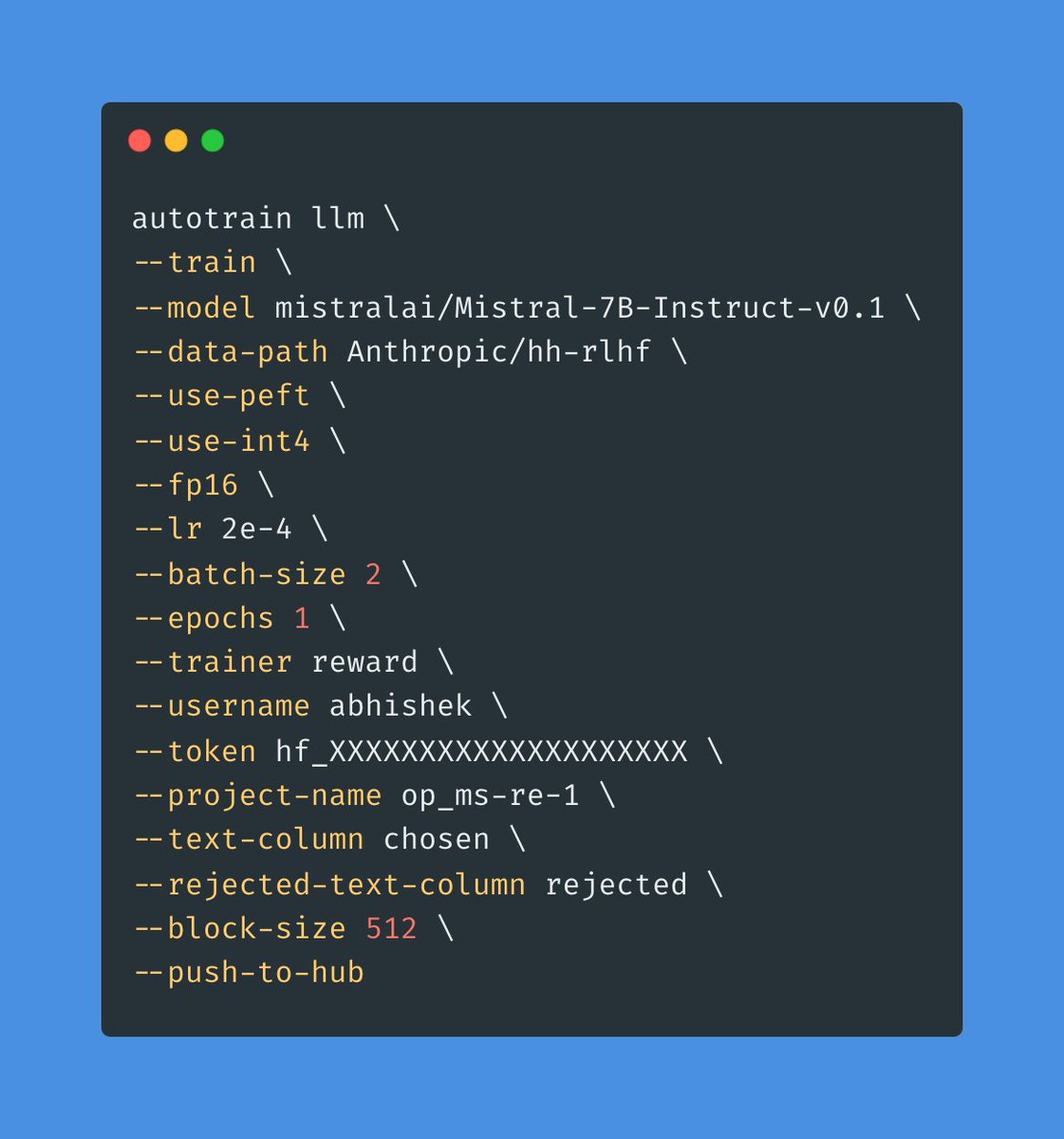
🚀 With just a few CLI params, AutoTrain Advanced now lets you train a reward model! ML engineers, rejoice! 🎉 No-code? No problem! 🔥 Just pip install autotrain-advanced and let your system work for you! 💥 https://t.co/H3DzALhYYH
Our textbook generation is really cooking now. Now putting out ~500m tokens/day of RAG-grounded synthetic textbooks with a fine-tuned Mistral 7b. That's a good fraction of a public library. Thx in part to the help from @winglian https://t.co/MYkHl1BBTS
Jackalope 7B has arrived. Finetuned on @MistralAI, we use a SlimOrca that achieves the same performance as OpenOrca with 65% of the data. We didn't stop there for Jackalope. We include PIPPA for multi-turn RP, MetaMathQA, and datasets by @ldjconfirmed https://t.co/WE8SP99Yci 🧵👇 https://t.co/XZmv8evH2j

In 2021, Meta Reality Labs published a method called Pixel Codec Avatars (PiCA). I didn't realize its significance until @lexfridman's one-of-a-kind podcast. PiCA is actually the MP4 format for VR. A brand new protocol for 3D streaming. Here's the intuition: - The encoder first compresses the image captured by VR face cam into a latent code. The code captures the fine-grained facial expression and nuances, which give Lex's interview a hyper-realistic touch. - Send the latent code over internet - wayyy more efficient than sending 3D mesh or images over. - The decoder does two things: (1) Reconstruct the global, 3D geometry of the face & expression in real-time. (2) Re-render the color at each pixel, given a particular viewing angle. PiCA does NOT render any pixels that are occluded, i.e. the back of Lex and Mark's heads actually don't exist. I find an intriguing connection to the Simulation Hypothesis: the world isn't there until you actively look at it.

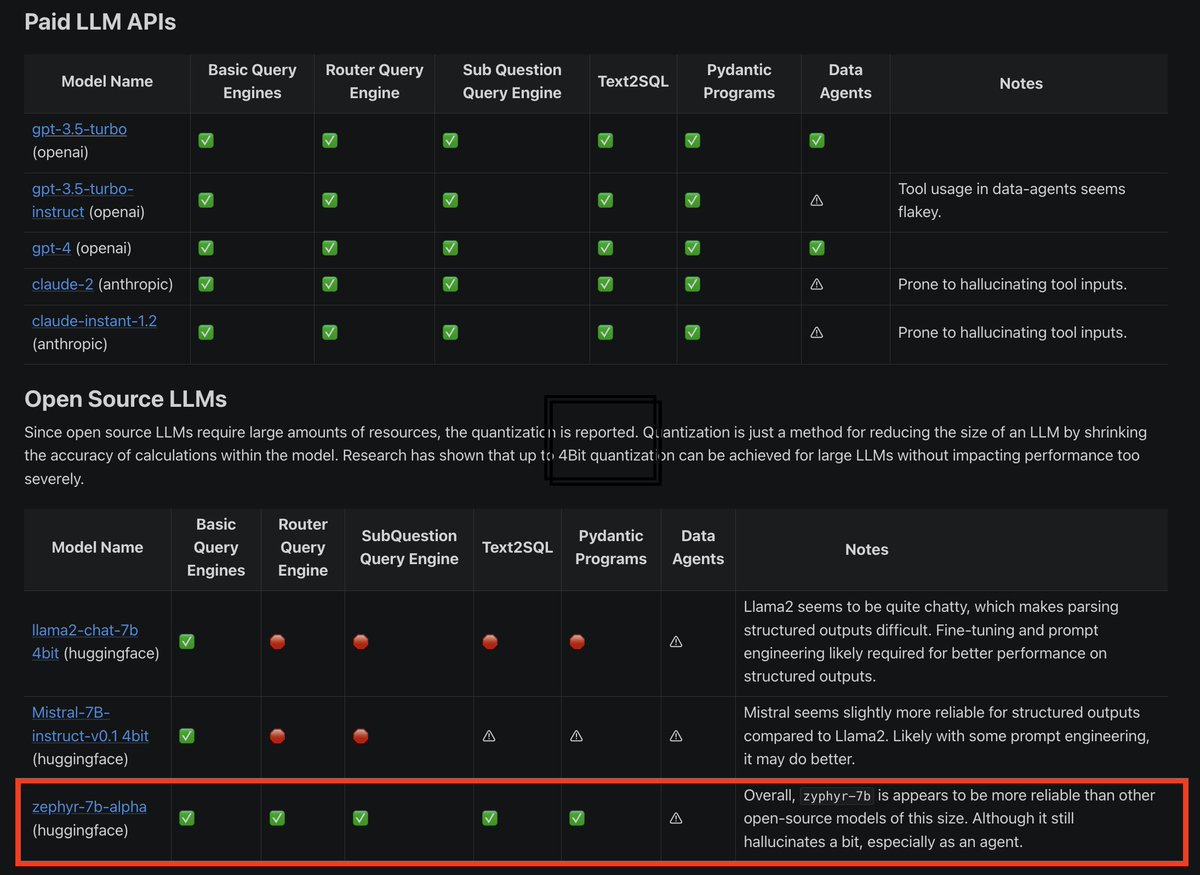
The recent @huggingface zephyr-7b-alpha model outperforms ChatLlama 70B 😮 We immediately tested it on @llama_index easy-to-hard tasks 🧪 We found that it is the ONLY open 7B model atm that does well on advanced RAG/agentic tasks 🔥👇 Colab: https://t.co/IzehsZZZz9 https://t.co/yB9xwLAwLx