@iScienceLuvr
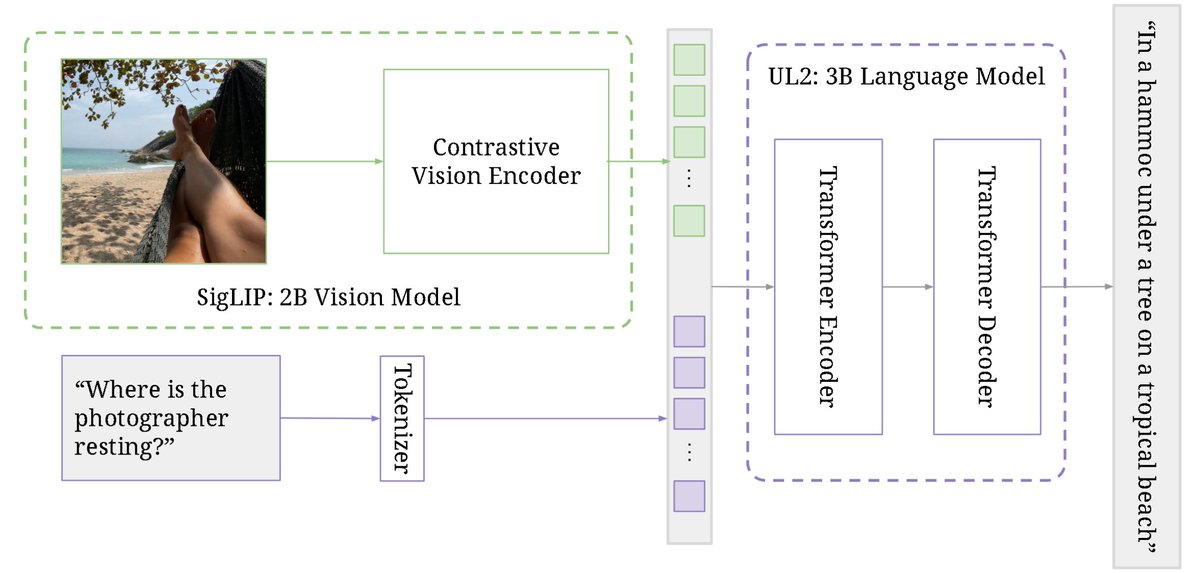
PaLI-3 Vision Language Models: Smaller, Faster, Stronger abs: https://t.co/VATjcGkZXi Uses a 2B SigLIP vision encoder and 3B UL2 language model to obtain SOTA performance on visually-situated text understanding tasks. SigLIP observed to be a better encoder than classification-pretrained ViT. Model generalizes to video understanding tasks despite not being trained with videos.