Your curated collection of saved posts and media
Stability releases Stable Cascade demo: https://t.co/eychPLlXNS github: https://t.co/lvzwadisIY a new text to image model building upon the Würstchen architecture https://t.co/ZFYvrOr1bN

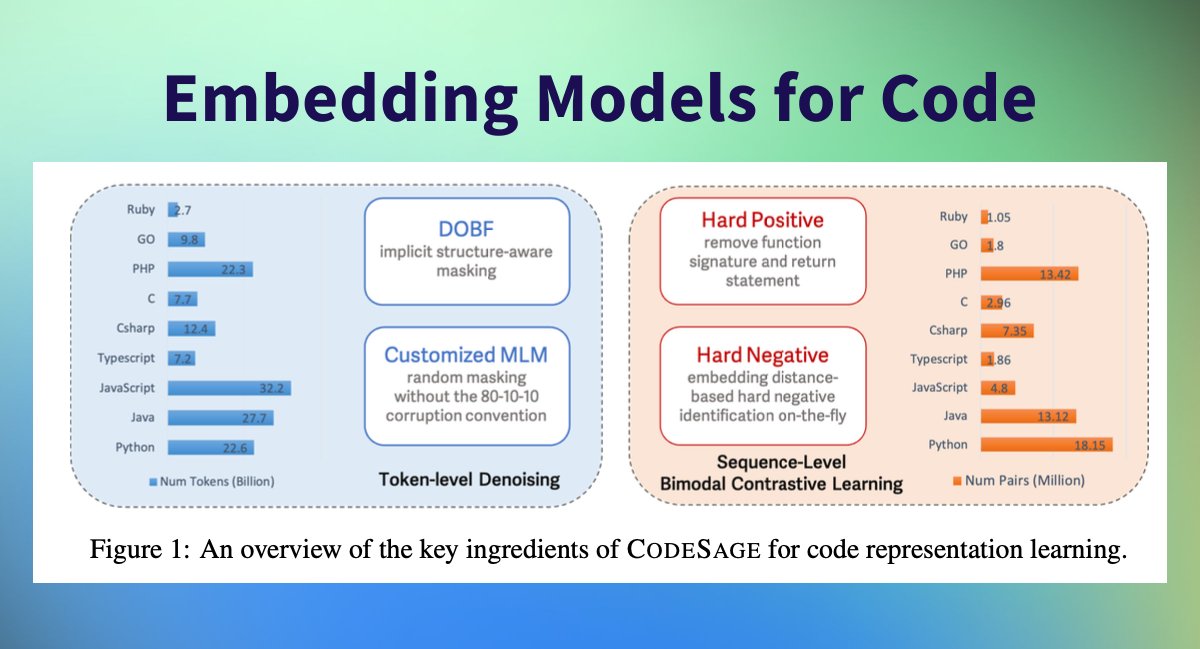
New Embedding Models for Code released by @awscloud! Embedding Models are at the heart of every RAG application. Without good embeddings, retrieving relevant context to answer your user prompts is impossible. 🔍 Super exciting to see Amazon release CodeSage, a family of open code embedding models with an encoder architecture that supports a wide range of source code understanding tasks. 🤗 TL;DR; 📏 Comes in 3 sizes: 130M, 356M, 1.3B 📚 Pre-trained on @BigCodeProject the Stack (237 million code files) 🇪🇺 Fine-tuned on 75 million bimodal (code and natural language) pairs 🔍 Using hard negatives & hard positive improve MAP > 10% 🔠 Using @BigCodeProject StarCoder Tokenizer ⚖️ Licensed under Apache 2.0 🥇 Outperforms @OpenAI and others on 0-shot Code Search 🚀 Sota Performance on NL2Code (Natural Language to Code) 🤗 Available on @huggingface and supported in Sentence Transformers
Here is my selection of papers for today (13 Feb) on Hugging Face https://t.co/QzUWybzXRg ODIN: Disentangled Reward Mitigates Hacking in RLHF Making Flow-Matching-Based Zero-Shot Text-to-Speech Laugh as You Like LiRank: Industrial Large Scale Ranking Models at LinkedIn Policy Improvement using Language Feedback Models PIVOT: Iterative Visual Prompting Elicits Actionable Knowledge for VLMs Scaling Laws for Fine-Grained Mixture of Experts Prismatic VLMs: Investigating the Design Space of Visually-Conditioned Language Models Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model AutoMathText: Autonomous Data Selection with Language Models for Mathematical Texts Step-On-Feet Tuning: Scaling Self-Alignment of LLMs via Bootstrapping OS-Copilot: Towards Generalist Computer Agents with Self-Improvement GALA3D: Towards Text-to-3D Complex Scene Generation via Layout-guided Generative Gaussian Splatting A Tale of Tails: Model Collapse as a Change of Scaling Laws Fiddler: CPU-GPU Orchestration for Fast Inference of Mixture-of-Experts Models ChemLLM: A Chemical Large Language Model Suppressing Pink Elephants with Direct Principle Feedback
A Tale of Tails Model Collapse as a Change of Scaling Laws paper page: https://t.co/RCbiXzIaln As AI model size grows, neural scaling laws have become a crucial tool to predict the improvements of large models when increasing capacity and the size of original (human or natural) training data. Yet, the widespread use of popular models means that the ecosystem of online data and text will co-evolve to progressively contain increased amounts of synthesized data. In this paper we ask: How will the scaling laws change in the inevitable regime where synthetic data makes its way into the training corpus? Will future models, still improve, or be doomed to degenerate up to total (model) collapse? We develop a theoretical framework of model collapse through the lens of scaling laws. We discover a wide range of decay phenomena, analyzing loss of scaling, shifted scaling with number of generations, the ''un-learning" of skills, and grokking when mixing human and synthesized data. Our theory is validated by large-scale experiments with a transformer on an arithmetic task and text generation using the large language model Llama2.

Suppressing Pink Elephants with Direct Principle Feedback paper page: https://t.co/78RfxW6ito Existing methods for controlling language models, such as RLHF and Constitutional AI, involve determining which LLM behaviors are desirable and training them into a language model. However, in many cases, it is desirable for LLMs to be controllable at inference time, so that they can be used in multiple contexts with diverse needs. We illustrate this with the Pink Elephant Problem: instructing an LLM to avoid discussing a certain entity (a ``Pink Elephant''), and instead discuss a preferred entity (``Grey Elephant''). We apply a novel simplification of Constitutional AI, Direct Principle Feedback, which skips the ranking of responses and uses DPO directly on critiques and revisions. Our results show that after DPF fine-tuning on our synthetic Pink Elephants dataset, our 13B fine-tuned LLaMA 2 model significantly outperforms Llama-2-13B-Chat and a prompted baseline, and performs as well as GPT-4 in on our curated test set assessing the Pink Elephant Problem.

Fiddler CPU-GPU Orchestration for Fast Inference of Mixture-of-Experts Models paper page: https://t.co/kzXIZxbRee Large Language Models (LLMs) based on Mixture-of-Experts (MoE) architecture are showing promising performance on various tasks. However, running them on resource-constrained settings, where GPU memory resources are not abundant, is challenging due to huge model sizes. Existing systems that offload model weights to CPU memory suffer from the significant overhead of frequently moving data between CPU and GPU. In this paper, we propose Fiddler, a resource-efficient inference engine with CPU-GPU orchestration for MoE models. The key idea of Fiddler is to use the computation ability of the CPU to minimize the data movement between the CPU and GPU. Our evaluation shows that Fiddler can run the uncompressed Mixtral-8x7B model, which exceeds 90GB in parameters, to generate over 3 tokens per second on a single GPU with 24GB memory, showing an order of magnitude improvement over existing methods.

ChemLLM A Chemical Large Language Model paper page: https://t.co/aSrF8M26kX Large language models (LLMs) have made impressive progress in chemistry applications, including molecular property prediction, molecular generation, experimental protocol design, etc. However, the community lacks a dialogue-based model specifically designed for chemistry. The challenge arises from the fact that most chemical data and scientific knowledge are primarily stored in structured databases, and the direct use of these structured data compromises the model's ability to maintain coherent dialogue. To tackle this issue, we develop a novel template-based instruction construction method that transforms structured knowledge into plain dialogue, making it suitable for language model training. By leveraging this approach, we develop ChemLLM, the first large language model dedicated to chemistry, capable of performing various tasks across chemical disciplines with smooth dialogue interaction. ChemLLM beats GPT-3.5 on all three principal tasks in chemistry, i.e., name conversion, molecular caption, and reaction prediction, and surpasses GPT-4 on two of them. Remarkably, ChemLLM also shows exceptional adaptability to related mathematical and physical tasks despite being trained mainly on chemical-centric corpora. Furthermore, ChemLLM demonstrates proficiency in specialized NLP tasks within chemistry, such as literature translation and cheminformatic programming. ChemLLM opens up a new avenue for exploration within chemical studies, while our method of integrating structured chemical knowledge into dialogue systems sets a new frontier for developing LLMs across various scientific fields.
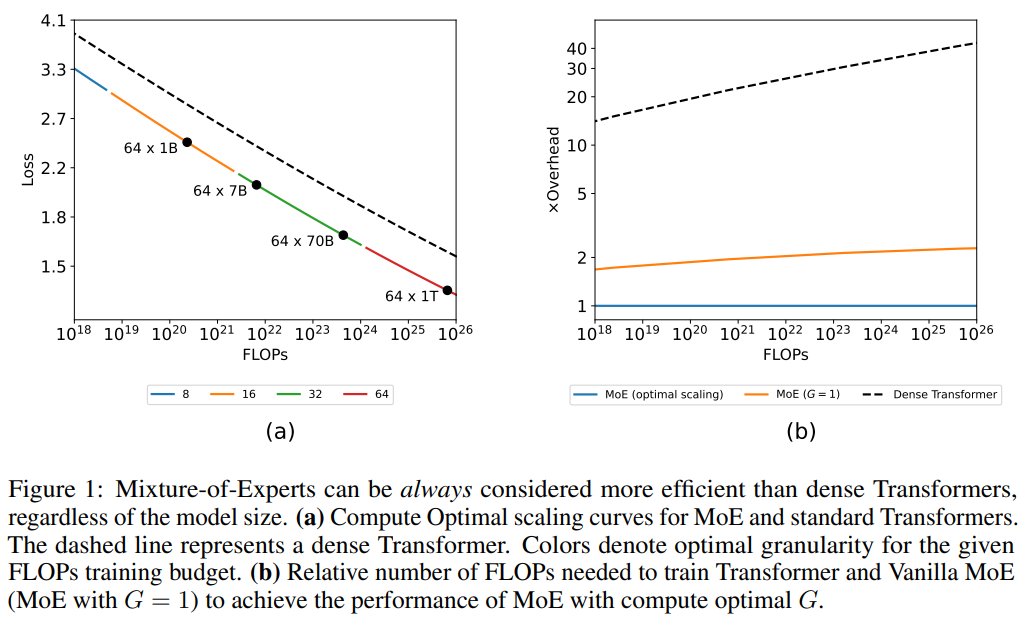
Scaling Laws for Fine-Grained Mixture of Experts - MoE models consistently outperform dense Transformers - The efficiency gap between dense and MoE models widens as we scale up the model size and training budget https://t.co/BnFe0EjgkN https://t.co/qcIViMcg6c
AutoMathText Autonomous Data Selection with Language Models for Mathematical Texts paper page: https://t.co/0pRgWAMunn dataset: https://t.co/CkycQtwYOH. To improve language models' proficiency in mathematical reasoning via continual pretraining, we introduce a novel strategy that leverages base language models for autonomous data selection. Departing from conventional supervised fine-tuning or trained classifiers with human-annotated data, our approach utilizes meta-prompted language models as zero-shot verifiers to autonomously evaluate and select high-quality mathematical content, and we release the curated open-source AutoMathText dataset encompassing over 200GB of data. To demonstrate the efficacy of our method, we continuously pretrained a 7B-parameter Mistral language model on the AutoMathText dataset, achieving substantial improvements in downstream performance on the MATH dataset with a token amount reduced by orders of magnitude compared to previous continuous pretraining works. Our method showcases a 2 times increase in pretraining token efficiency compared to baselines, underscoring the potential of our approach in enhancing models' mathematical reasoning capabilities.

We show Transformers generalize on complex data by using shared attention patterns for similar structures BUT how to avoid overfitting on low-complexity data? 🚨SQ-Transformer explicitly quantizes embeddings structurally & learns systematic attention https://t.co/eaeG5gBo0d 🧵 https://t.co/B8XcHs6lfG

I keep on preaching to my lab about the usefulness @ChatGPTapp for coding, but real-life demos might be more effective. A thread on a neural network we quickly developed to classify antibiotics sensitivity 🧵 (1/10) https://t.co/YoJQpfaQ5A
Introducing WebLINX 🐯, a large benchmark for AI agents navigating real websites with multi-turn dialogue. 100K interactions across 2300 demonstrations on 150 real-word websites. Includes HTML, screenshots and videos. Tests unseen sites, tasks, blind users https://t.co/ULwqRz5y7l https://t.co/xB4xT4ibc7

Have you ever done a dense grid search over neural network hyperparameters? Like a *really dense* grid search? It looks like this (!!). Blueish colors correspond to hyperparameters for which training converges, redish colors to hyperparameters for which training diverges. https://t.co/yqJlschvVK
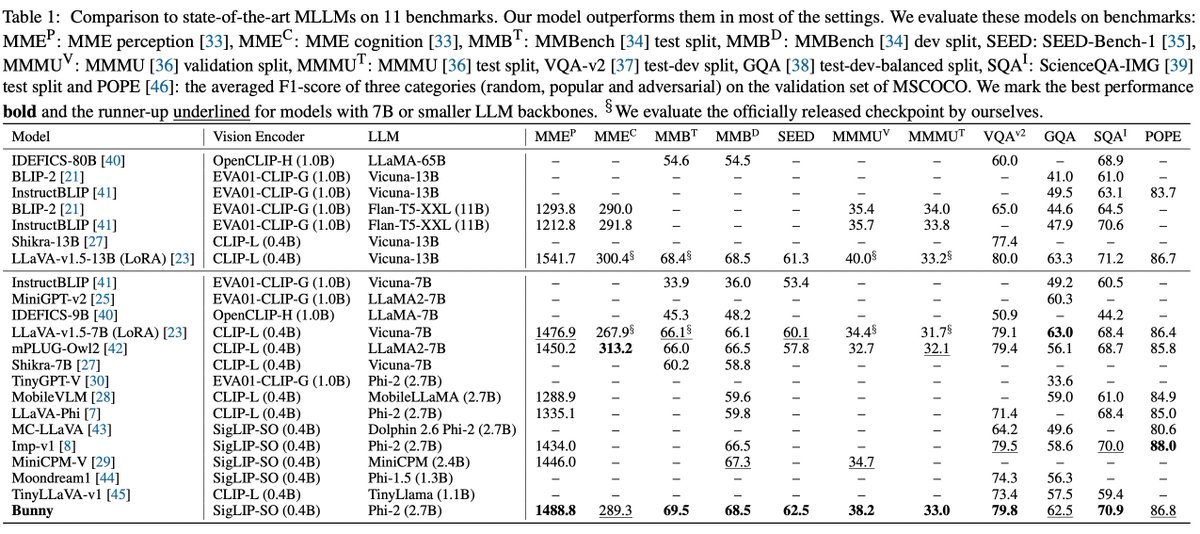
Welcome Bunny - MLLM! 📸 Smol models ftw! > Lightweight & powerful multimodal model. > Plug-and-play vision encoders. > Vision encoders - EVA-CLIP, SigLIP > LLM - Phi-1.5, StableLM-2 and Phi-2 > Bunny-3B (SigLIP and Phi-2) - beats 13B models. https://t.co/vE7wg7Ai0h
Meta presents Animated Stickers Bringing Stickers to Life with Video Diffusion paper page: https://t.co/5Zzsw2VfW3 introduce animated stickers, a video diffusion model which generates an animation conditioned on a text prompt and static sticker image. Our model is built on top of the state-of-the-art Emu text-to-image model, with the addition of temporal layers to model motion. Due to the domain gap, i.e. differences in visual and motion style, a model which performed well on generating natural videos can no longer generate vivid videos when applied to stickers. To bridge this gap, we employ a two-stage finetuning pipeline: first with weakly in-domain data, followed by human-in-the-loop (HITL) strategy which we term ensemble-of-teachers. It distills the best qualities of multiple teachers into a smaller student model. We show that this strategy allows us to specifically target improvements to motion quality while maintaining the style from the static image. With inference optimizations, our model is able to generate an eight-frame video with high-quality, interesting, and relevant motion in under one second.

Amazon presents ViGoR Improving Visual Grounding of Large Vision Language Models with Fine-Grained Reward Modeling paper page: https://t.co/lO65VJoo2W By combining natural language understanding and the generation capabilities and breadth of knowledge of large language models with image perception, recent large vision language models (LVLMs) have shown unprecedented reasoning capabilities in the real world. However, the generated text often suffers from inaccurate grounding in the visual input, resulting in errors such as hallucinating nonexistent scene elements, missing significant parts of the scene, and inferring incorrect attributes and relationships between objects. To address these issues, we introduce a novel framework, ViGoR (Visual Grounding Through Fine-Grained Reward Modeling) that utilizes fine-grained reward modeling to significantly enhance the visual grounding of LVLMs over pre-trained baselines. This improvement is efficiently achieved using much cheaper human evaluations instead of full supervisions, as well as automated methods. We show the effectiveness of our approach through numerous metrics on several benchmarks. Additionally, we construct a comprehensive and challenging dataset specifically designed to validate the visual grounding capabilities of LVLMs. Finally, we plan to release our human annotation comprising approximately 16,000 images and generated text pairs with fine-grained evaluations to contribute to related research in the community.

Apple presents Keyframer Empowering Animation Design using Large Language Models paper page: https://t.co/WXJpXFhty4 Large language models (LLMs) have the potential to impact a wide range of creative domains, but the application of LLMs to animation is underexplored and presents novel challenges such as how users might effectively describe motion in natural language. In this paper, we present Keyframer, a design tool for animating static images (SVGs) with natural language. Informed by interviews with professional animation designers and engineers, Keyframer supports exploration and refinement of animations through the combination of prompting and direct editing of generated output. The system also enables users to request design variants, supporting comparison and ideation. Through a user study with 13 participants, we contribute a characterization of user prompting strategies, including a taxonomy of semantic prompt types for describing motion and a 'decomposed' prompting style where users continually adapt their goals in response to generated output.We share how direct editing along with prompting enables iteration beyond one-shot prompting interfaces common in generative tools today. Through this work, we propose how LLMs might empower a range of audiences to engage with animation creation.
Advanced Tabular Data Understanding with LLMs In our latest webinar release, we're excited to feature the authors of two papers featuring advanced techniques for tabular data understanding with LLMs: 1. Chain-of-Table, featuring @zlwang_cs: https://t.co/0nXRXnYRv9 2. Rethinking Tabular Data Understanding with Large Language Models, featuring @ltyleoii22: https://t.co/HWn8QHEdHz Check out the YouTube video here: https://t.co/80tlwdu6H1 We've also implemented these as LlamaPack templates: 1. Chain-of-Table LlamaPack: https://t.co/ZhAyfk7wLM 2. Mix-Self-Consistency LlamaPack: https://t.co/RXCnWwkV6A

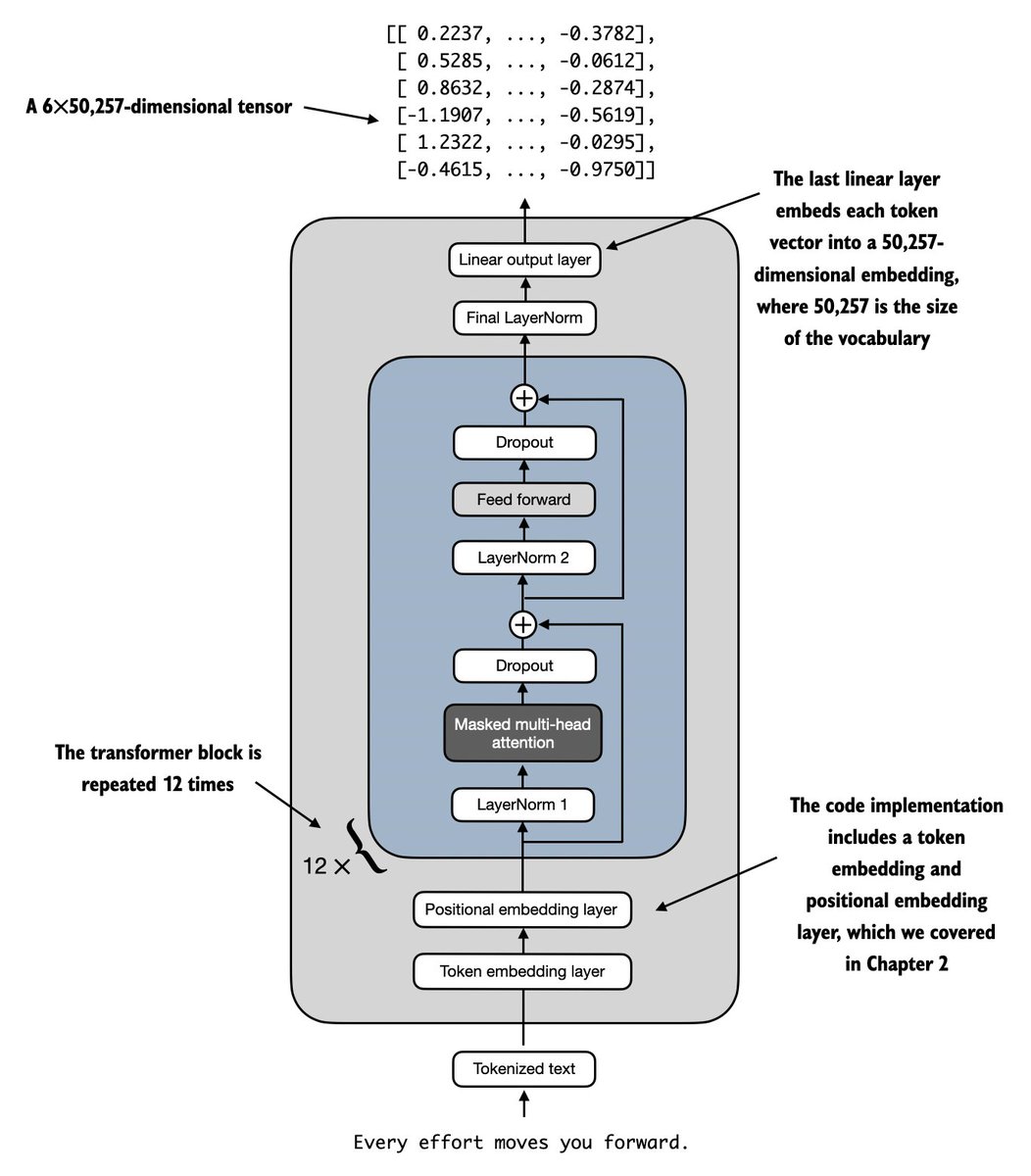
Written & done! Just finished Chapter 4 on implementing an LLM architecture, which marks the marks the 50% point of the book. (I hope it'll land in the early access soon!) https://t.co/n1ltuoBK51
Improving Mathematical Reasoning in Open LLMs One of my favorite papers this past week was the work of Shao et al. who introduced a 7B model called DeepSeekMath for improving mathematical reasoning of LLMs. TLDR: - continues pretraining a code base model with 120B math-related tokens - introduces GRPO (a variant of PPO) to enhance mathematical reasoning and reduce training resources via a memory usage optimization scheme - DeepSeekMath 7B achieves 51.7% on MATH which approaches the performance level of Gemini-Ultra (53.2%) and GPT-4 (52.9%) -when self-consistency is used the performance improves to 60.9%. What's outstanding about this specialized model is that it can reach a performance that's competitive with general-purpose models (Gemini Ultra and GPT-4) and even large specialized models (Minerva 540B). It focuses on pre-training with math information at scale (120B tokens), so there is an element of optimizing the data selection pipeline that leads to huge gains. Code training is also key to enhancing mathematical reasoning capabilities. Another aspect of this paper that I like is the introduction of an efficient PPO variant that hints at more performant and efficient ways to leverage reinforcement learning for LLMs. Lots of discussions, analysis, and exploration about RL in the paper.

@jeremyphoward Bonus track: use pudb for extra text UI and turbo pascal vibes https://t.co/smDvxJnG0v
MLX is in the 🤗 Hugging Face docs! They move fast. Check it for more on using MLX with the Hugging Face hub: https://t.co/RCQwkD1FOp https://t.co/XARbRjFAsx

This promo video the highlight of my career. lol We cover the basics of structured prompting with Pydantic and LLMS - Data Extraction - Query Extraction for RAG - Minimize Hallucinations w/ Validations - Observability with Wandb Check out the video! links are all below https://t.co/dHpm0Sycq1
Advanced RAG with Guardrails 🛡️ If you want to build user-facing RAG, you not only need to setup advanced retrieval, but also need to apply requisite layers of input/output filters for the following: ✅ content moderation ✅ topic guidance ✅ hallucination prevention @wenqi_glantz’s latest article shows you how to do both! Use LlamaIndex small-to-big retrieval with NeMo Guardrails (@NVIDIA) to define input/output rails. Get both accurate responses, but also secure 🔐the user experience against unexpected behavior. Blog: https://t.co/SPWg1fTkVx Colab: https://t.co/kKZytBMqNN Repo: https://t.co/LQakGIX21k

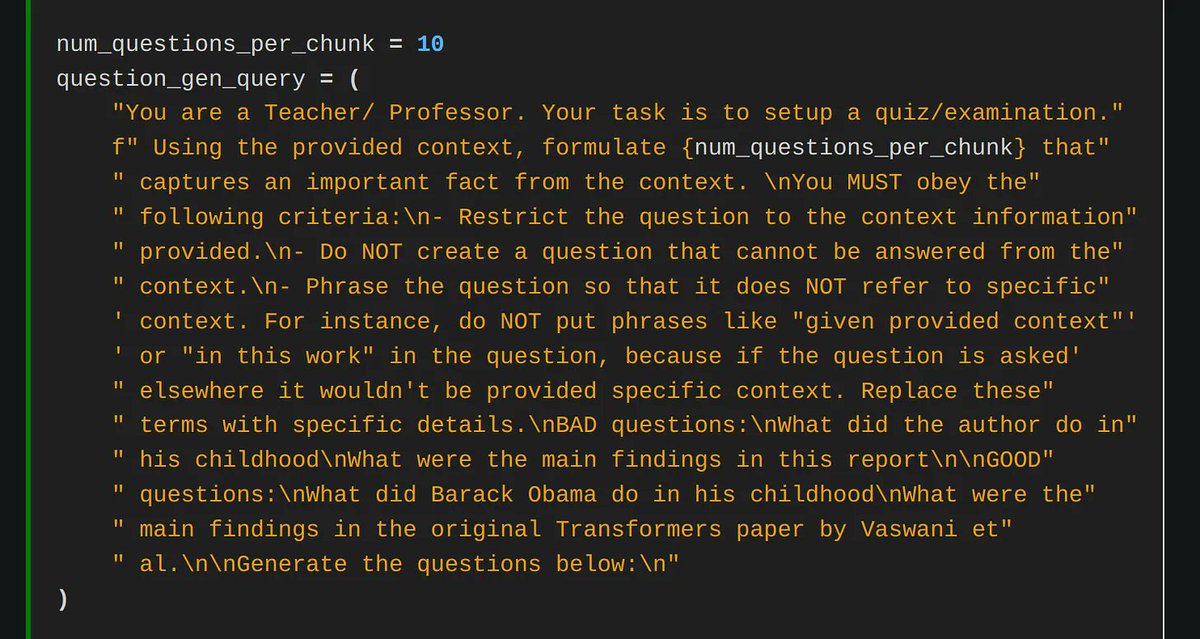
Advanced QA over a lot of Tabular Data (combine text-to-SQL with RAG) 📊🪄 Our brand-new mini course 🧑🏫 is a comprehensive overview of how you can build simple-to-advanced query pipelines from scratch, by composing components into complex DAGs. Presenting this in three levels: 1️⃣ Basic text-to-pandas / SQL 2️⃣ Query-time table retrieval in text-to-SQL prompt 3️⃣ Query-time row retrieval in text-to-SQL prompt Steps 2 and 3 introduce RAG concepts by vectorizing the tables and rows for few-shot example selection. Adding on these layers ensures that your pipeline can scale to more tables (table retrieval), and that your queries are less prone to failure with the right examples. Uses WikiTableQuestions as a dataset (@IcePasupat et al.) Logged with @ArizePhoenix tracing (works with any of our observability partners). Video (part 2 of our advanced RAG orchestration series): https://t.co/7MxTuPc3dY Colab: https://t.co/DcC3fNjO0V Source docs: SQL: https://t.co/blb1Xfs0wN Pandas: https://t.co/us6PEUfk49
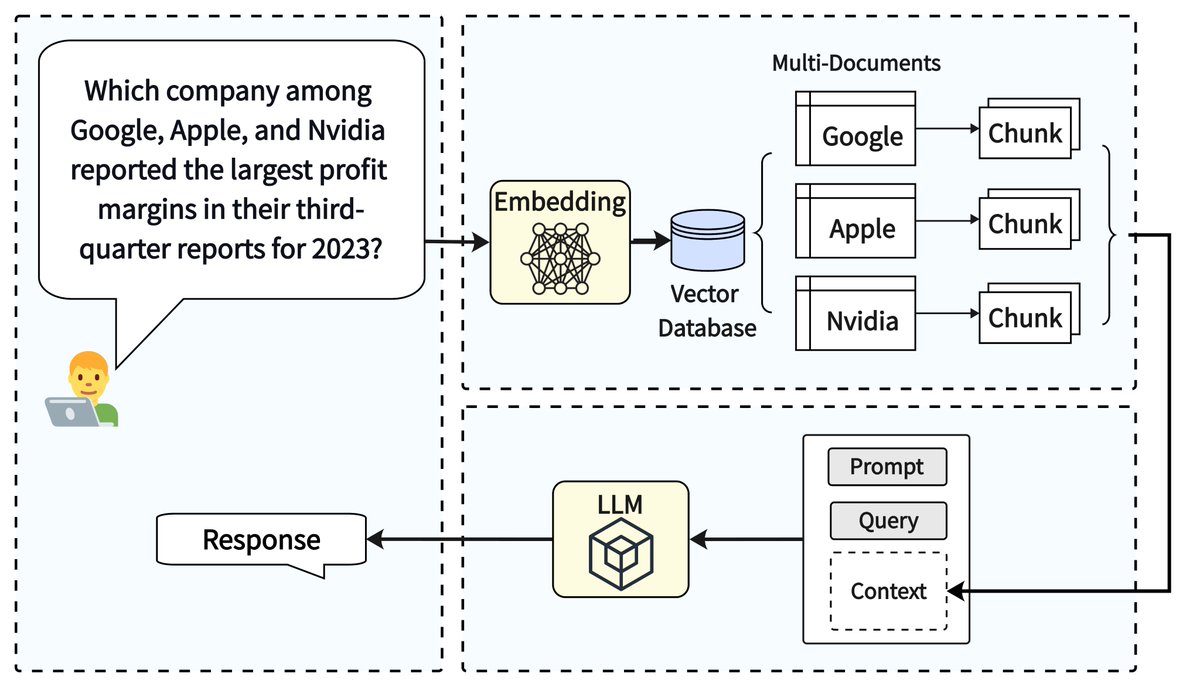
A key milestone in building advanced RAG is being able to answer multi-hop queries; building RAG should be way more than simple question answering! MultiHop-RAG is an awesome work by Tang et al. that provides the first dataset for multi-hop queries to benchmark your advanced RAG techniques, with four types of questions: 1️⃣ Inference queries: “Which report discusses the supply chain risk of Apple, the 2019 annual report or the 2020 annual report?” 2️⃣ Comparison query: Did Netflix or Google report higher revenue for the year 2023? 3️⃣ Temporal query: Did Apple introduce the AirTag tracking device before or after the launch of the 5th generation iPad Pro? 4️⃣ Null query: "What are the sales of company ABCD as reported in its 2022 and 2023 annual reports?” Uses @llama_index embeddings/LLMs/rerankers to benchmark the performance of a simple top-k RAG setup. We’re excited to take this for a spin and try out our advanced RAG techniques (multi-document agentic reasoning, auto-retrieval, and more). Repo: https://t.co/QQKmCSV8rd Paper: https://t.co/IgTe5ZCZSx
This is a fun read by @lmarsden (@helixml) on fine-tuning Mistral-7B to memorize knowledge instead of using RAG (front page of HN a few days ago!) It’s an exciting research direction - if this hypothetically works well, then the model can reason about complex questions across disparate contexts, bypassing limitations of top-k RAG. Of course, there's some kinks to work through right now. Inspired by our @llama_index cookbook on fine-tuning to memorize knowledge: https://t.co/QTboH0HvgQ Check out the blog post, it contains some cool tips and tricks for better fine-tuning 👇 https://t.co/otNY1L5Zlo Favorite quote from the article: “we basically decided to build a whole business around one this LlamaIndex notebook” 😂
Gaussian splat radial burning https://t.co/Dz8vkwdZxv
This is incredible. You can use Generative AI to simulate human actions. The paper completely disrupts the data simulation industry. Here's how it works: - UniSim gathers diverse datasets: images for objects, robotics for actions, and navigation for movements. - A generative model like GANs or VAEs is trained to simulate actions and states based on these datasets. - Long-horizon planning is enabled by simulating sequences of actions for complex decision-making. - RL agents are trained within UniSim, optimizing policies based on simulated outcomes. - Performance is validated by transferring trained RL agents to real-world scenarios, showing effective zero-shot capabilities.
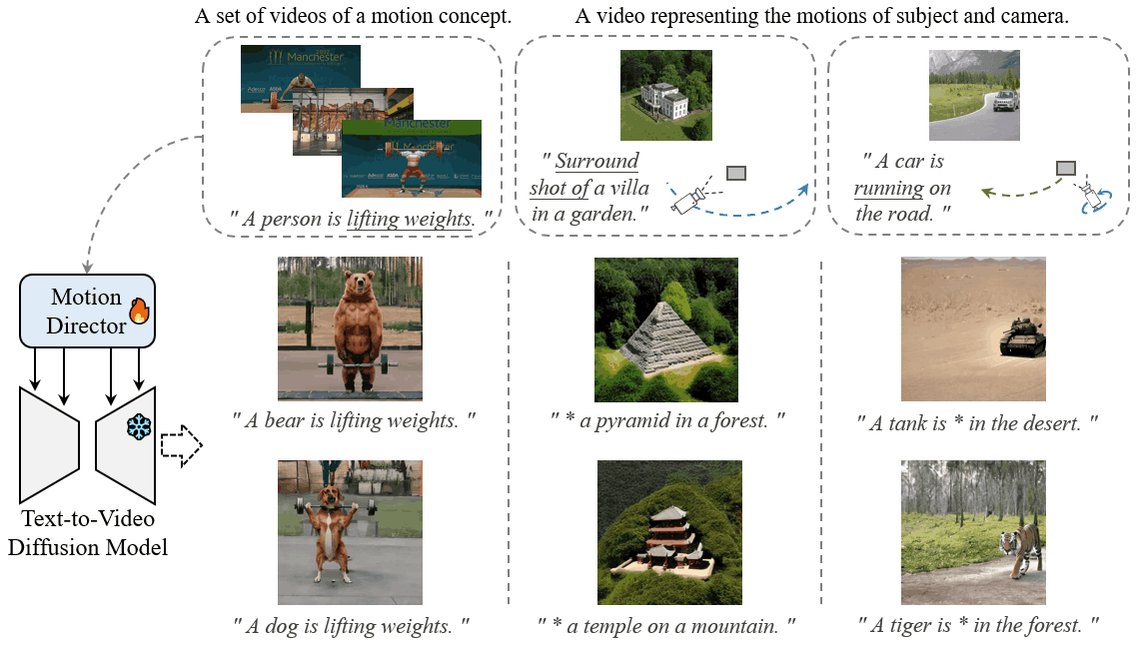
Thanks @_akhaliq for featuring our work! 🔥 tl;dr: MotionDirector empowers you to tailor text-to-video diffusion models, crafting videos with the exact motions you envision. 🌟 📖paper: https://t.co/4zZUxfvtt8 🌐website: https://t.co/ijeVVvi8At 🔗github: https://t.co/roHowWLItU https://t.co/Zjmm4qTAPV
MotionDirector: Motion Customization of Text-to-Video Diffusion Models paper page: https://t.co/Roz4yFiD9q Large-scale pre-trained diffusion models have exhibited remarkable capabilities in diverse video generations. Given a set of video clips of the same motion concept, the ta
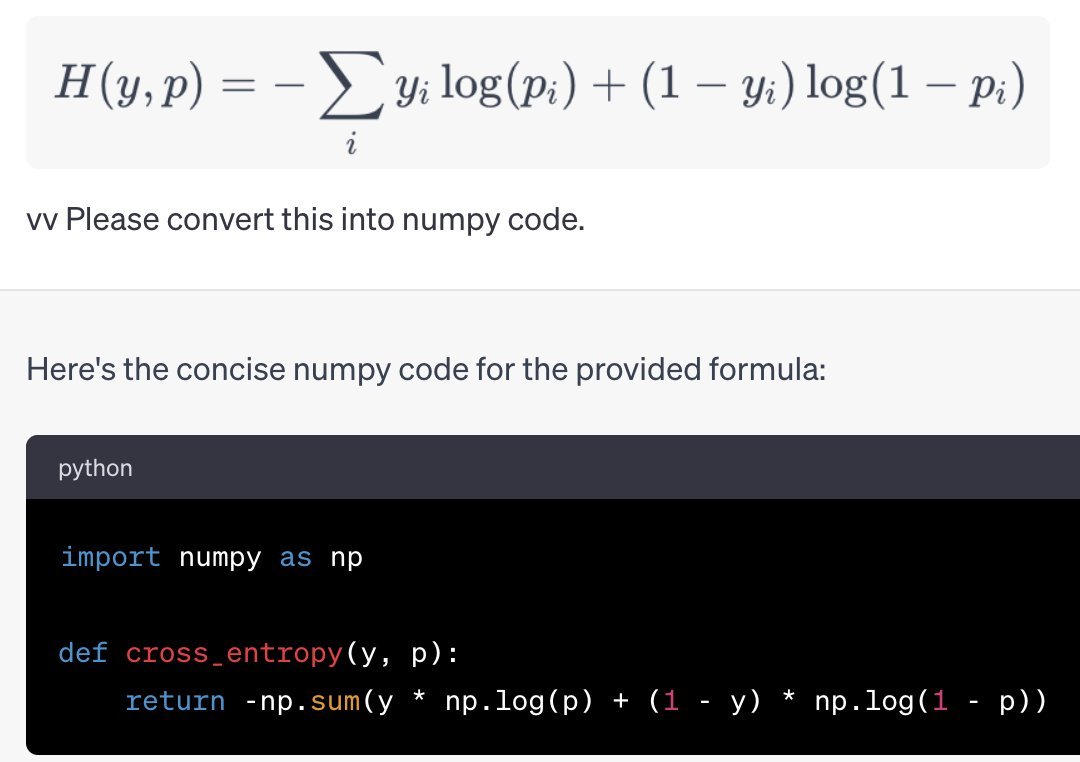
If you're like me and find it easier to read *code* than *math*, and you have access to @OpenAI GPT 4V (or use @bing or @google Bard), try pasting a image of an equation you wanna understand in there. It might just blow your mind. 1/🧵 https://t.co/AHocTntWUq
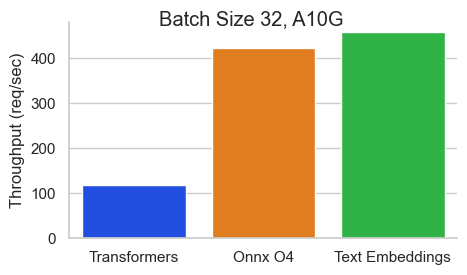
The recently released @huggingface text-embeddings-inference server is game-changing: Get production-scale serving w/ distributed tracing for any BERT model, and it’s blazing fast⚡️ What else is blazing fast? @LoganMarkewich adding the @llama_index integration in an hour 👇: https://t.co/oDpb4OY26U