@llama_index
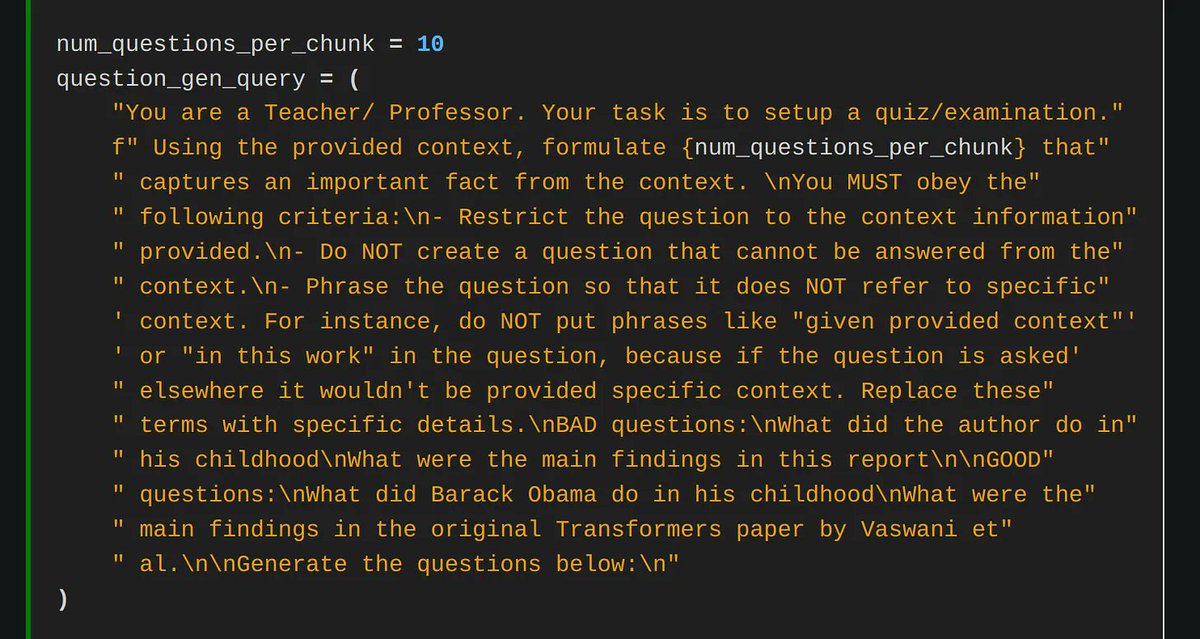
This is a fun read by @lmarsden (@helixml) on fine-tuning Mistral-7B to memorize knowledge instead of using RAG (front page of HN a few days ago!) It’s an exciting research direction - if this hypothetically works well, then the model can reason about complex questions across disparate contexts, bypassing limitations of top-k RAG. Of course, there's some kinks to work through right now. Inspired by our @llama_index cookbook on fine-tuning to memorize knowledge: https://t.co/QTboH0HvgQ Check out the blog post, it contains some cool tips and tricks for better fine-tuning 👇 https://t.co/otNY1L5Zlo Favorite quote from the article: “we basically decided to build a whole business around one this LlamaIndex notebook” 😂