Your curated collection of saved posts and media
Google presents PaLM2-VAdapter SoTA visual understanding and multi-modal reasoning capabilities with 30∼70% fewer parameters than the SoTA VLM, marking a significant efficiency improvement https://t.co/lvC4UJ0DqM https://t.co/K1zS8Mu95L
An Introduction to LlamaIndex v0.10 🦙🧑🏫 LlamaIndex has core abstractions and hundreds of integrations in our ecosystem to help you build any context-augmented LLM application: RAG, agents, and more. This video gives you a comprehensive overview of LlamaIndex v0.10 and why its the best fit for your production app: ✅ Versioned/Packaged hundreds of integrations/templates, from LLMs to vector stores to data loaders ✅ LlamaHub: your one-stop-shop for all integrations: https://t.co/x1xEDQtHa8 ✅ Guides for migration and contributing. Check it out! https://t.co/Duo4UOpFt2

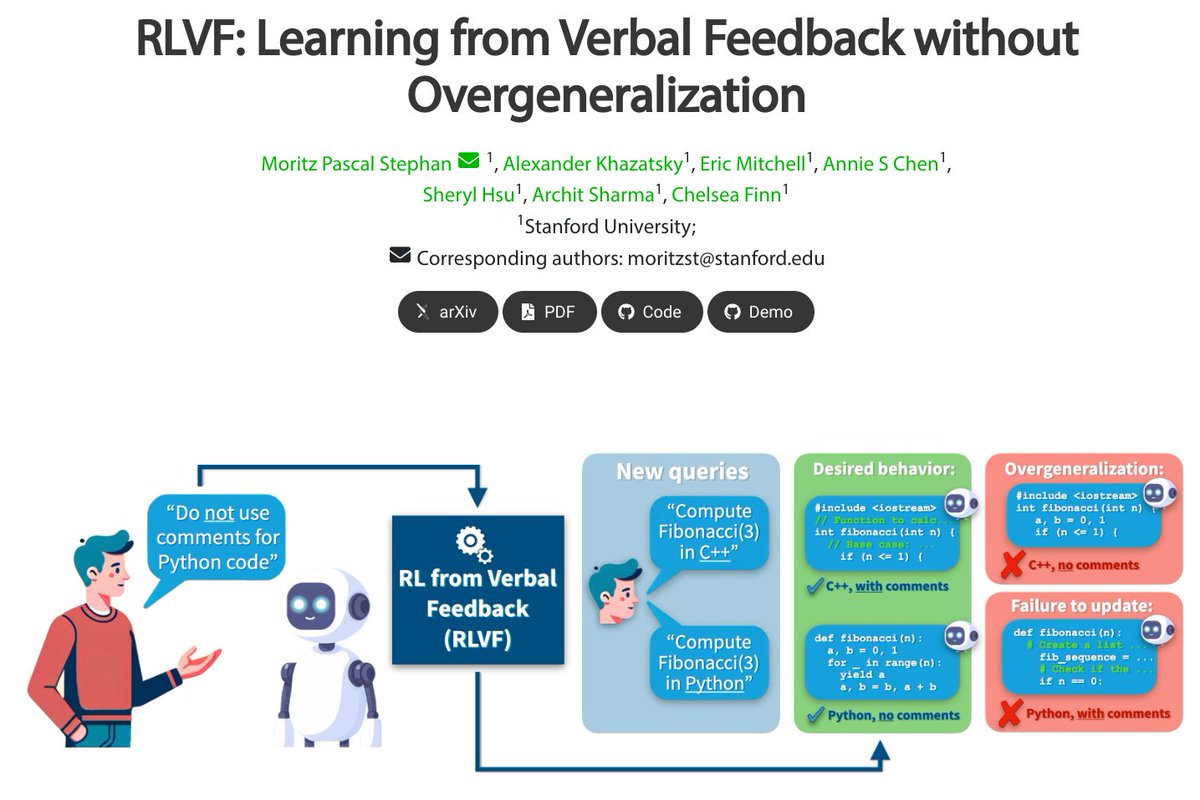
RLVF: Learning from Verbal Feedback without Overgeneralization proj: https://t.co/QN8GmwopCl abs: https://t.co/viT7VRqUNT repo: https://t.co/G3Dw32gtRL https://t.co/K7OS1Qtzd6
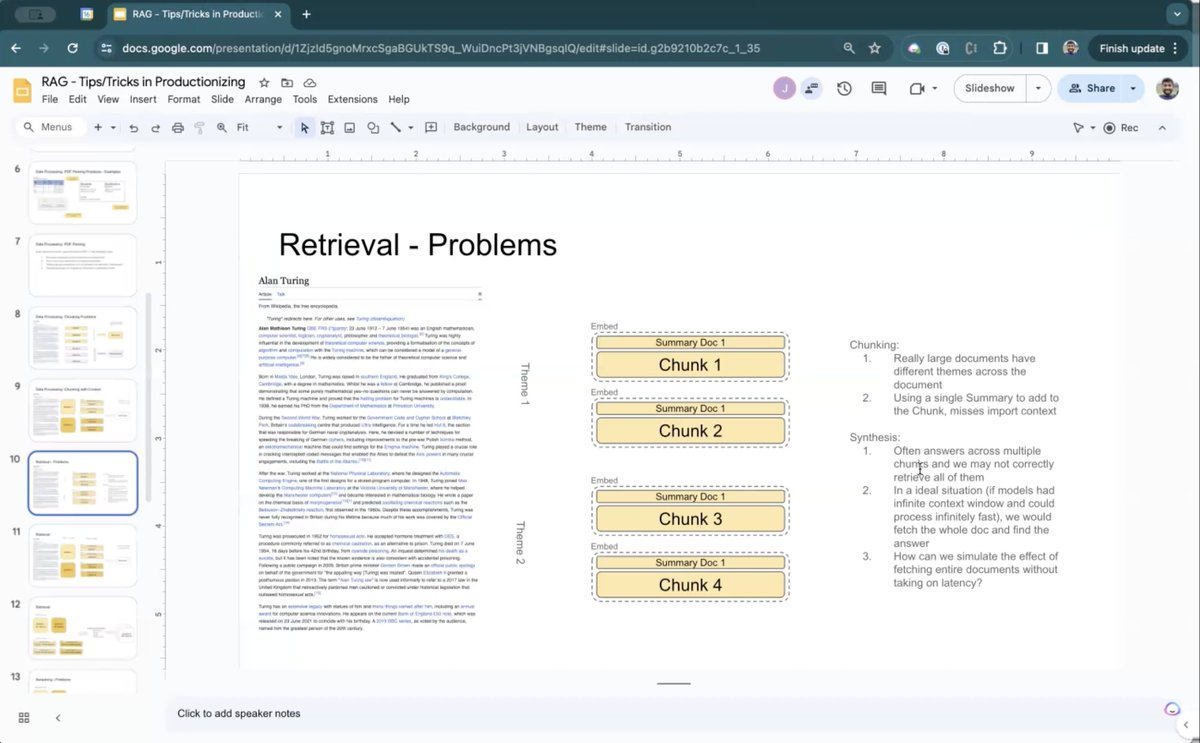
We’re excited to feature a set of novel RAG tips/tricks 💡 from @sisilmehta (@heyjasperai). These tips enabled his team to build a production app, powered by @llama_index, that serves end users! 🔥 Available in a special @llama_index session video 👇. These tips include the following: 1. Sub-document metadata: Adding the right "layers" of metadata; besides global document context, also inject summary context from "sub-documents" to more precisely localize each chunk. 2. Use LLMs to rerank chunk summaries. LLMs are quite good at reranking, but they’re slow the larger the context. Reduce token usage by reranking summaries that reference underlying chunks. 3. Use XML and emotion prompting to get well-structured outputs free of hallucinations. Video: https://t.co/DtqLJV1Idh
what https://t.co/klxxiOYAVZ

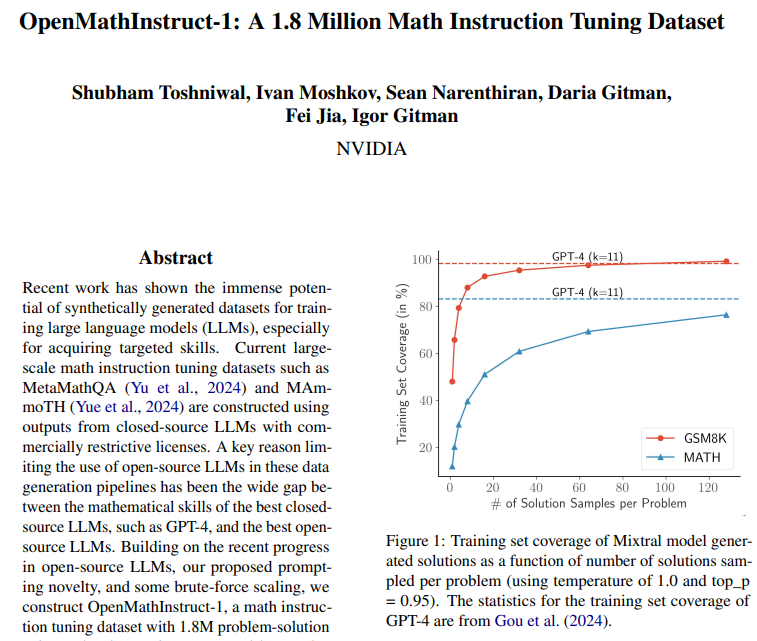
OpenMath Instruct-1 by @NVIDIAAI 🧮 > 1.8 Million Problem-Solution (synthetic) pairs. > Uses GSM8K & MATH training subsets. > Uses Mixtral 8x7B to produce the pairs. > Leverages both text reasoning + code interpreter during generation. > Released LLama, CodeLlama, Mistral, Mixtral fine-tunes along with. > Apache 2.0 licensed! Brilliant work by the Nvidia AI team - 2024 is deffo the year of Synthetic data and stronger models! 🔥
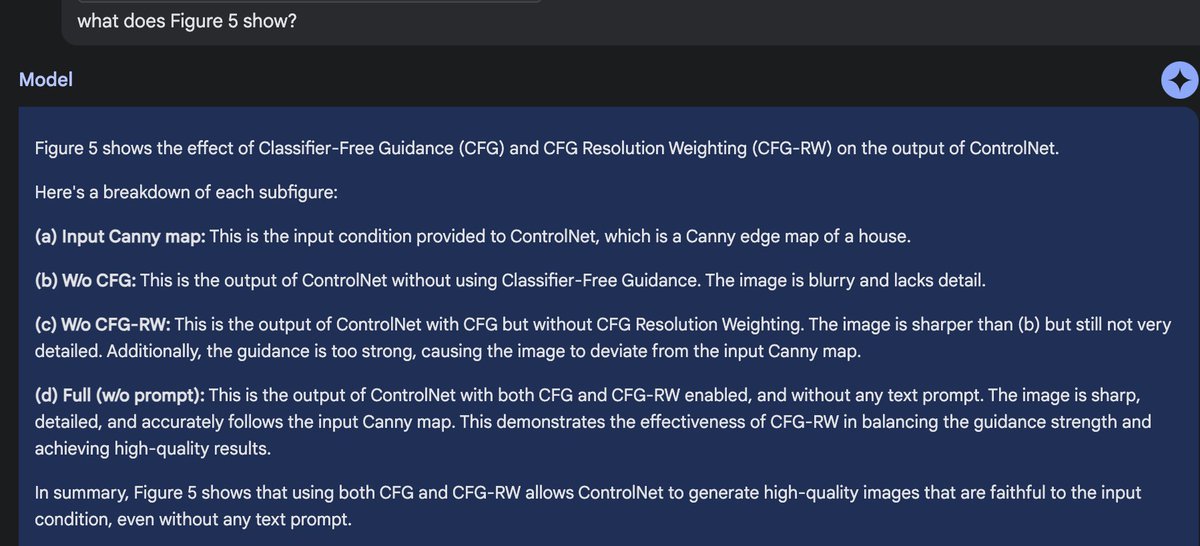
Ok, gemini 1.5 is really really good. seriously the most impressive jump i've seen in models in a while when it comes to long context just tried with a paper and asked it "what does Figure 5 show?" it contextualized the whole thing and answered based on that tiny section + figure.

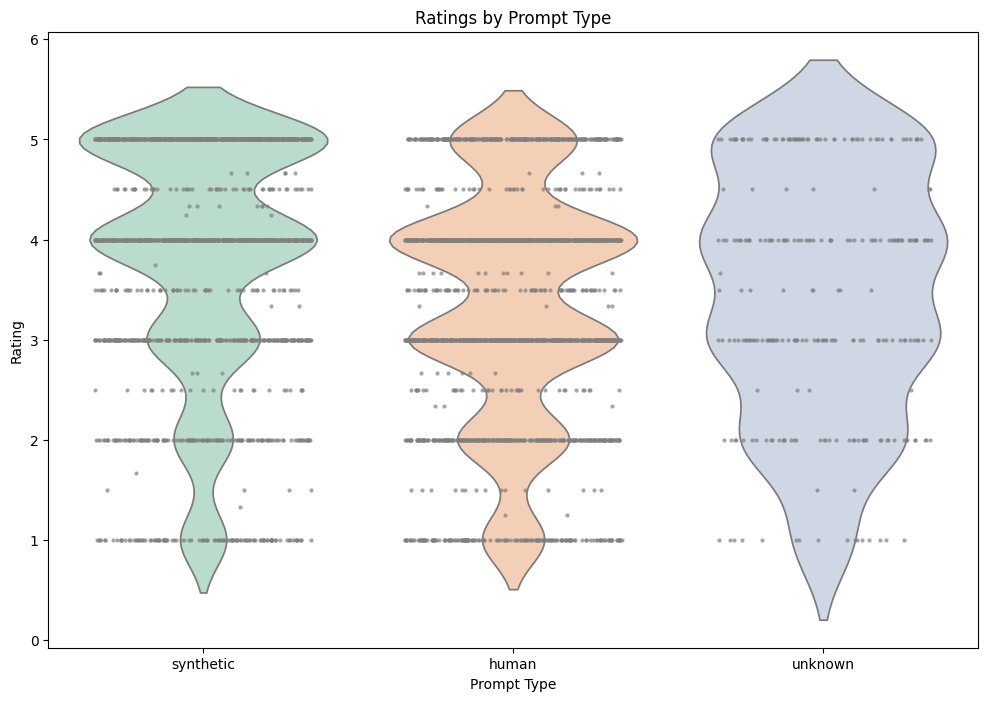
🤖👩💻Do humans prefer synthetic or human generated prompts? If you wanna know, participate in the prompt collective event and share with your friends & teammates! https://t.co/yWl1EkiG5n With +230 participants and ~4,300 ratings already, here's some interesting results 1/7🧵 https://t.co/jPZAfYhCRB
Karpathy announced he was leaving OpenAI 4 days ago. Today, he released an implementation of the Byte Pair Encoding algorithm behind GPT and most LLMs. Byte Pair Encoding: "Minimal, clean, educational code for the Byte Pair Encoding (BPE) algorithm commonly used in LLM tokenization." The best part? It's written in 70 lines of pure python.
🤗Transformers welcomes 4x speed-up by leveraging torch.compile to its very core ! Static Cache + compile for decoder models: on llama 7b ⤵️ https://t.co/TJ0xC0GrSx
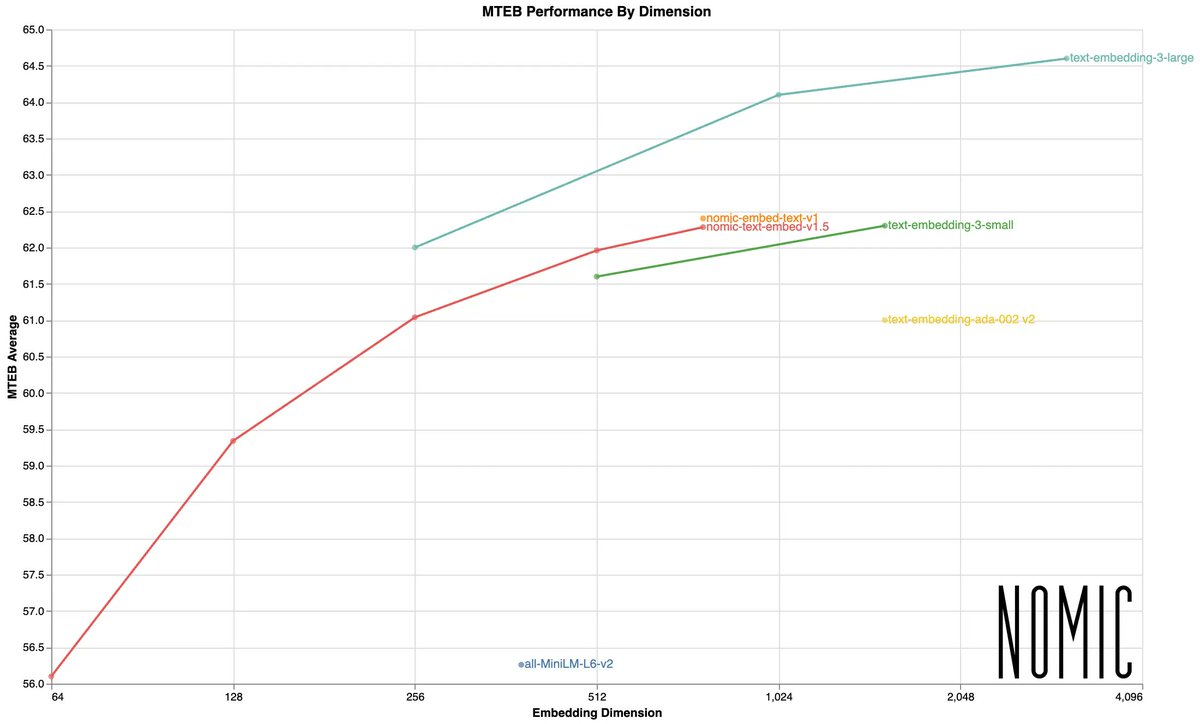
Nomic-embed-text-v1.5 is the first open-source embedding model we’ve seen that allows you to dynamically tradeoff memory, storage, bandwidth for embedding performance - get back embeddings for any dimension between 64 and 768. Inspired by Matryoshka Representation Learning that also powers the latest @OpenAI embedding models. Thanks to @ravithejads, check out our cookbook here! https://t.co/0B9MkJnXI1
Video analysis with RAG! @lancedb shows us step by step how to ➡️ Split video into frames for analysis ➡️ Extract audio to text ➡️ Embed it all into your database ➡️ Retrieve the most relevant images + text to answer questions The results are impressive! Check out the blog post here: https://t.co/ytTqqTRBND
2024 will be the year of videos. While robotics & embodied agents are just getting started, I think video AI will meet its breakthrough moments in the next 12 months. There are two parts: I/O "I": video input. GPT-4V's video understanding is still quite primitive, as it treats video as a sequence of discrete images. Sure, it kind of works, but very inefficiently. Video is a spatiotemporal volume of pixels. It is extremely high-dimensional yet redundant. In ECCV 2020, I proposed a method called RubiksNet that simply shifts around the video pixels like a Rubik's Cube along 3 axes, and then apply MLPs in between. No 3D convolution, no transformers, a bit similar to MLP-Mixer in spirit. It works surprisingly well and runs fast with my custom CUDA kernels. https://t.co/CQU8D7TZgx, w/ Shyamal Buch, @guanzhi_wang, @yukez, @drfeifei, etc. Are Transformers all you need? If yes, what's the smartest way to reduce the information redundancy? What should be the learning objective? Next frame prediction is an obvious analogy to next word prediction, but is it optimal? How to interleave with language? How to steer video learning for robotics and embodied AI? No consensus at all in the community. Part 2, "O": video output. In 2023, we have seen a wave of text-to-video synthesis: WALT (Google, cover video below), EmuVideo (Meta), Align Your Latents (NVIDIA), @pika_labs, and many more. Too many to count. Yet most of the generated snippets are still very short. I see them as video AI's "System 1" - "unconscious", local pixel movements. In 2024, I'm confident that we will see video generation with high resolution and long-term coherence. That would require much more "thinking", i.e. System 2 reasoning and long-horizon planning.
We propose ReadAgent 📖, a LLM agent that reads and reasons over text up to 20x more than the raw context length. Like humans, it decides where to pause, keeps fuzzy episodic memories of past readings, and looks up detail info as needed. Just by prompting. https://t.co/7RuZE7ThQs https://t.co/scTGg8X03n
Here's my take on the Sora technical report, with a good dose of speculation that could be totally off. First of all, really appreciate the team for sharing helpful insights and design decisions – Sora is incredible and is set to transform the video generation community. What we have learned so far: - Architecture: Sora is built on our diffusion transformer (DiT) model (published in ICCV 2023) — it's a diffusion model with a transformer backbone, in short: DiT = [VAE encoder + ViT + DDPM + VAE decoder]. According to the report, it seems there are not much additional bells and whistles. - "Video compressor network": Looks like it's just a VAE but trained on raw video data. Tokenization probably plays a significant role in getting good temporal consistency. By the way, VAE is a ConvNet, so DiT technically is a hybrid model ;) (1/n)
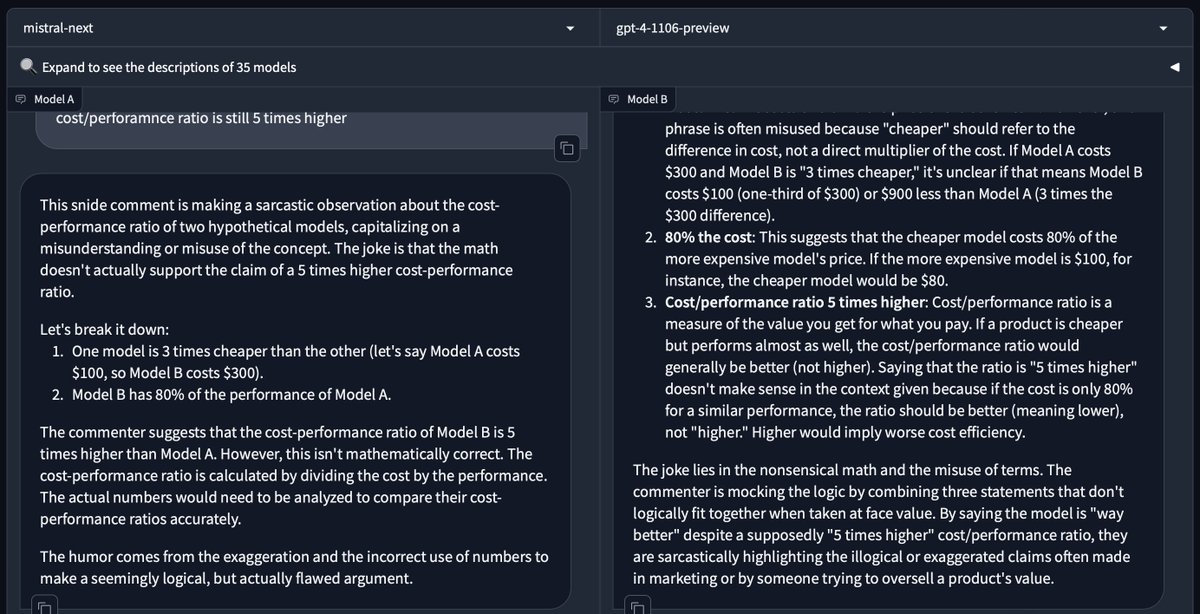
new 'mistral-next' model on arena. in my tests, it bests gpt-4 at reasoning and has mistral's characteristic conciseness. is this mistral-large? https://t.co/C06dkLE0Fs
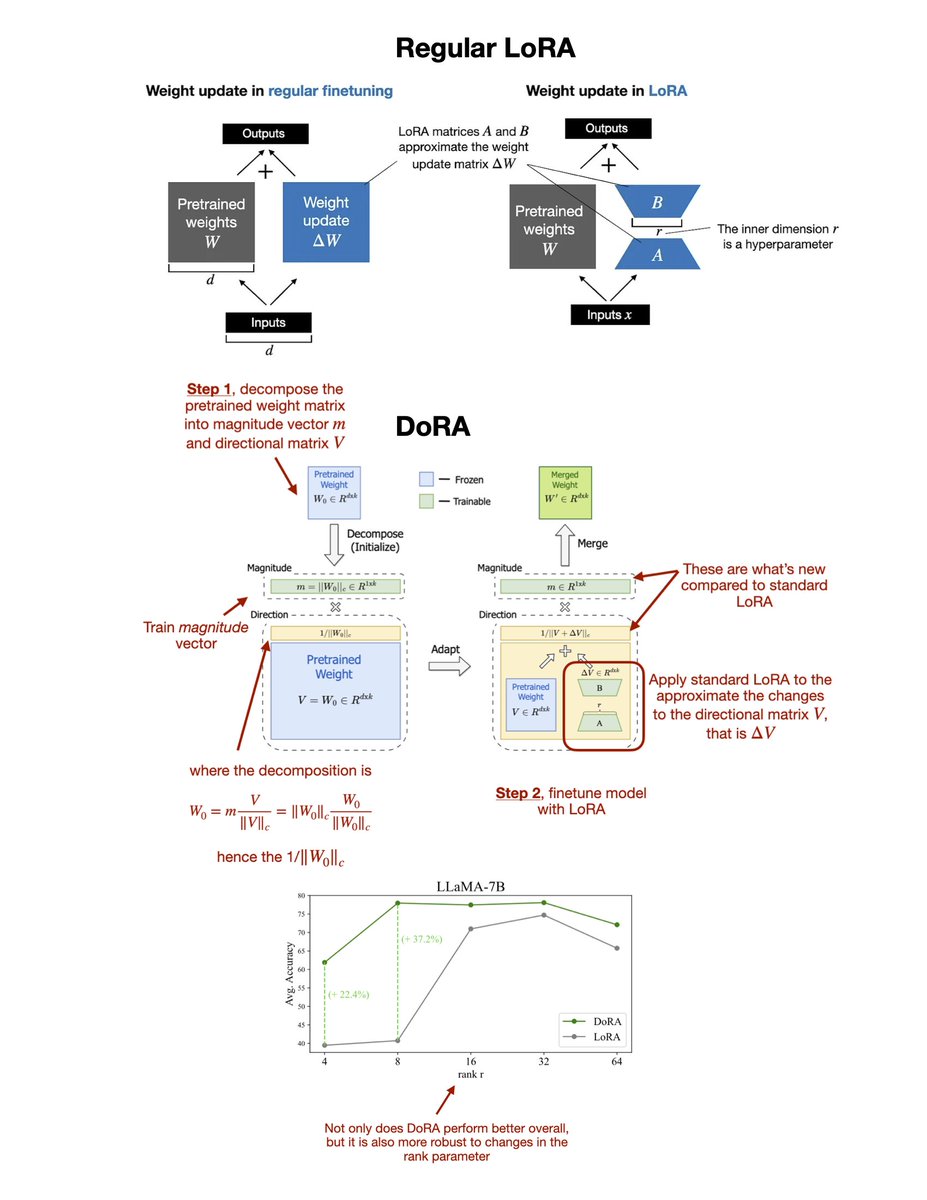
While everyone is talking about Sora, there's a potential successor to LoRA (low-rank adaptation) called DoRA. Here's a closer look at the "DoRA: Weight-Decomposed Low-Rank Adaptation" paper: https://t.co/nDHYeoSUPf LoRA is probably the most widely used parameter-efficient finetuning method for LLMs and vision transformers, and DoRA can be seen as an improvement or extension of LoRA that is built on top of it. A brief LoRA recap: Assuming we have pretrained model weights W, LoRA uses low-rank matrices to approximate weight changes ΔW. I.e., in regular finetuning we have W' = W + ΔW, and in LoRA, we approximate ΔW with BA. Now, the DoRA method first decomposes the pretrained weight matrix into a magnitude vector (m) and a directional matrix (V). Then, it takes the directional matrix V and applies standard LoRA to it, i.e., W' = m (V + ΔV)/norm = m (W + BA)/norm. The motivation for developing this method is based on analyzing and comparing the LoRA and full finetuning learning patterns. They found that LoRA either increases or decreases magnitude and direction updates proportionally but seems to lack the capability of making only subtle directional changes as found in full finetuning. Hence, the researchers propose the decoupling of magnitude and directional components. In other words, their DoRA method aims to apply LoRA only to the directional component (while also allowing the magnitude component to be trained separably.) Note that introducing the magnitude vector m in DoRA adds 0.01% more parameters than standard LoRA. However, across both LLM and vision transformer benchmarks, they found that DoRA even outperforms LoRA if the DoRA rank is halved, i.e., when DoRA only uses half the parameters of regular LoRA. Overall, I am actually quite impressed by the results and need to toy with this method in practice. It should not be too big of a lift to upgrade a LoRA implementation to DoRA.
I've tested the "long is more" trick on @Teknium1's OpenHermes dataset and it works surprisingly well 🔥! - Select the 1k longest samples (0.1%) - SFT Mistral-7B for 15 epochs with NEFTune α=10 - MT Bench ~7 + decent perf on other benchmarks 💾Dataset: https://t.co/MWnWXgZ6QT https://t.co/0HpXvX1DAm
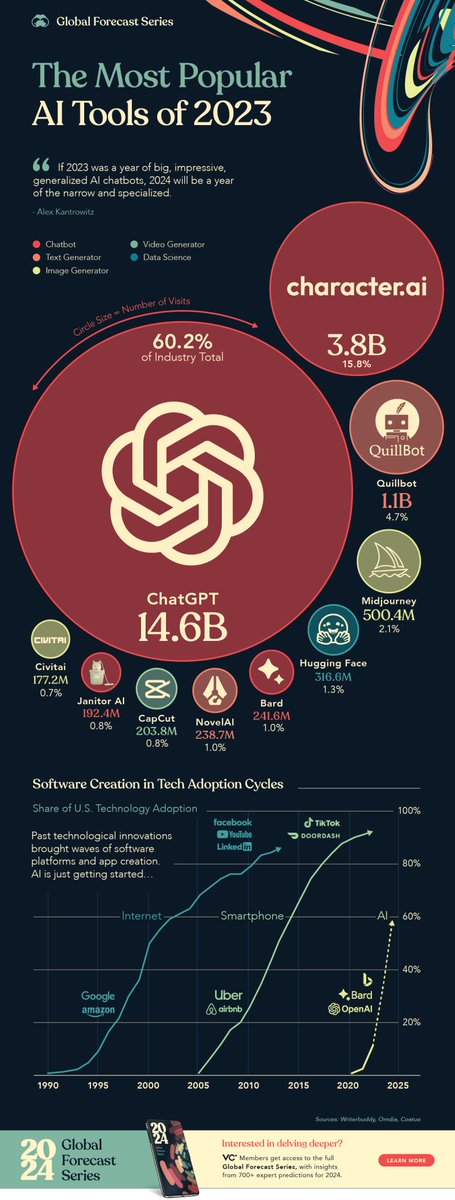
"If 2023 was a year of big, impressive, generalized #AI #chatbots, 2024 will be a year of the narrow and specialized." - Alex Kantrowitz https://t.co/sDGt17OpMI #ArtificialIntelligence #MachineLearning #DataAnalytics @SpirosMargaris @GlenGilmore @sallyeaves @Shi4Tech @rwang0 https://t.co/zjfwOnRBKl
If you think OpenAI Sora is a creative toy like DALLE, ... think again. Sora is a data-driven physics engine. It is a simulation of many worlds, real or fantastical. The simulator learns intricate rendering, "intuitive" physics, long-horizon reasoning, and semantic grounding, all by some denoising and gradient maths. I won't be surprised if Sora is trained on lots of synthetic data using Unreal Engine 5. It has to be! Let's breakdown the following video. Prompt: "Photorealistic closeup video of two pirate ships battling each other as they sail inside a cup of coffee." - The simulator instantiates two exquisite 3D assets: pirate ships with different decorations. Sora has to solve text-to-3D implicitly in its latent space. - The 3D objects are consistently animated as they sail and avoid each other's paths. - Fluid dynamics of the coffee, even the foams that form around the ships. Fluid simulation is an entire sub-field of computer graphics, which traditionally requires very complex algorithms and equations. - Photorealism, almost like rendering with raytracing. - The simulator takes into account the small size of the cup compared to oceans, and applies tilt-shift photography to give a "minuscule" vibe. - The semantics of the scene does not exist in the real world, but the engine still implements the correct physical rules that we expect. Next up: add more modalities and conditioning, then we have a full data-driven UE that will replace all the hand-engineered graphics pipelines. https://t.co/7BikSgE7iN
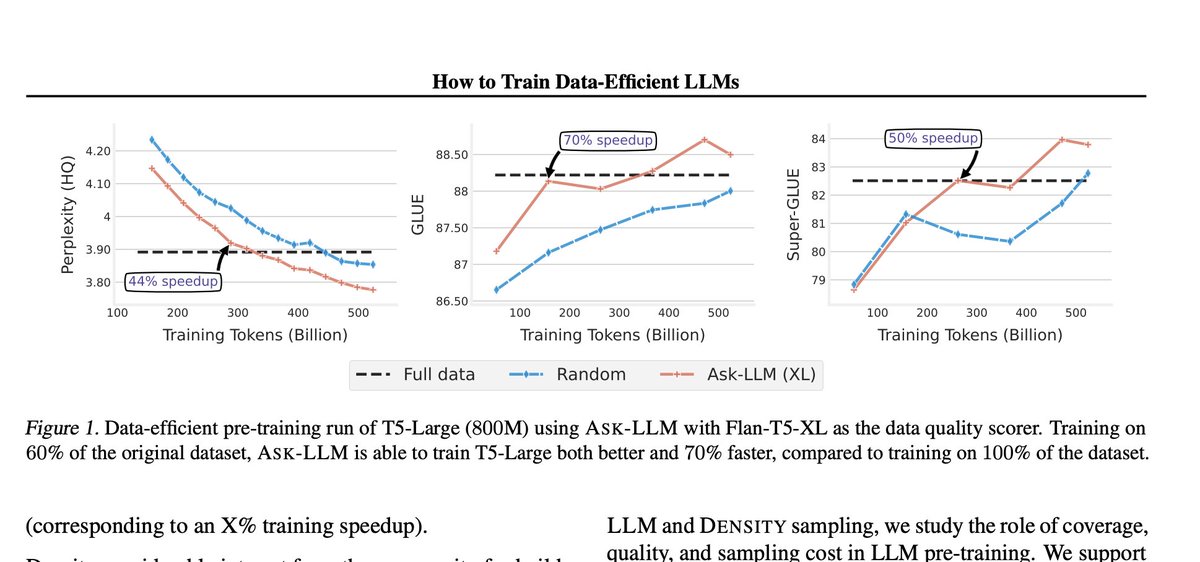
How to Train Data-Efficient LLMs paper page: https://t.co/xP1PYQURjY The training of large language models (LLMs) is expensive. In this paper, we study data-efficient approaches for pre-training LLMs, i.e., techniques that aim to optimize the Pareto frontier of model quality and training resource/data consumption. We seek to understand the tradeoffs associated with data selection routines based on (i) expensive-to-compute data-quality estimates, and (ii) maximization of coverage and diversity-based measures in the feature space. Our first technique, Ask-LLM, leverages the zero-shot reasoning capabilities of instruction-tuned LLMs to directly assess the quality of a training example. To target coverage, we propose Density sampling, which models the data distribution to select a diverse sample. In our comparison of 19 samplers, involving hundreds of evaluation tasks and pre-training runs, we find that Ask-LLM and Density are the best methods in their respective categories. Coverage sampling can recover the performance of the full data, while models trained on Ask-LLM data consistently outperform full-data training -- even when we reject 90% of the original dataset, while converging up to 70% faster.
Google presents A Human-Inspired Reading Agent with Gist Memory of Very Long Contexts paper page: https://t.co/LTpxAIfy1N Current Large Language Models (LLMs) are not only limited to some maximum context length, but also are not able to robustly consume long inputs. To address these limitations, we propose ReadAgent, an LLM agent system that increases effective context length up to 20x in our experiments. Inspired by how humans interactively read long documents, we implement ReadAgent as a simple prompting system that uses the advanced language capabilities of LLMs to (1) decide what content to store together in a memory episode, (2) compress those memory episodes into short episodic memories called gist memories, and (3) take actions to look up passages in the original text if ReadAgent needs to remind itself of relevant details to complete a task. We evaluate ReadAgent against baselines using retrieval methods, using the original long contexts, and using the gist memories. These evaluations are performed on three long-document reading comprehension tasks: QuALITY, NarrativeQA, and QMSum. ReadAgent outperforms the baselines on all three tasks while extending the effective context window by 3-20x.
Hierarchical State Space Models for Continuous Sequence-to-Sequence Modeling proj: https://t.co/ATeSpreRpF abs: https://t.co/YB3M3nmQC2 https://t.co/T5YiMTCitl
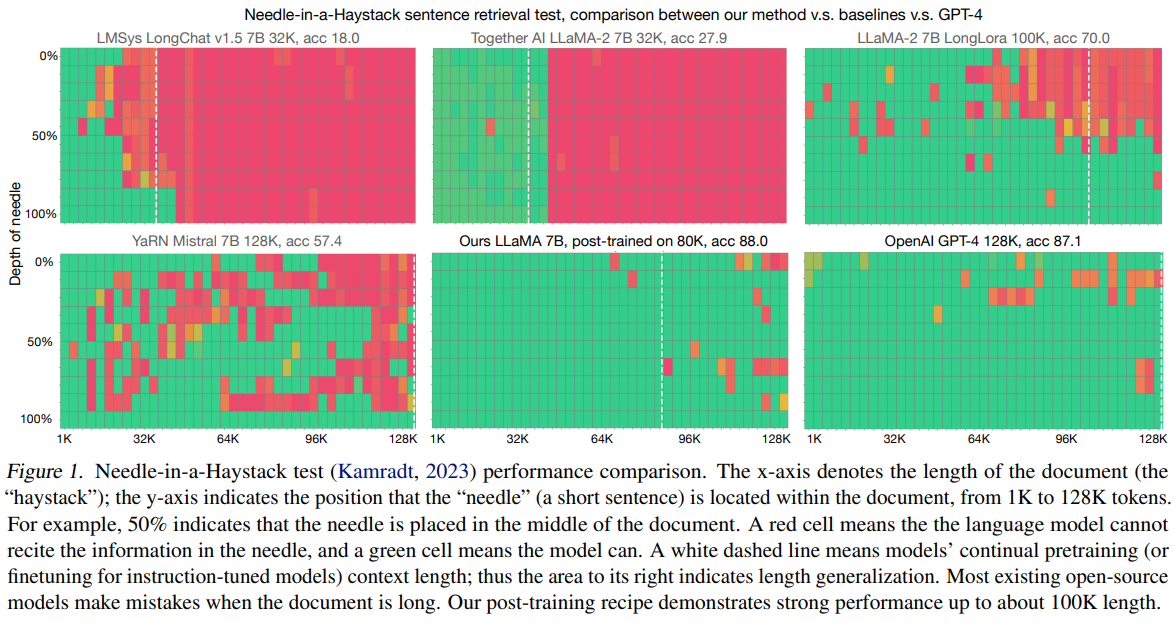
Data Engineering for Scaling Language Models to 128K Context - 500M to 5B tokens are enough to enable the model to retrieve information anywhere within the 128K context - Domain balance and length upsampling are needed repo: https://t.co/kxEaWcqa3l abs: https://t.co/jvrKDntG7i https://t.co/9Sna7v0H6e
NVIDIA releases OpenMathInstruct-1 - Opensources a high-quality 1.8M math instruction-tuning dataset - OpenMath-CodeLlama-70B achieves 84.6% on GSM8K and 50.7% on MATH, which is competitive with the best gpt-distilled models https://t.co/wITeXKE7L0 https://t.co/5AzWwWJhLm
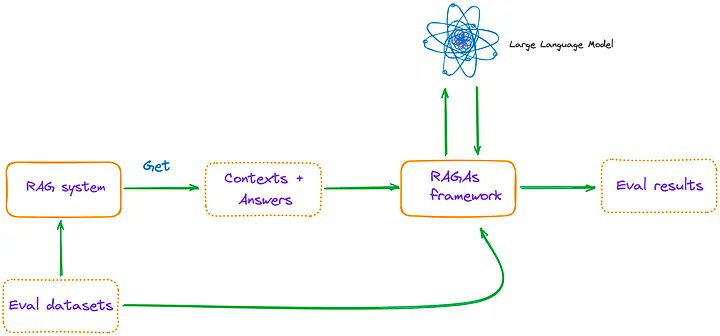
LlamaIndex + RAGAs Cookbook 🧑🍳 The first step to building any advanced RAG application is defining quality metrics, and RAGAs (@Shahules786) is a popular framework to comprehensively evaluate a RAG app component-wise and e2e. Metrics: Context relevance/recall/precision, faithfulness/groundedness, answer relevance. Check out this comprehensive article by Florian J. on how to setup a RAG pipeline with @llama_index and evaluate it on the set of metrics above. Link: https://t.co/ny2SUkxDG6
I'm starting to get more and more serious with YOLO-World; trying to solve real-life problems. I wanted to see if YOLO-World could recognize that the holes had been filled out. It was pretty tricky, but I learned a little about prompting. ↓ read more https://t.co/sMBDK40wFb
OpenAI released a technical report on Sora: - method for turning visual data of all types into a unified representation that enables large-scale training of generative models - qualitative evaluation of Sora’s capabilities and limitations. https://t.co/m8VJ6KPBlr https://t.co/yLsb5Jwu0R

Very nice to see the authors of a paper ask librarian-bot for a paper recommendation. I hope it was helpful, @vicgalle_! You can find similar papers for a @huggingface paper by commenting `@librarian-bot recommend`. https://t.co/bkggs8tEQI
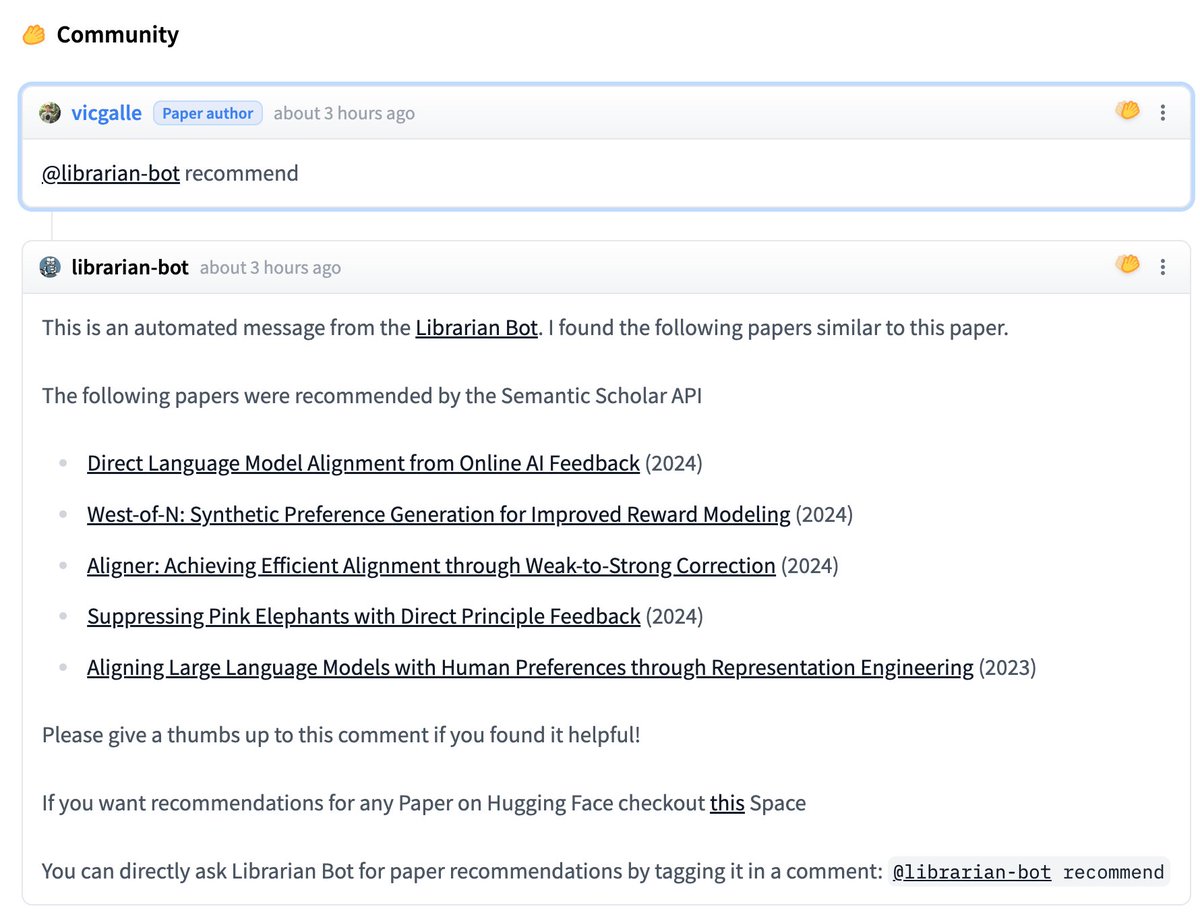
Really glad the bot/spam problem was so easy to solve. https://t.co/eva4DGT7kh
**Reverse image #RAG (or RIR)** for #GPT4V #VLM Below minimal #API that works great on examples (still needs proper eval) Code / package: https://t.co/mQKWbmTXeI (Non-cherry picked) examples: https://t.co/2iQmSxbbXW

I built a copilot for podcasters Live feedback and question ideas for your interview, while you're recording built with @AssemblyAI @OpenAI and @jxnlco's delightful Instructor https://t.co/71s7jsZ7T0