@arankomatsuzaki
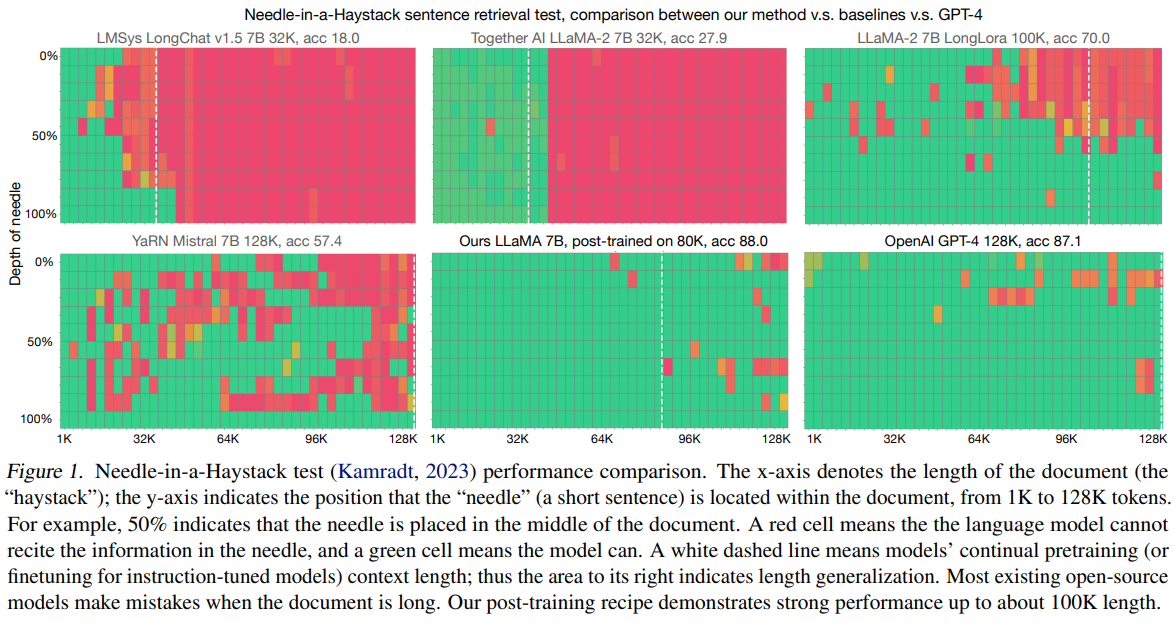
Data Engineering for Scaling Language Models to 128K Context - 500M to 5B tokens are enough to enable the model to retrieve information anywhere within the 128K context - Domain balance and length upsampling are needed repo: https://t.co/kxEaWcqa3l abs: https://t.co/jvrKDntG7i https://t.co/9Sna7v0H6e