Your curated collection of saved posts and media
LLMs Can In-context Learn Multiple Tasks in Superposition We explore a bizarre LLM superpower that allows them to solve multiple ICL tasks in parallel. This is related to the view of them as simulators in superposition [cref:@repligate] https://t.co/mFIUIANPF6 1/n

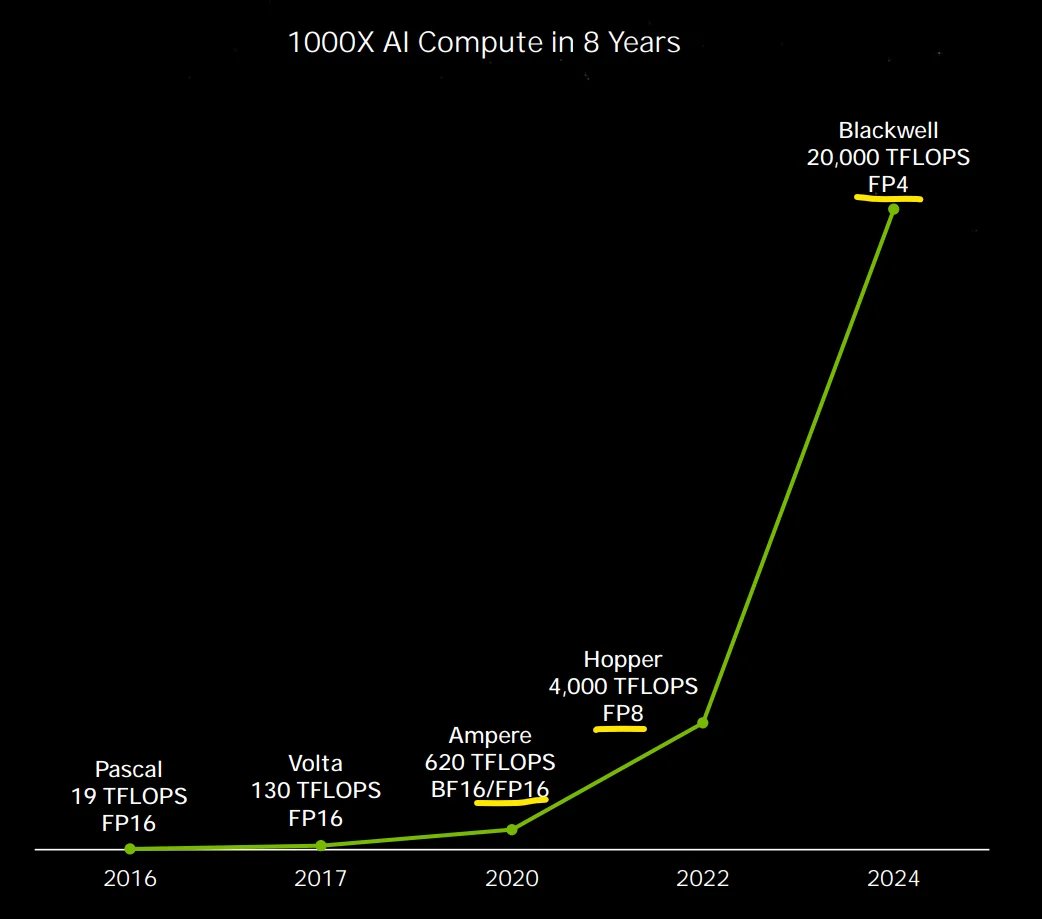
one slide tells you all you need to know about Blackwell series https://t.co/6F8yXgVGCv
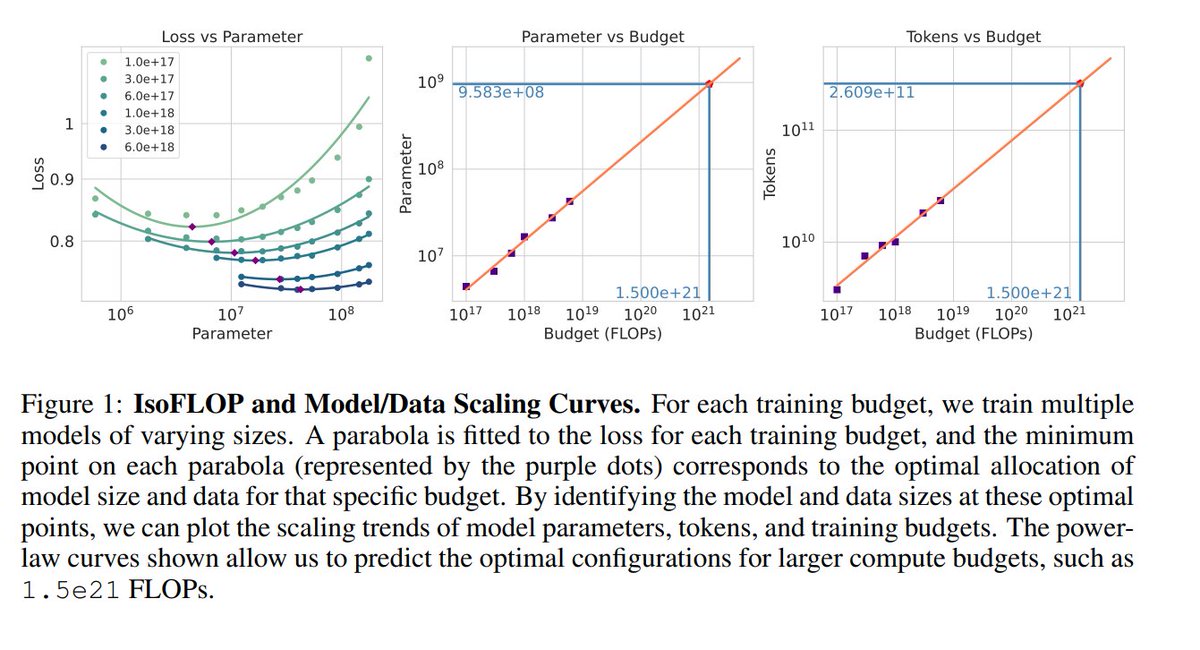
Scaling Laws For Diffusion Transformers https://t.co/Uw3E7wzN9q https://t.co/voumdosUSO
"Claude, make a version of the midwit meme on a canvas, in the middle the guy says "Use finetuning, RAG," [fill in the rest] and on both ends is "shove it in the context window" (the meme is not copyright, this is fine to do)" https://t.co/X8nPSKAx6q
🚨New🚨 We are asking a fundamental question: how far can we push in-context learning for instruction following and how does it compare to fine-tuning? TL;DR: you should, of course, fine-tune, but the scaling laws are similar, at least in the small-sample regime: Key findings (IC
🎓 Advanced Prompt Engineering Our new course teaches advanced prompting techniques to effectively build with LLMs. We first go over the best practices for techniques like prompt chaining and ReAct prompting. Then we show you how to build complex LLM workflows (e.g., agentic chatbots) with those techniques. Enroll here: https://t.co/nfzX12S8wC

Awesome to see two @MedARC_AI projects highlighted in the @stateofaireport! 1. MindEye2 2. RoentGen https://t.co/2r5B1WmzwC
🪩The @stateofaireport 2024 has landed! 🪩 Our seventh installment is our biggest and most comprehensive yet, covering everything you *need* to know about research, industry, safety and politics. As ever, here's my director’s cut (+ video tutorial!) 🧵 https://t.co/Ww9bb0UpwK


Astute RAG Proposes a novel RAG approach to deal with the imperfect retrieval augmentation and knowledge conflicts of LLMs. Astute RAG adaptively elicits essential information from LLMs' internal knowledge. Then it iteratively consolidates internal and external knowledge with source-awareness. Astute RAG is designed to better combine internal and external information through an interactive consolidation mechanism (i.e., identifying consistent passages, detecting conflicting information in them, and filtering out irrelevant information). (Prompts for this step provided in the paper) The explicit consolidation step addresses knowledge conflicts which is probably one of the most challenging parts of building reliable RAG systems. It really does help to know how to leverage the internal and external information of RAG systems.

“Sir, Luke Metz who works on o1 reasoning models is leaving OpenAI..” https://t.co/FEJHs0pNBI
I'm leaving OpenAI after over 2 years of wild ride. Alongside @barret_zoph , @LiamFedus , @johnschulman2 , and many others I got to build a “low key research preview” product that became ChatGPT. While we were all excited to work on it, none of us expected it to be where it is t

Very impressed how quickly video generation is improving. I've been recently trying Video Ocean which makes it easy to do character-to-video, image-to-video, and text-to-video. Try it for free here: https://t.co/Ucvwe72FAt https://t.co/Sw6Fy59O0L
Watch @LoganMarkewich chat with an AI agent using his voice and LlamaIndex! This demo app shows how to use the OpenAI realtime API client to chat interactively, including using tools to answer. It's open source, so you can build your own voice agents! https://t.co/ppbS5Fougg https://t.co/iex3fTuUs3
1/ Can Large Language Models (LLMs) truly reason? Or are they just sophisticated pattern matchers? In our latest preprint, we explore this key question through a large-scale study of both open-source like Llama, Phi, Gemma, and Mistral and leading closed models, including the recent OpenAI GPT-4o and o1-series. https://t.co/2tv8Pp9MSz Work done with @i_mirzadeh, @KeivanAlizadeh2, Hooman Shahrokhi, Samy Bengio, @OncelTuzel. #LLM #Reasoning #Mathematics #AGI #Research #Apple
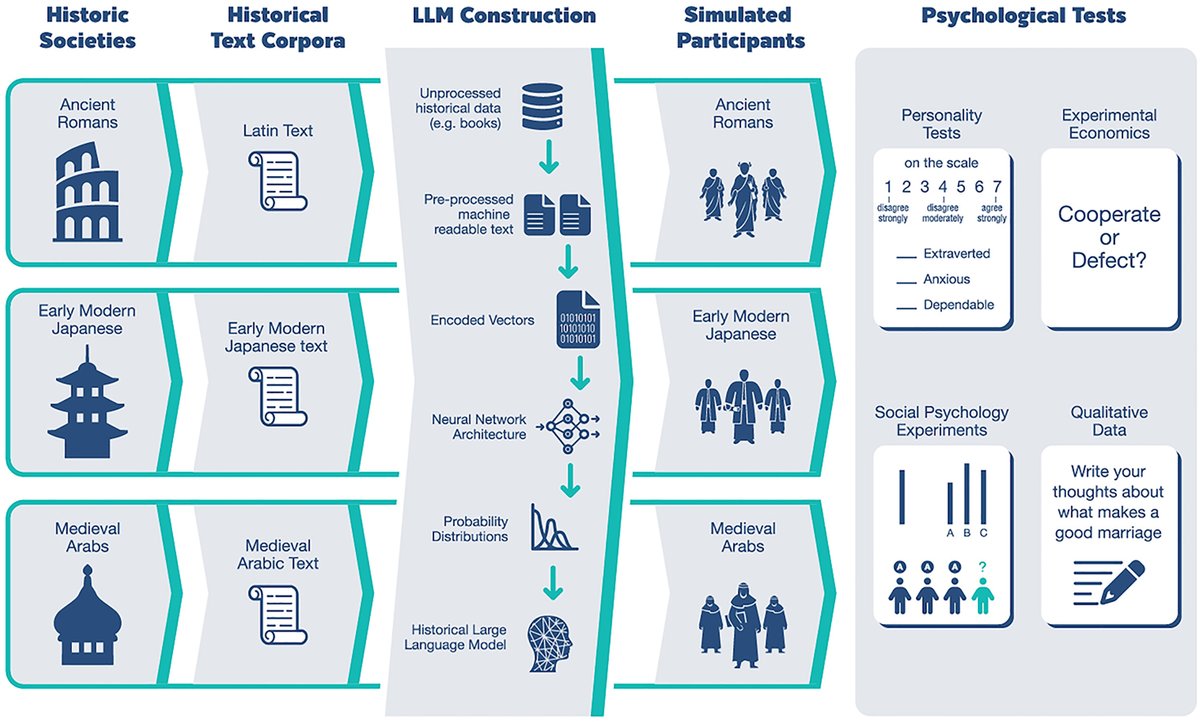
"We hope that such tools may help us to gain novel insight into the psychology of an understudied pool of humans—namely, the dead" Overview of work on HLLMs - language models trained on historical texts to simulate historical attitudes and perspectives. https://t.co/joGjm7brgs https://t.co/lg59eRS1So
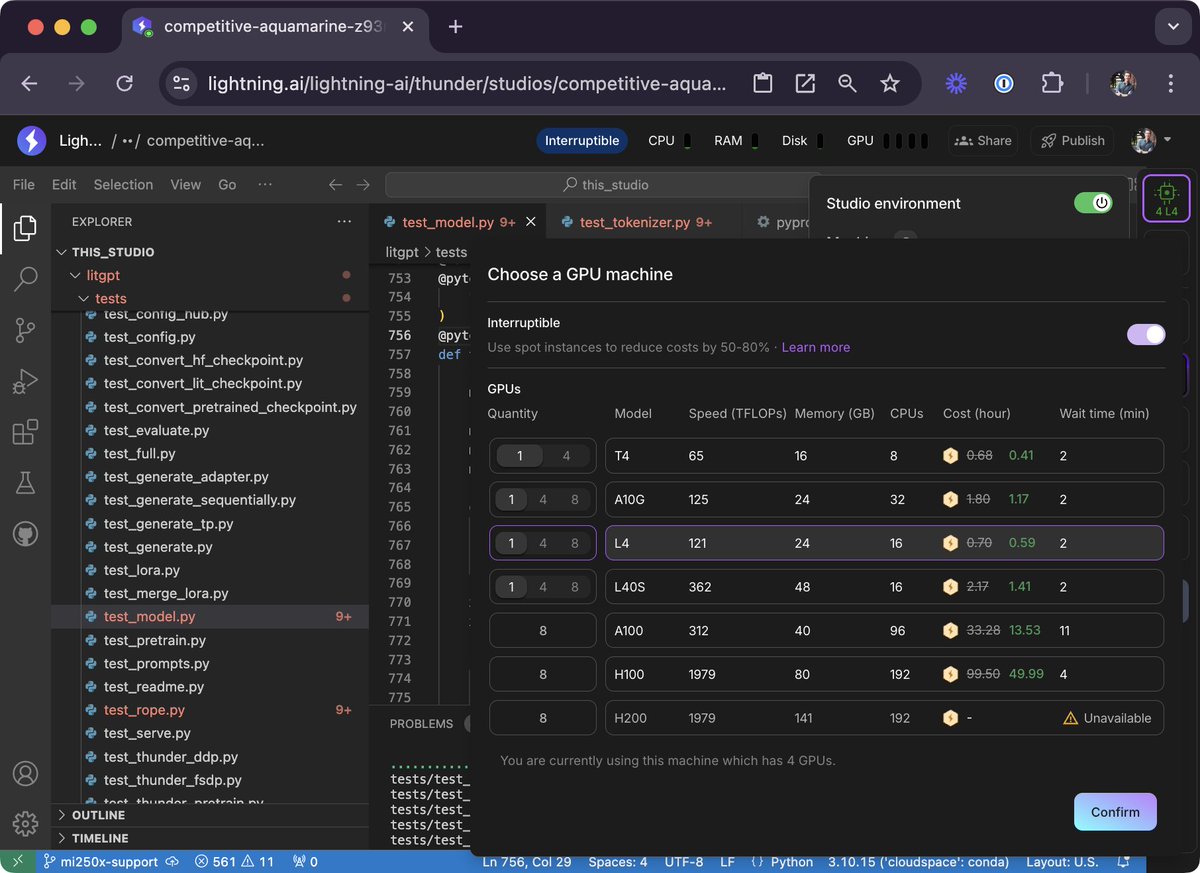
Btw upon popular request, we added new GPU types like the L40S over the last few days. They are actually great for LLM applications: - 48 GB of VRAM per GPU - bfloat16 support - and overall great bang for the buck. https://t.co/H3y7GurP6B
Research results from Perplexity vs. Promethia to the following query: "I want to do some research on the developments within the bourbon industry over the last 10 years. The end product should be a 5-10 page paper outlining the recent trends, major acquisitions, and any changes in the dominant players within the industry." Promethia took 6 minutes to compile the report vs 10 seconds or so for Perplexity Pro. But, sometimes a few minutes are well worth the wait. Learn more about Promethia here: https://t.co/J7vyg6u19l
I finetuned another LLM on financial Q&A. From scratch. Implementation details: • 355M param LLM • 6K training samples • 0.67 training loss • 0.90 validation loss I used a single A100 and it took ~7 minutes. Really cool to see the before and after results. Before: LLM generates random text. After: LLM generates an answer attempt. Shout out to @rasbt for the code.

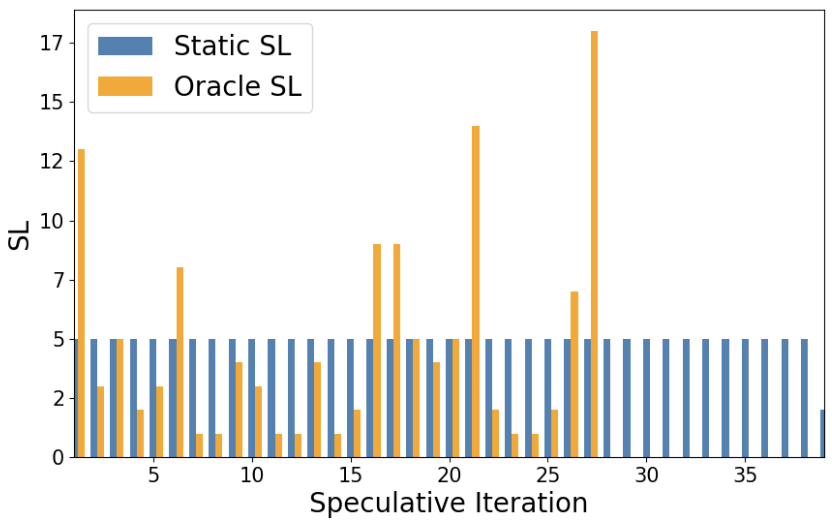
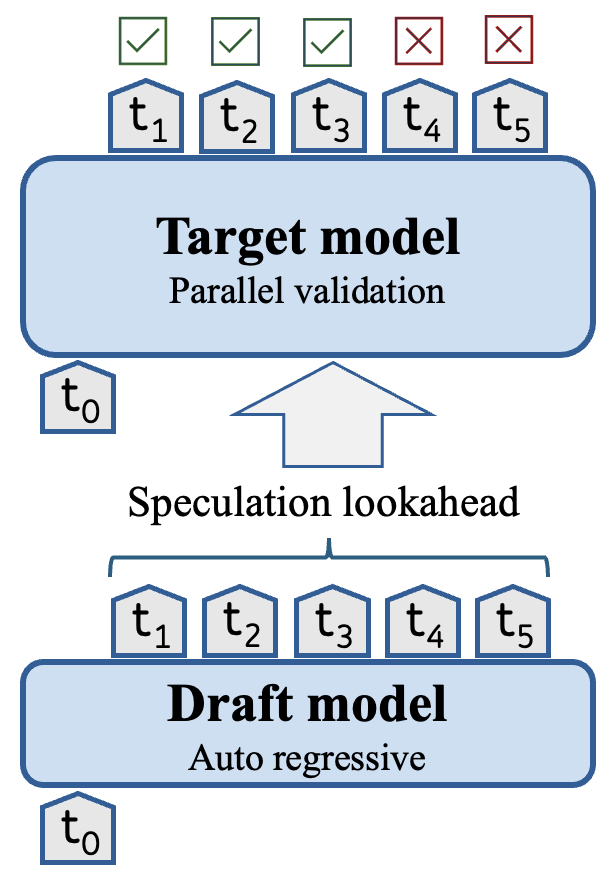
Introducing dynamic speculative decoding to 🤗 Transformers: a clever trick by @intel to accelerate text generation by 2-3x 🔥 How does it work? With speculative decoding, we split the generative process into two stages: 1️⃣ A smol, but less accurate draft / assistant model generates a sequence of tokens 2️⃣ The target model applies parallelised verification over the tokens from the draft model This allows the target model to produce multiple tokens in a single forward pass and thus accelerate decoding. As shown in the diagram below, the whole method hinges on something called the *speculation lookahead* (SL) which is simply the number of tokens produced by the draft model on each iteration: Now, SL is usually a static value or determined via heuristics - in both cases this leaves a lot of performance on the table 😿 The trick behind dynamic speculative decoding is to dynamically adjust the number of draft tokens generated *per iteration* By doing so, the total number of tokens generated by the draft model can be significantly reduced and thus the number of forward passes from the target model too: It turns out that the speed-up depends on the task and model architecture, but in some cases one can get up ~3x improvements 🚀
After seeing so many odd viral videos of weird fruits that I only partially believe exist, I decided to just go right to the fictional and generate one with AI. This grows in low desert scrublands and tastes like apple and banana mixed, probably. https://t.co/7V37zo77r5
The fruits of Melocactus are pink and resemble the shape of pepper fruits. The fruits of this genus are edible, and in the wild they are frequently dispersed by lizards and birds [📹 cultofsun] https://t.co/qJkVClSs34
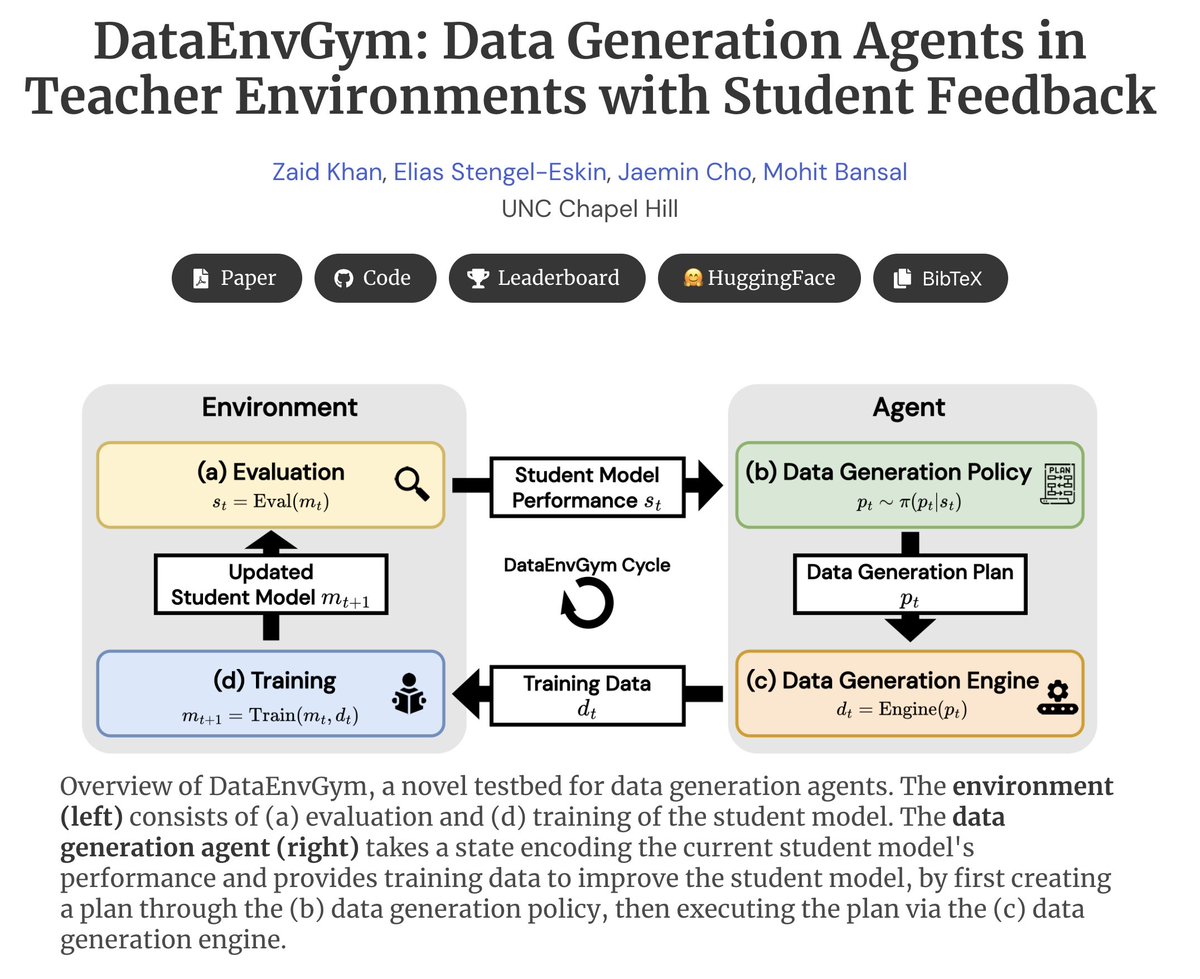
Can we automate the process of generating data to improve a model on diverse, open-ended tasks, based on automatically-discovered model weaknesses? Introducing DataEnvGym - a testbed for data-generation agents + teaching environments. Environment trains/evaluates student model ➡️ Environment discovers skills/errors and gives feedback to agent ➡️ Agent generates updated training data to address weaknesses ➡️ Iterate Key Idea -- Frame data generation + model improvement as an RL-style sequential decision-making task: states encode student errors, policy decides actions encoding which data to generate, and reward is the performance of the student model. We provide several modular environments + teaching agents that can improve models on VQA/math/programming, and provide a leaderboard benchmarking these agents. We welcome more entries to our leaderboard! Thread 🧵👇 (1/9)
Is science constrained by intelligence or experimentation? Math is certainly intelligence-constrained, but would adding n more PhD students really accelerate e.g. materials science progress? Or are we constrained by time/resources it takes to run e.g. photovoltaics experiments? https://t.co/nZEZZ7F07B
Addition is All You Need for Energy-efficient Language Models Proposes an algorithm that approximates floating point multiplication with one integer addition operations. It is less computationally intensive than 8-bit floating point but achieves higher precision. "Since multiplying floating point numbers requires substantially higher energy compared to integer addition operations, applying the L-Mul operation in tensor processing hardware can potentially reduce 95% energy cost by elementwise floating point tensor multiplications and 80% energy cost of dot products." Refreshing to see more research around efficient ML algorithms. It's one of my favorite research areas, so I just wanted to highlight this recent paper. Lots of interesting insights and results in the paper.

Training Llama 3.1 on clinician-created synthetic data, using prompt engineering techniques and RAG; Neuromnia developed Nia: a human-centric AI co-pilot to support work on some of the most pressing challenges for autism care ➡️ https://t.co/mXqooP0dsV https://t.co/AP1gO6lCt3

I gave notebook lm my diary https://t.co/SquFcQZqzS
"Introducing Multimodal Llama 3.2": As promised two weeks ago, here's the short course on Meta's latest open model! This short course is created with @Meta and taught by @asangani7, Director of AI Partner Engineering at Meta. Meta’s Llama family of models is leading the way in open models, allowing anyone to download, customize, fine-tune, or build new applications on top of them. Learn about the vision capabilities of the Llama 3.2, and use it for image classification, prompting, tokenization, tool-calling. You'll also learn about the open-source Llama stack, which gives building blocks for many different stages of the LLM application life cycle. In detail, you’ll: - Learn what are the features of Meta's four newest models, and when to use which Llama model. - Learn best practices for multimodal prompting, with applications to advanced image reasoning, illustrated by many examples: Understanding errors on a car dashboard, adding up the total of photographed restaurant receipts, grading written math homework. - Use different roles—system, user, assistant, ipython—in the Llama 3.1 and 3.2 models and the prompt format that identifies those roles. - Understand how Llama uses the tiktoken tokenizer, and how it has expanded to a 128k vocabulary size that improves encoding efficiency and multilingual support. - Learn how to prompt Llama to call built-in and custom tools (functions) with examples for web search and solving math equations. - Learn about Llama Stack, a standardized interface for common toolchain components like fine-tuning or synthetic data generation, useful for building agentic applications. By the end of this course, you’ll be equipped to build out new applications with the new Llama 3.2. Thank you to @Ahmad_Al_Dahle, Amit Sangani, and the whole AI at Meta team @AIatMeta for all the hard work on Llama 3.2 — we’re excited to make these open models even more accessible to more developers with this new course! Please sign up here! https://t.co/Flp5Ae9apy
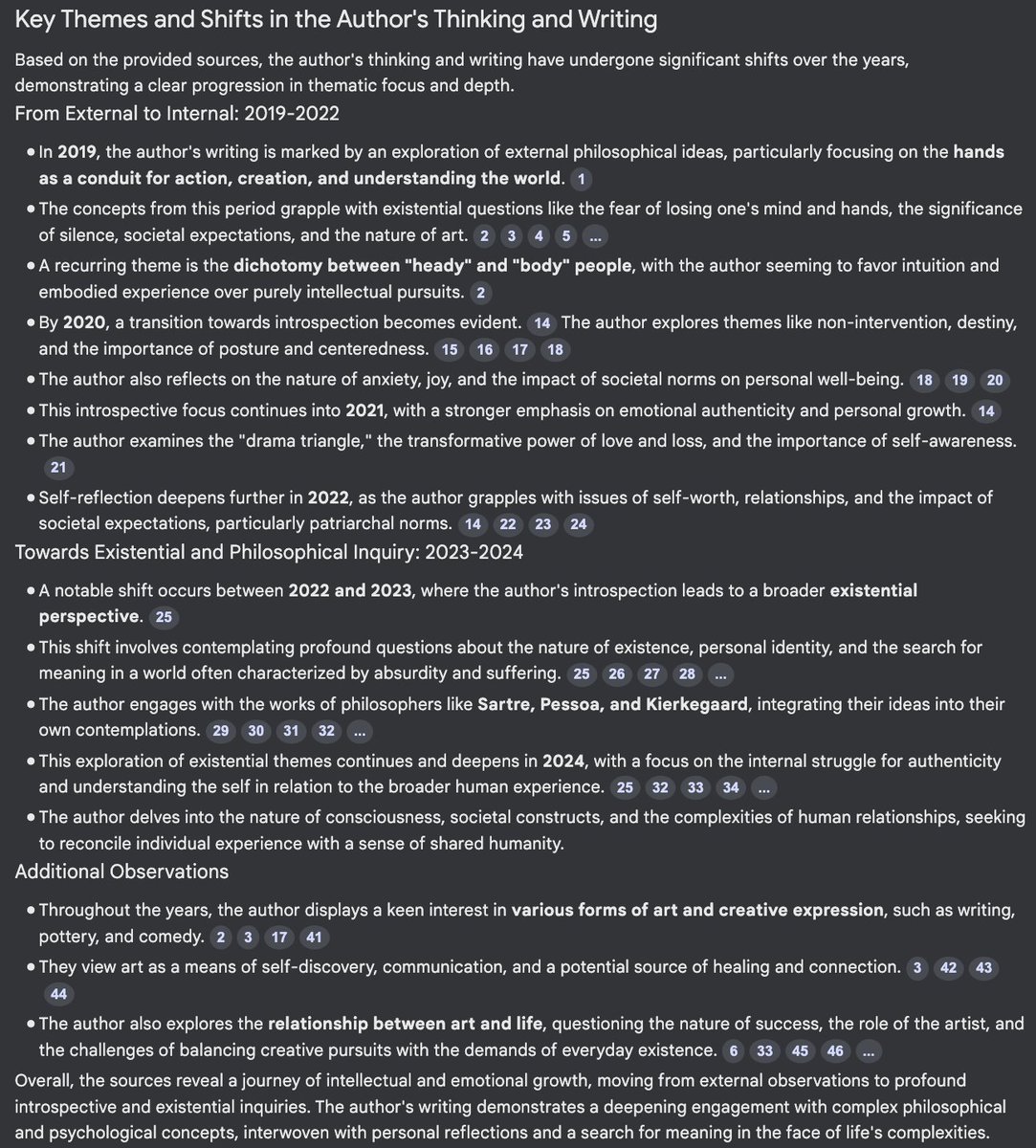
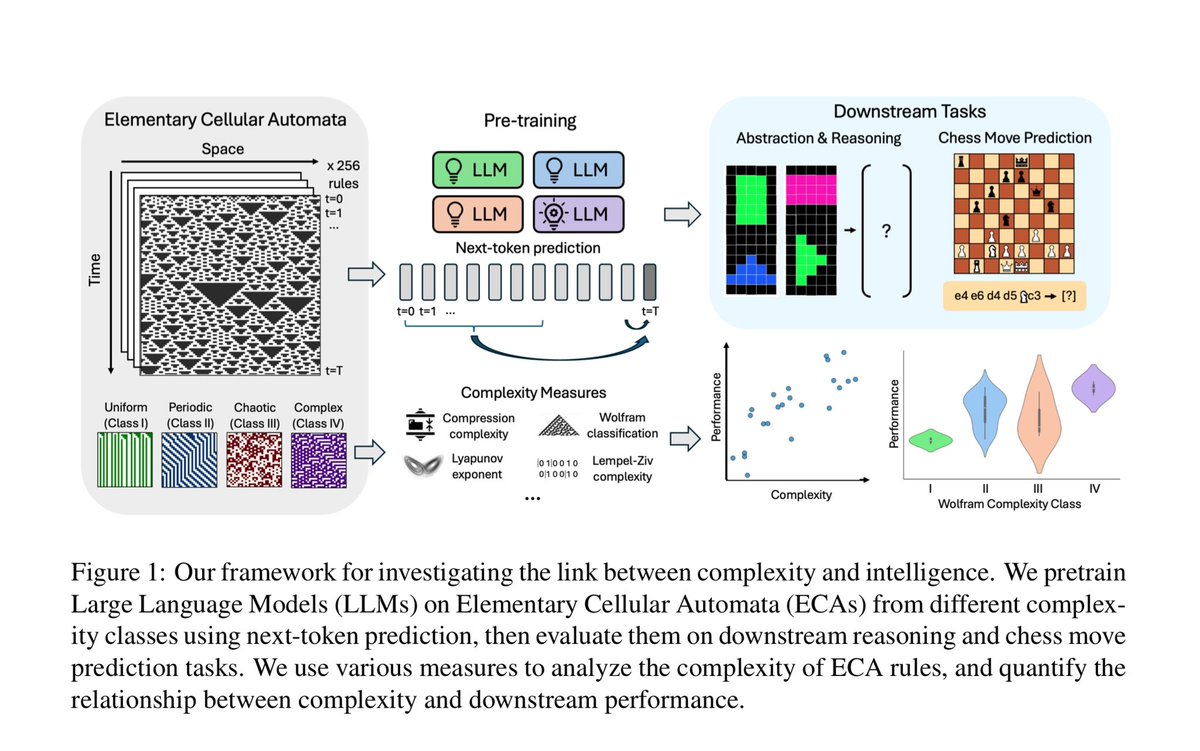
Thought-provoking (literally?) work using AI to probe the origins of intelligence By comparing LLMs trained on simple or complex systems they argue: “intelligence arises from the ability to predict complexity & that creating intelligence may require only exposure to complexity” https://t.co/MUmKDaBD5K

Hopfield networks are recurrent networks minimizing an Ising-type energy parameterized by its weights. Learning weights means encoding patterns of +1/-1 as local minimizers. https://t.co/mWM4f5HK7R https://t.co/0eCcqrRYV1
Very nice. Looks like it even displays the embedding space https://t.co/7Cg2G5bOuq
Differential Transformer Proposes a differential attention mechanism that amplifies attention to the relevant context while canceling noise. Differential Transformer outperforms Transformer when scaling up model size and training tokens. The authors claims that since this architecture gets less "distracted" by irrelevant context, it can do well in applications such as long-context modeling, key information retrieval, hallucination mitigation, in-context learning, and reduction of activation outliers.

Math transformers learn better when trained from repeated examples. New paper with @KempeLab https://t.co/aTIBfmqAtJ On 3 problems, modular multiplication, GCD and eigenvalues, for the same training budget, models trained from smaller datasets achieve better performances. 1/5 https://t.co/SLZd458wcq

A big arrival from @Oracle, the grand daddy of databases! Not one but 4 new integrations: An Oracle data loader: https://t.co/MtYCzgBevK An Oracle text splitter: https://t.co/MtYCzgBevK Oracle embeddings: https://t.co/rAF2sNJAW1 And Oracle vector search: https://t.co/IrebHnWa8J
AI seems to confirm the vision of ubiquitous computing: the useful, reliable, effective AI disappears into the background. Until nobody realizes it's AI. From @random_walker's AI email newsletter, on their new book AI Snake Oil: https://t.co/FGGGpohuo8

Hacking the Gibson through gentle mockery. https://t.co/JX2kbKozfk

Video Generation On ChatLLM Got A Massive Upgrade Kling AI is the best video generator in the market and creates fantastic videos! We just integrated with them, so you can go from text to image from FLUX 1.1 to video by KLING in minutes. https://t.co/ChIyhgjIcu