@_lewtun
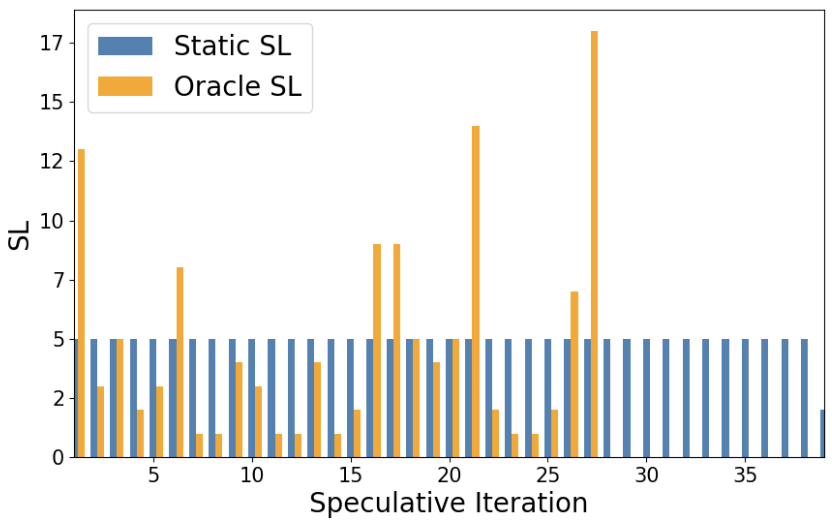
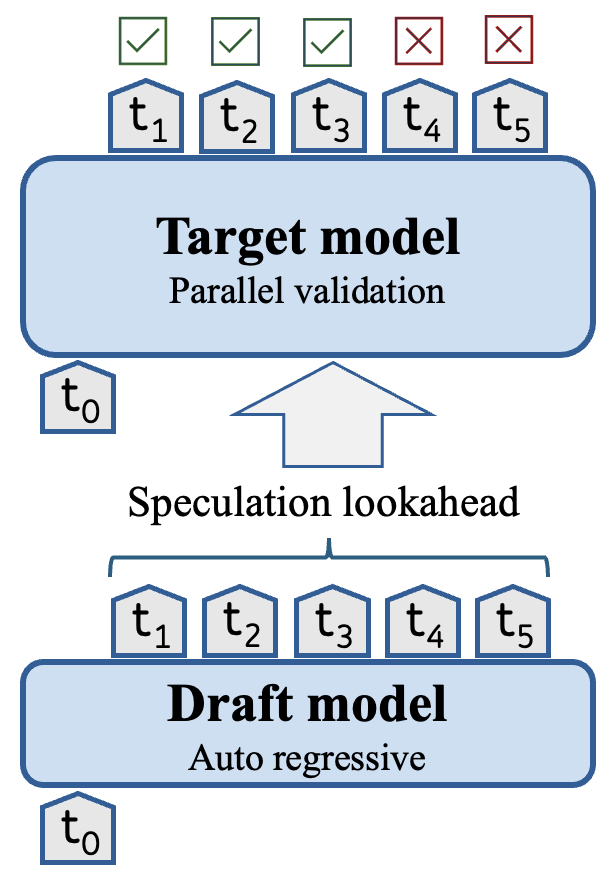
Introducing dynamic speculative decoding to 🤗 Transformers: a clever trick by @intel to accelerate text generation by 2-3x 🔥 How does it work? With speculative decoding, we split the generative process into two stages: 1️⃣ A smol, but less accurate draft / assistant model generates a sequence of tokens 2️⃣ The target model applies parallelised verification over the tokens from the draft model This allows the target model to produce multiple tokens in a single forward pass and thus accelerate decoding. As shown in the diagram below, the whole method hinges on something called the *speculation lookahead* (SL) which is simply the number of tokens produced by the draft model on each iteration: Now, SL is usually a static value or determined via heuristics - in both cases this leaves a lot of performance on the table 😿 The trick behind dynamic speculative decoding is to dynamically adjust the number of draft tokens generated *per iteration* By doing so, the total number of tokens generated by the draft model can be significantly reduced and thus the number of forward passes from the target model too: It turns out that the speed-up depends on the task and model architecture, but in some cases one can get up ~3x improvements 🚀