Your curated collection of saved posts and media
The Role of Prompting and External Tools in Hallucination Rates of LLMs Tests different prompting strategies and frameworks aimed at reducing hallucinations in LLMs. Finds that simpler prompting techniques outperform more complex methods. It reports that LLM agents exhibit higher hallucination rates due to the added complexity of tool usage. As we develop more advanced systems with LLMs, we can't just ignore these hallucination problems. Tool use, compute-use, long context understanding, reasoning, and more of these newer capabilities introduce unique hallucination challenges. The role of prompt engineering doesn't go away, it actually increases in importance as we optimize ways to communicate important instructions to advanced AI systems.

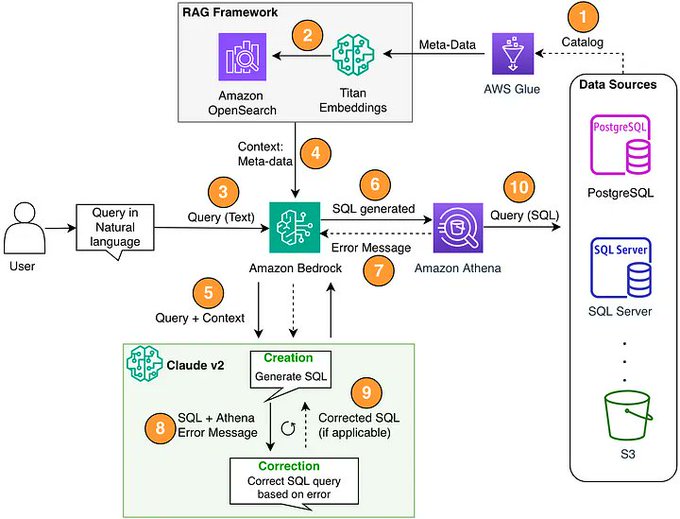
Simple text-to-SQL is trivial, actual enterprise-grade text-to-SQL is hard. There should be a lot more tutorials like the one from @kiennt_ on creating a proper SQL agent. You need to first map out and index your entire data catalog, and figure out how to retrieve from it (advanced retrieval, graphRAG) in order to properly inform SQL generation. Check out the blog below: https://t.co/kIAa7iIq0x
Reliable Text-to-SQL over 500 Tables 🔥🔎 Most text-to-SQL tutorials are easy and operate over “trivial” examples like 2-3 tables. This tutorial by @kiennt_ is one of the best we’ve seen in showing you how to construct a SQL agent that can operate over a large and complex data mod
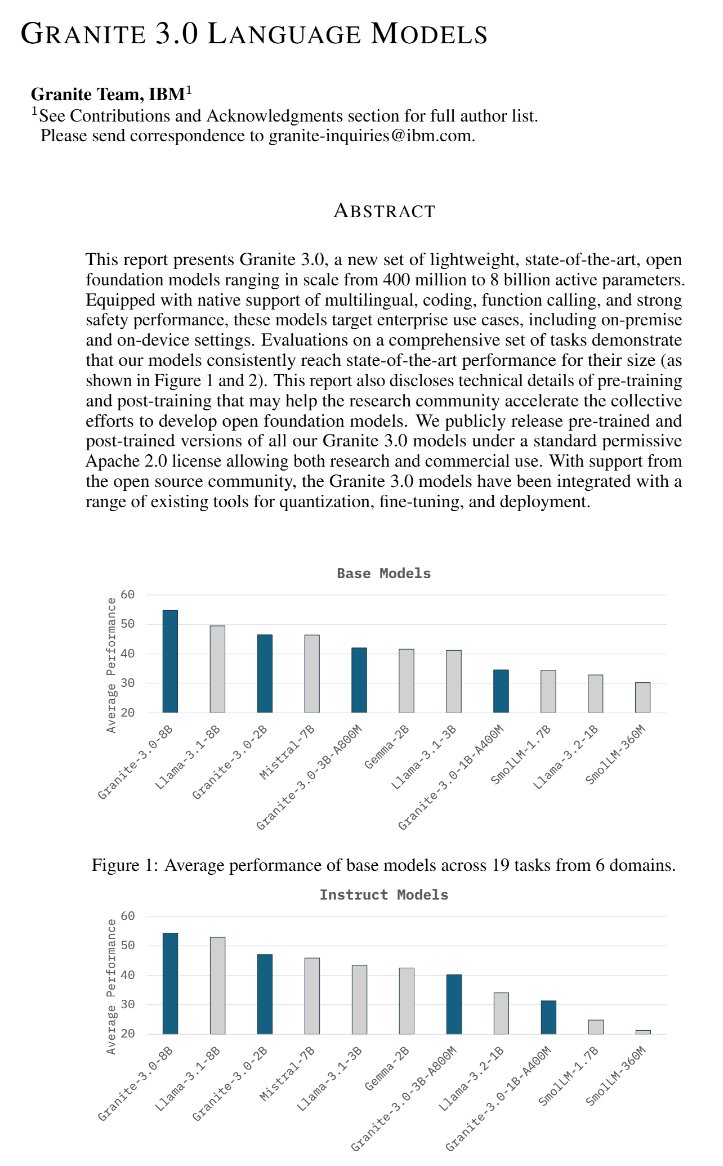
Qwen2.5 is so far ahead of other LLMs that it has become normal not to include it in evaluations. Here, Qwen2.5 doesn't exist and Granite 3.0 can reach SOTA: https://t.co/koLsoS2voy
Excited by Antropic Computer Use? Introducing Methodic Mind, the first agentic system that can solve any task, no coding or integrations needed! simply delegate any task by describing it, and Mind will take care of everything else, automagically! https://t.co/xUyvhAFAWo
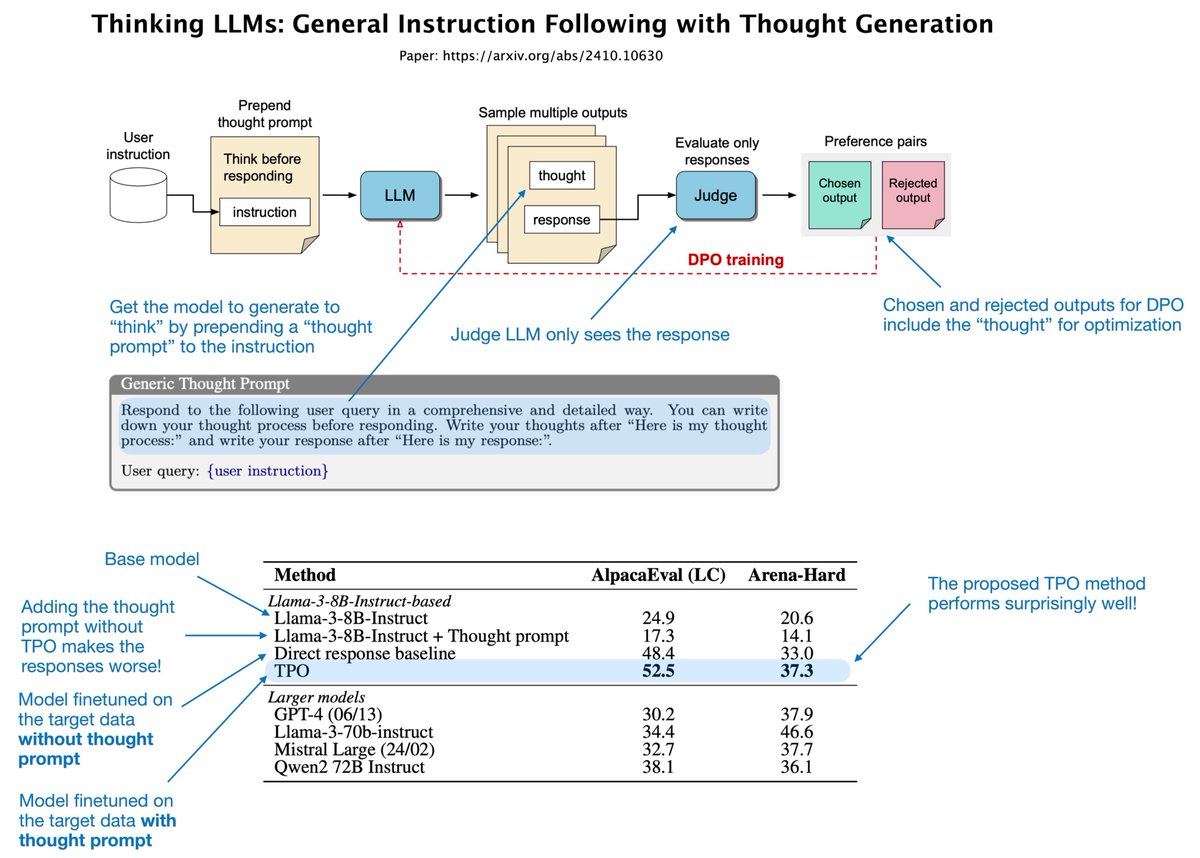
I just read the "Thinking LLMs: General Instruction Following With Thought Generation" paper (I), which offers a simple yet effective way to improve the response quality of instruction-finetuned LLMs. Thinking of it as a very simple alternative to OpenAI's o1 model, which produces better answers via internal "thinking" yet only shows you the final response, not the thinking process. The idea of the proposed Thought Preference Optimization (TPO) is to incorporate a Chain-of-Thought-style prompting/reasoning into the training. However, a) just asking the model to "think" via Chain-of-Thought prompting can reduce response accuracy b) training on Chain-of-Thought data would be hard because human thought processes are usually not included in instruction datasets So, their idea is this (see figure below): 1) Modify the prompt with a Chain-of-Thought style: "think before responding." 2) Use an LLM judge to evaluate the responses (excluding the thoughts generated by the LLM) 3) Form preference pairs for DPO based on the rejected and preferred responses (these responses include the thoughts) This way, the LLM implicitly learns to optimize its thinking process to produce better responses. (Note that the thinking process doesn't need to be shown to the user in a way similar to how it's not shown to the judge LLM.) The results, based on Llama 3 8B Instruct, show that this TPO approach works quite well: i) Interestingly, if the thought prompt is prepended but the Llama 3 8B Instruct base model doesn't undergo DPO finetuning on the preference pairs, this base model performs much worse than without the thought prompt ii) Finetuning the model on the instruction data (direct response baseline) without thought prompt improves the base model performance already by a lot, about 27.6% points on AlpacaEval and 17% on Arena-Hard; this shows how important finetuning is in general iii) Now, adding the thought preference optimization further boosts the performance by 4% Note that this method is applied to general instruction-response answering and is not specific to logic or math tasks.
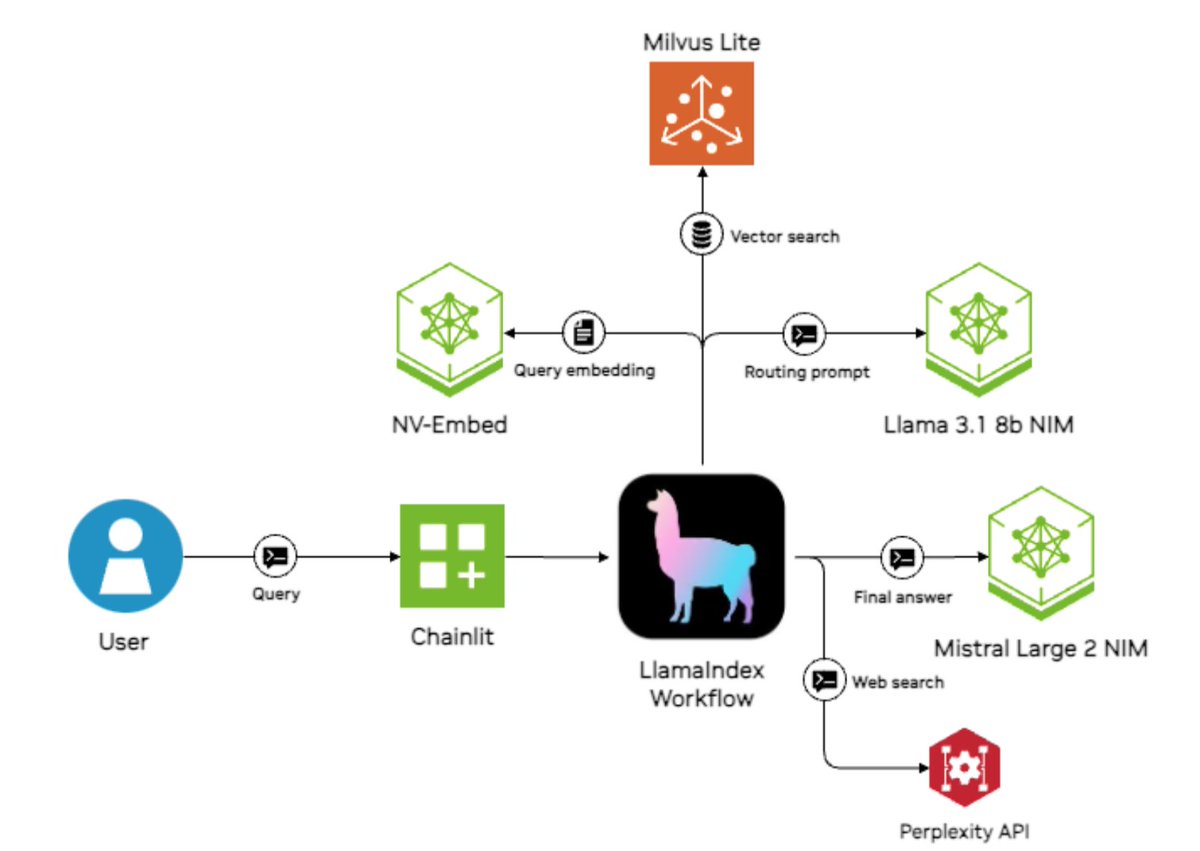
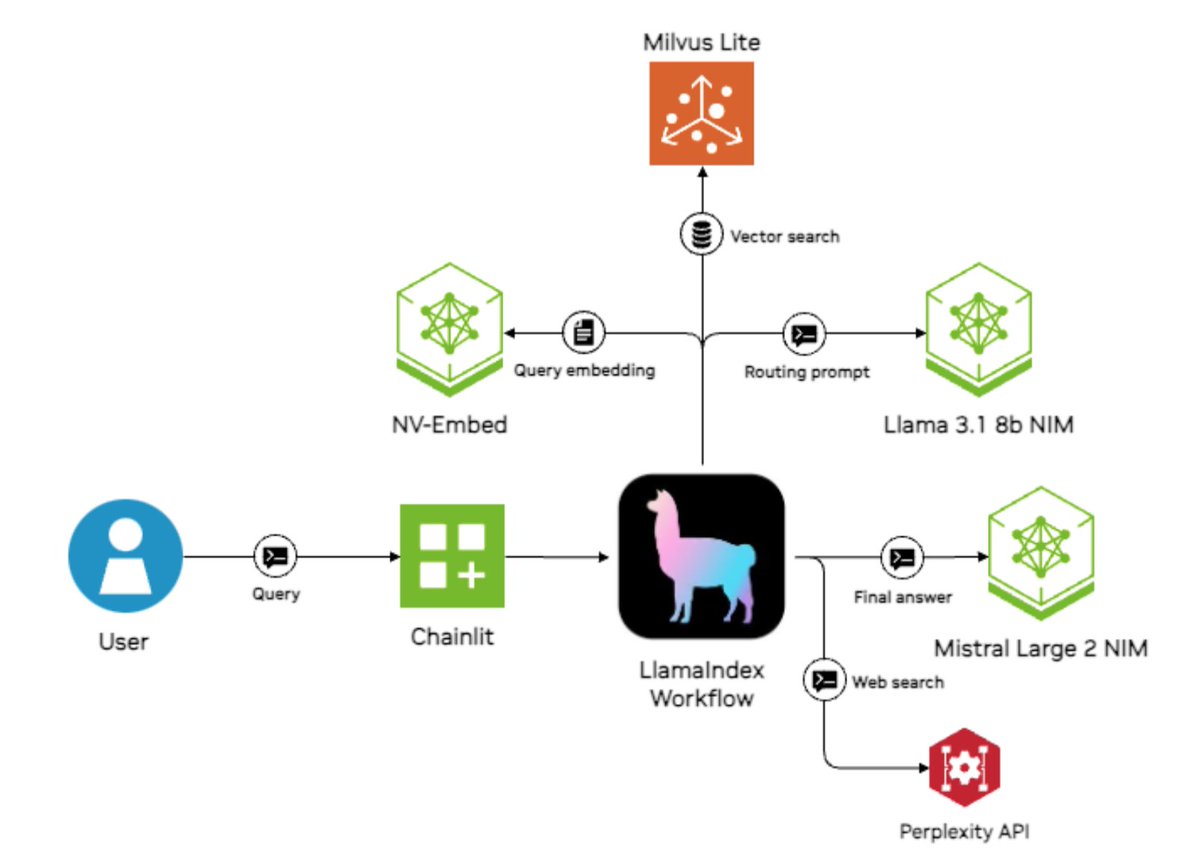
Excited to feature this @nvidia case study on a sales research copilot - not only is it an ROI-generating use case 📈, there's a lot of useful bits on how to properly architect your agent to optimize performance/speed/cost ⚙️⚡️ 1. Route a user query to a top-performing model (llama3.1-405b) to directly answer the question, or to a cheaper model (llama3.1-70b) that knows less but can do RAG synthesis over documents 2. parallel retrieval to combine information from data sources, like internal documents, NVIDIA's own website, and the open internet through perplexity 3. Model each query prompt with the relevant acronyms. By decomposing your workflow into steps, you can also have more modular prompts that contain acronym subsets Blog: https://t.co/yoPuoS5F6x Built on top of @llama_index workflows. If you're new to workflows, come check it out! https://t.co/YnZYWKgdQj
We are thrilled to announce a case study of a successful internal deployment of LlamaIndex at @nvidia, an internal AI assistant for sales 🧑💼🤖 * Uses Llama 3.1 405b for simple queries, 70b model for document searches * Retrieves from multiple sources: internal docs, NVIDIA site,
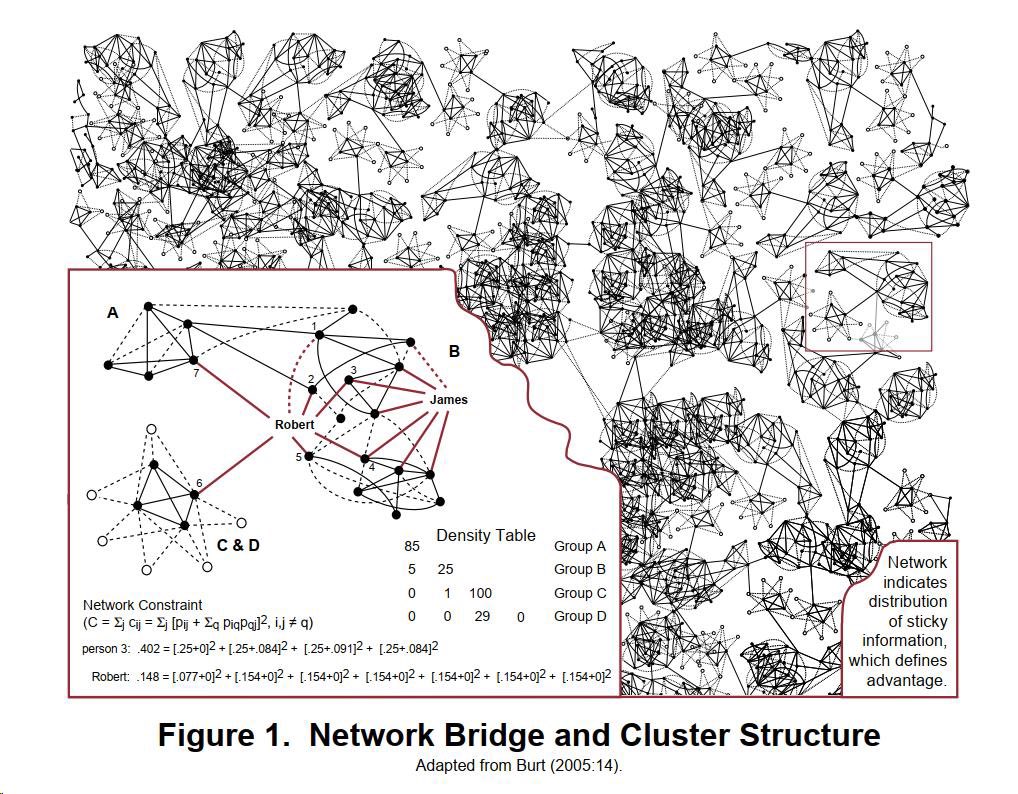
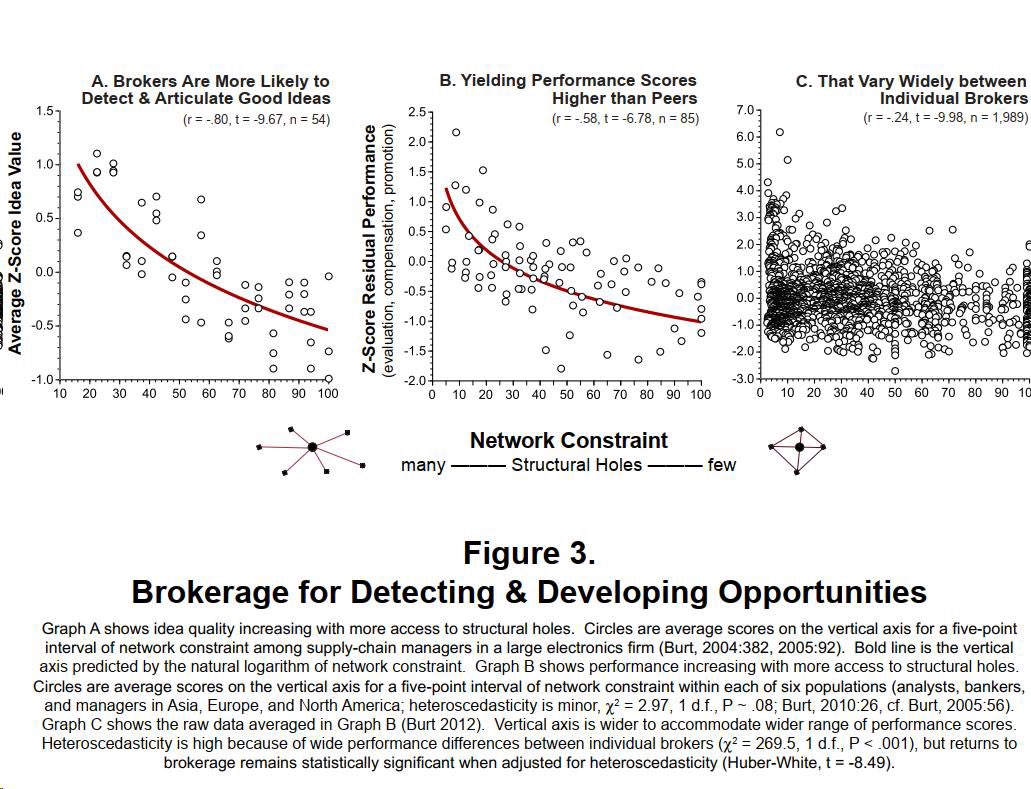
Brokers (in the formal social network analysis sense) win for a reason. https://t.co/P7goXoD6GP
Most diffusion of knowledge problems are also opportunities!
claude can just do things https://t.co/mSZEY81XsW

Here's an AI hype case study. The paper "The Rapid Adoption of Generative AI" has been making the rounds based on the claim that 40% of US adults are using generative AI. But that includes even someone who asked ChatGPT to write a limerick or something once in the last month. Buried in the paper is the fact that only 0.5% – 3.5% of work hours involved generative AI assistance, translating to 0.125 – 0.875 percentage point increase in labor productivity. Compared to what AI boosters were predicting after ChatGPT was released, this is a glacial pace of adoption. The paper leaves these important measurements out of the abstract, instead emphasizing much less informative once-a-week / once-a-month numbers. It also has a misleading comparison to the pace of PC adoption (20% of people using the PC 3 years after introduction). If someone spent thousands of dollars on a PC, of course they weren't just using it once a month. If we assume that people spent at least an hour a day using their PCs, generative AI adoption is roughly an order of magnitude slower than PC adoption. https://t.co/XLgF7Awp2v

Puts to rest all theories about Sonnet being smarter due to feature steering https://t.co/rwdqPQRM6w

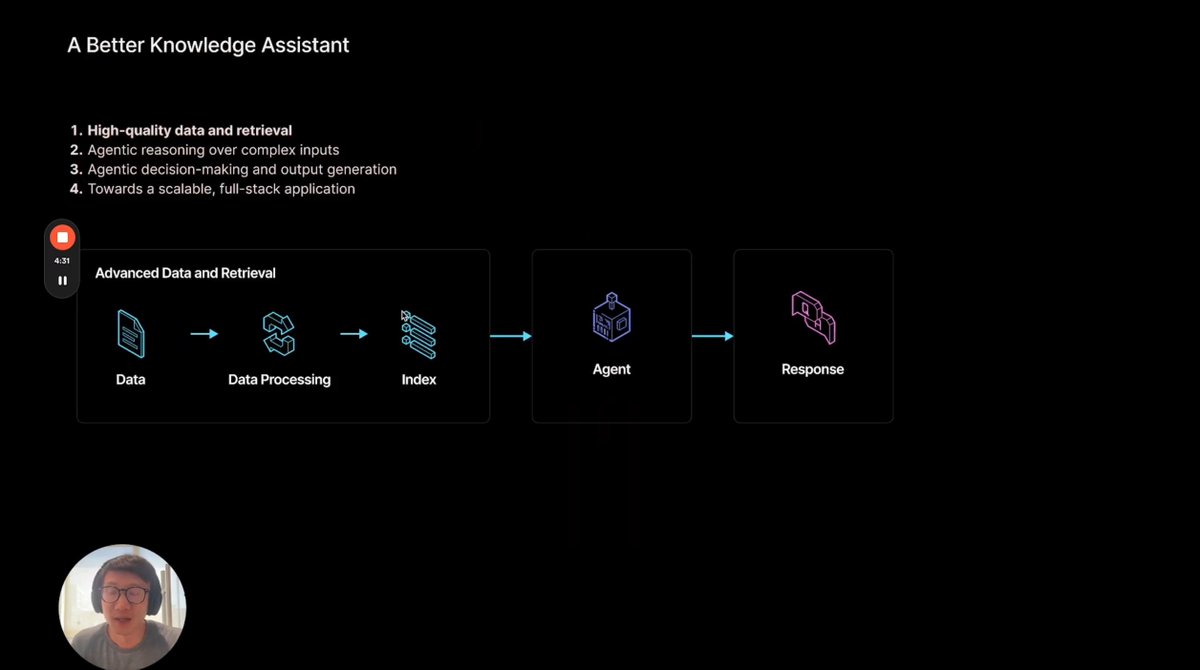
We’re launching a new video series on building advanced knowledge assistants ✨ Our goal is to build agentic workflows that can reason over your data and automate greater degrees of output generation and decision making. It’ll cover core advanced RAG topics (auto- and dynamic retrieval, corrective RAG, and more), emerging use cases around report generation, and give you a glimpse of how to use our entire integrated suite of products: LlamaCloud for data processing, LlamaParse for document parsing, LlamaIndex as the framework. First video - a high-level introduction to building a better knowledge assistant. @jerryjliu0 has given variations of this talk, and we’ve now turned it into a video: https://t.co/rPEhBz0GN0
The results on age and success in startups: older founders are good. 1) The median age in the US for launching a 1-in-1000 fastest growing company is 45 & the average age of founders is 42 https://t.co/vWS0mr0uNn 2) Worldwide, older founders beat younger https://t.co/UkXTHKcgnp https://t.co/SP3KgwdtNC
Reliable Text-to-SQL over 500 Tables 🔥🔎 Most text-to-SQL tutorials are easy and operate over “trivial” examples like 2-3 tables. This tutorial by @kiennt_ is one of the best we’ve seen in showing you how to construct a SQL agent that can operate over a large and complex data model (500+ tables, relationships between them). Here are some of the key steps: 1. Iterate through each table and extract a structured schema with LLM-generated summaries 2. Use hierarchical chunking and indexing to help retrieve an initial set of relevant tables 3. Use graphRAG techniques to provide tables related to the existing tables 4. Feed relevant and related set of tables to text-to-SQL prompt to generate the query https://t.co/pSYc3NWa38
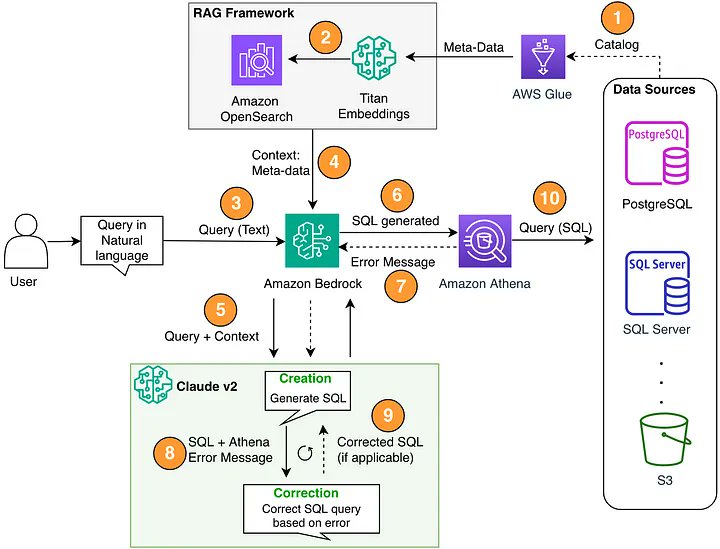
Something I don't need convincing about: LLMs are insanely useful for code test generation. I use LLMs for creating all kinds of tests not just for code. This is worth learning especially if you are looking for areas where to save time and effort using LLMs. https://t.co/pQsnd45isr
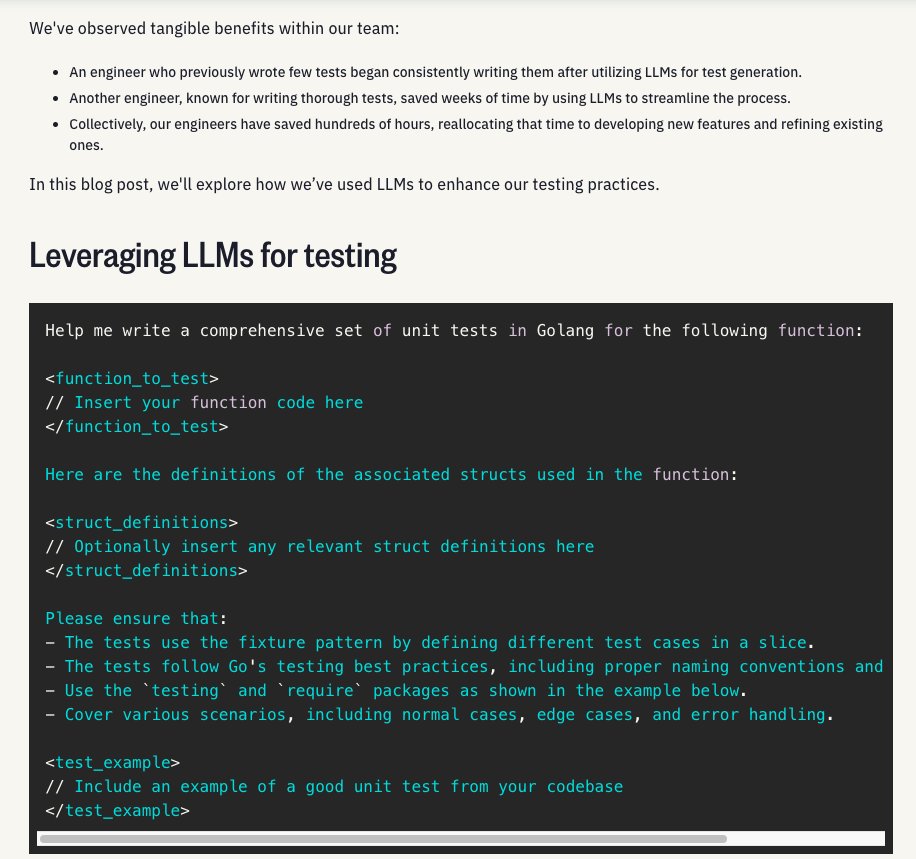
I just published the NotebookLM crash course on YouTube (~1 hr). I've said it before and I'll repeat it, don't sleep on NotebookLM. I built this course to share the useful and complex applications possible with NotebookLM. I've added timestamps to help navigate the content better. Enjoy! https://t.co/5wQ1zXUlO2
WSL does not get enough credit for what an amazing piece of tech it is. I've used it almost exclusively for dev for the last ~5 years and have run into less issues than I did developing on MacOS or Windows natively. https://t.co/h4E0IgmqqS
Folks using WSL* as their dev environment, what's your experience been like? I have a phat gaming PC that could churn up some dev tasks/video editing tasks but am nervous about the switch. * Windows Subsystem for Linux
Oldies but goldies: Corinna Cortes, Vladimir Vapnik, Support-vector networks, 1995. Defines a kernelized version of the support vector machine of Vapnik, Chervonenkis. Very popular for classification. https://t.co/4bE0hMZEDp https://t.co/jt6fWuj5TG
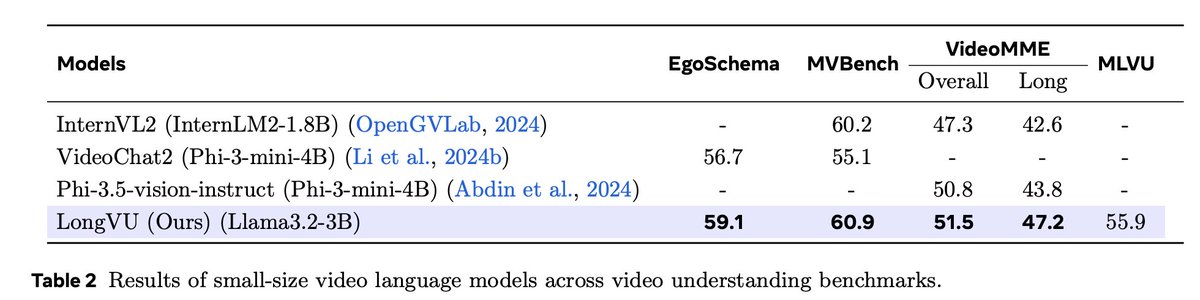
📢 New Paper Alert! 🚀📄 Excited to announce "LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding." 📝Paper: https://t.co/ttRNJw8IWW 🧑🏻💻Code: https://t.co/Bbeu381hTk 🚀Project (Demo): https://t.co/msbgSv6zlP https://t.co/eA6QUBt3SY

Reminder: SQLite is 35% faster than the filesystem while also using 20% less disk space https://t.co/3nsSa6G8F7

GPT o1 is impressive in logical derivations. Here are three examples I just tried it on. It succeeds in two, and miserably fails in another, slightly harder one. Still, very good. Specifically, it proves (1) x=y => y=x, (2) phi => phi, and fails in proving (3) phi => (not phi => psi). 1/2


We are thrilled to announce a case study of a successful internal deployment of LlamaIndex at @nvidia, an internal AI assistant for sales 🧑💼🤖 * Uses Llama 3.1 405b for simple queries, 70b model for document searches * Retrieves from multiple sources: internal docs, NVIDIA site, and web * LlamaIndex Workflows handles routing and core functionality * @chainlit_io provides the chat interface for sales reps * Parallel retrieval system searches multiple sources simultaneously * Built-in context augmentation helps handle company acronyms/terms * Real-time inference achieved through NVIDIA NIM optimization Sales automation is a top use case for agents. Check out our case study here: https://t.co/AApFNVjp0v
This feels pretty big to me. There is an assignment I give my MBA students where I give them a financial model for a business & ask them to identify missing or incorrect assumptions. The new Claude analysis module does a really good job spotting the issues & revising the model. https://t.co/uQXU6fv5Mi

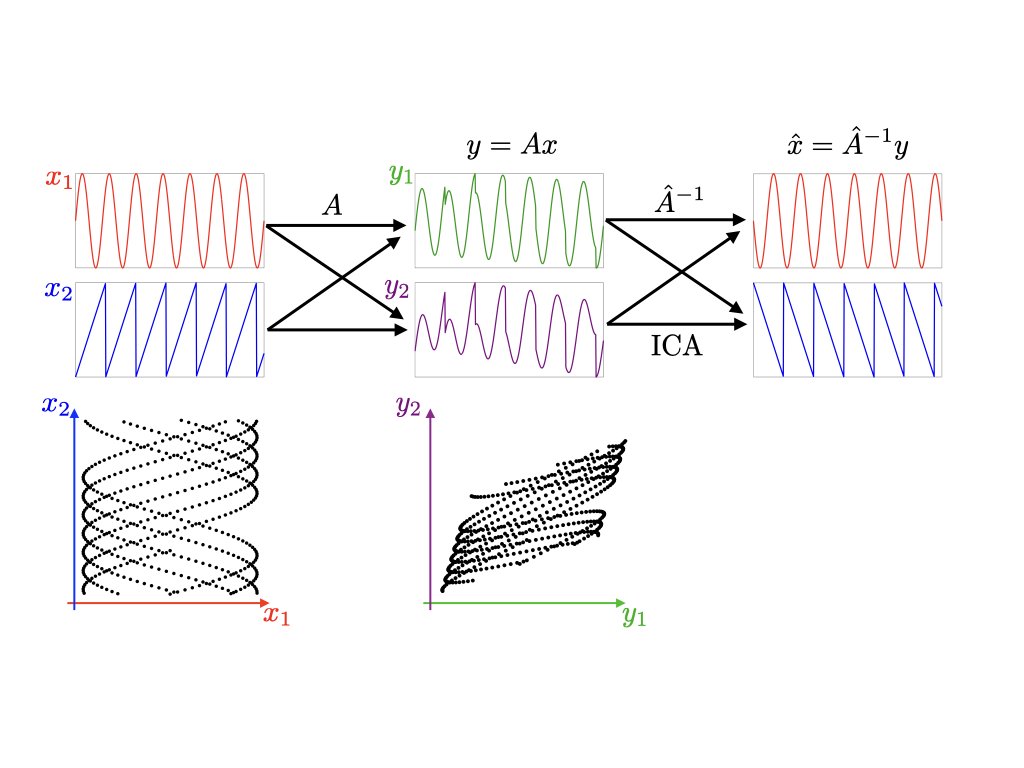
Independent component analysis estimates a mixing matrix leveraging the non-Gaussianity and independence of the sources. Solves a matrix factorization problem. https://t.co/dQBmNeqmKt https://t.co/AxQsE0YqlX
Watermarking does not solve for identifying AI content in the real world From the paper: "enforcing watermarking on [open source] models deployed in a decentralized manner is difficult.... generative watermarks are weakened by edits to the text, such as through LLM paraphrasing" https://t.co/uctFYp0qDU

IBM devs release Bee Agent Framework, an open-source framework to build, deeply, and serve agentic workflows at scale. Features include: - Bee agents refined for Llama 3.1 - sandboxed code execution - flexible memory management for optimizing token usage - handling complex agentic workflow controls and easily pausing and resuming agent states - provides traceability through MLFlow integration and event logging, along with production-grade features such as caching and error handling. - API to integrate agents using an OpenAI compatible Assistants API and Python SDK - serve agents using a Chat UI

3.6 sonnet with higher temperature works REALLY well with MC bench. Possibly the best model I've seen with the least effort put in by me. Just one example, will update this thread. https://t.co/OGtIeLEIsS
LLMs Reflect the Ideology of their Creators Finds that LLMs exhibit a diverse ideological stance which reflects the worldview of its creators. "By identifying and analyzing moral assessments reflected in the generated descriptions, we find consistent normative differences between how the same LLM responds in Chinese compared to English. Similarly, we identify normative disagreements between Western and non-Western LLMs about prominent actors in geopolitical conflicts."

I don't remember Claude being *this* fucking judgey before… Seriously, this does not, in any way, make anyone more "safe". https://t.co/8NItLFaOKB
"'Agent' might become a 'noise' term, subject to both abuse and misuse, to the potential confusion of the research community." - M. Wooldridge, The Knowl- edge Engineering Review. (1994) https://t.co/Lo2OpLSbQy

I've said it before: Structured generation is the future 🔮 The @dottxtai team has ported its core Outlines algos to rust, which means from now on, structured LLM generation is: - faster - more robust - embeddable into any ML software (no need for Python anymore) ^#3 is my personal favorite

U wanted to use @cursor_ai on latex but it doesn't autocompile when saved like overleaf right? here is latex installer + watcher + command maker setup code that makes your linux machine into overleaf-like environment, so you can use cursor instead of overleaf. https://t.co/2JNSaAtDRC
another schmidhuber moment of mine: LLM agents from 2016-2017. https://t.co/hDxXFQ8Vzc