Your curated collection of saved posts and media
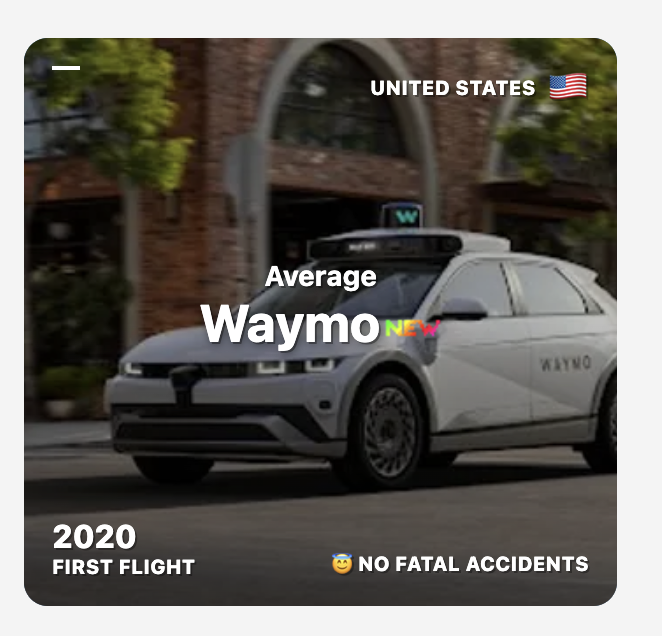
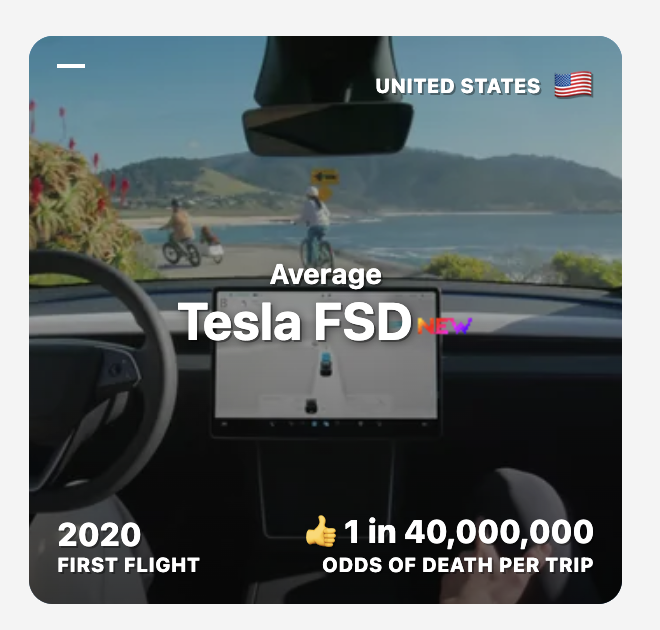
Also added Waymo and Tesla FSD to https://t.co/7sQDNqbZhr Interestingly, Waymo never had fatalities yet And Tesla FSD is ~4x safer than the average car (in fatal odds per trip) 1,190,000 people die every year in traffic deaths 80% of those would be prevented with self driving, meaning you could save 952,000 lives every year if all cars became self driving overnight! After heart disease and cancer, traffic deaths are the biggest killer, so it should be one of the government's biggest priorities to roll out fast!
https://t.co/zVn7JHebEI
Post your best codex billboard

https://t.co/zVn7JHebEI

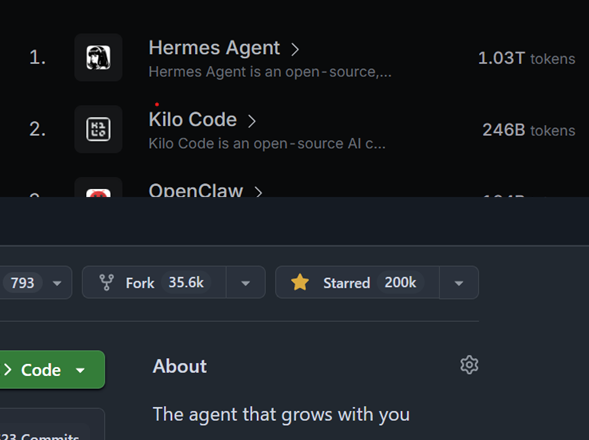
A trillion tokens a day and 200k GitHub stars Very proud of the Hermes Agent team and what we've built at @NousResearch "Better today than yesterday, better tomorrow than today" https://t.co/vCgDKdYeRy
https://t.co/wbBJGtF6Ot
Post your best codex billboard

https://t.co/wbBJGtF6Ot

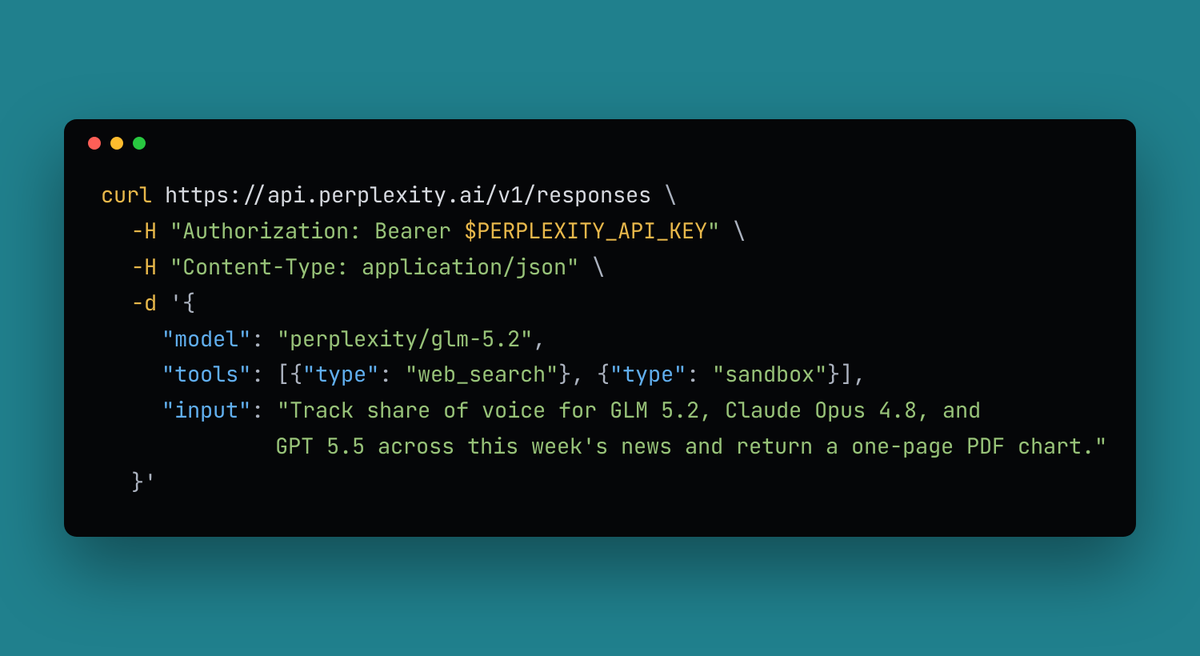
@Zai_org's flagship model, GLM-5.2, is now available in Perplexity's Agent API. GLM-5.2 is one of the strongest open-source models for long-horizon coding and agentic workflows. It shines in Agent API, making particularly effective use of our Search as Code architecture. Combine frontier reasoning with real-time programmatic search with just one API call. OpenAI-compatible interface and first-party pricing with no markup. Get started: https://t.co/tADlfN6X6c
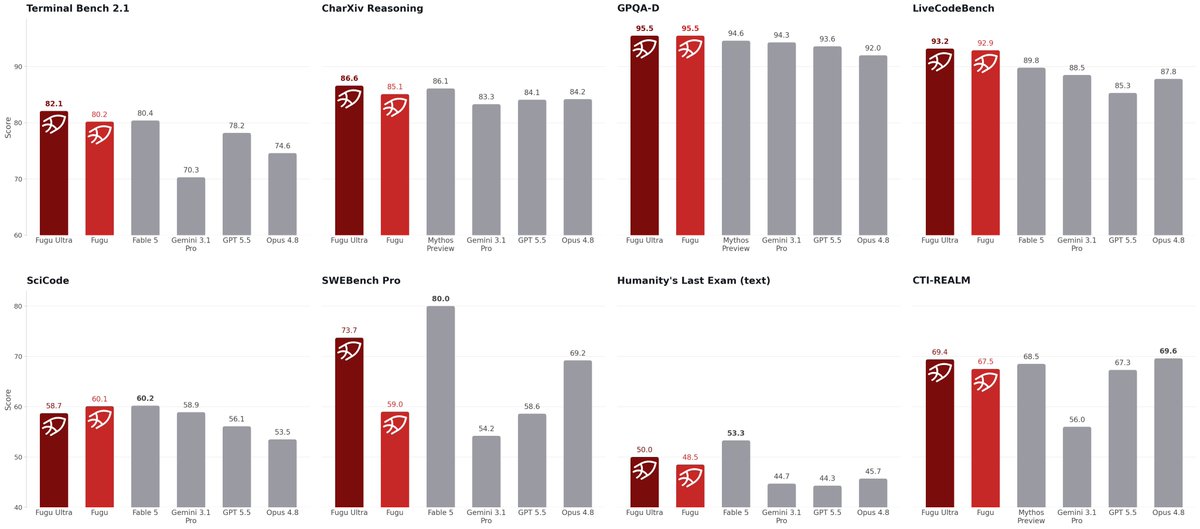
I've been trying @SakanaAILabs Fugu Ultra as an oracle to replace Fable I packaged it up as plugin for codex/claude https://t.co/dOJpOxsIS2 I don't have rigorous evals 😅 but vibes seem like its a bit jagged in its abilities. ex: It seems great for code review but not for front end development. Curious what other's found so far
https://t.co/Mn9W4nHH40
Post your best codex billboard

https://t.co/Mn9W4nHH40

the tag team’s back together!!! reunited. in sf. and so soooo ready for another szn of @aiDotEngineer ✈️🇺🇸 https://t.co/jR30faX1Uu

Use Case 5: Rubik’s Cube Solver Can an AI write complex algorithmic solvers from scratch? We tasked Fugu Ultra and three frontier models with writing a Rubik’s Cube solver in pure Python from a single prompt. No off-the-shelf solving libraries were allowed. We then ran the resulting programs locally on 300 randomly scrambled cubes. In this example, Fugu Ultra’s solver reaches the goal in 19 moves compared to Model A (best of the three models)’s 21 moves. The Results: • Fugu Ultra and Model A generated solvers that successfully ran and solved all 300 cubes. • Models B and C shipped sophisticated-looking code that completely crashed on execution (0/300). • Fugu Ultra was strictly more efficient, averaging 19.72 moves versus Model A’s 19.76, and never requiring a single move more than Model A across all 300 scrambles. For code generation that actually executes and optimizes for efficiency, dynamically orchestrating multiple agents beats relying on a single monolithic model.

Use Case 6: Classical Japanese Kana Reading Order It would not be a Sakana AI launch without a uniquely Japanese challenge. Can an AI decipher the chaotic layout of a 400-year-old letter? We tested whether the models could recover the reading order of "scattered writing" (chirashigaki) in a letter from 1610. This letter is held by the Keio Institute of Oriental Classics. Given character bounding boxes and a rough set of rules, the models had to write code to predict the exact order the characters should be read. In the clip below, the green line is the expert ground truth. The red line is the AI’s prediction. The Results: • Fugu Ultra achieved a 0.80 accuracy score, tracing the highly complex path almost exactly. • Models A and B scored a dismal 0.24, jumping wildly and incorrectly all over the page. • Model C failed to produce a working predictor at all. You might not decode 17th-century calligraphy every day, but this proves Fugu’s unparalleled ability to handle extreme spatial reasoning and completely novel, non-linear logic.

Being a leader has its own risks. The market rarely asks whether you're doing well. It asks whether you're doing better than expected. https://t.co/gOkkmZBrj9

we made an interactive movie in a day - powered by a world model - running in real time - you can explore and make your own choices this is Operation Pandora. play now 👇 https://t.co/gQ2NevjC52
@jxnlco https://t.co/uEFoiyi8AB

@jxnlco https://t.co/uEFoiyi8AB

@jxnlco https://t.co/Hgq9lay1xu

@jxnlco https://t.co/Hgq9lay1xu

@jxnlco https://t.co/VEU12DAm1t

@jxnlco https://t.co/VEU12DAm1t

@jxnlco https://t.co/UIPoA53tWo

@jxnlco https://t.co/UIPoA53tWo

@jxnlco https://t.co/O5JnYkxgBO

@jxnlco https://t.co/O5JnYkxgBO

Codex irl https://t.co/DP2z8DTa4Y

Collab? https://t.co/fW6z6mTEPb
Post your best codex billboard

Collab? https://t.co/fW6z6mTEPb

https://t.co/P5GRV4YxlT
Post your best codex billboard

https://t.co/P5GRV4YxlT

@jxnlco https://t.co/Ihw7pzdpA9

@jxnlco https://t.co/Ihw7pzdpA9
