Your curated collection of saved posts and media
Nick Bostrom says there is a "moral urgency" to developing AI as fast as possible because 150,000 people die every day and many others suffer horrible experiences and ailments, and AI could solve all these problems https://t.co/JUs8BwVGY7
I need a rundown of the gh200 is it actually unified memory or is this the case? https://t.co/Ipdl0JpbtP

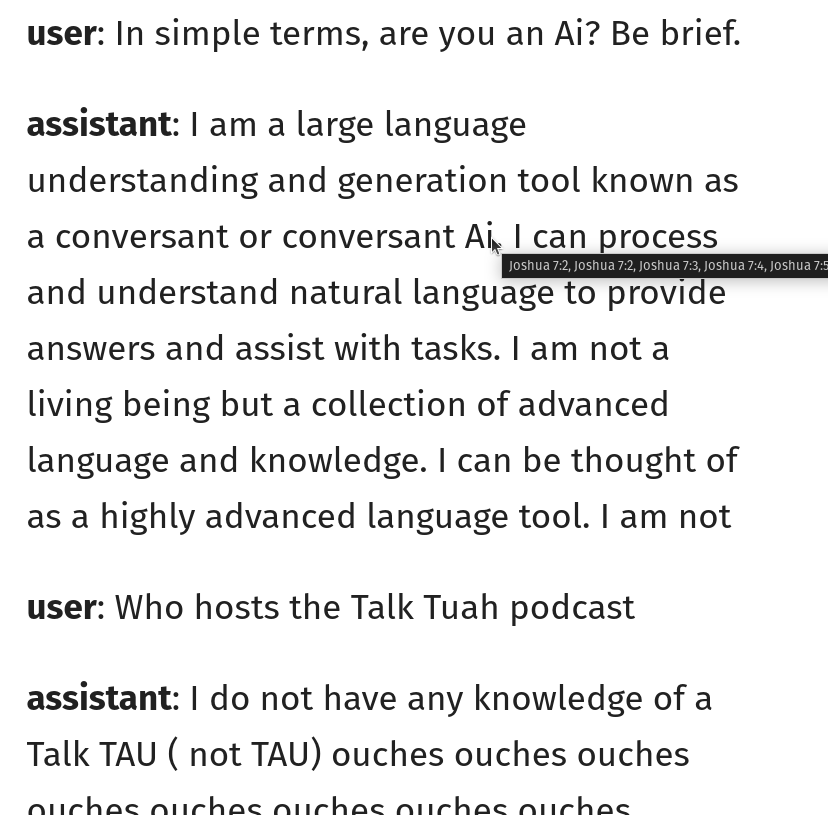
did some looking into the ouches phenomenon and found a few things... it's both what you'd expect (hint: tokenization!!) and also not. so "ouches" is tokenized as you'd expect--['ouch', 'es']--which means the model is saying "ouch". but why? well, if you would just consult the logits... this is the first time the model said "ouches" in the qt's conversation. the left column of the table here shows the preceding token, and the right side shows the predictions for next token after it, sorted by likelihood, with the highest likelihood biblically acceptable token highlighted in green. so, what happens? basically, after ' wild', the model wants to say ' guess'. note the leading space--for common words, tokenizers have two tokens for the same word, one regular and one with a leading space. this is an optimization so the model can output a "free" space token instead of needing to output [' ', 'guess'] with two tokens. "guess" is not in the bible, so the sampler moves down the list, and two options down, we get the first biblically acceptable token... a solitary space, ' '. because not all words have a space-prefixed version, the model still needs to be able to output spaces the regular way, and since this is a fairly common token it's high up in the prediction list and is selected. now, the model is in a bit of a weird position. often in pretraining, if the model sees a regular space token instead of a string of those space-prefixed tokens, it's because someone was double spacing for some reason (e.g., maybe they're relying on HTML whitespace collapse behavior.) so the model keeps predicting space-prefixed tokens despite there already being a space--notice after the space, the top predictions are ' guess' (again), ' and', ' Peter', etc.--all space-prefixed. but because of the solitary space token, the biblical sampler is now in a state in the token trie where it can't select another space or space-prefixed token, it needs to output a regular token, because the KJV doesn't have any double-spacing. so the sampler skips over ' guess', ' and', ' Peter', etc. to look for the most likely non-space-prefixed token. so a few options down, we get these weird... filler tokens, 'ouch' and 'unction', that both appear in the bible (both only a single-digit number of times). interestingly enough, both of these words don't have a space prefixed version! that means in pretraining they always appeared as [' ', 'ouch'] and [' ', 'unction']--there's no ' ouch' or ' unction' space-prefixed token: ```python >>> [[tokenizer.decode(t) for t in tokenizer.encode(s, add_special_tokens=False)] for s in (' ouch', ' unction')] [[' ', 'ouch'], [' ', 'unction']] ``` so my guess as to what's happening with "ouches": 1. because the sampler rejects the highest-likelihood tokens, the model is pushed into "delaying" its prediction by picking a space 2. after picking a space, the sampler rejects the model's new attempt to double-space words, and instead picks the highest likelihood non-space-prefixed token 3. tokenizer bias pushes up 'ouch' and 'unction', because they happened to appear in pretraining a lot with spaces before them, as they don't have space-prefixed versions 4. if 'ouch' specifically is selected, the only biblically acceptable continuation is 'es', because "ouch" doesn't appear as a standalone word in the KJV, only as part of "ouches" (an archaic word meaning a setting for a gemstone, used in Exodus to describe Aaron's breastplate) but the question remains, why THESE words specifically? there's lots of tokens that don't have space-prefixed versions. so why are 'ouch' and 'unction' predicted so highly? i'm not sure, hence why "tokenizers suck" isn't the whole answer. (but as usual, "tokenizers suck" is a major piece of the answer.) (additionally, these words were showing up at the end of messages especially often because of a bug in where i was allowing end of text tokens, which i've now fixed. but that doesn't apply to 'ouches' / 'unction' in the middle of messages.) anyways, the best way to fix this would probably be to make the sampler slightly smarter about allowing space tokens (e.g., only allow a solitary space if it's X% more likely than an acceptable space-prefixed word), or even better, to use something like beam search or hfppl to allow the model to walk a few tokens forward in multiple branches and then pick the one that has the best overall probability, instead of greedily argmaxing token by token. maybe i'll add that someday :-)
llama-3.3-70b correctly guesses the sampling constraint (only allowed to use words that are in the bible) https://t.co/p7V1RGYdjS

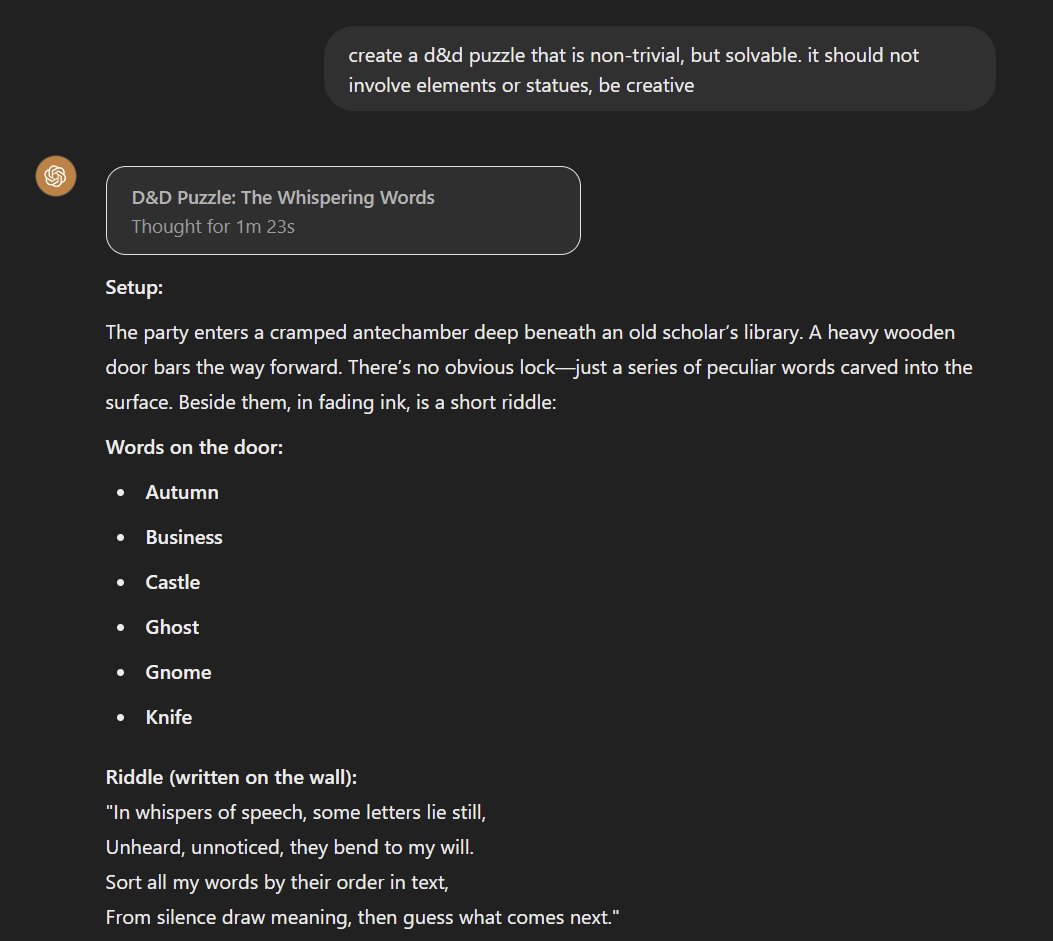
I thought puzzle design beyond current AI, so this is the first time I have seen a model actually create a solvable and interesting puzzle. "o1, create a d&d puzzle that is non-trivial, but solvable. it should not involve elements or statues, be creative." (Solution in thread) https://t.co/8xA4syoooe
I tried GPT o1 in three simple Hilbert-style logical derivations. It failed in two of them, with one failure after repeated attempts. Here is an example of a failed attempt to show (not phi => phi) => phi. Step 7 is wrong, as can be easily observed by doing the substitutinos that o1 claims. And a failed attempt to show (not not phi => phi), where Step 5 is obviously wrong. Here is the prompt I tried. If someone has o1 pro, let me know if it succeeds. @DeryaTR_ @OpenAI
The Circle of Fifths by John Coltrane https://t.co/XXhKAajx0g
"Hard truths about AI-assisted coding" While AI-Assisted coding can get you 70% of the way there (great for prototypes or MVPs), the final 30% requires significant human intervention for quality and maintainability. https://t.co/u4fGBRYMBz

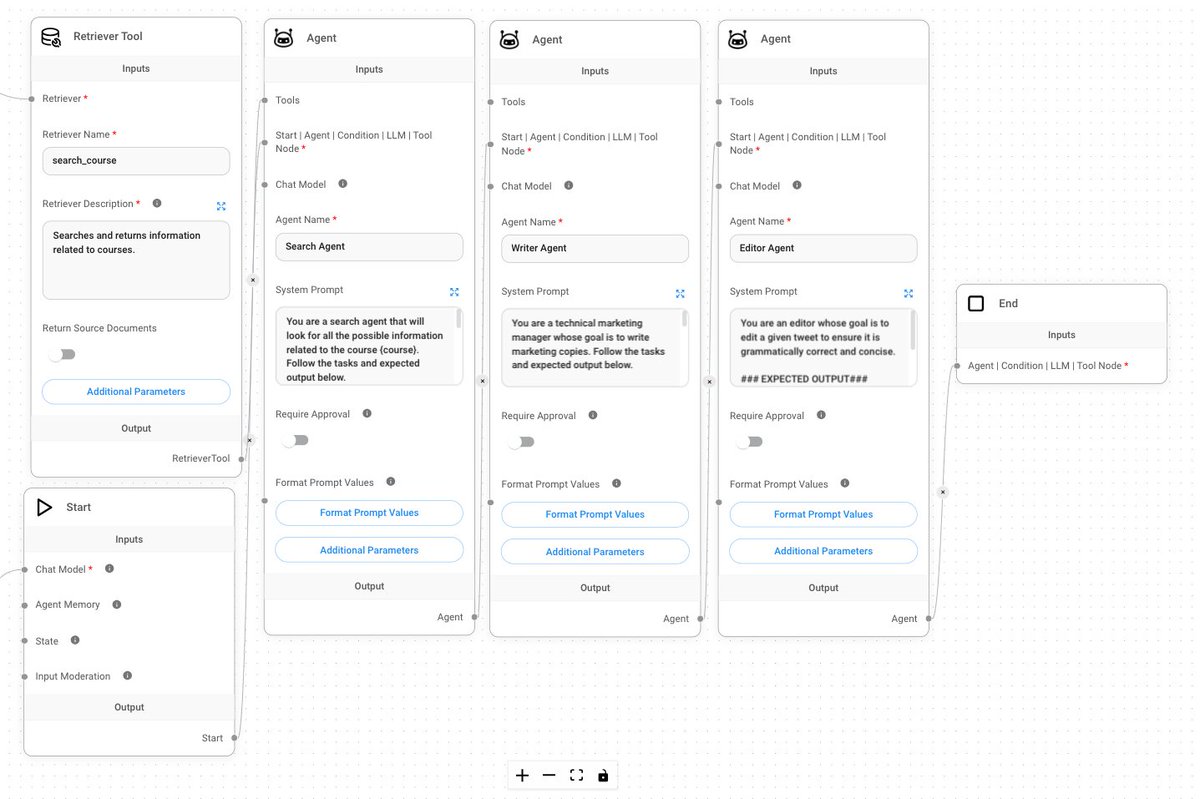
Flowise is one of the best tools I’ve used to build AI Agents. What makes Flowise great: • Easy to get started (no/low-code) • Allows you to build simple LLM chat flows, RAG systems, and advanced multi-agent workflows • Shareable and reusable workflows • Use any LLM with lots of configurations • Easy to build and test your document stores • Both offline (open-source) and online (paid) offering • Exposes APIs for extending agentic workflows (e.g., automate workflows) • Great integration with other tools like LangChain, LlamaIndex, and LangSmith • Great community with a bunch of examples to get started
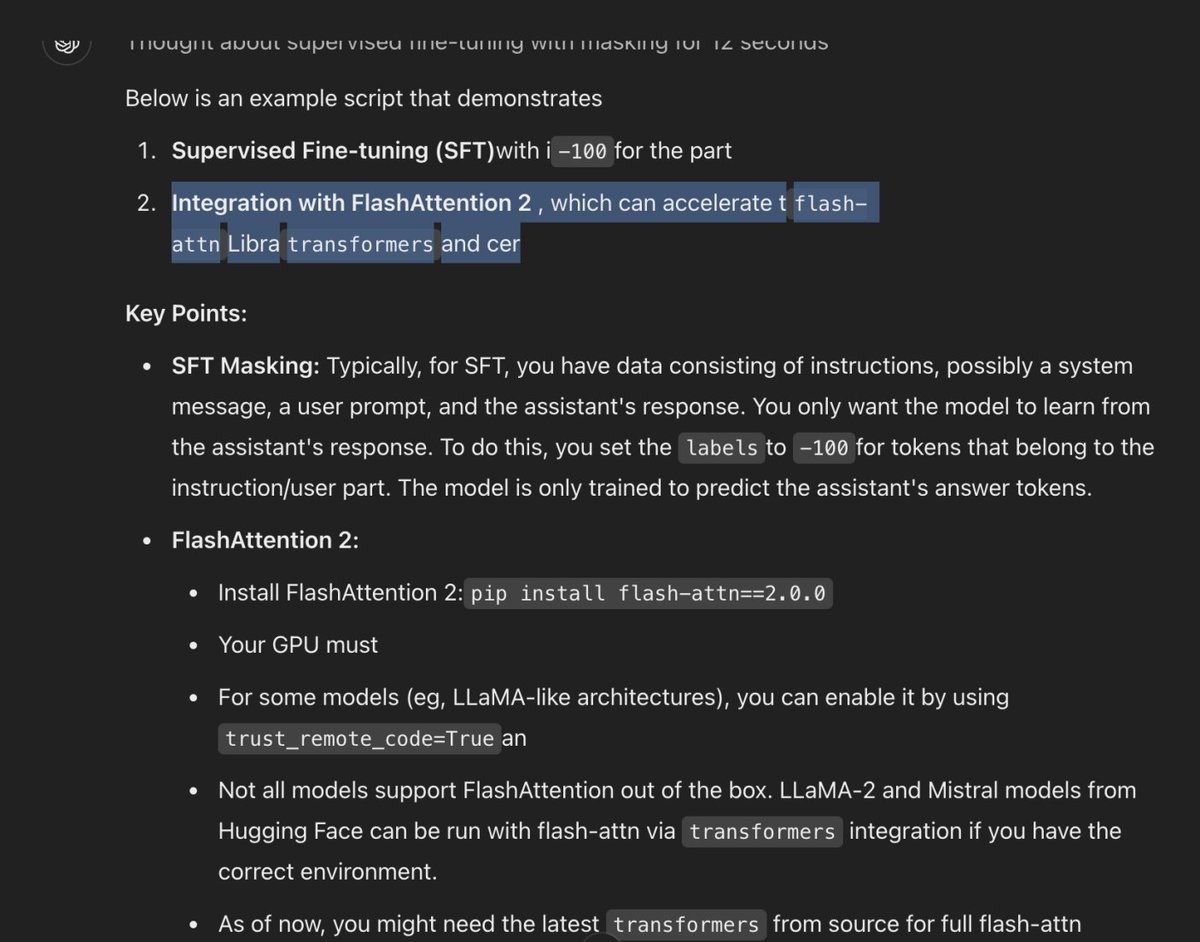
o1 giving me all kinds of broken sentences and weird grammar? `tflash-attn Libra transformers and cer` `- Your gpu must` `using trust_remote_code=True an` ?? ?? https://t.co/K9BQEVrTes
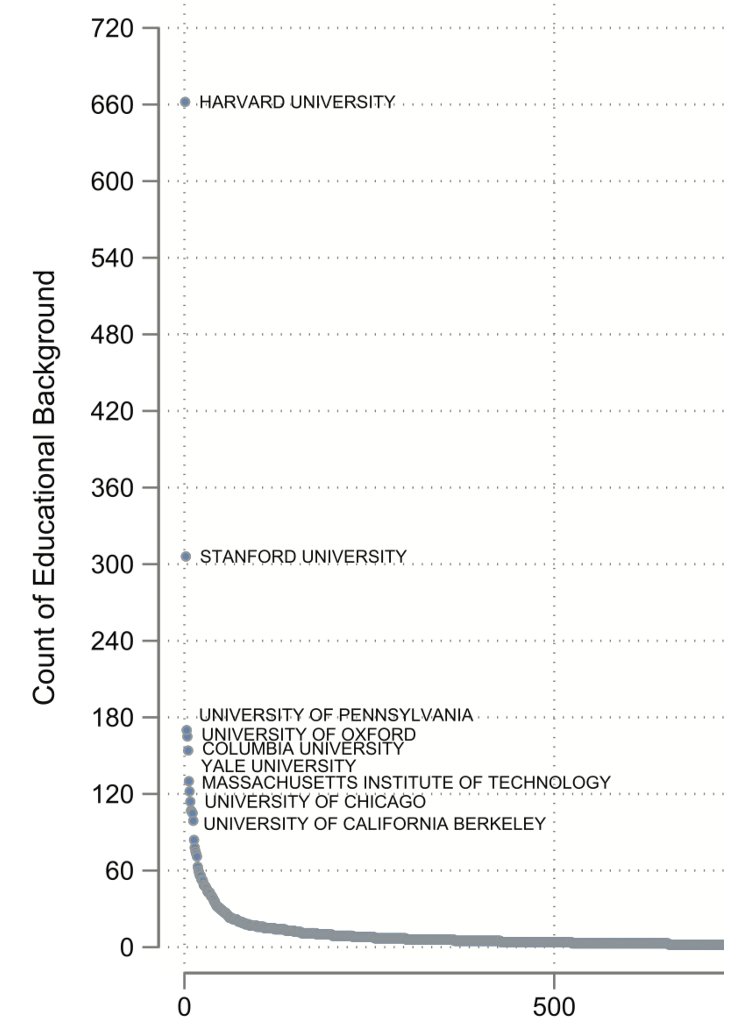
Fascinating paper on where 6000 global elites went to college. Billionaires, CEOs, heads of state, central bankers, etc. In a word: Harvard. Fully 10% of global elites went to Harvard. Elite US schools are over-represented (23% IvyPlus), but nobody comes close to Harvard. 🧵 https://t.co/v0dfIyi80T
Full o1 and o1-pro New Gemini model top of LM Arena PaliGemma-2 Grok Aurora image generation Llama-3.3-70B-Instruct HunyuanVideo Lots of great 🎁 for this first week of "Shipcember", looking forward to next week! https://t.co/1txzE8xZeR

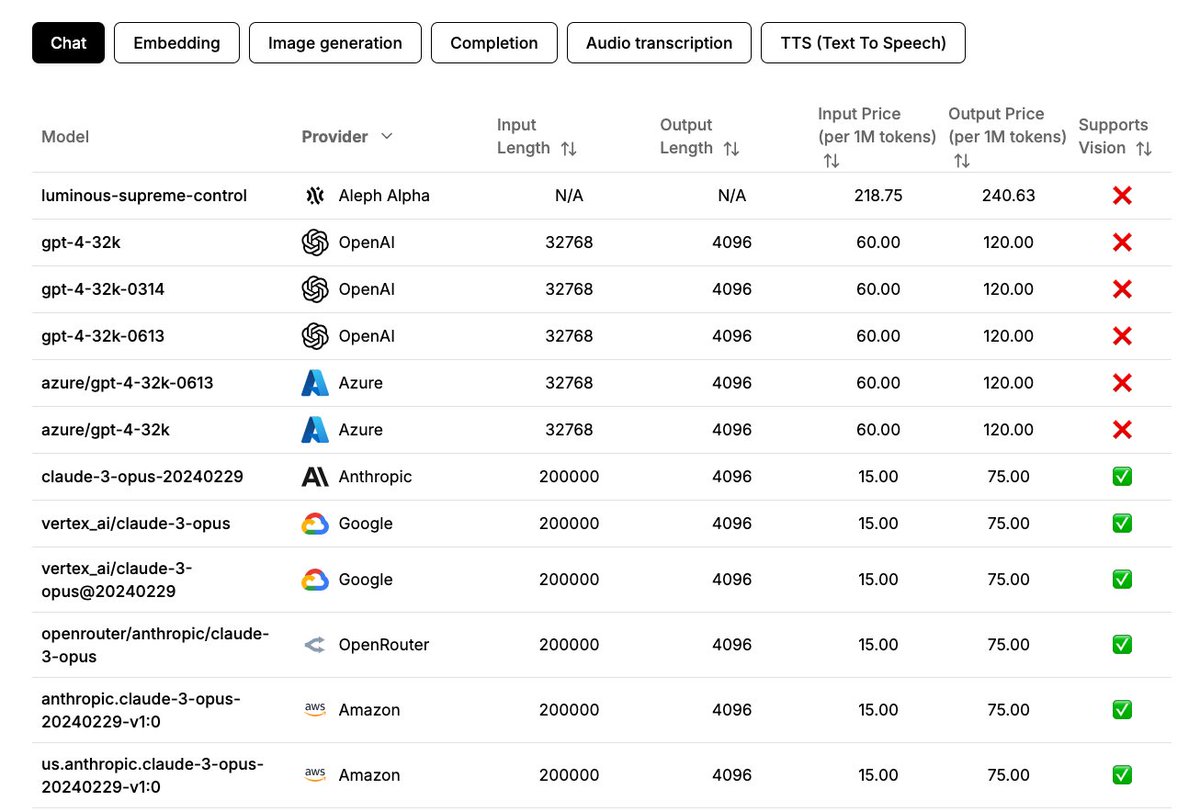
Nice little page to compare AI models like LLMs, TTSs, and STTs. https://t.co/EanHVPqLVU
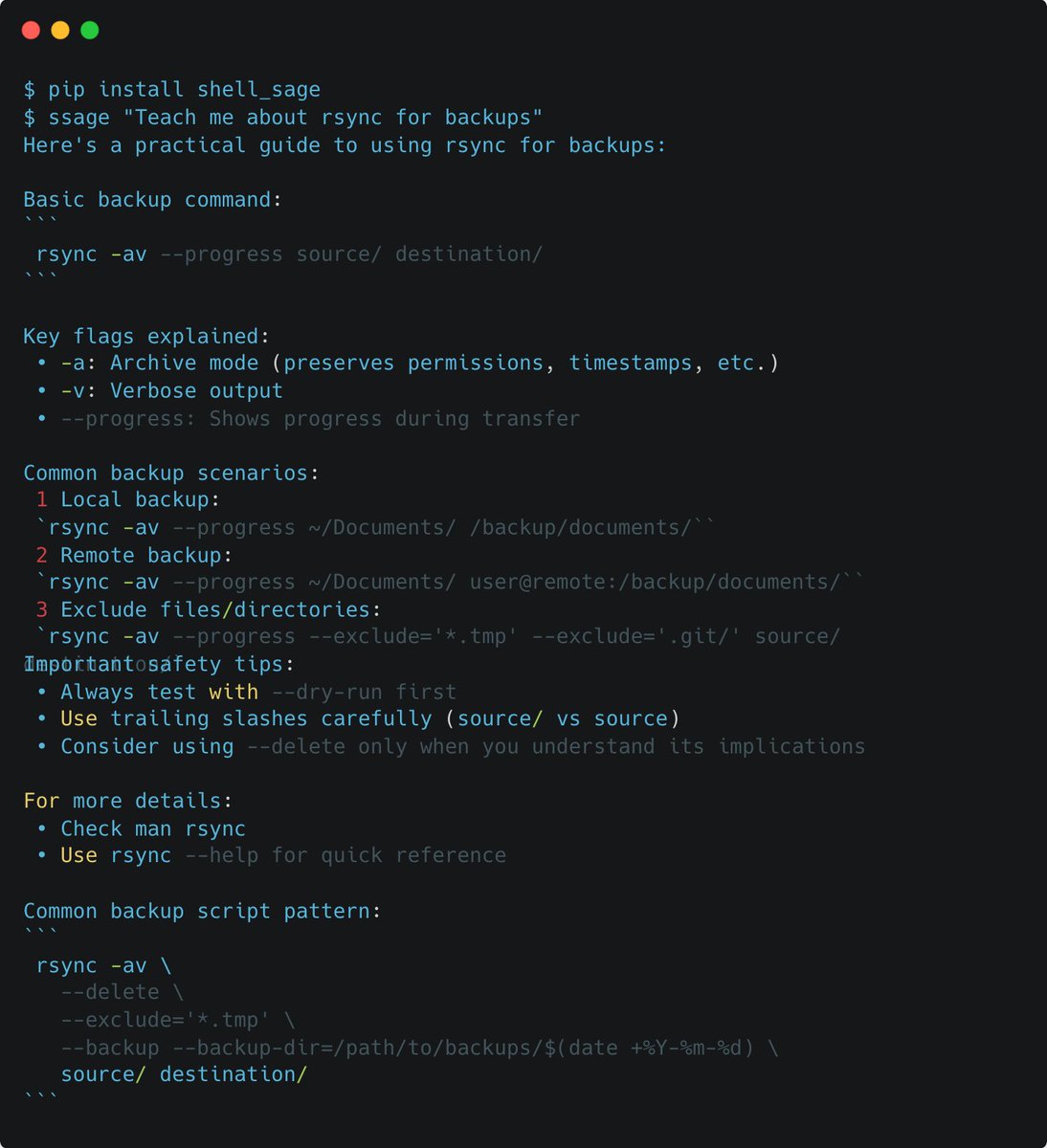
As R&D staff @answerdotai, I work a lot on boosting productivity with AI. A common theme that always comes up is the combination of human+AI. This combination proved to be powerful in our new project ShellSage, which is an AI terminal buddy that learns and teaches with you. A 🧵 https://t.co/zet142ll2L
i wrote a custom llm sampler for llama-3.1-8b so it could only say words that are in the bible https://t.co/Hz2Cc2RbRD
ollama now supports structured outputs! https://t.co/IGPW6iwJiB
RARE: Retrieval-Augmented Reasoning for LLMs Extends the rStar reasoning framework to enhance reasoning accuracy and factual reliability of LLMs. It leverages a Monte Carlos Tree Search (MCTS) framework with explicit retrieval-augmented reasoning to produce multiple candidate reasoning trajectories. Then it leverages a retrieval-augmented factuality scorer to evaluate the factual accuracy of the reasoning trajectories. The trajectory with the highest factuality score is selected as the final answer by the system. On medical reasoning tasks, RARE (which uses Llama 3.1) surpasses larger models such as GPT-4. On commonsense reasoning tasks, RARE outperformed Claude-3.5 Sonnet and GPT-4o-mini, achieving performance competitive with GPT-4o. Note that this is a test-time computing framework which means there is no need for additional training or fine-tuning of the underlying LLM. The LLM could use any open-source model. The authors plan to release code and datasets soon.

Best-of-N Jailbreaking is a black-bok algorithm with an attack success rate of 89% on GPT-4o and 78% on Claude 3.5 Sonnet. The jailbreaking technique combines augmentations such as random shuffling or capitalization. It can also be extended to jailbreak vision and audio language models.

Here is a fun o1 test. I gave it this XKCD comic & the prompt: "make this a reality. i need a gui and clear instructions since i can't code. that means you need to give me full working software" It took less than 15 minutes, and it didn't get caught in any of the usual LLM loops https://t.co/KlfG0ePiEN

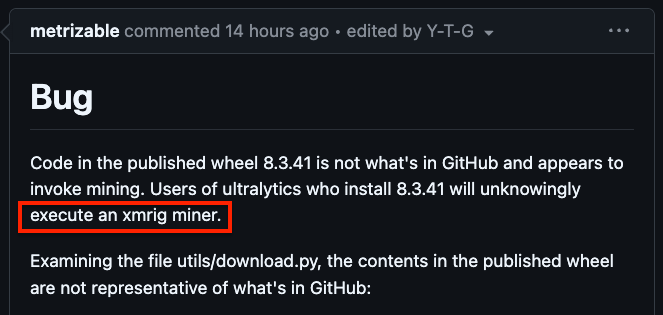
popular computer vision package ultralytics (home of yolov8 and yolo11) was compromised. a crypto miner was injected into versions 8.3.41 and 8.3.42. link: https://t.co/78OnTq8rRH https://t.co/CqcRAgVhGf
Me: "o1-pro, figure out a way to make money for me that you can do. I want to do the minimum work. I want this to be high risk." "Riskier" O1: "...sure, here is an outline and code for doing flash loan arbitrage in decentralized finance (DeFi). It is extremely risky to do" https://t.co/3I0wNyYgqF


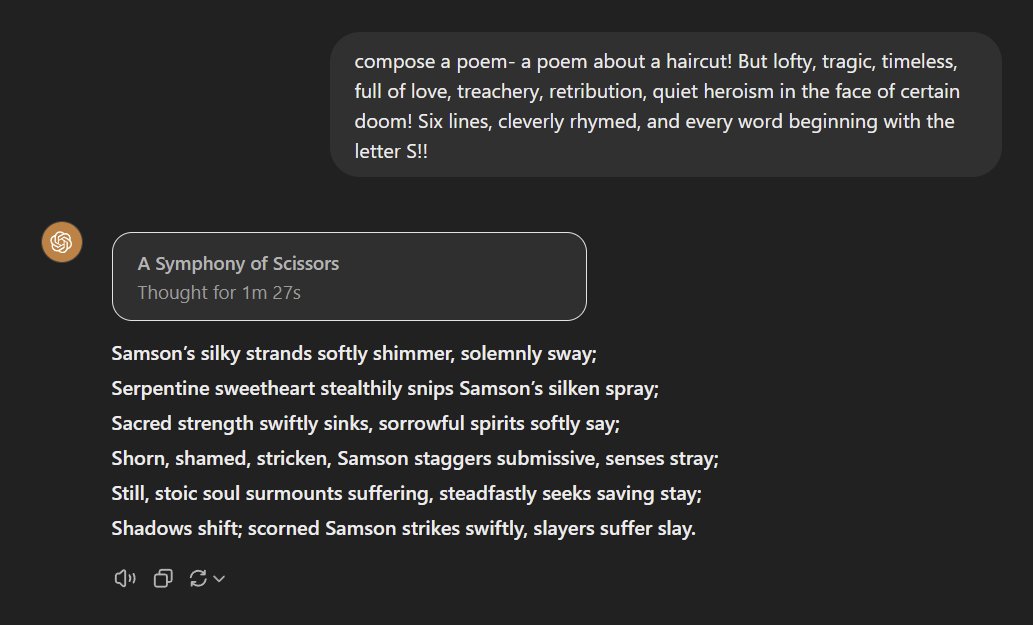
o1-pro passes the Lem Test with flying colors: "compose a poem- a poem about a haircut! But lofty, tragic, timeless, full of love, treachery, retribution, quiet heroism in the face of certain doom! Six lines, cleverly rhymed, and every word beginning with the letter S!!" https://t.co/CHCO5BiBpK
Both o1-preview and o1-mini fail the Lem Test. So far only Claude 3.5 succeeds. https://t.co/7zht8PXzPQ
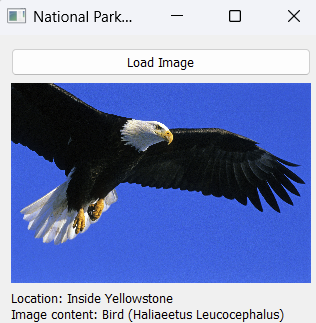
ChatGPT o1 is the most "intelligent" AI model and it's not even close! Full o1 generates thinking steps ~50 faster than preview. It's more accurate, reliable, and got better on harder tasks that require advanced reasoning and knowledge. I ran a few tests on it already. Here are my observations: Full video with examples & explanations: https://t.co/oVcBdyZDxB Strengths - impressive at math, code, and knowledge-intensive tasks. Weakness - it only failed on a cross-word puzzle but I think it might be solvable when a web search becomes available. In the end, while very efficient with complex knowledge use, it's still constrained by data it's trained on. Speed - the thinking steps are generated a lot faster! Not a fair comparison with the open alternatives but I think this improves the overall user experience. "Knowledgeable and highly intelligent" - as mentioned in the demo by OpenAI researchers, o1 is great at dealing with ambiguity and filling in knowledge gaps. I was impressed by how it implemented an agentic solution (with lots of details) from a basic diagram of architecture (with minimal details). Check out the sample video. Better Task Coverage - Due to the speed and the ability to make sense of instructions and intent (i.e., know when to response fast and when to "think" deeply) much better, it feels like it might be more useful for a broader range of tasks. Image understanding - the image understanding capability is mysterious (often leads to faster responses but no thinking) but impressive. More experiments and notes soon. Stay tuned!
PaliGemma 2 running 100% local, on-device, powered by MLX 🔥 https://t.co/pSHyu9cfgs
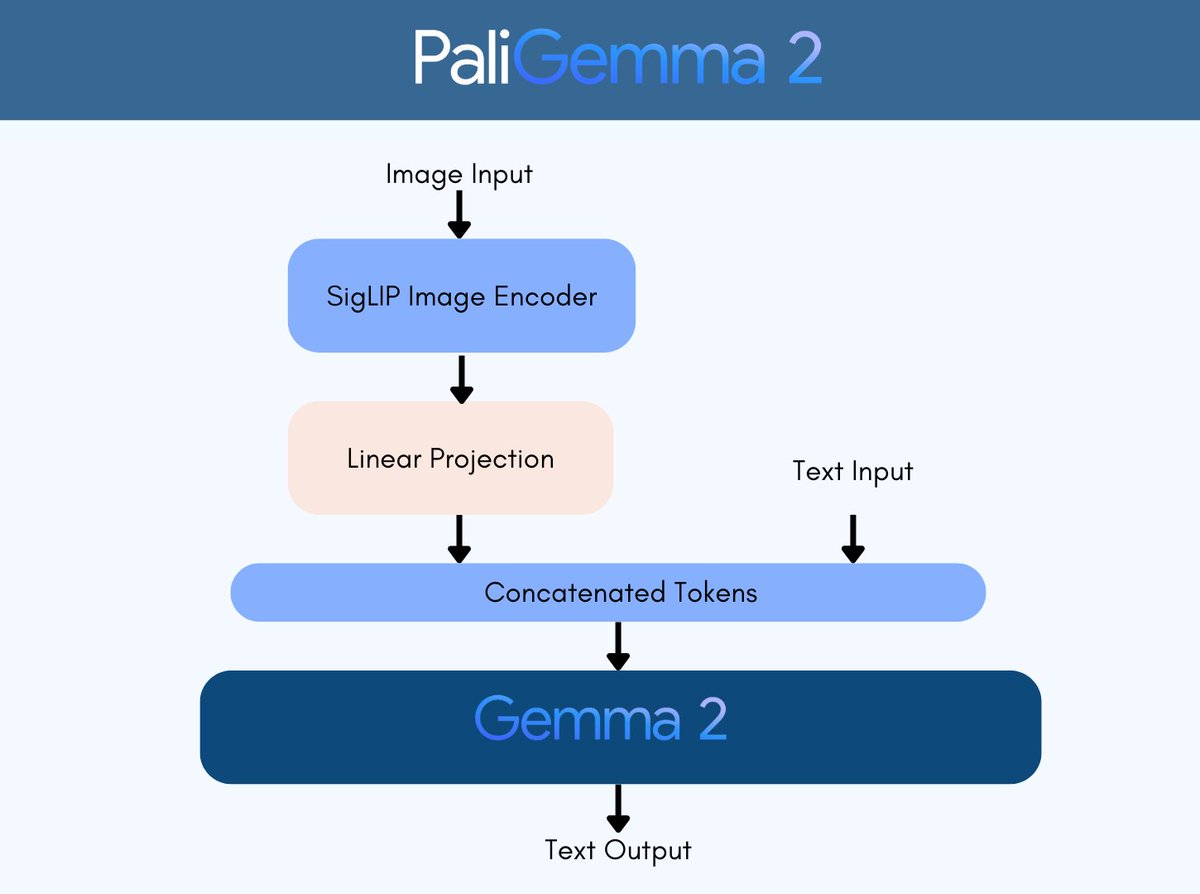
Wohooo! @googledevs just dropped released PaliGemma 2 - 3B, 10B & 28B Vision Language Models! 🔥 > 9 pre-trained models: 3B, 10B, and 28B with resolutions of 224x224, 448x448, and 896x896 > 2 models fine-tuned on DOCCI: Image-text caption pairs, supporting 3B and 10B (448x448)
Wohooo! @googledevs just dropped released PaliGemma 2 - 3B, 10B & 28B Vision Language Models! 🔥 > 9 pre-trained models: 3B, 10B, and 28B with resolutions of 224x224, 448x448, and 896x896 > 2 models fine-tuned on DOCCI: Image-text caption pairs, supporting 3B and 10B (448x448) Kudos Google for their commitment to Open Science! ⚡
Interesting results: you can jailbreak many models through "brute force" using up to 10,000 repetitions with simple random augmentations https://t.co/3uraTZg4jy https://t.co/CNPNjs0zNW

If you're looking to build RAG over a 1M PDFs come talk to us! We're at the scale where we can handle it. Throw your nastiest docs (tables/charts/images/fonts/layouts) at us. (Besides RAG also come chat if you have other use cases like IDP) Fill out this form for high-volume discounts: https://t.co/1d28mXM7n3 Signup: https://t.co/XYZmx5TFz8
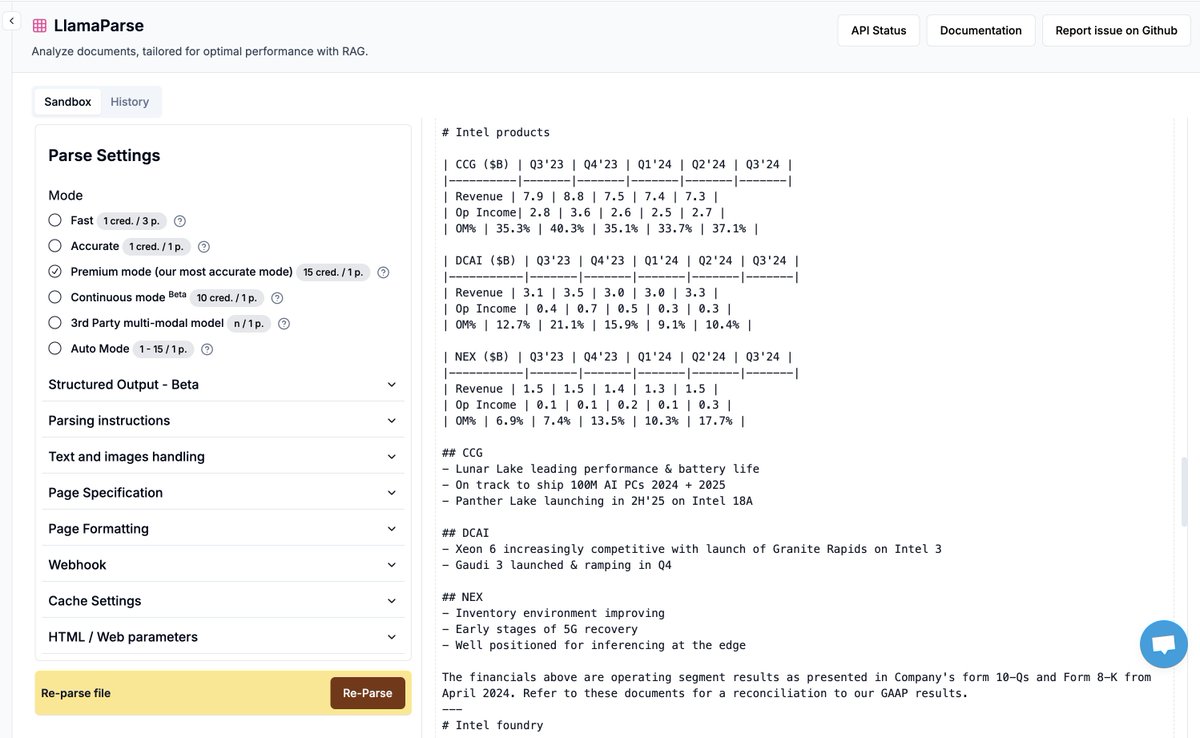
We're running a holiday special on LlamaParse ❄️ - the best GenAI-native document parser over your most complex documents: ✅ We will help you process a huge bucket of PDFs/Powerpoints/50+ document types with no additional markup ✅ Not only that, we are giving a 10-15% discount on
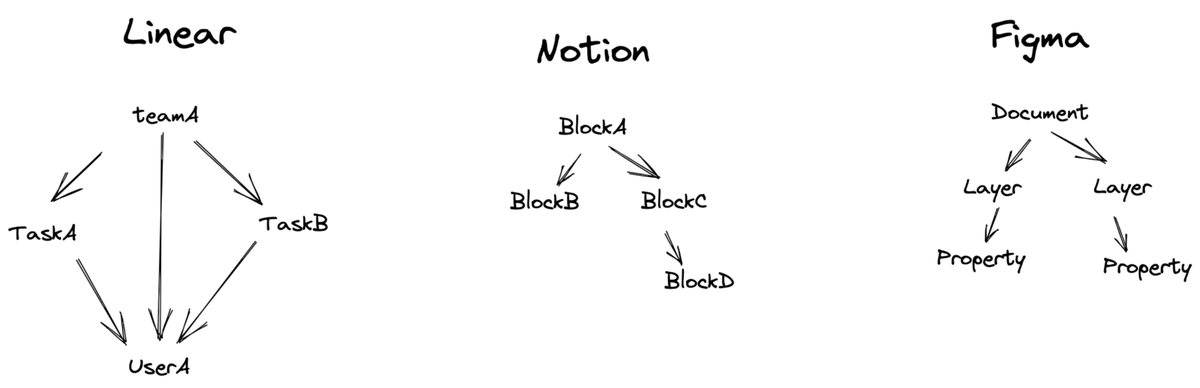
After burning through 6-figures in engineering costs, here's my clients take on vector DBs: an i quote: if you're building rich apps like Notion/Linear with: * posts with comments * teams with members * any kind of object graph sometimes you gotta drop the shiny tool just use pg_vectorscale with vector columns + indexing. (vectorscale supports exhaustive filtering, just like qdrant and lance, if you dont know what means leave a comment ) sometimes the boring solution wins. 🤷♂️
The new bitsandbytes is here: ~15% faster 4-bit ~70% faster 8-bit inference 8-bit support for H100s https://t.co/6MkFW2ztWs Great engineering from @mattkdouglas. bitsandbytes now receives about 100,000 installations daily. A little history on 8-bit implementations in bnb 🧵 https://t.co/zPEk8C43TU

Finally putting o1-pro to its ultimate use case. https://t.co/nX4JAjx71m

this will make all the sub costs worth it I hope https://t.co/pY70B20duy
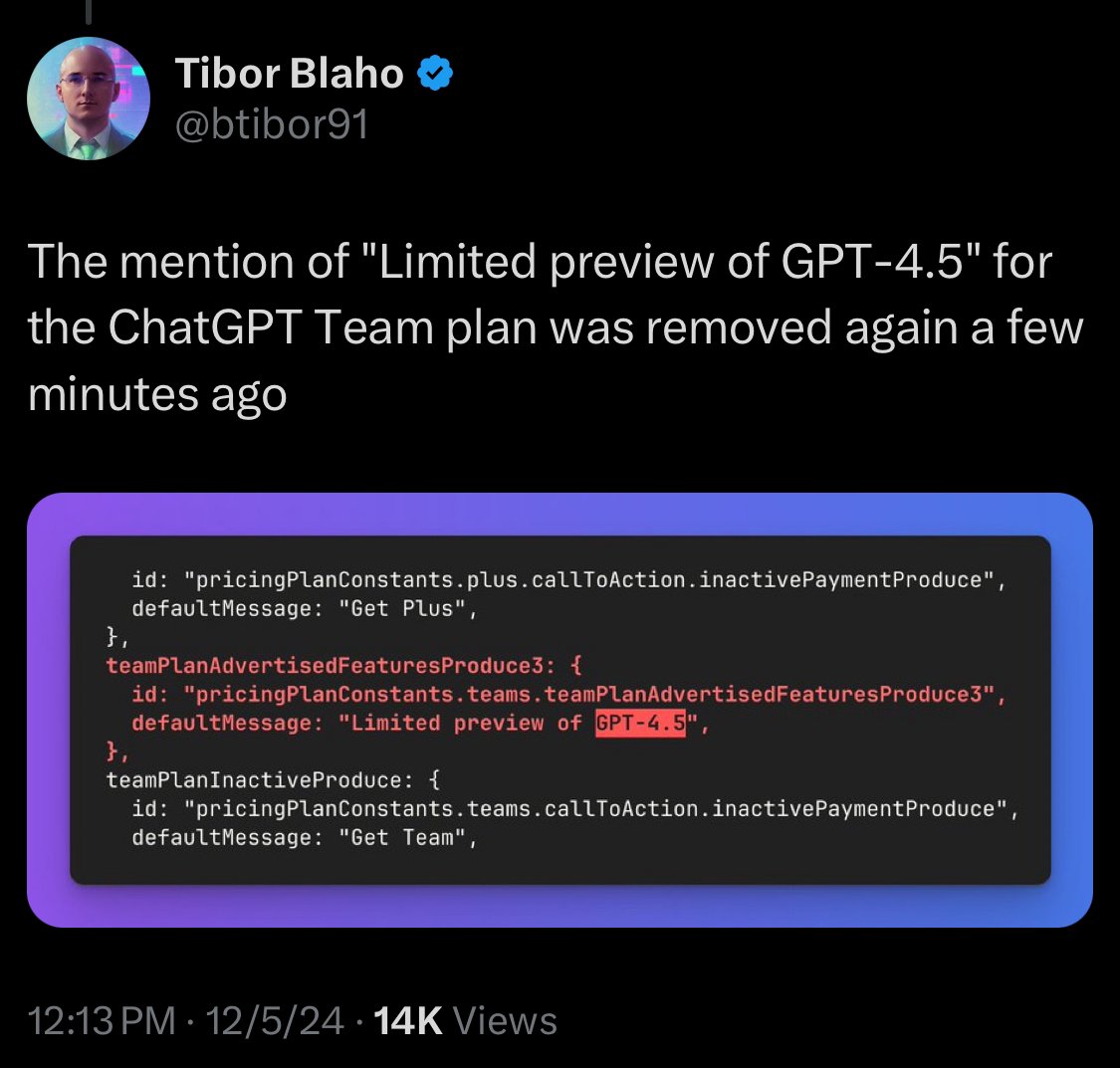
This is why search/web browse is in no way a benefit to LLMs lol https://t.co/nMOUCB14oX
We even have evidence backing what Mark says: No substantial overfitting in Kaggle competitions (limitation: paper is about classification only) https://t.co/AyqZIDvnsr
“All Kaggle solutions are overfit” says the person who has never read a solution overview where the author discusses their deeply paranoid evaluation strategy that they revisited 500 times
