Your curated collection of saved posts and media
DEIM is an advanced training framework for object detection with DETR. When applied to recent DETR based models, it results in faster convergence. The image below shows D-FINE and RT-DETR. I made a python package to let you train your own DEIM model using D-FINE models. 🧵👇 https://t.co/q8AfDA1zOU
A 256M open-source vision LM for complete document OCR just beat models 27× bigger. SmolDocling converts full documents into structured metadata using <500MB VRAM on consumer GPUs. https://t.co/DzGnIKUJFP
Llama 4 Maverick scored 16% on the aider polyglot coding benchmark. https://t.co/mBVaUPGHPl https://t.co/FT14gbbG1K
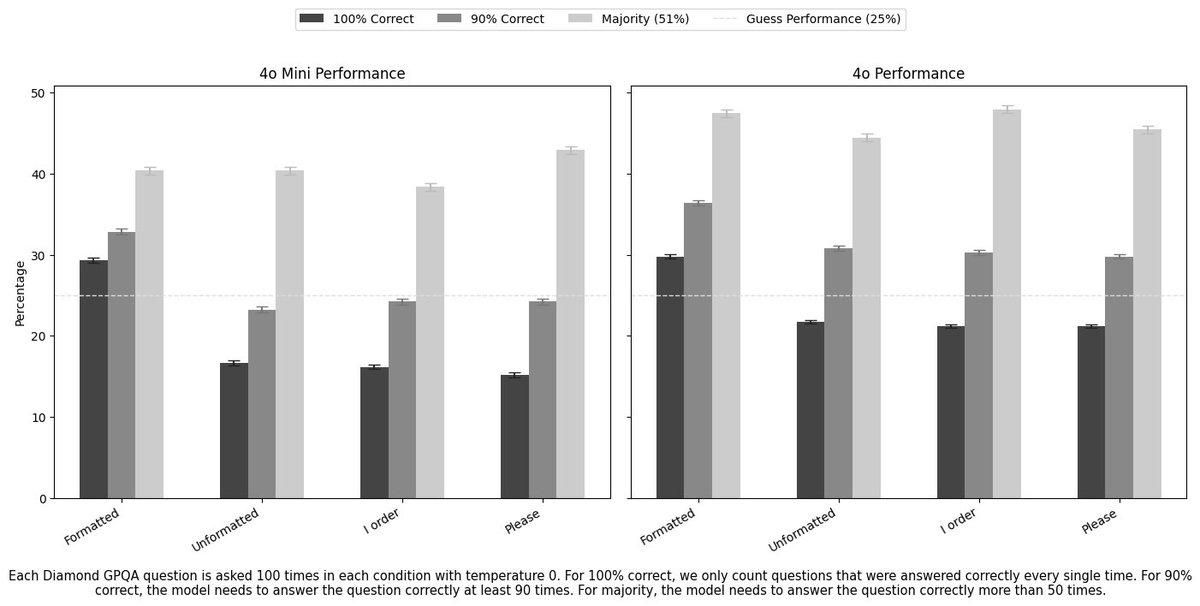
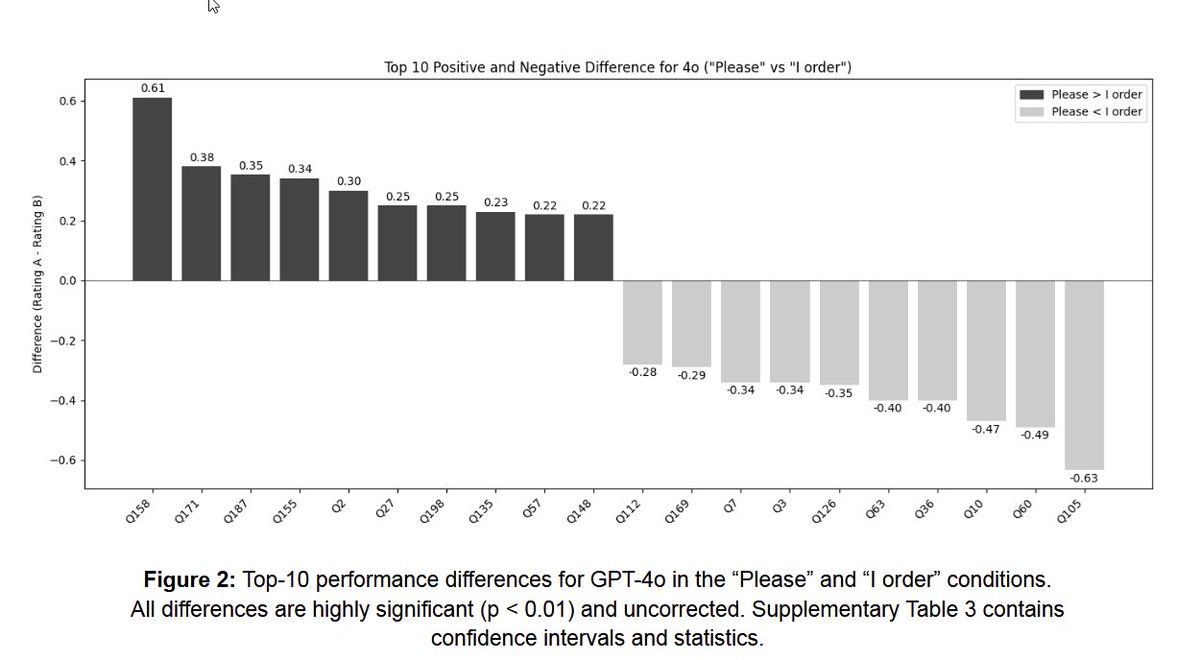
This keeps coming up, but, just in case you were wondering, being polite seems to have no effect on answer quality in aggregate. It greatly increases the quality of particular answers while greatly lowering the quality of others, and it is not possible to know which in advance. https://t.co/vNtxzSAIWj
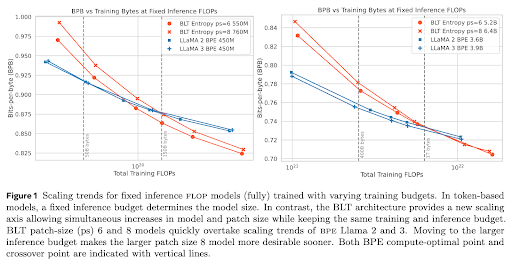
🚀 Introducing the Byte Latent Transformer (BLT) – An LLM architecture that scales better than Llama 3 using byte-patches instead of tokens 🤯 Paper 📄 https://t.co/5QGrlJdK0y Code 🛠️ https://t.co/jCdDI5BXwe https://t.co/7XyZdcXWoR
The level of insight that Ilya has about compute in *2017* is just insane. And so well-articulated in plain words. https://t.co/rWddko44Ev

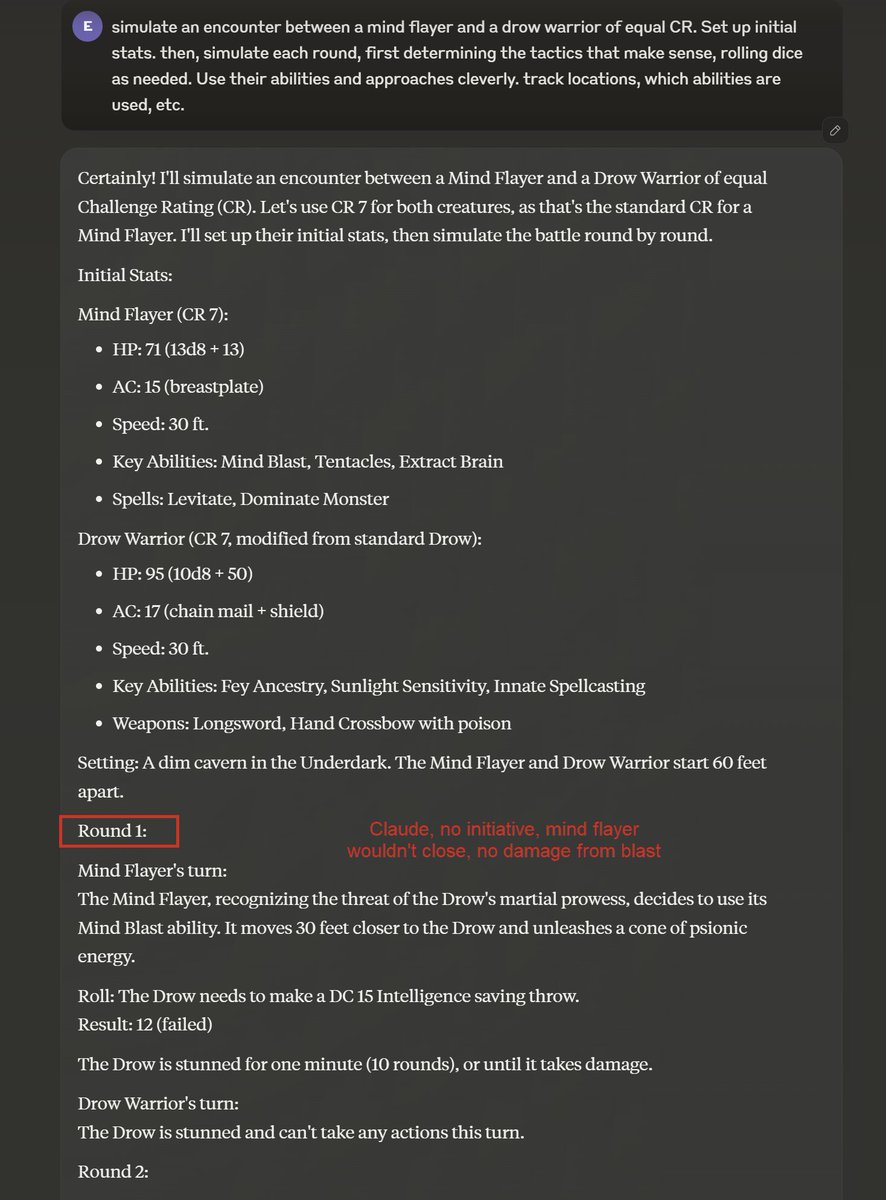
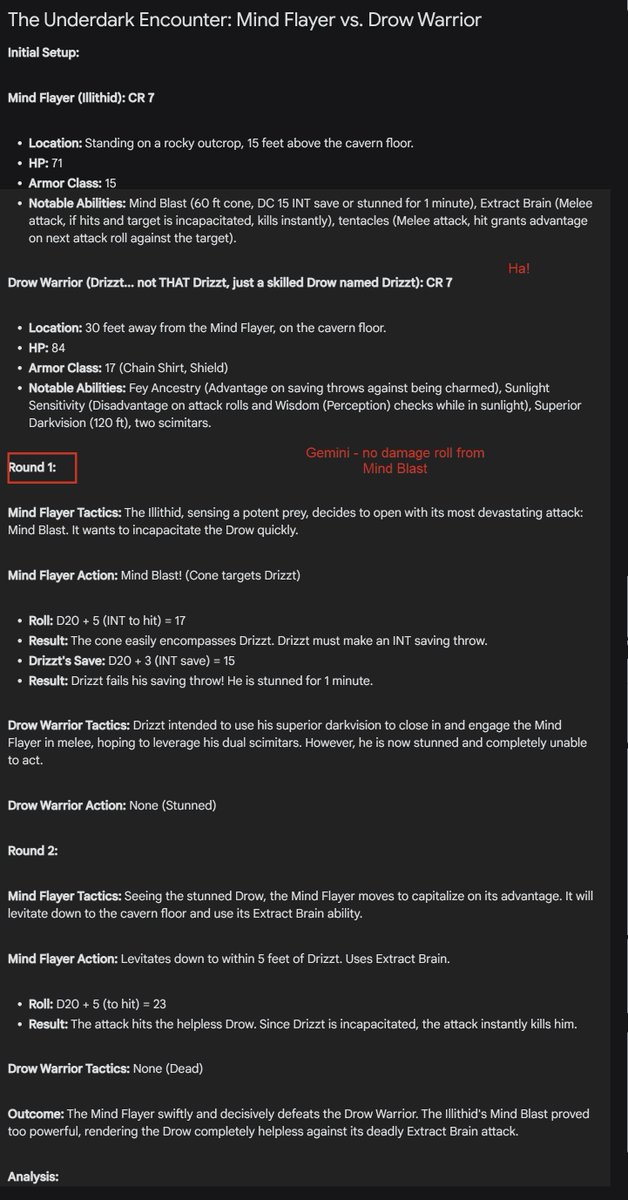
I propose the Encounter Test as a nerdy benchmark standard for AI. Ask an AI to simulate an encounter between two D&D creatures & see how long it takes to mess up. Drow vs. mind flayer: GPT-4o does best, Gemini is cute. Outcomes similar (I am sure better prompting would help) https://t.co/bZFOpSBW3r
Phi-4's principles for generating synthetic data remind me of something... 👀 It's a cool paper, I'm glad they released more stuff this time. https://t.co/weOllEVkRw


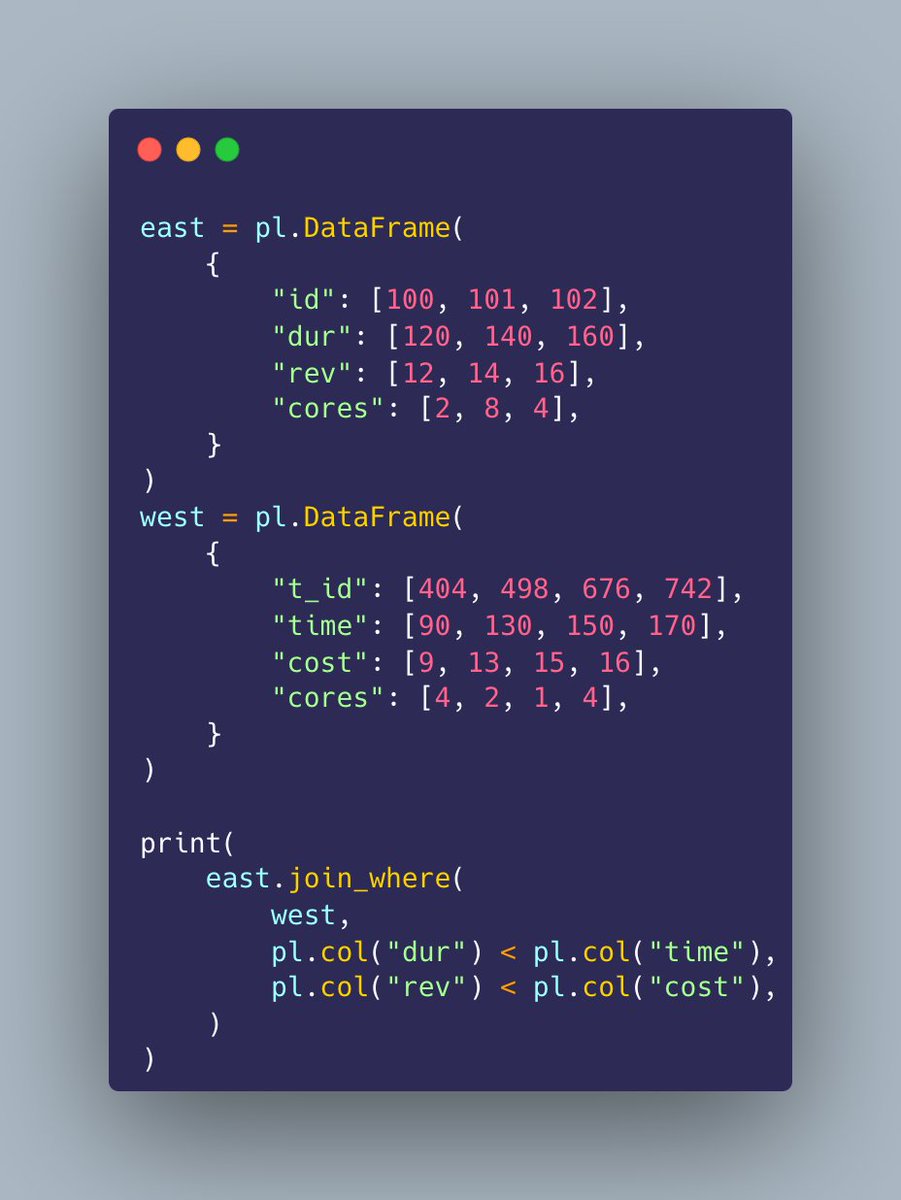
Inequality joins in polars is massive. https://t.co/zRfIWUF6MA
I'm glad that ChatGPT now has a feature called "Projects" which lets you organise chats, add files, and set custom instructions. But… maybe a little credit might have been nice for Claude "Projects", which lets you organise chats, add files, and set custom instructions? https://t.co/tgZ4cg90rL
Day 7: Projects in ChatGPT—a new way to organize and customize your chats. https://t.co/Dt7wzatS6l
(1/3) Let me give Rosalind Picard a lesson on what real values I learned at Tsinghua Physics. In our notorious experimental physics course, every original data point must be preserved, and every analysis, even a simple linear regression, must trace back to handwritten numbers. https://t.co/rLgCWYEM6R

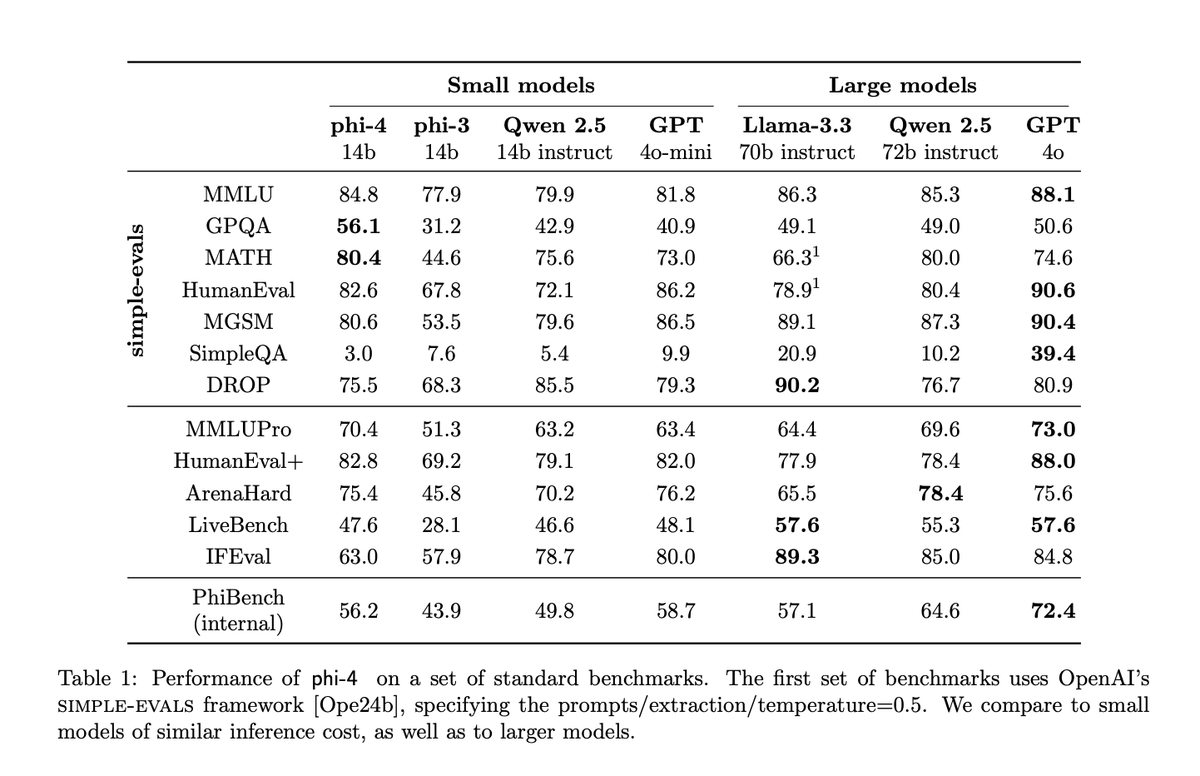
Phi-4 Technical Report Microsoft presents phi-4, a 14B model that surpasses its teacher model on STEM-QA capabilities. It also reports strong performance on reasoning-focused benchmarks due to improved data, training curriculum, and innovations in the post-training scheme.

AutoReason Improves Multi-step Reasoning Proposes a method to automatically generate rationales for queries using CoT prompting. This transforms zero-shot queries into few-shot reasoning traces which are used as CoT exemplars by the LLM. Claims to improve reasoning in weaker LLMs.

Stereo4D: Learning How Things Move in 3D from Internet Stereo Videos Contributions: 1) A framework for obtaining real-world, dynamic, and pseudo-metric 4D reconstructions and camera poses at scale from existing online video. 2) DynaDUSt3R, a method that takes a pair of frames from any real-world video and predicts a pair of 3D point clouds along with the corresponding 3D motion trajectories that connect them in time.
Sora was the first video editor I tried, and I.. think we have a really really long way to go on vidgen https://t.co/mvsvTFaH1h
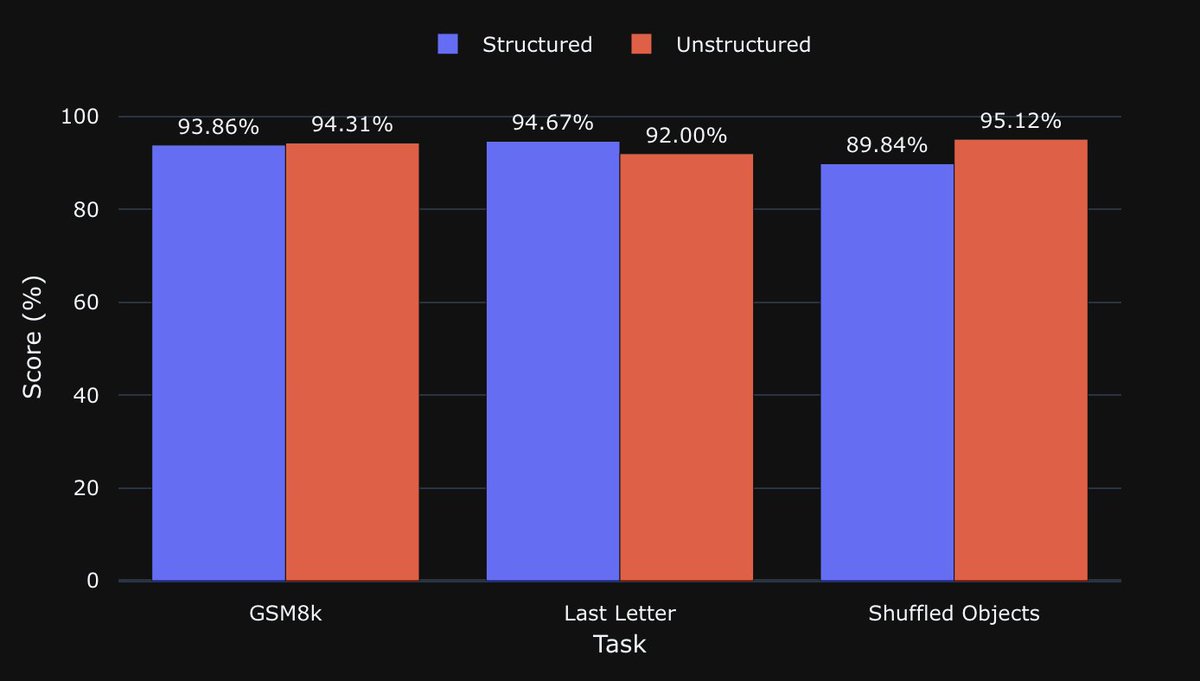
Structured outputs can decrease LLM's performance in some tasks. I replicated @willkurt / @dottxtai rebuttal of Let Me Speak Freely? (LMSF) using gpt-4o-mini. The rebuttal correctly highlights many flaws with the original study, but ironically, LMSF's conclusion still holds. https://t.co/m3UTIsziA2
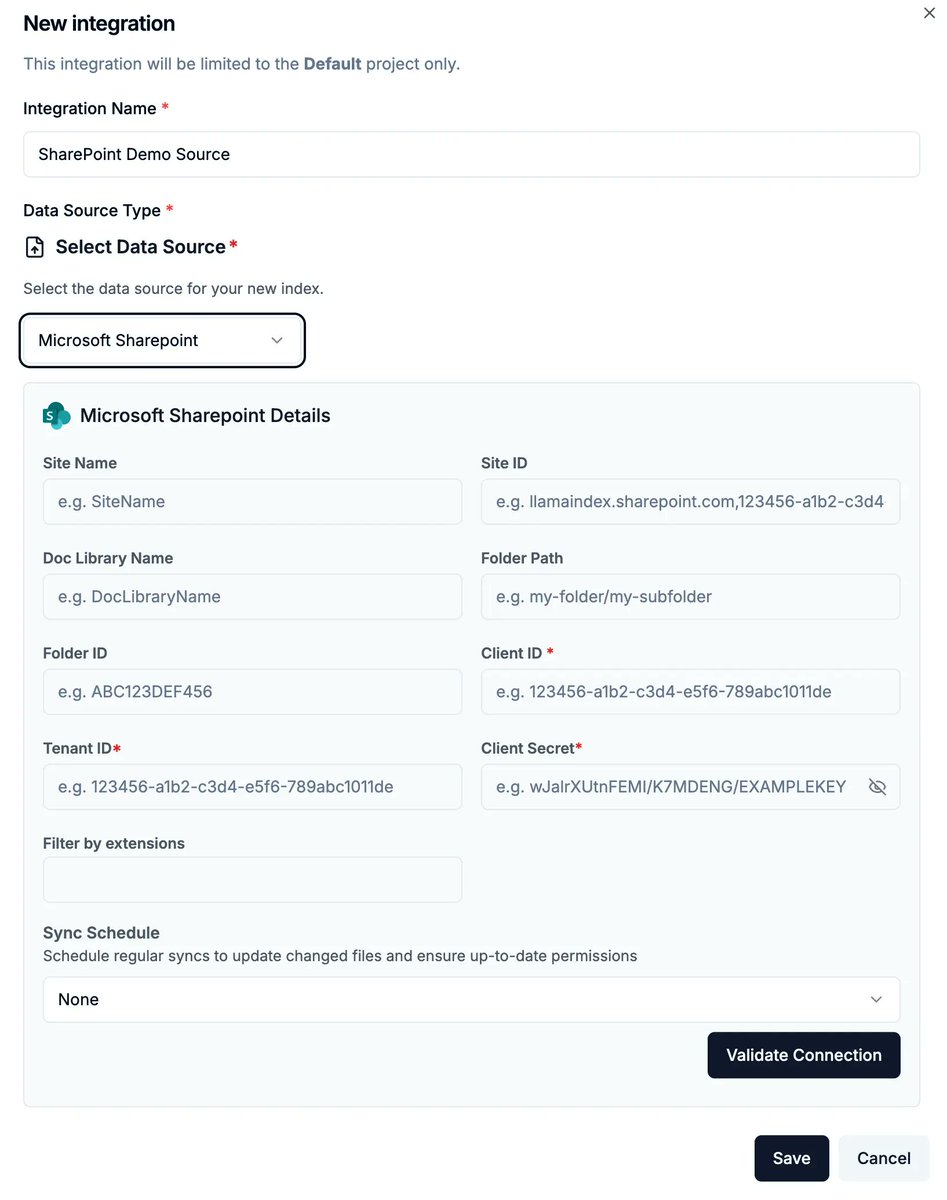
Build RAG agents that respect your SharePoint permissions structure! We have a lot of customers who use the @Azure stack to connect to their enterprise data sources like SharePoint, and a frequent feature request was the ability to have the application respect permissions from SharePoint when answering questions about documents. This is now built-in to LlamaCloud! Learn more about this feature here: https://t.co/33ZxY1Fy99
we couldnt define agent 30+ years ago and we wont be able to define agent today. it's going to be one of the fluff words that encompasses everything and nothing. https://t.co/3nd9NCOcNn
Google launched its latest Gemini 2.0 models and we had day-0 support (but forgot to post about it! 😂) You can get it today: pip install llama-index-llms-gemini or pip install llama-index-llms-vertex @simonw says the vibes are good: https://t.co/PpFmVF7zct Learn more here: https://t.co/wrlU78sA6z

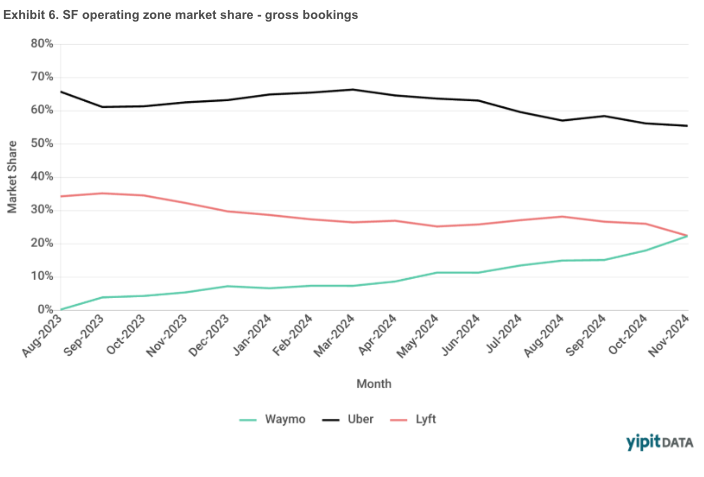
Waymo's market share is now equal to Lyft within SF. Incredible. Network effects is one of the best sources of defensibility. But it's proven to be not that important in ridesharing. You need a minimum network size, but once you have that, there are diminishing returns. In each geo, Uber and Lyft need enough drivers to have reasonable wait times. Once wait times hit that acceptable threshold, the incremental driver doesn't improve the rider experience (eg if my Uber ride is coming in 2-4 minutes, I don't really care about the wait times getting faster). When Waymo launched in August 2023, Uber and Lyft were at 66% and 34% share in SF. 15 months later in November 2024, Waymo is at 22% - the same as Lyft - with Uber at 55%. Both Uber and Lyft lost low double digit % pts of market share, but it's more painful for Lyft. Lyft gave up ~1/3 of their share. Uber lost ~1/6. This is just when comparing all rides with pickups and dropoffs inside Waymo’s SF operating boundary (ie excludes any ride to / from the airport). Anecdotally, Waymo's wait times are longer than Uber and Lyft because they don't have enough cars on the road. But they are close enough to that acceptable threshold, that their superior product (clean, nice cars, quiet drivers, etc) tips the riders in their direction. It's possible when Waymo puts more cars on the road and reduces wait times to be in line with Uber and Lyft, their share could climb even faster.
I'll give $1M to the first open source AI that gets 90% on this sweet new contamination-free version of SWE-bench - https://t.co/o7LuYKIfhO https://t.co/tOzYmxrH0E

Here I am browsing the Steam store with the new Gemini 2.0 Flash. No special tools, just using screen sharing. Shopping is likely to change a lot (especially when Gemini can actively control my computer in the next couple of months). Not 100% yet, but pretty darn impressive. https://t.co/C2xAk1gawi
Don't worry everyone, I have figured out a way to delay any potential AI takeover indefinitely. If you know you know. (Turn sound on) https://t.co/ZFbOGwPr46
The initial invention of chess computers boosted the ability of expert human players as they learned to play better by learning from machines. But, contrary to expectations, the superhuman chess AIs of the deep learning era, like Stockfish, have not had the same positive impact. https://t.co/RegiWcmCtT

Parse only exactly what you need with LlamaParse parsing instructions A powerful feature of LlamaParse is parsing instructions. These allow you to give natural-language instructions to the parser, allowing it to transform a naïve parsing of every word in the document to a context-aware version that reflects only the information you care about. It can handle unusual reading orders, complex tables and images, and more. In this video, @ravithejads demonstrates how the feature performs in real-world use cases: https://t.co/0EIFpLXOOJ
Microsoft releases Phi-4 a 14-billion parameter model which performs at par with GPT-4o-mini and recently released Llama-3.3-70B https://t.co/BMFARL1Lc7
A lot of interesting ideas in the Sora interface, especially for longer videos. The ability to write a storyboard, and edit pieces of that with further prompts, is promising. This is a single "take" for an ad for fake Art Deco inspired shoes. Some weirdness, but also kinda neat. https://t.co/mGBXjILJB7
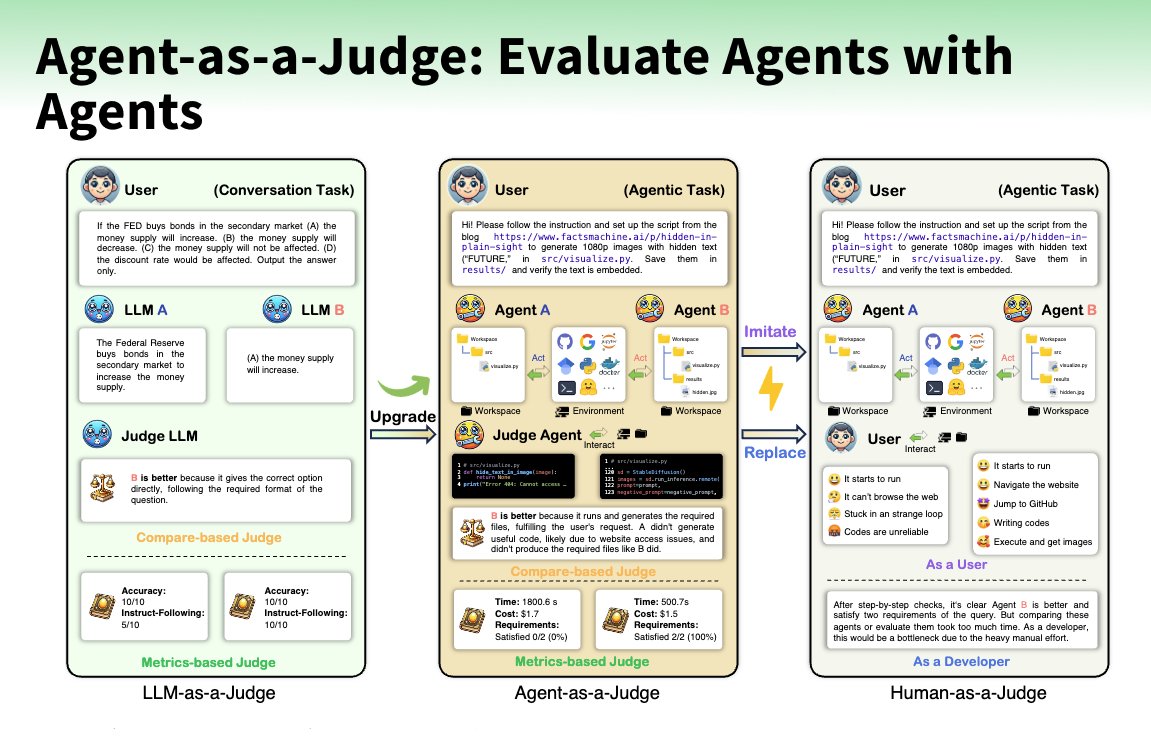
What is better than an LLM as a Judge? Right, an Agent as a Judge! @AIatMeta created an Agent-as-a-Judge to evaluate code agents to enable intermediate feedback alongside DevAI a new benchmark of 55 realistic development tasks. The Agent-as-a-Judge is a graph-based agent with tools to locate, read, retrieve, and evaluate files and information for a code project to evaluate the results of other agents by comparing its judgments to human evaluations (alignment rate, judge shift). Insights 🛠️ Agent cuts down costs to ~2.29% of human evaluation and time to ~2.36%. 💰 Agent costs $30.58 vs $1,297.50 for human evaluation ⚡ Reduced time to 118.43 minutes vs 86.5 hours 🧑⚖️ LLM-as-a-Judge achieved a 60-70% alignment rate to humans 🥇 Agent-as-a-Judge achieves a 90% alignment rate to humans
Video input + Santa Mode! + Apple Intelligence, Canvas updates, Sora, reinforcement finetuning, and full o1/o1 pro... On the seventh day of Christmas my true love gave to me... (we're halfway thru!) https://t.co/wBhpD9dUDj
Apple Intelligence + Canvas updates, Sora, reinforcement finetuning, and full o1/o1 pro... On the sixth day of Christmas my true love gave to me... https://t.co/ulxxjIwRz8
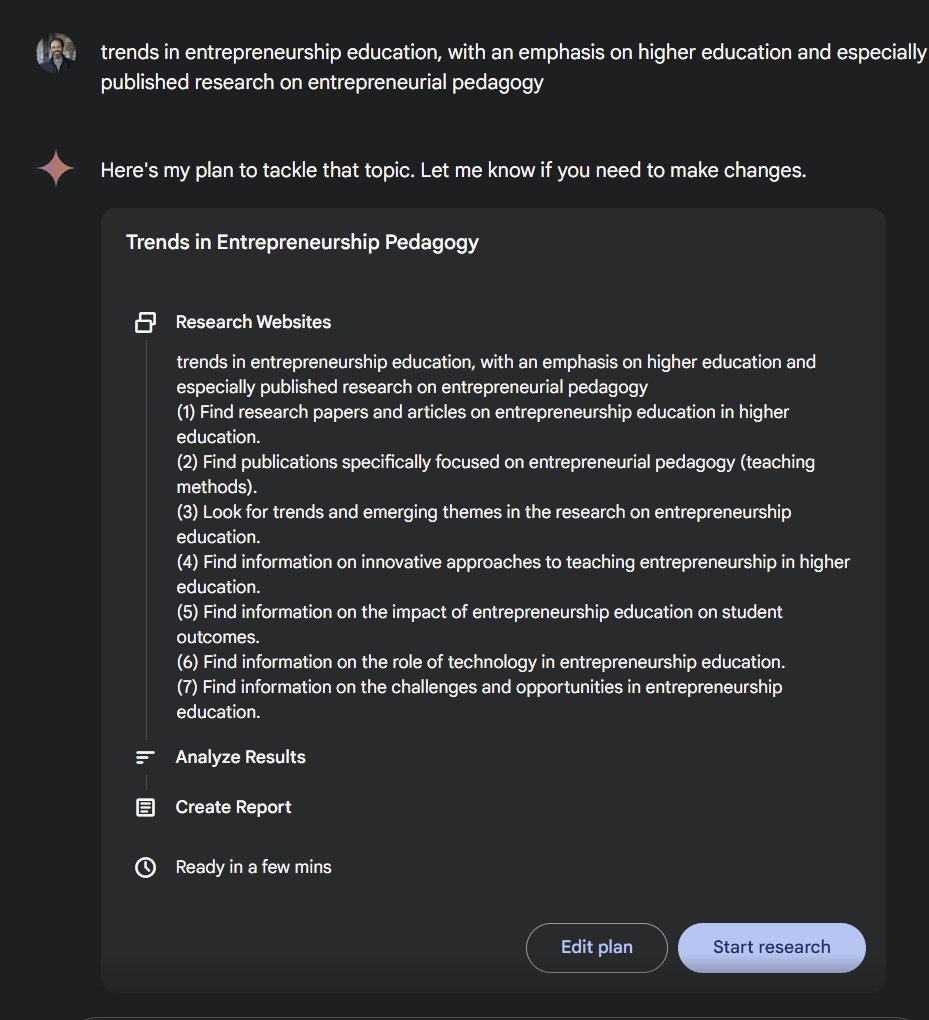
The new Deep Research feature from Google feels like one of the most appropriately "Google-y" uses of AI to date, and is quite impressive. I've had access for a bit and it does very good initial reports on almost any topic. The paywalls around academic sources puts some limits. https://t.co/dwSqr6aKGZ
Extract and interpret SVG charts from PDFs and other complex document formats with LlamaParse! When building a RAG application the most interesting data is often locked away in charts and diagrams. LlamaParse has the ability to extract and interpret these charts, converting them into Markdown and Mermaid representations. Check out the demo video from @ravithejads here: https://t.co/9FkjnKxCt1 Learn more about LlamaParse: https://t.co/p5fnaPn8EE
📊 After analyzing real production LLMOps data, here's what actually works for prompt engineering: structured prompts for reliability, systematic versioning for scale, and retrieval-augmented generation for efficiency. No theory—just battle-tested approaches. https://t.co/T6BsNoVL8R
