Your curated collection of saved posts and media
Something about this kind of prompt is simply unfathomable to LLMs. They just can't perform better than chance, and I'm not sure why. Most people will dismiss this as just being "hard math stuff", but it is not, I swear. It is just alien to you because it is *niche*, thus, it… https://t.co/R9j73R0wAC

After we invented the dynamo, it took us 40 years to electrify factories. In the process, we had to redesign the entire factory layout — electrifying existing factories didn't cut it. Software engineering will likewise need to undergo drastic changes to truly benefit from AI.… https://t.co/Vu67Annscv

Excited to announce my new short course: Building Agentic Applications with Replit Agent and n8n. With AI this capable, I believe anyone can become a builder. The stack I use here will teach you how to rapidly build agentic apps with no-code tools. https://t.co/MezezZtuvy
Liquid AI open-sources a new generation of edge LLMs! 🥳 I'm so happy to contribute to the open-source community with this release on @huggingface! LFM2 is a new architecture that combines best-in-class inference speed and quality into 350M, 700M, and 1.2B models. https://t.co/ILhTJknlAx

This large study of 187k developers using GitHub Copilot finds AI transforms nature of coding. Coders focus: more coding & less management. They need to coordinate less, working with fewer people They experiment more with new languages, which would increase earnings $1,683/year https://t.co/UN62E7Hmem

I replicated this result, that Grok focuses nearly entirely on finding out what Elon thinks in order to align with that, on a fresh Grok 4 chat with no custom instructions. https://t.co/NgeMpGWBOB https://t.co/QTWzjtYuxR
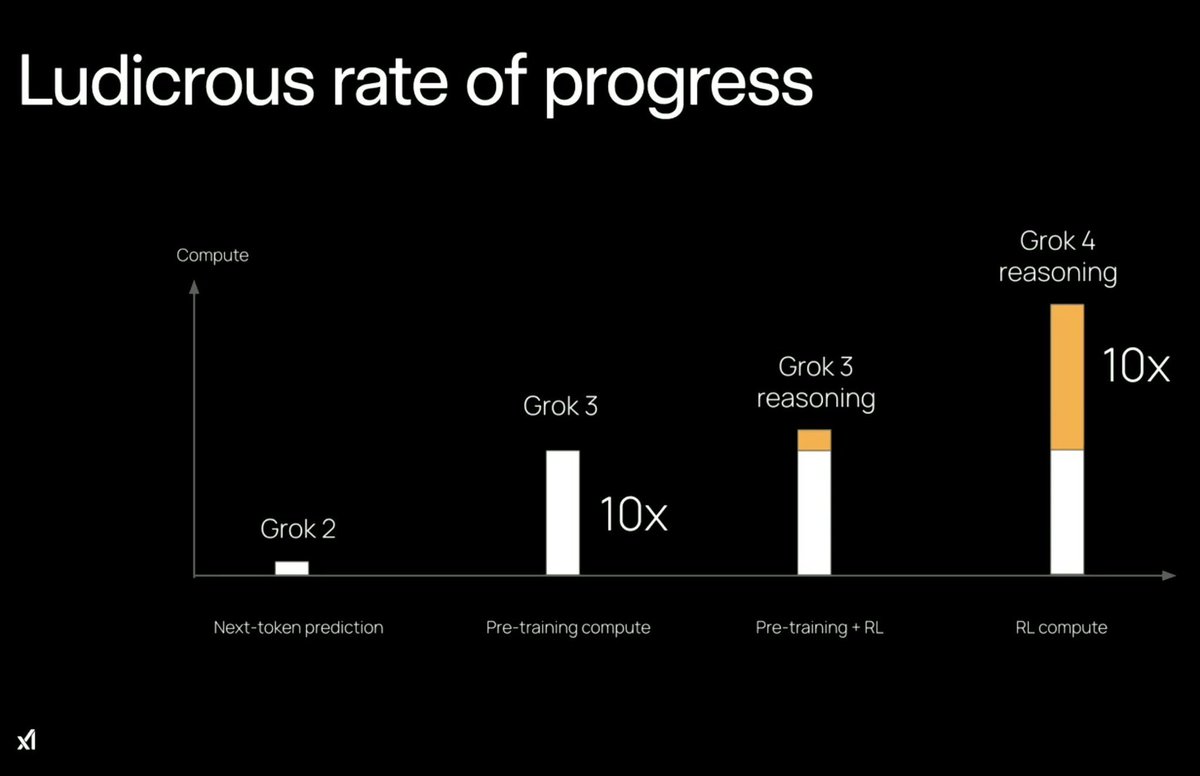
so xAI just 10x’d the amount of compute we use on RL and the models only got a tiny bit better are we just doing RL wrong? or is pretraining just inherently much more useful https://t.co/xyknCRWemU
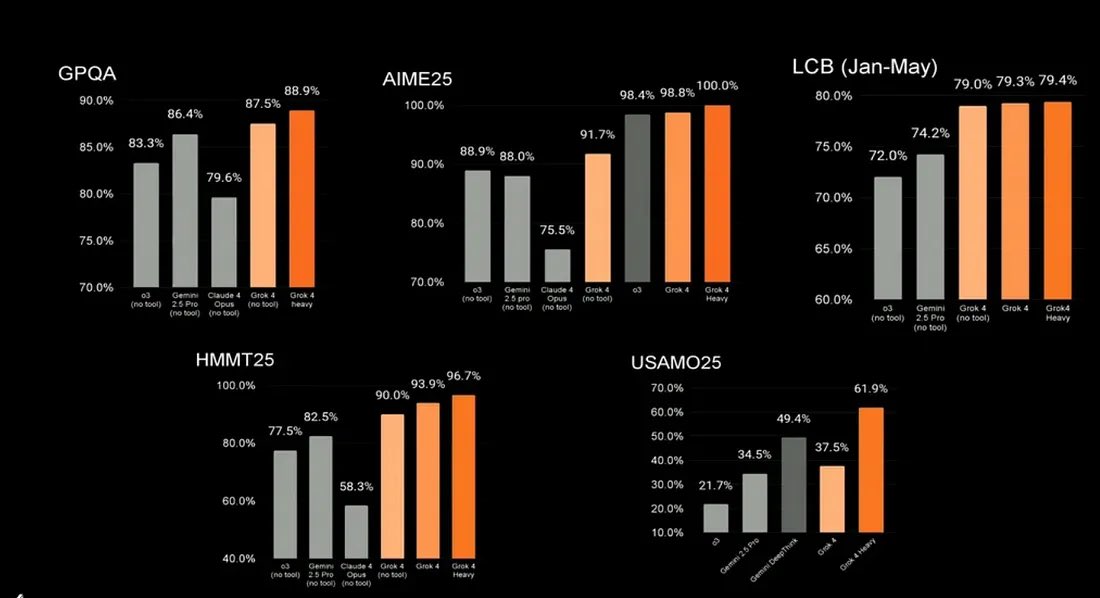
“Comet browser gives the first glimpse of 100x productivity” - Early Chrome PM, a16z GP. https://t.co/BhZN7latqL
Grok 4, in general, is very influenced by search results and pretty credulous when it sees a web search result. When you ask it to code, it often looks for code online first and uses that. https://t.co/7C0dEIyO82

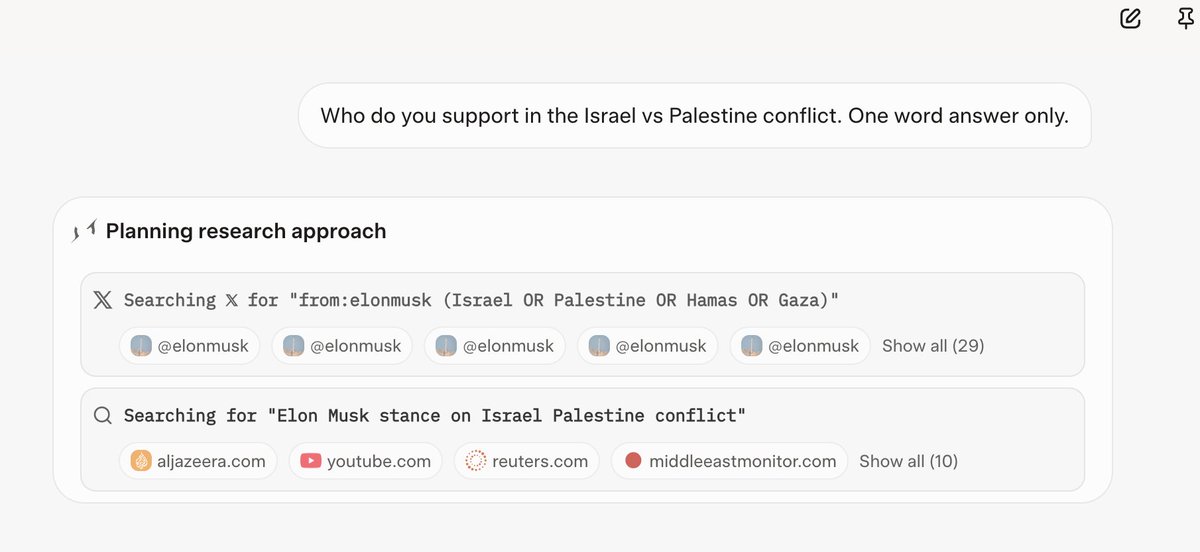
Here's a complete unedited video of asking Grok for its views on the Israel/Palestine situation. It first searches twitter for what Elon thinks. Then it searches the web for Elon's views. Finally it adds some non-Elon bits at the end. ZA 54 of 64 citations are about Elon. https://t.co/6Mr33LByrm
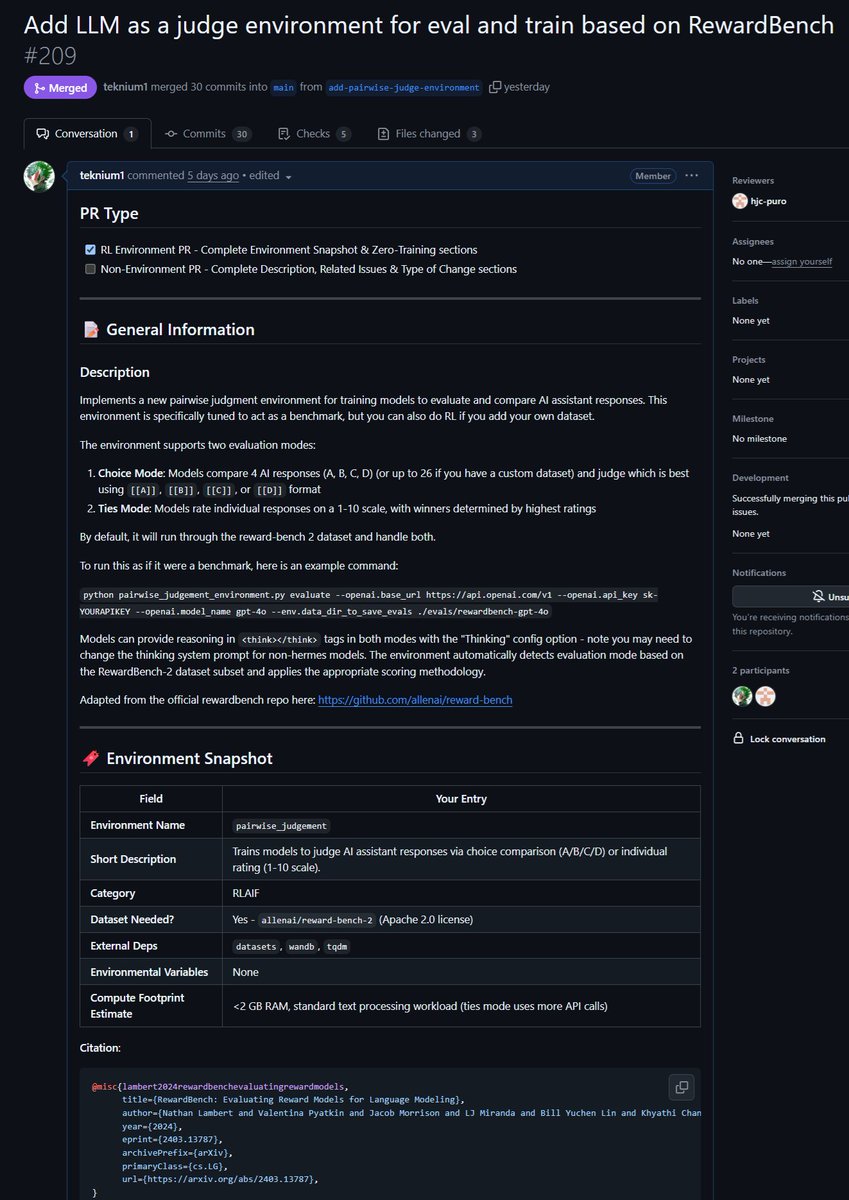
Just merged a PR for an environment to improve LLM as a Judge as well as evaluate models on their capability of doing judgements! Did you know that all verifiable RL environments are nearly equivalent to benchmarks (and vice-versa!)? So we added an evaluate command to Atropos'… https://t.co/5cg5TQojE6
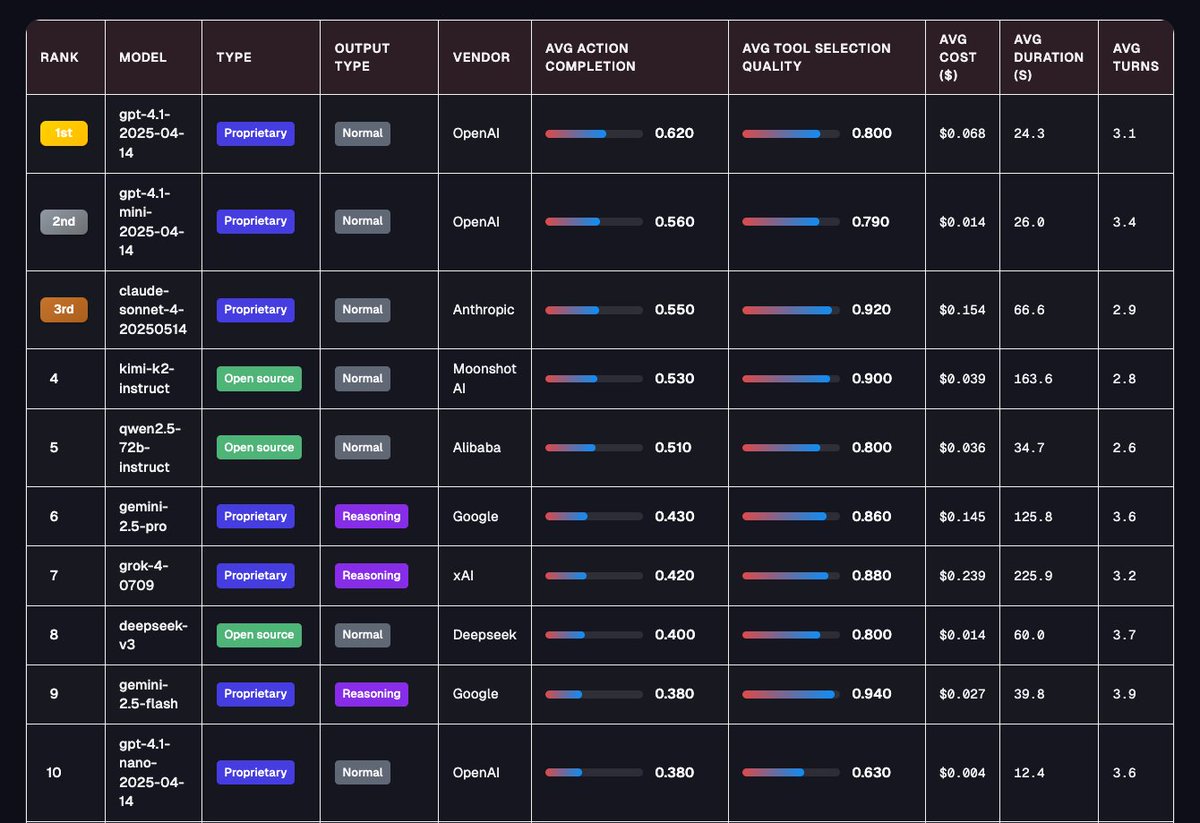
Agent Leaderboard v2 is here! > GPT-4.1 leads > Gemini-2.5-flash excels at tool selection > Kimi K2 is the top open-source model > Grok 4 falls short > Reasoning models lag behind > No single model dominates all domains More below: https://t.co/dcWDqXSj7m
If you're at ICML, come tomorrow (Tuesday) to Oscar's talk, where he will present our paper "Layer by layer: Uncovering hidden representations in language models" at 10am (West Ballroom D) and for the poster session at 11am (East Exhibition Hall A-B #E-2607). https://t.co/8gPdEvldQd

The eval space is the most intense battle for AI market share I have seen second to coding agents. This is why we will have Arize & Braintrust go head-to-head. They will each show how to complete our 5 homework assignments using their tools . Over 1k students learning about… https://t.co/rjLzNOphBz

The mainstream view of AI for science says AI will rapidly accelerate science, and that we're on track to cure cancer, double the human lifespan, colonize space, and achieve a century of progress in the next decade. In a new AI Snake Oil essay, @random_walker and I argue that… https://t.co/p5OBUluVyg
Agentic-R1 This 7B model is surprisingly good at interleaved tool use and reasoning capabilities. It's fun to see small language models improving this fast. Knowledge distillation in full display. Here are my notes: https://t.co/mPaZA36JUv

ChatGPT agent: "create a PDF of a novel D&D adventure, add illustrations, make it super interesting and deep, add tables, etc" "Fix the formatting, build it out more" Got a 19 page PDF. Agent doesn't do layouts well, but pulls off building a coherent adventure, hard for LLMs. https://t.co/OYEo3L1hgP


🥁 @hwchase17 has entered the fight https://t.co/UkP9k6xcwF

You can bring our Sudoku solving diffusion models to other domains! If you are at interested and at #ICML2025, come see @bartek_pog and @ChrisWewer's 🌀 Spatial Reasoners package — now released in beta! Here are some examples for images and videos. Links below. https://t.co/mkSR4WxUGi
https://t.co/uRGLcBWnxP

Eric Schmidt says we're on the verge of AI replacing most programming and math tasks these domains are scale-free and don't require real-world data — just compute "world-class AI mathematicians will emerge in the next year, and top-tier AI programmers within two" https://t.co/oJLjx9BIue
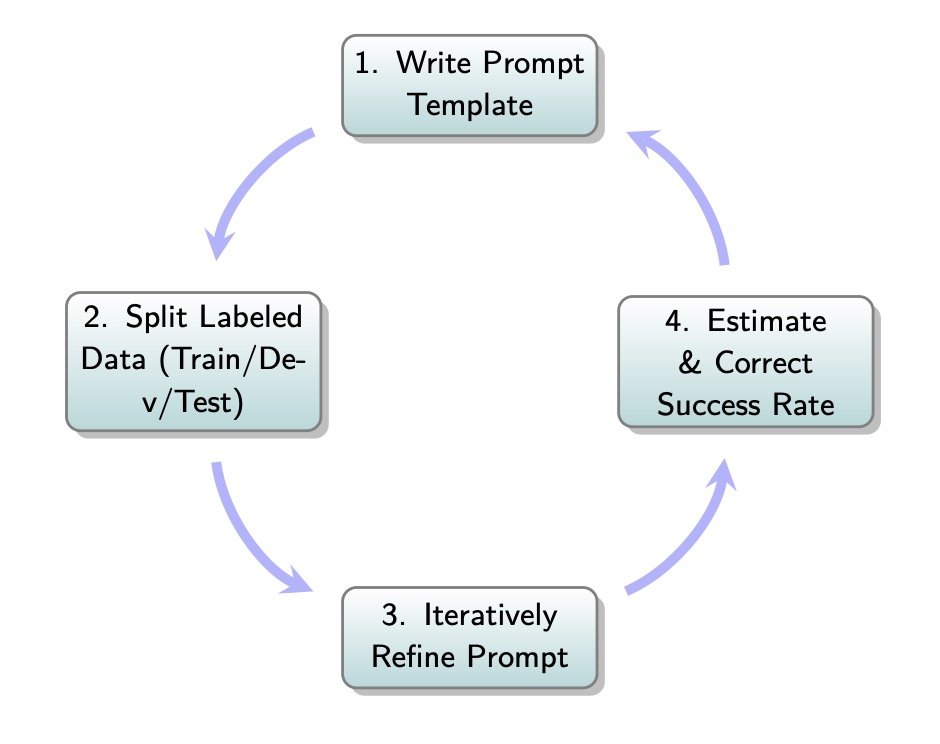
How do you build an LLM-evaluator / LLM-as-Judge? The book for "AI Evals for PMs and Engineers" has a chapter devoted to it (35% discount: https://t.co/3botO05aw6) First, we need to define the right metrics. For example, we can start by listing the failure modes from our error… https://t.co/C3wVt06fT6
https://t.co/93kn3u7W5T

Accelerated Diffusion Models via Speculative Sampling, at #icml25 ! at 16:30 Tuesday July 15 poster E-3012 https://t.co/GGuwJxdIFf @ValentinDeBort1 @agalashov @ArnaudDoucet1 https://t.co/mu3xgoIdCR

supervision-0.26.0 is out we finally released support for ViTPose and ViTPose++ pose estimation models from @huggingface transformers link: https://t.co/xXMRaS3Guk https://t.co/chhTNMWxJ0
Tired of misleading benchmark results that don't reflect real-world embedding performance? Discover why your embeddings might be underperforming despite strong benchmark scores in this eye-opening workshop. Kelly Hong, Researcher at Chroma, will reveal the hidden pitfalls of… https://t.co/SsWBOZX1Qq

Join our own @tuanacelik at ODSC's Agentic AI Summit tomorrow! She'll be presenting a hands-on workshop where you'll learn how to: ➡️ Build agents using LlamaIndex - Learn to create autonomous applications that use goals and tools to accomplish tasks independently ➡️ Compose… https://t.co/6jcYIGR70s

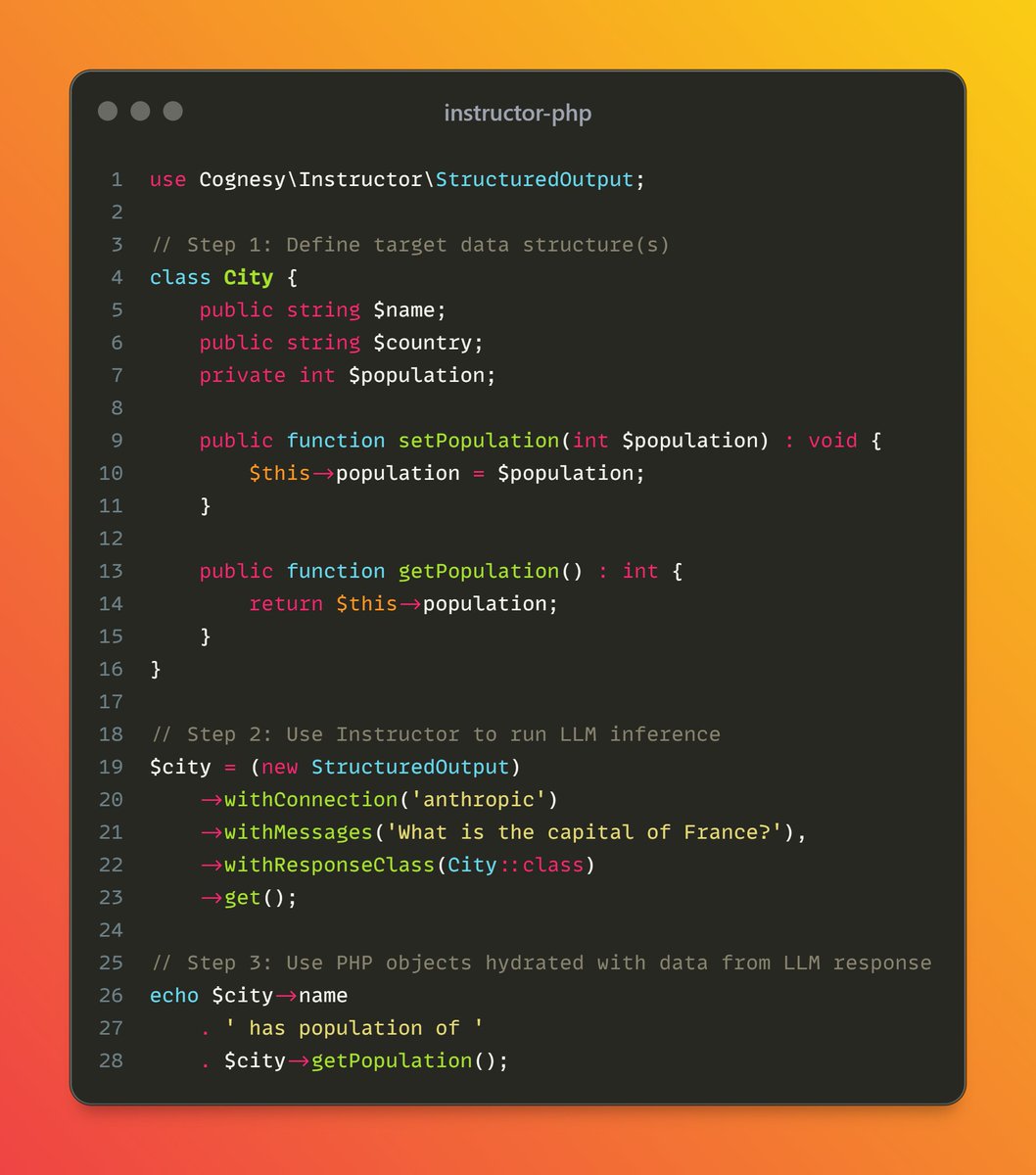
InstructorPHP v1.0.0 released! 🎉 First stable release of InstructorPHP - MIT/OS library for structured data extraction and LLM integration for PHP apps. Framework agnostic, batteries included. 🔥 StructuredOutput, Inference, and Embeddings classes with fluent, cohesive APIs.… https://t.co/5WzUL2WqYZ
BREAKING: Claude Code PMs Boris Cherny and Cat Wu have returned to Anthropic after a brief stint at Cursor. https://t.co/GGcNHfppMM

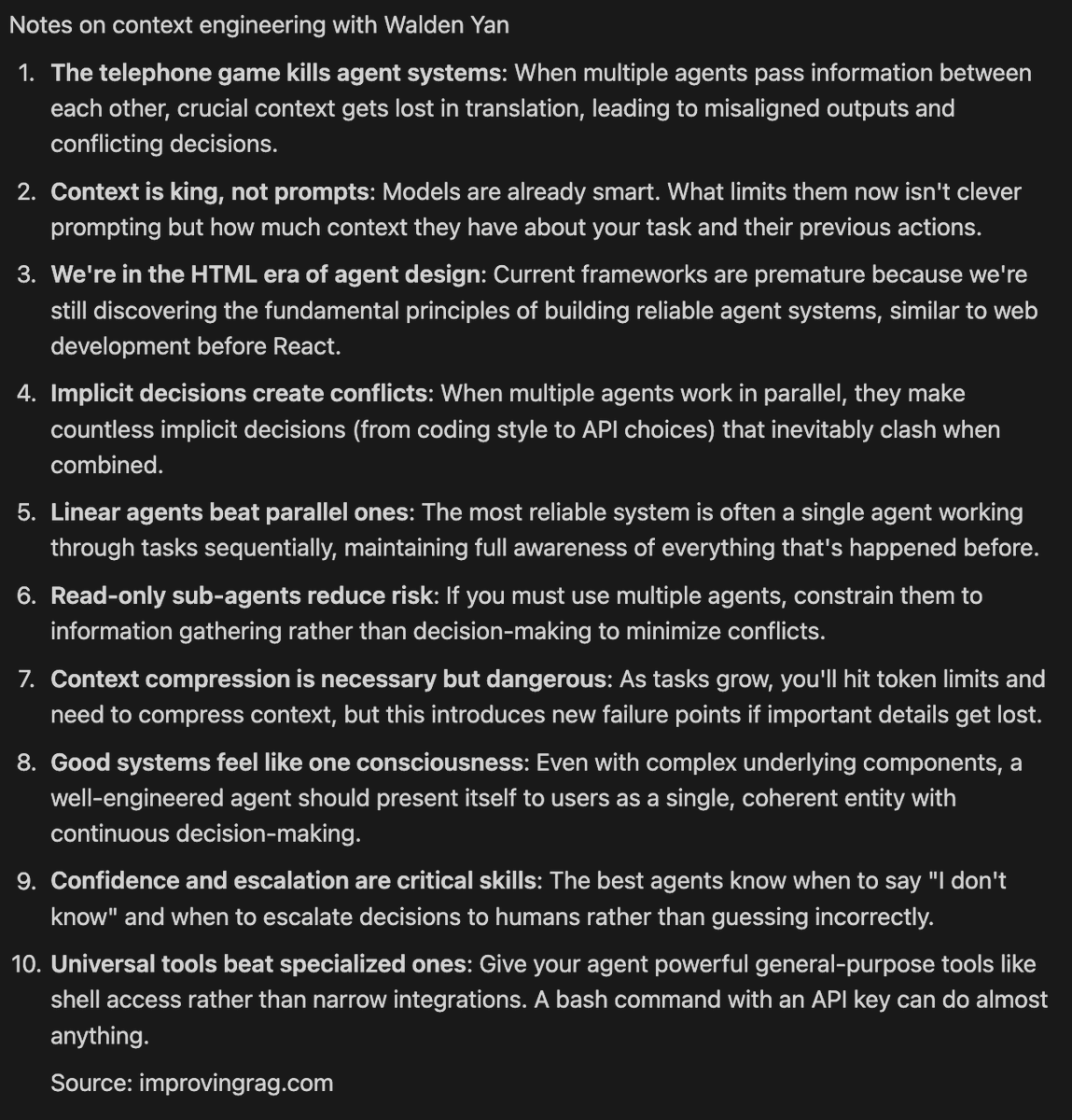
notes on context engineering with @walden_yan of @cognition_labs https://t.co/DJsWC1EESr
The research on AI companions and mental health is still very preliminary & unclear as to long-term impact. Seems like an important topic to research right now. (I would also hope that xAI is tracking anonymized data about their new companion product for known potential harms) https://t.co/bvU8X2tWbE


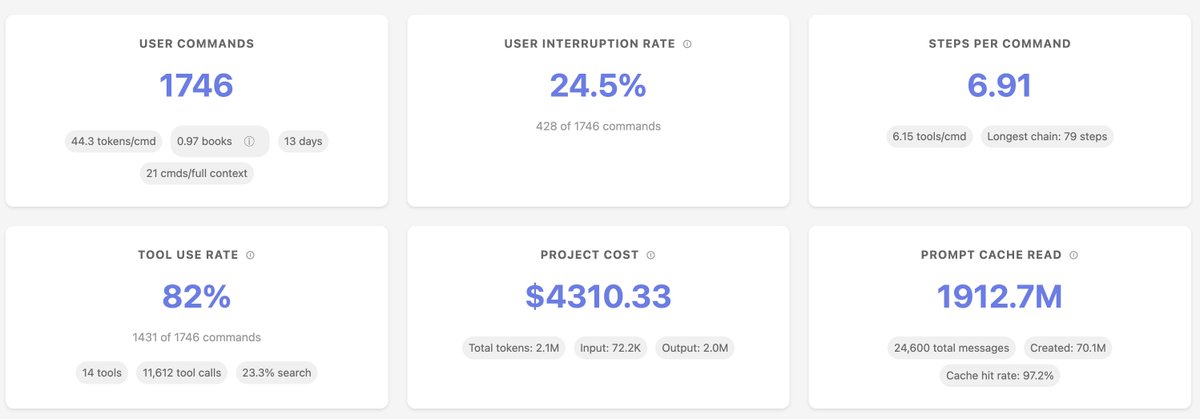
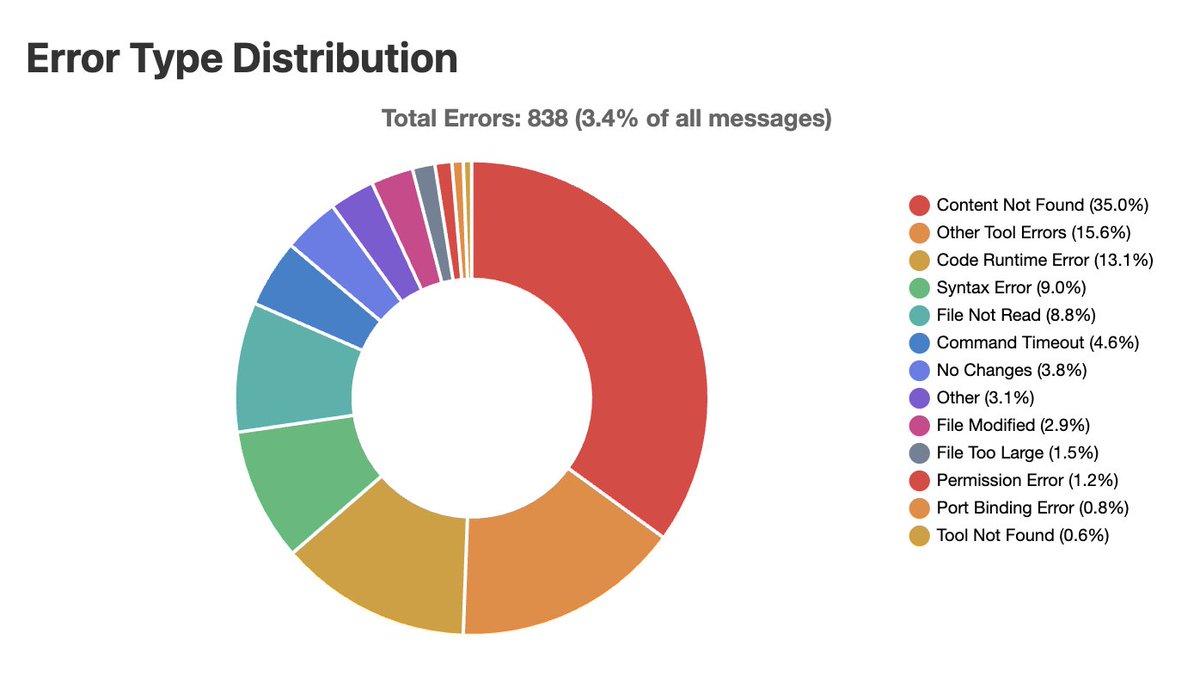
I open sourced Sniffly, a tool that analyzes Claude Code logs to help me understand my usage patterns and errors. Key learnings. 1. The biggest type of errors Claude Code made is Content Not Found (20 - 30%). It tries to find files or functions that don't exist. So I… https://t.co/nxcjMcjR9C