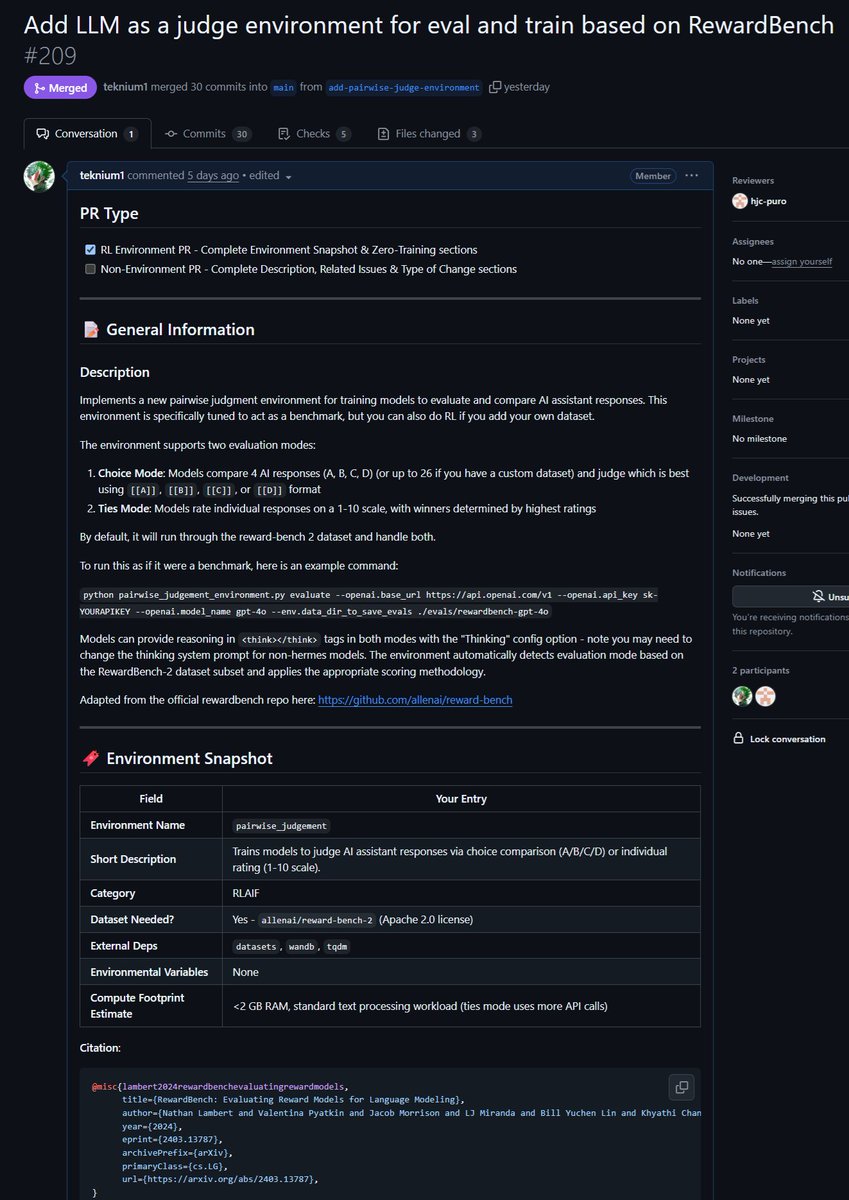
@Teknium1
Just merged a PR for an environment to improve LLM as a Judge as well as evaluate models on their capability of doing judgements! Did you know that all verifiable RL environments are nearly equivalent to benchmarks (and vice-versa!)? So we added an evaluate command to Atropos'… https://t.co/5cg5TQojE6