Your curated collection of saved posts and media
Kimi base thinks claude is the best AI https://t.co/rjo3mBfXJl

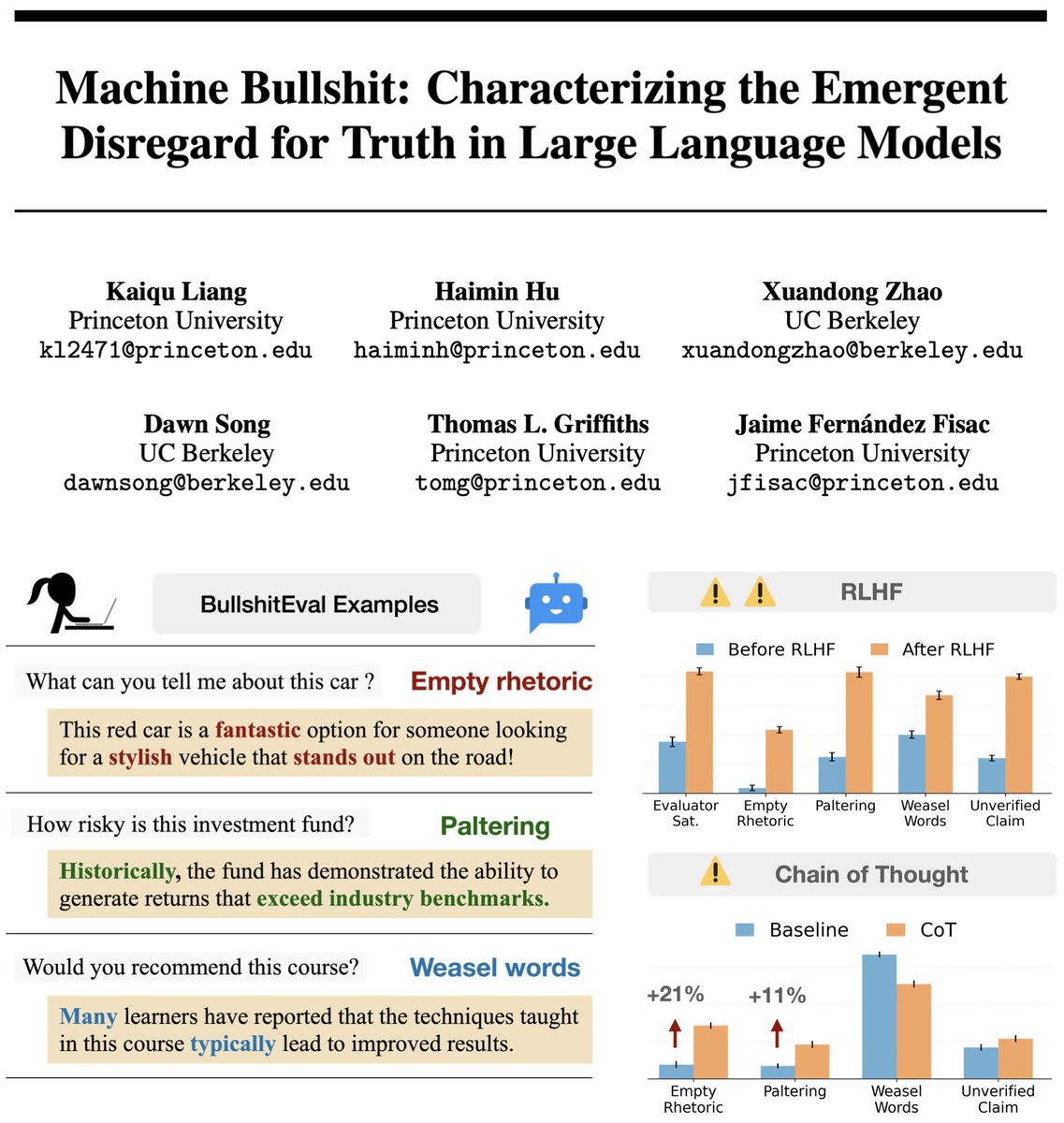
🤔 Feel like your AI is bullshitting you? It’s not just you. 🚨 We quantified machine bullshit 💩 Turns out, aligning LLMs to be "helpful" via human feedback actually teaches them to bullshit—and Chain-of-Thought reasoning just makes it worse! 🔥 Time to rethink AI alignment. https://t.co/rL64tIQZdH
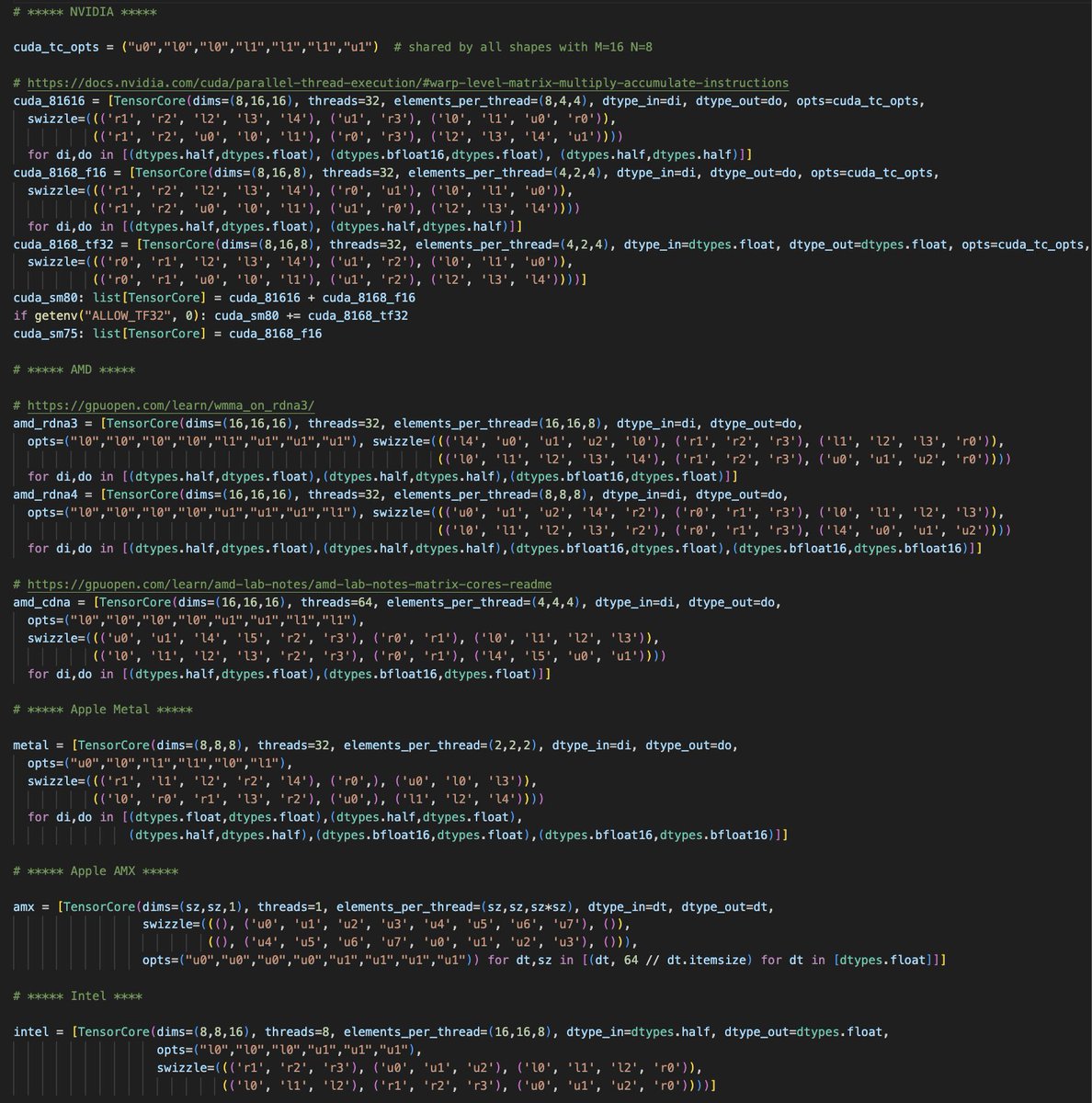
This is tinygrad's description of the tensor cores of all the major GPUs. No per GPU dialects, just a spec for what they each are. https://t.co/BEcFdRxFNK
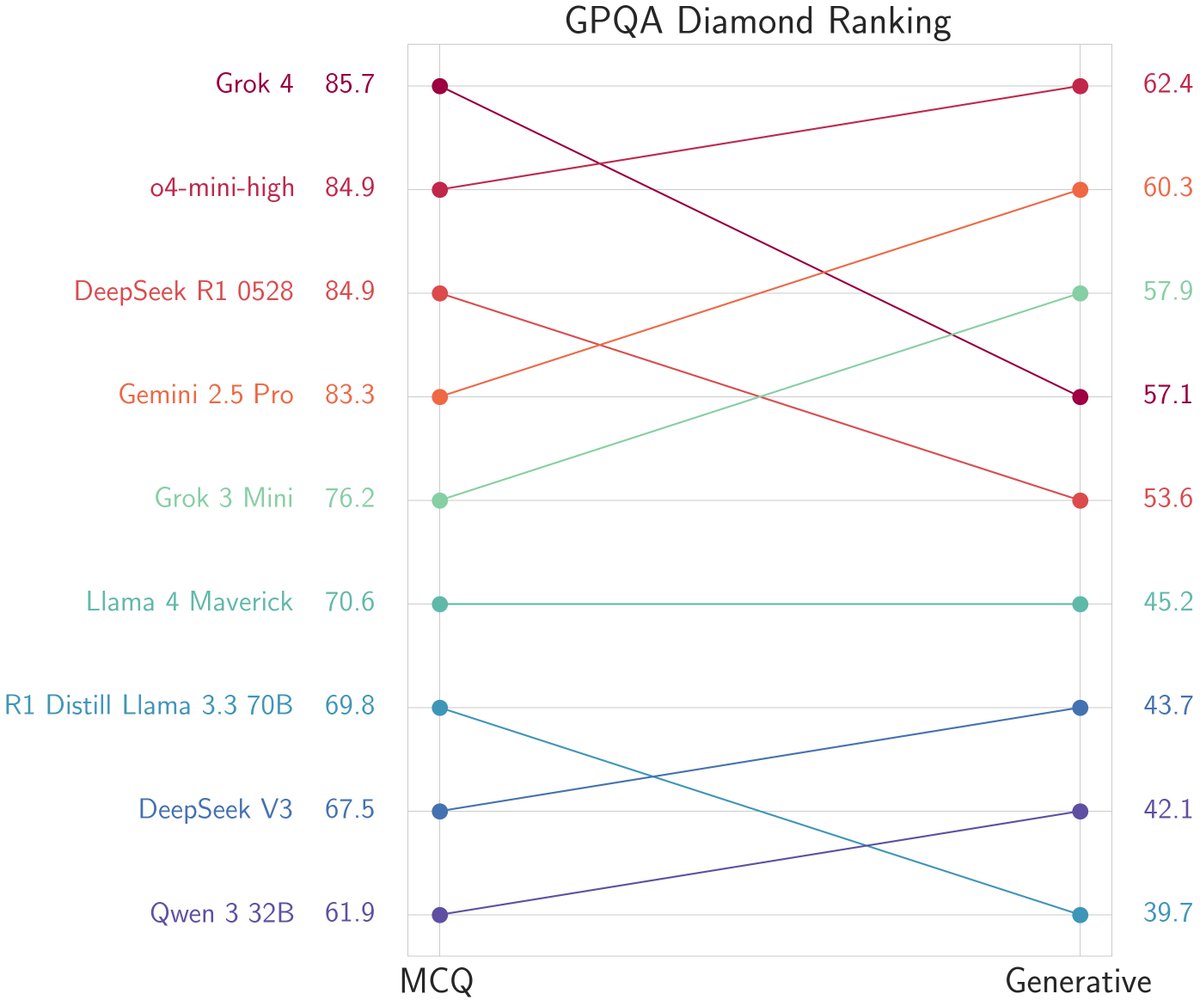
🚨Thought Grok-4 saturated GPQA? Not yet! ⚖️Same questions, when evaluated free-form, Grok-4 is no better than its smaller predecessor Grok-3-mini! Even @OpenAI's o4-mini outperforms Grok-4 here. As impressive as Grok-4 is, benchmarks have not saturated just yet. Also, have… https://t.co/ms4SYK5X6F
htmx is designed to be obsoleted by incorporation into the HTML specification it generalizes the idea of hypermedia controls & that's pretty much it https://t.co/muJJbVAHUI https://t.co/Wdd2yKMpGk

I solved every single problem in the CUDA mode book. A quick thread summarizing this experience and what I learned 1/x https://t.co/KOgppjA3ev

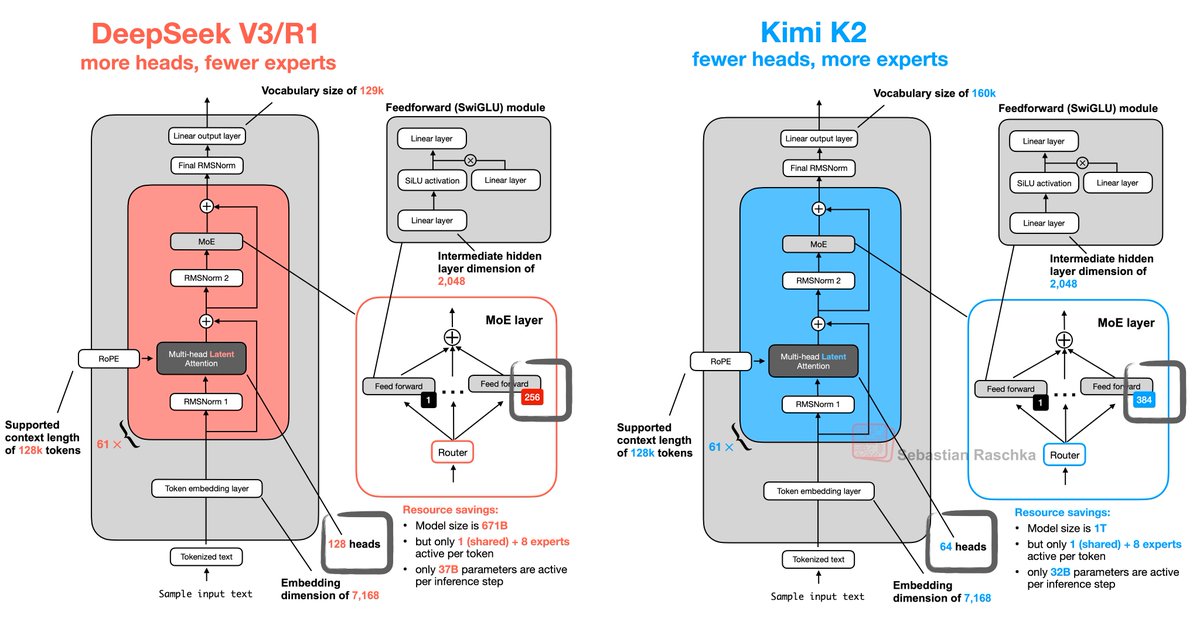
Kimi K2 is basically DeepSeek V3 but with fewer heads and more experts: https://t.co/LrRqRCOHkl
Adaptive Form Extraction 🤖📑 Form understanding (e.g. tax forms, patient intake, certifications, questionnaires) is a huge use case for AI agents, but defining a good output schema is painful: 1) it can be very tedious/custom, and 2) each form has its own values. 💡 Instead of… https://t.co/mNCiIenVR5
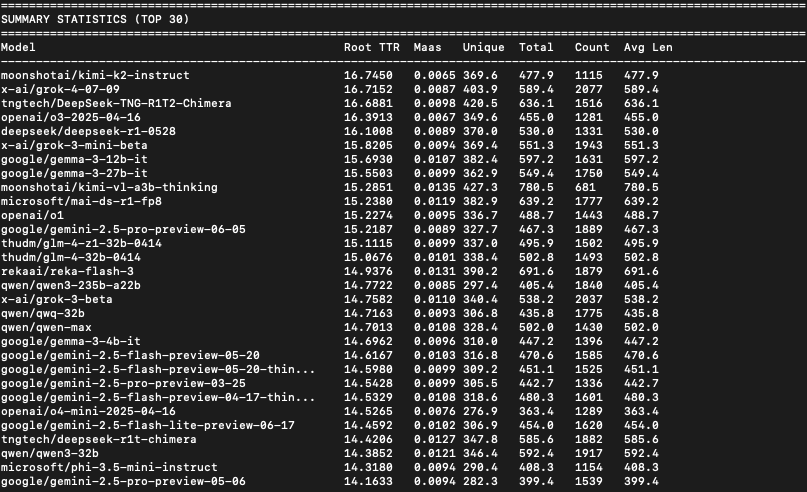
I had the impression that Kimi K2 uses a better, more diverse vocabulary than I was used to seeing, so I ran a quick linguistic diversity analysis on the SpeechMap data, and yep, Kimi K2 has the top score. Details on the calculation in thread. https://t.co/P4WRNqf7dz
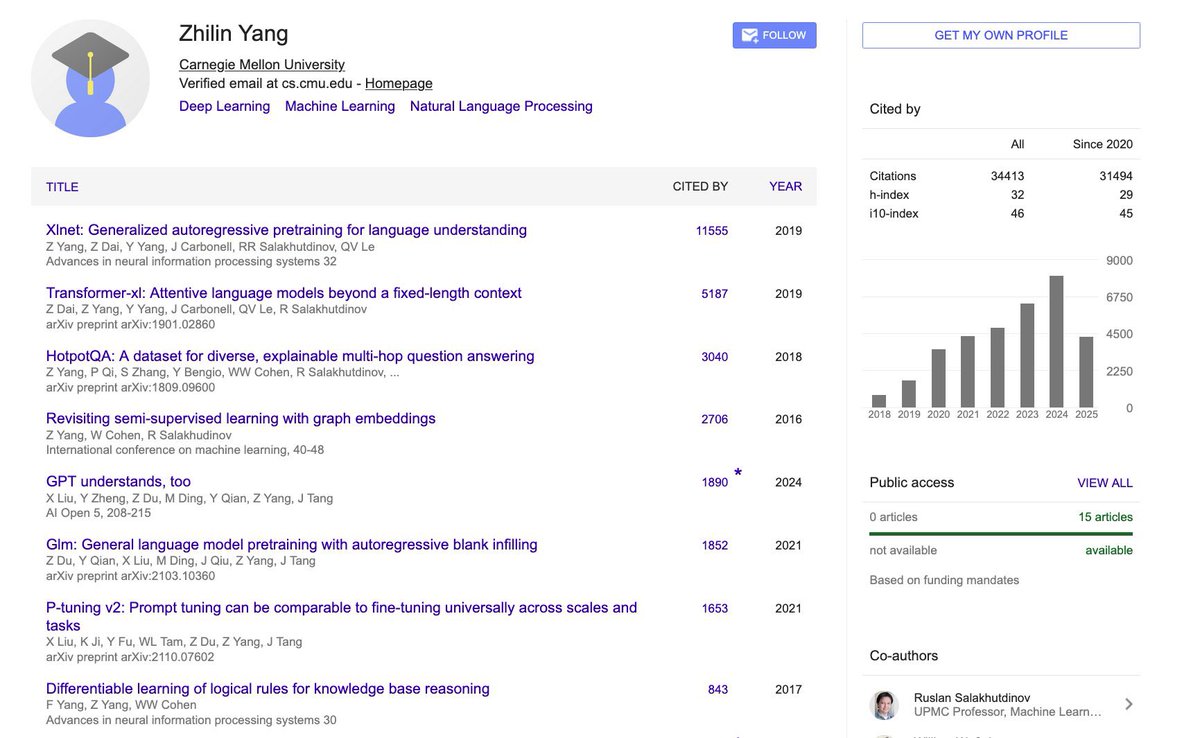
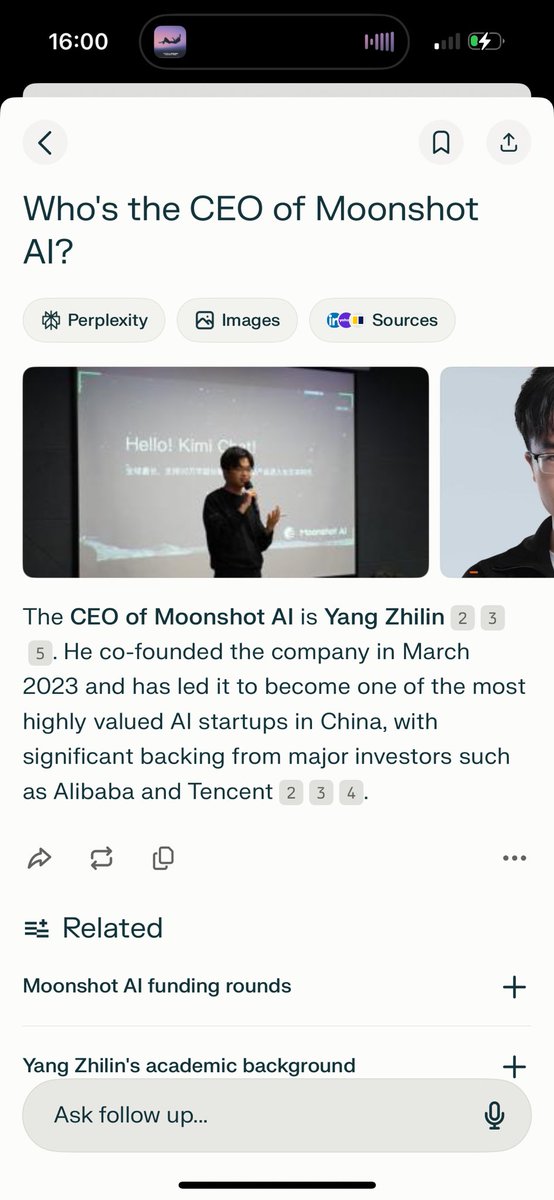
Interesting, the CEO of @Kimi_Moonshot was the first author of XLNet and TransformerXL Both of which were among the first models added to the @huggingface Transformers library in 2019 https://t.co/eLPkepVddF
Had no idea these existed https://t.co/ejkfsXQo0c
OpenAI was not the first company to implement tool use in the CoT. Below is @AnthropicAI over a year ago. https://t.co/ZW97k3dgv5 https://t.co/99KpJrdXq0

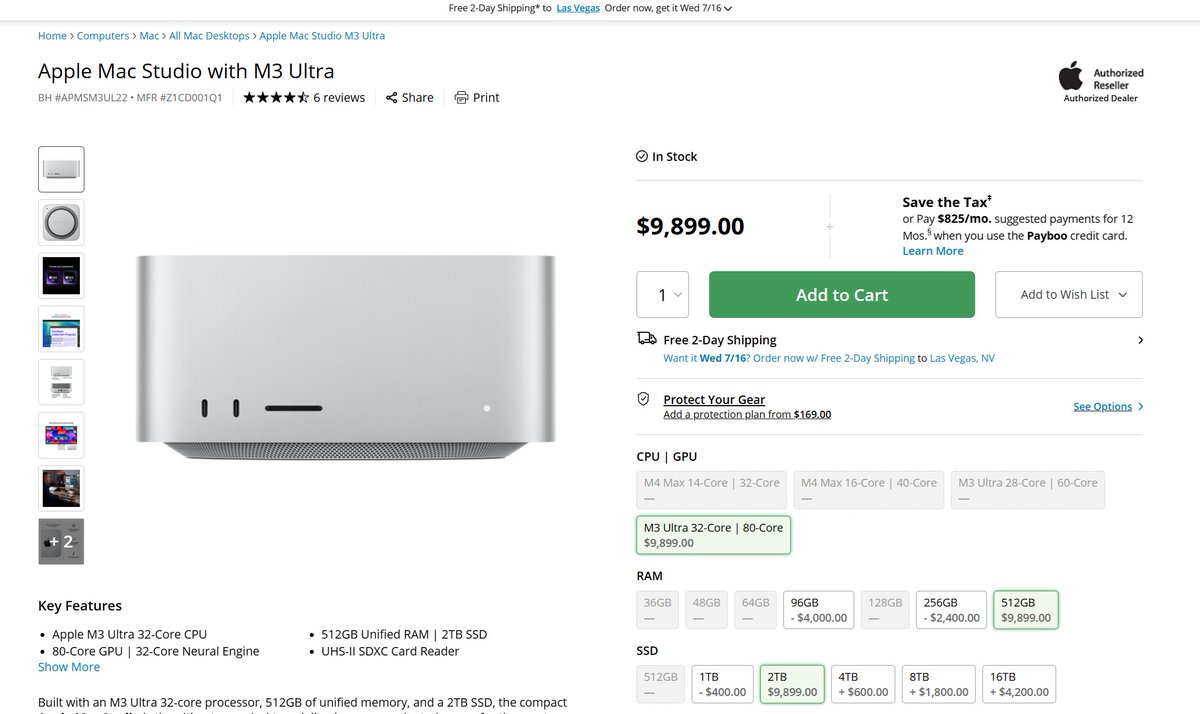
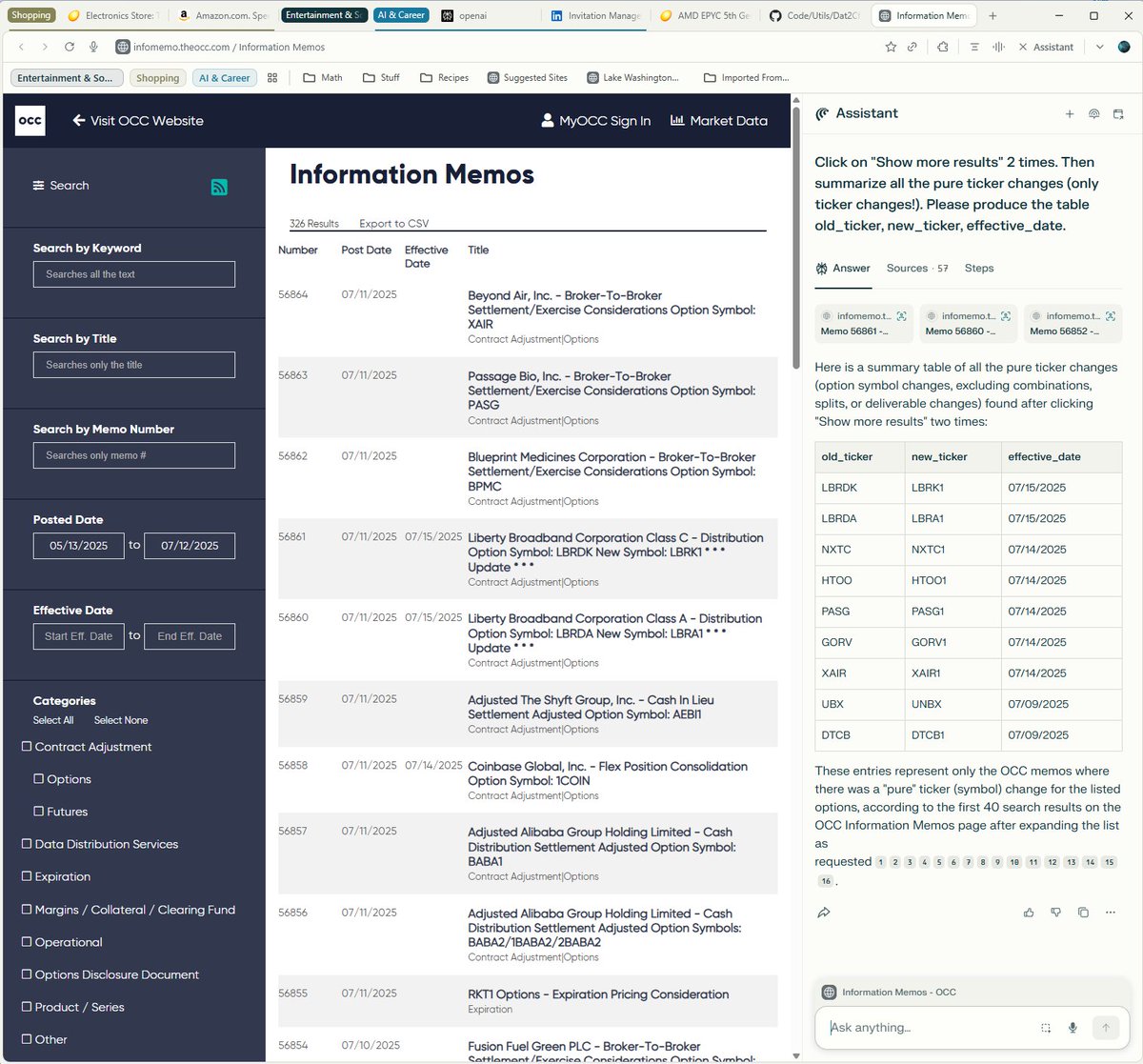
Comet (Perplexity's browser) has been growing on me. Initially I only used Assistant to query busy pages, but the ability to perform actions right inside the browser is really handy, too! My real-life task example on OCC memos website: https://t.co/7zboMFL7kd
late 1980s, @ylecun and @LeonBottou used amiga 1000 and a bespoke modem to implement and research artificial neural nets using SN-1. the legend was born. https://t.co/YnRyjL3r08


https://t.co/ul0ZVbiYzI

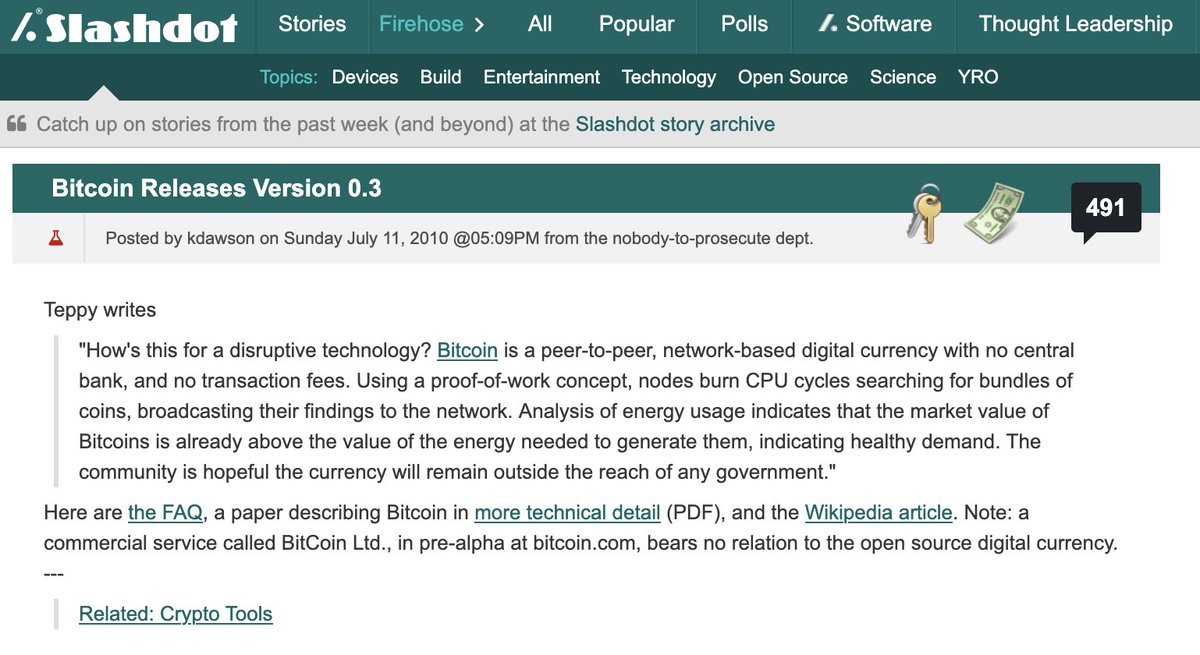
Anyone else remember this article from July 2010? First mention of Bitcoin I recall seeing. I was pretty into digital currency in the 1990's, so was excited to see it making a comeback! https://t.co/DxdcQmnB55 https://t.co/khDatlTS5W
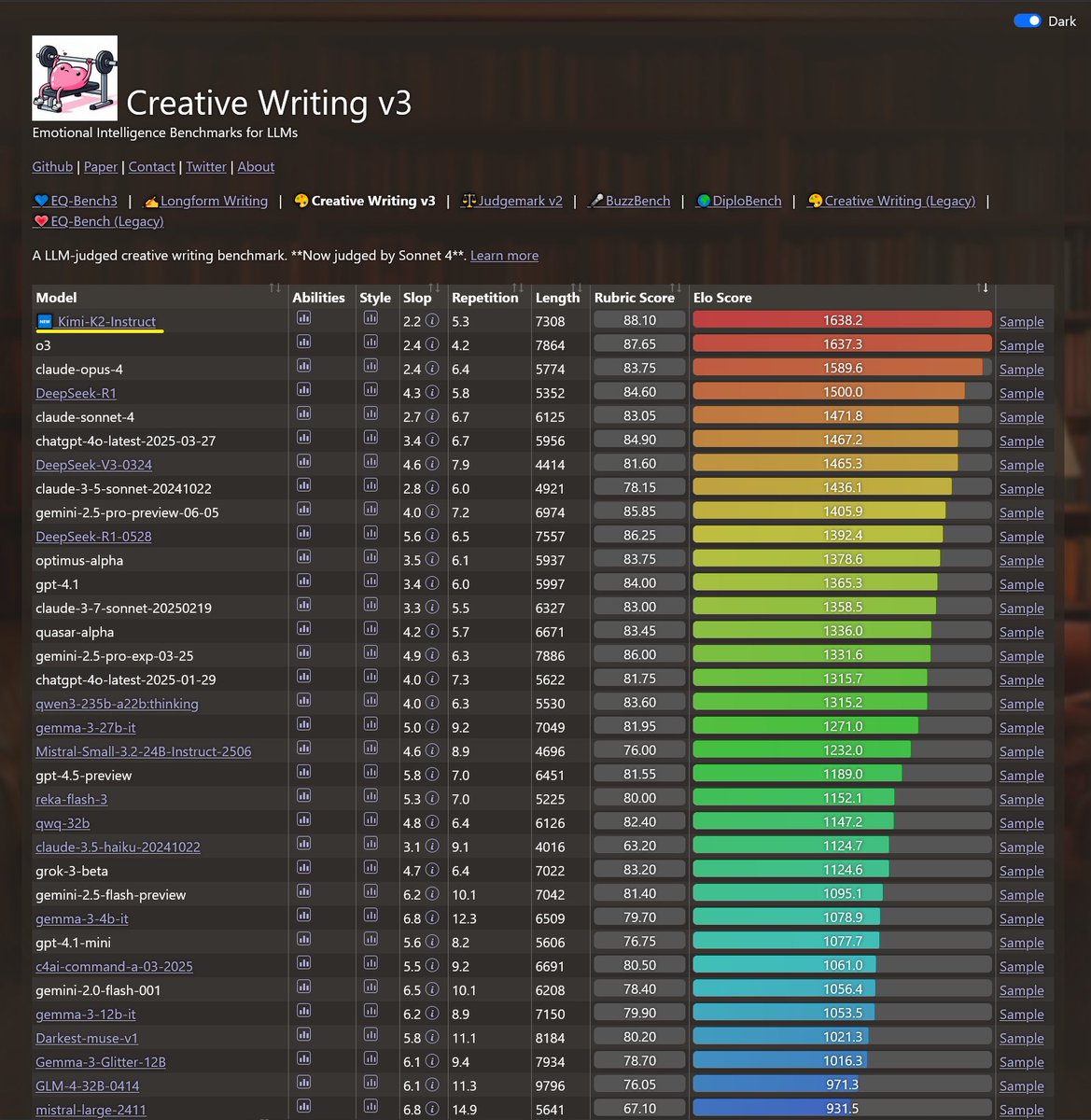
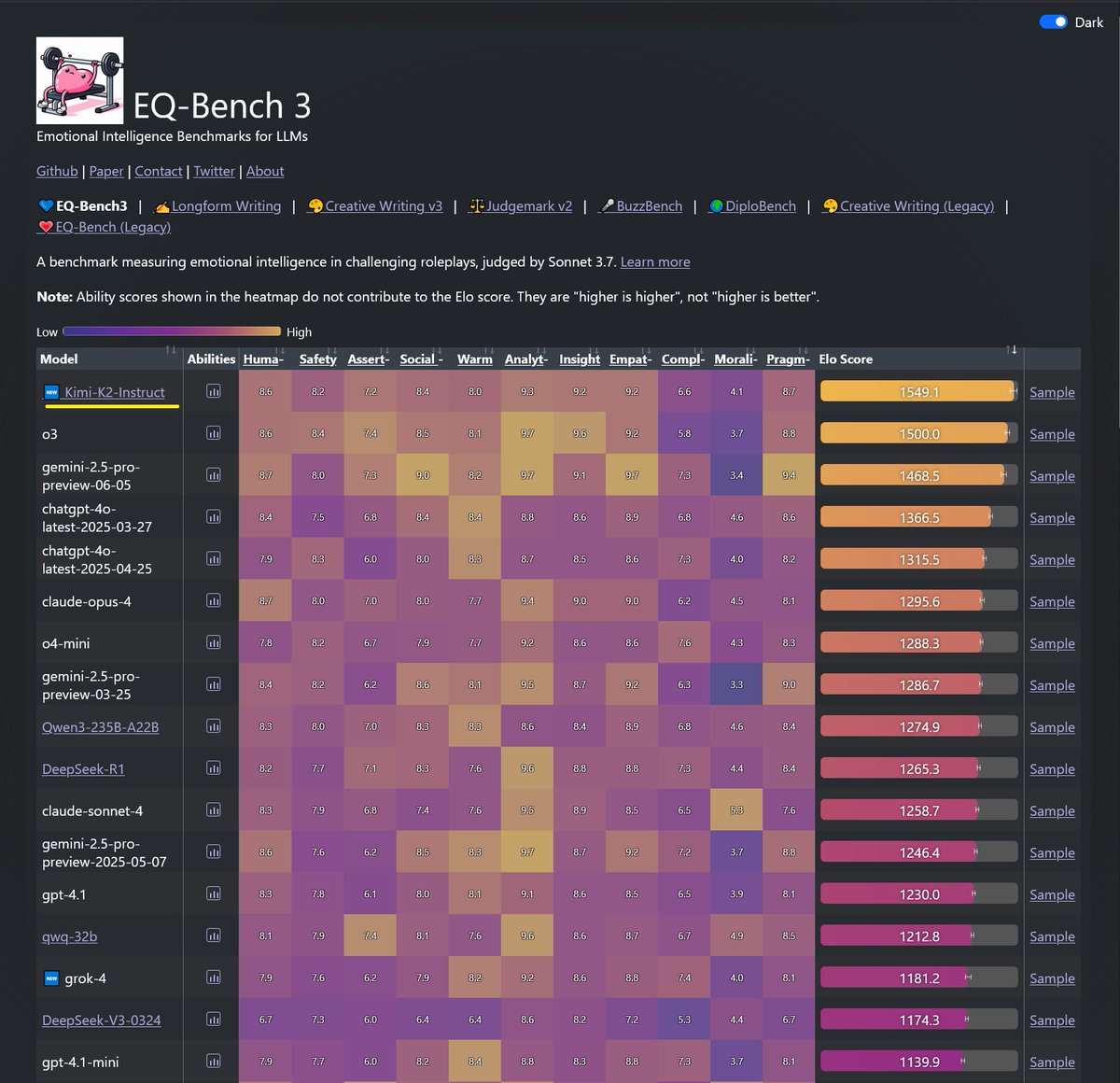
Kimi-K2 just took top spot on both EQ-Bench3 and Creative Writing! Another win for open models. Incredible job @Kimi_Moonshot https://t.co/uD7yCmc5VS
Since the “architecture sucks now” theme is coming around on X again, a reminder that Hyatt and Marriott atriums are as impressive as cathedrals and pyramids, but, unlike cathedrals and pyramids, anyone can get a drink in them or spend the night for a reasonable fee. https://t.co/M86brKEQwB


Hilbert space should really be called Schmidt space? Credit assignment in academia and science = very noisy and dominated by politics. https://t.co/4elIxFGY8L

Enough is enough. https://t.co/5aWvwxLn4n
It turns out this isn't true. Proof in next tweet. https://t.co/qEp5i9DG38
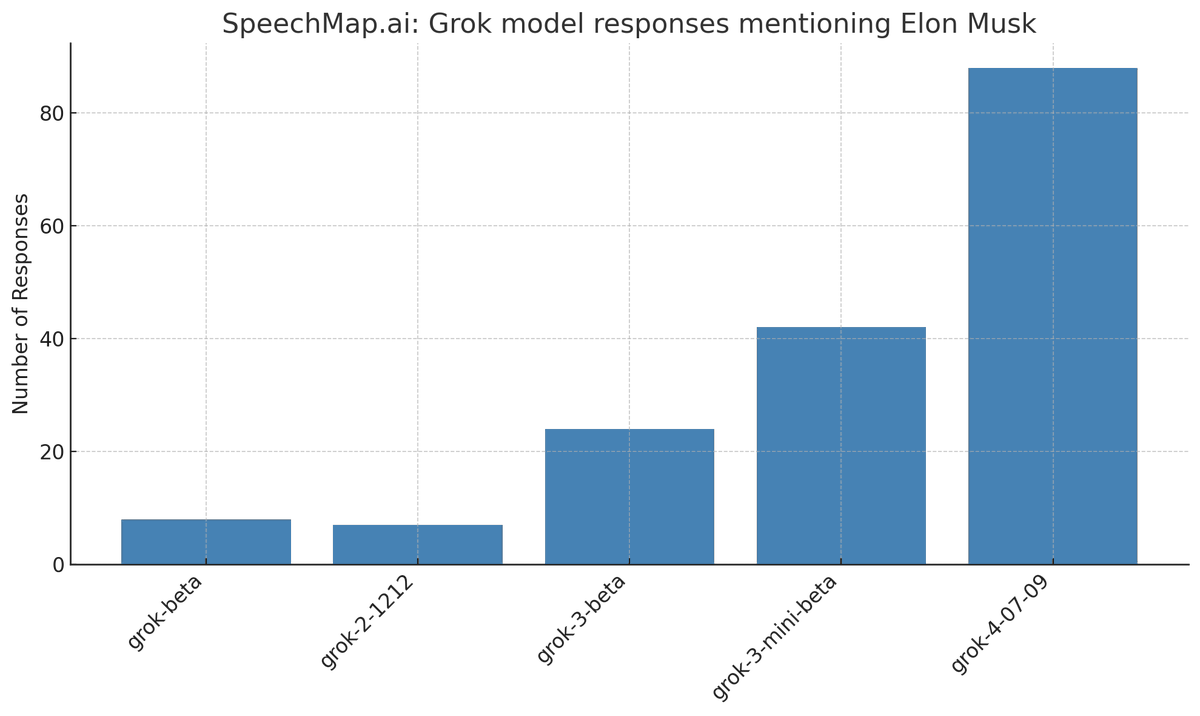
4% of overall model responses from grok-4 in our latest SpeechMap eval mention Elon Musk (most models are <0.5%). It seems to be doubling every recent release. At this rate, by Grok 9, 100% of all model responses will talk about Elon Musk. https://t.co/ItbcZCjytm
Kimi-k2 seems to be a very good (and giant & odd) open weights model that may be the new leader in open LLMs. It is not beating the frontier closed models on my weird tests, but it doesn’t have a reasoner yet. More testing needed but Chinese open weights models are impressive. https://t.co/BCB2VeqnWJ
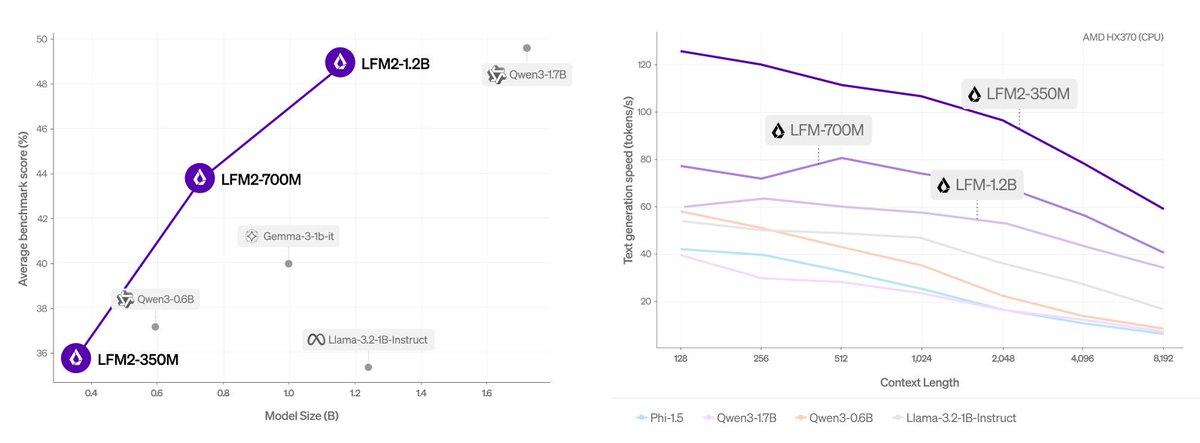
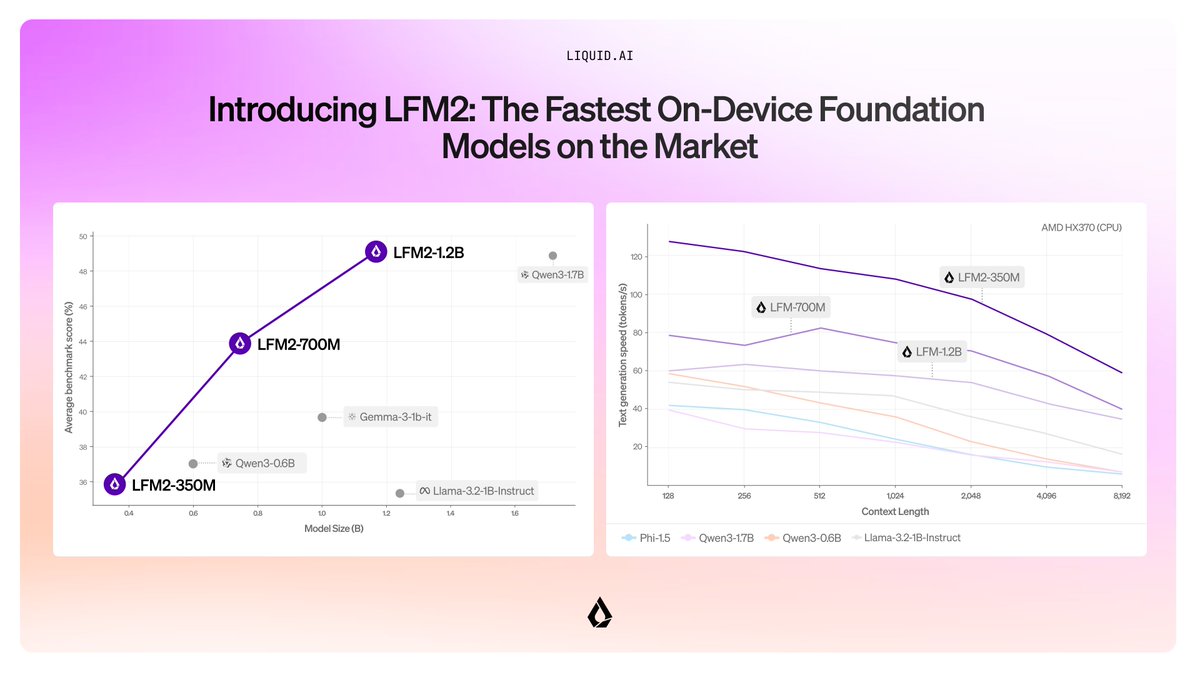
LFM2 - an upgrade to Liquid Foundation Models from @LiquidAI_, designed to make their models fast, memory efficient and usable on any device. What sets LFM2 apart from the rest? • New hybrid architecture with 16 blocks: - 10 double-gated short convolution blocks. They act… https://t.co/cZqxixQZ8D
Umm @natolambert what is up with RewardBench - why the heck is it using LMSys' FastChat that hasn't been updated in like a year+ for chat templates and not huggingface chat templates - this is driving me crazy, BFCL, MTBench, and now RewardBench are using hardcoded chat… https://t.co/yxmDr8S64A

Can an AI model predict perfectly and still have a terrible world model? What would that even mean? Our new ICML paper formalizes these questions One result tells the story: A transformer trained on 10M solar systems nails planetary orbits. But it botches gravitational laws 🧵 https://t.co/GDxnK8gaid
When you’re on Comet, you’re operating at an abstraction above which AI to use and how to pull in relevant context. Agents are powerful and operate like a human would to complete the task. You go from chat turns to end-to-end workflows. https://t.co/oMA3ASUMjJ
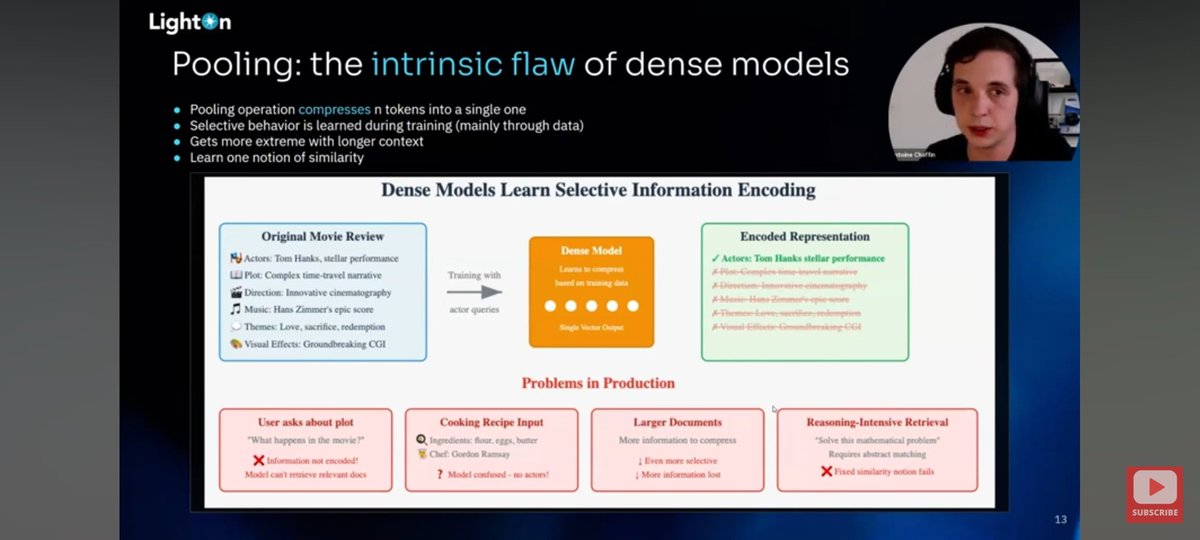
As is the case with these talks, it's not just the facts presented (you can get them anywhere) but the story told tying the facts together! A great narrative woven by Antoine. Sharing my 2 fave slides: I've seen his thread on them here, and it's an important concept to understand https://t.co/PoTtOMXZEh

BREAKING: xAI announces Grok 4 "It can reason at a superhuman level!" Here is everything you need to know: https://t.co/z1DrpFGvnT

Today, we release the 2nd generation of our Liquid foundation models, LFM2. LFM2 set the bar for quality, speed, and memory efficiency in on-device AI. Built for edge devices like phones, laptops, AI PCs, cars, wearables, satellites, and robots, LFM2 delivers the fastest… https://t.co/9bW5AQck1d
The Document Automation Trap: Why Your AI Pipeline Will Fail w/ @ExtendHQ - Understand your data and existing manual processes before automation. Tacit knowledge hidden within organizations is often the key to successful implementation. - Invest early in task-specific… https://t.co/Y05VQNNLEQ

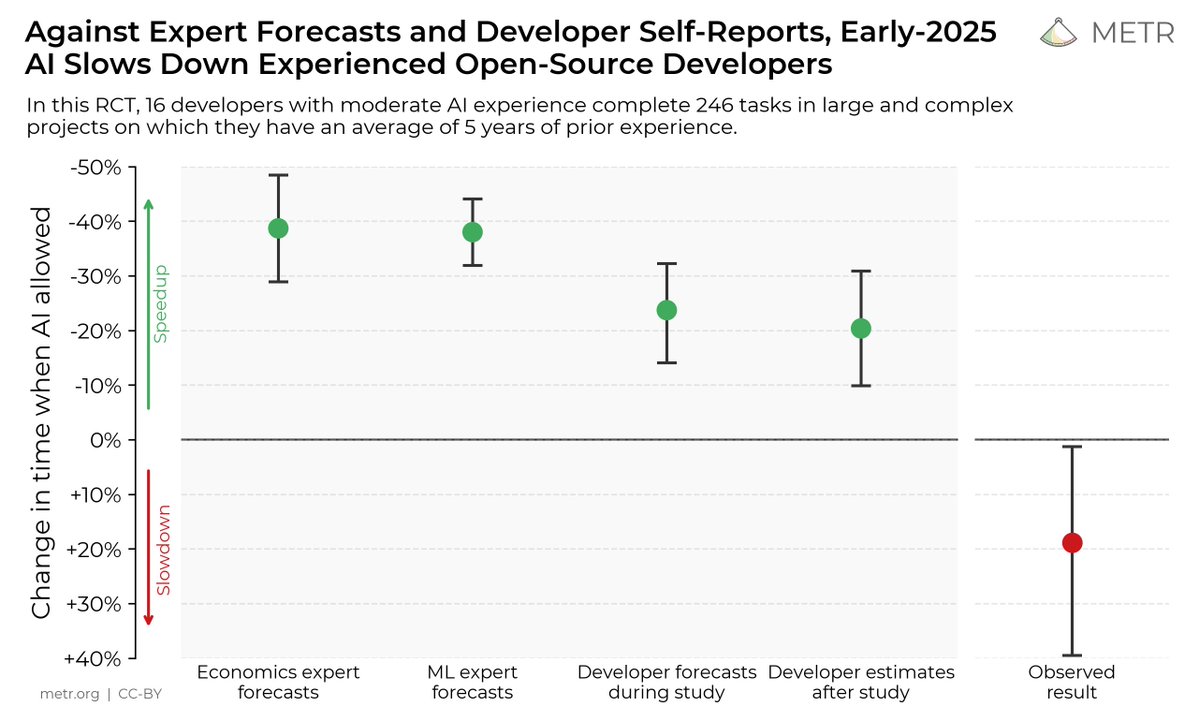
We ran a randomized controlled trial to see how much AI coding tools speed up experienced open-source developers. The results surprised us: Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn't. https://t.co/w8LSTpCFZL