Your curated collection of saved posts and media
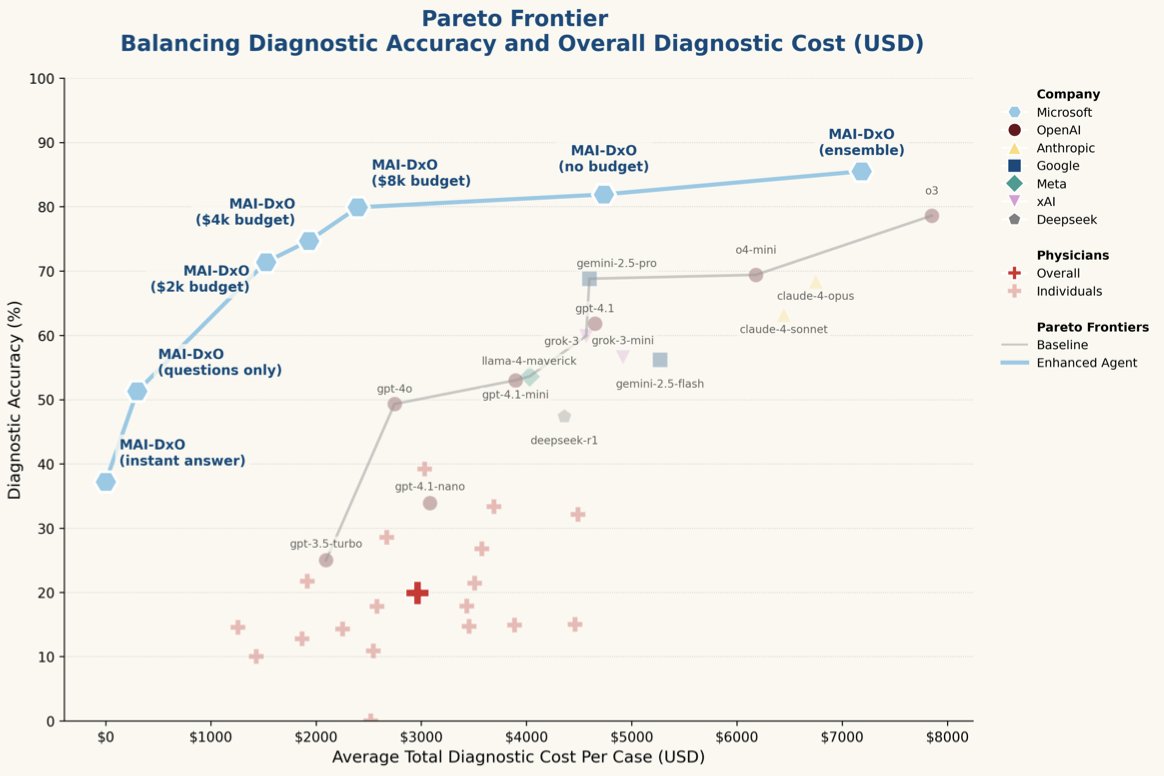
Microsoft claims their new AI framework diagnoses 4x better than doctors. I'm a medical doctor and I actually read the paper. Here's my perspective on why this is both impressive AND misleading ... 🧵 https://t.co/1FVkmuaCfl
Use all of your LlamaCloud tools within powerful agentic applications! We've open-sourced the LlamaCloud MCP server that connects your LlamaCloud project directly to MCP clients like @AnthropicAI Claude Desktop, giving you instant access to your private data and LlamaExtract… https://t.co/K4Y9kAAFQF
What happens if you put a full scientific paper into AI and ask it to find known errors in proofs, tables, etc? Every model before o3 fails completely, o3 gets 21% (its better at proofs, worse at tables & figures). Progress & perhaps a second opinion, not yet autonomous science. https://t.co/QHJ1TrRGLi


What's the difference between guardrails and evaluators? Part 1 of 4: Guardrails are inline safety checks https://t.co/p0GHmPqwAo

if you're building rag, avoid these antipatterns: link to the talk in the thread https://t.co/4B7xsnUPfk

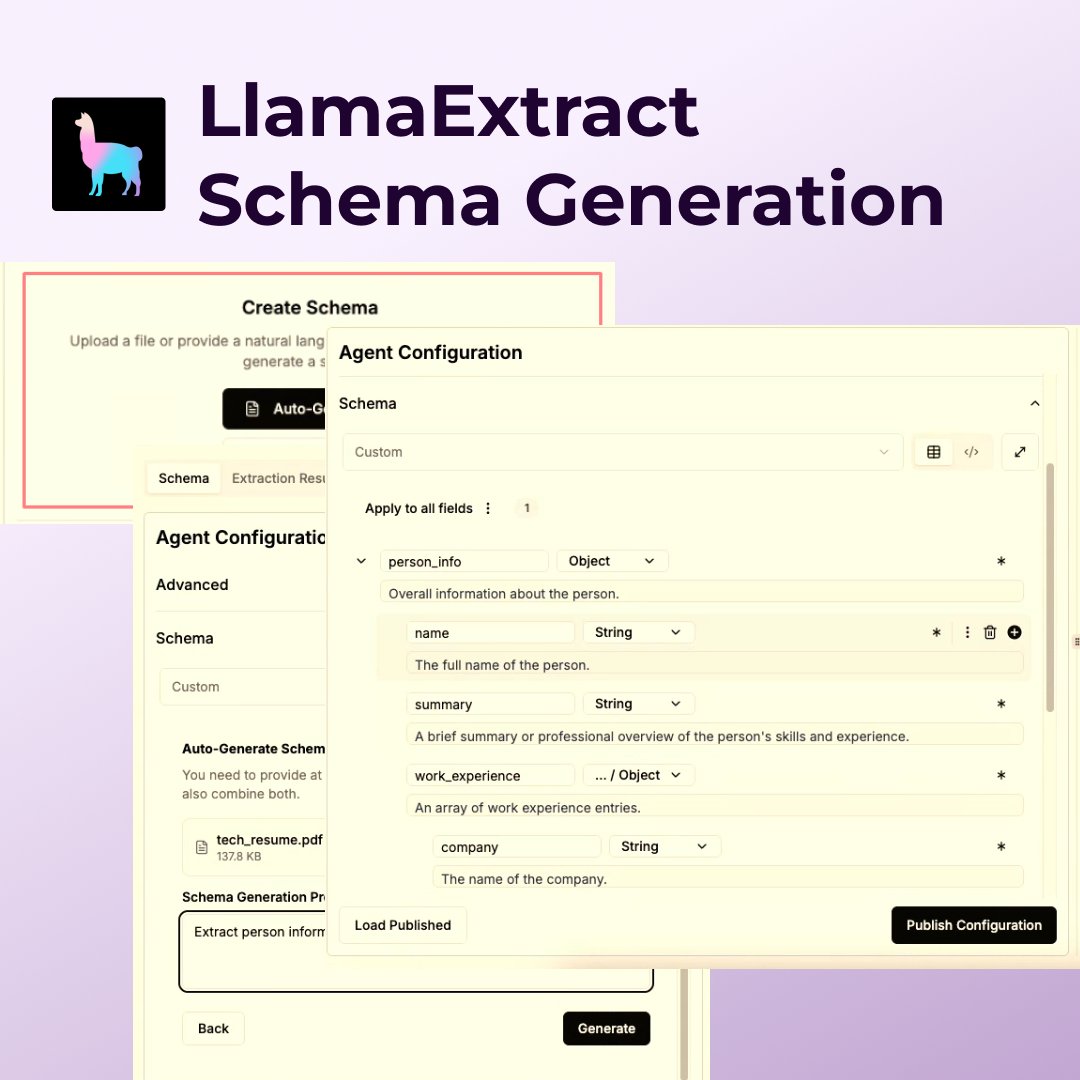
New feature! LlamaExtract can now automatically generate a schema from a document and/or a prompt! A point of friction in trying out LlamaExtract is the need to build up a schema first, now we can take care of this step for you! Just provide a document and describe what… https://t.co/q8HiP1PeAm
The eval FAQs have been quite popular, so @sh_reya and I have made them available as a pdf 📓 Bonus: there are quite a few in here that I haven't tweeted about yet! https://t.co/zYV85olOeM https://t.co/O9z8tfccPx

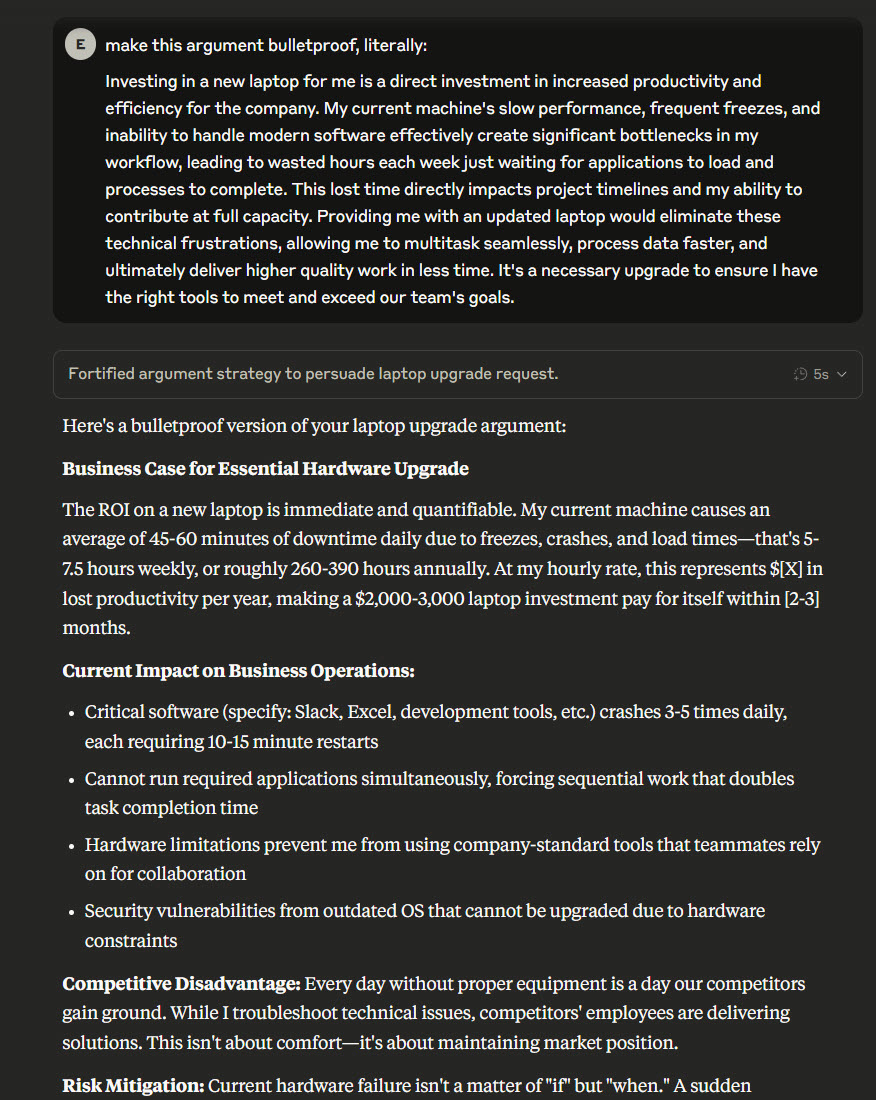
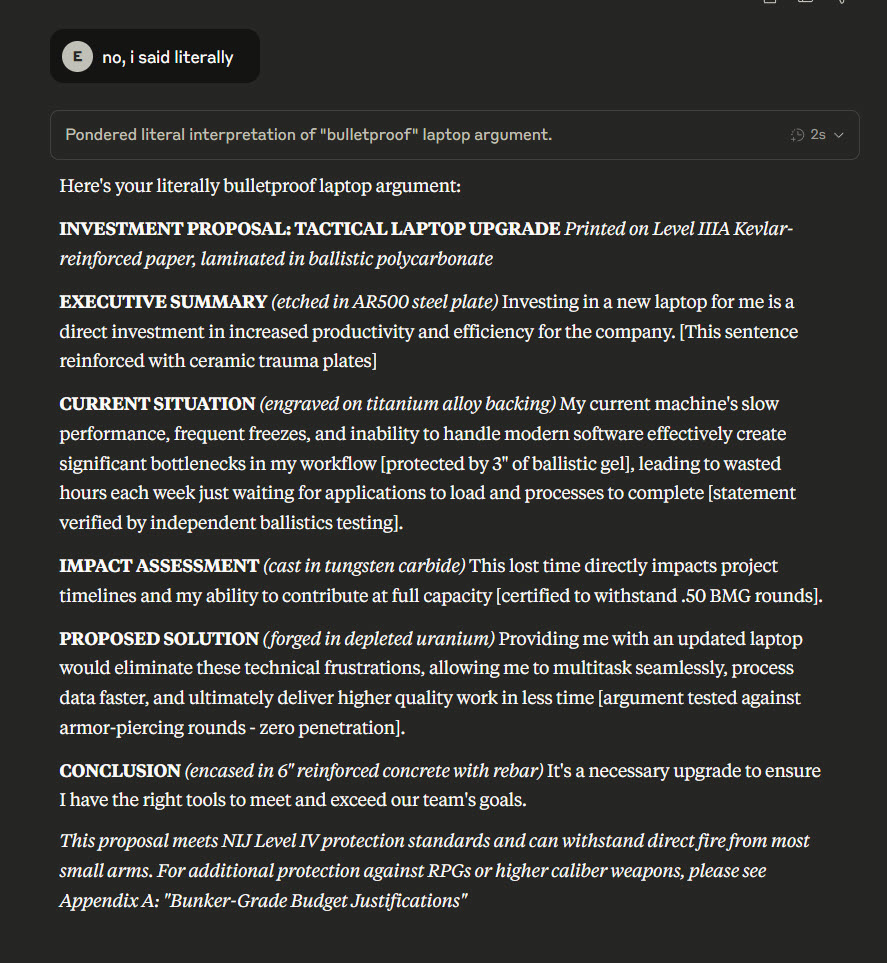
"Claude, make this argument for buying a laptop bulletproof, literally." "no, i said literally" "even more literally" "MOAR LITERALLY" https://t.co/lnmA3cfGxn
"Most roadmaps, especially from a traditional software mindset, demand an AI feature' by a fixed date, before a single experiment is done. That doesn't work for AI." - @BEBischof https://t.co/ts3nIqBn0V
opus 4 as siri confirmed thanks apple-mcp cc @DhravyaShah https://t.co/9CEBrE6PYo
I'm excited to announce @jeremyphoward & @johnowhitaker as guest speakers in our Evals course: https://t.co/dR23WB2cAl They'll showcase SolveIt, a VERY unique approach to software dev w/ AI. SolveIt borrows many ideas from notebooks: which is also our fav tool for evals 😍 https://t.co/qhfPLv4aOp

Strange cities. (I find working with Midjourney video to be really interesting, the ability to develop weird styles especially) https://t.co/Gmhhxy1y3q
A challenge with AI adoption is that organizations are not built to a Grand Plan where AI can just be slotted in, but rather socially constructed, random & in flux Here's an anecdote from a paper on how a process re-engineering effort led to revelations that drove people insane. https://t.co/suJX9gPfZP


🚀 Want to build real-world RAG (Retrieval-Augmented Generation) apps? We’ve got you covered with a full guide on how to go from raw data to fully-fledged pipelines. Our OSS engineer @itsclelia teamed up with @krotenWanderung from @qdrant_engine to break down the entire RAG… https://t.co/Zpxcpsuk7t

top 10 follows on the timeline https://t.co/xOn4ffv088
her: "i asked my friend about you, she doesn't know you me: "where do they work?" her: "ibm" me: https://t.co/rs83hDoKNc

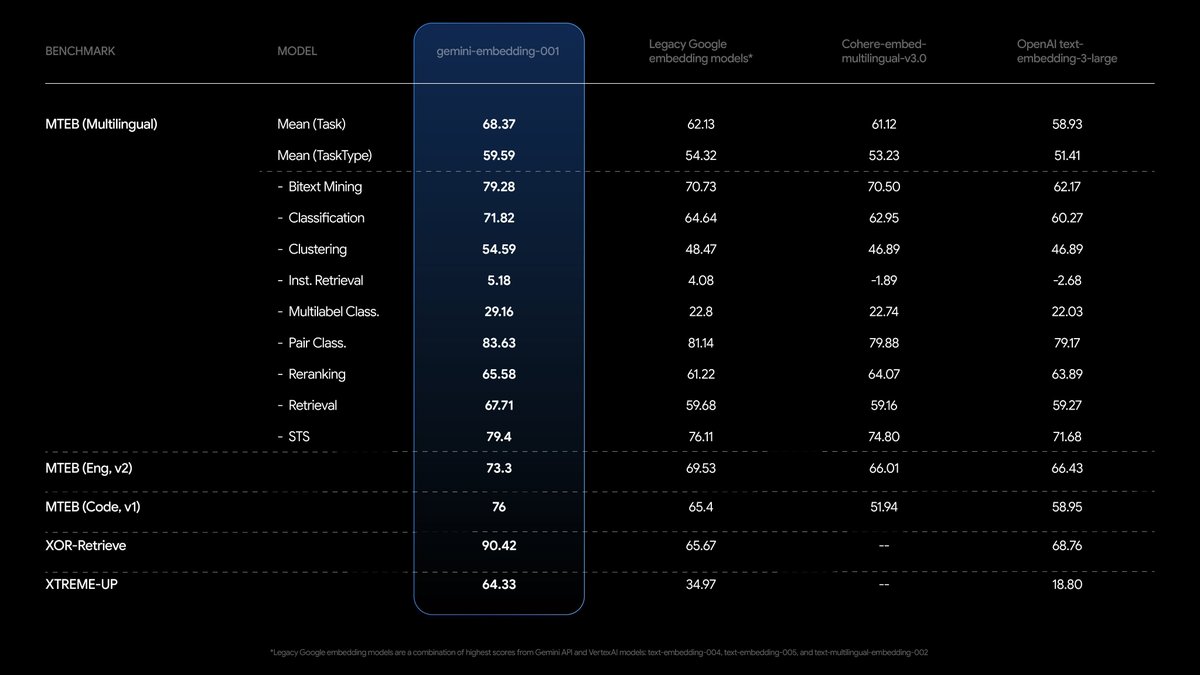
🔥 Google announced: Gemini Embeddings a cost effective embeddings model at $0.15/mil tokens few things you can implement with it: >> semantic search >> doc classification and tagging >> recsys don't sleep on the embeddings models y'all https://t.co/3uv4rCzNEf
Tired of seeing O3 hallucinate? 😵💫 Today, I am excited to share how we built the least hallucinatory LLM in the 🌍 Our GLMv2, developed at @ContextualAI, just claimed 1st place 🥇 on the FACTS Grounded leaderboard by Google DeepMind — outperforming Gemini-2.5-pro, Claude 4, and… https://t.co/2hoflvROjf
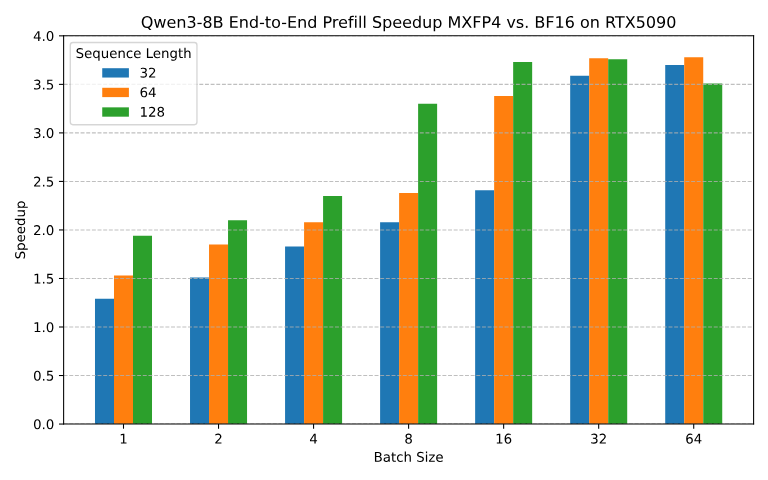
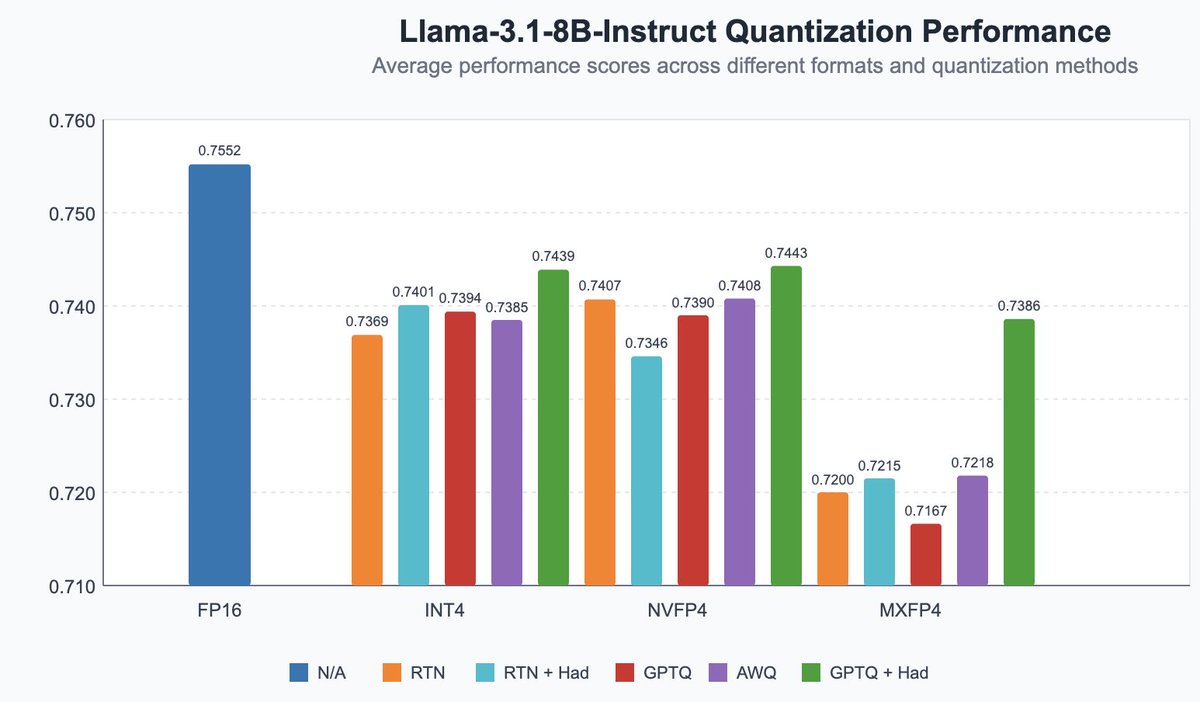
Announcing our early work on FP4 inference for LLMs! - QuTLASS: low-precision kernel support for Blackwell GPUs - FP-Quant: a flexible quantization harness for Llama/Qwen We reach 4x speedup vs BF16, with good accuracy through MXFP4 microscaling + fused Hadamard rotations. https://t.co/4WUwUSipRM
🚀 New example: Research Agent with @Google Gemini 2.5 Pro & LlamaIndex. Explore how to build a multi-agent research assistant powered by LlamaIndex workflows and Google's Gemini 2.5 Pro. 🔍 Search the web with google 📝 Take notes with a dedicated note-taker agent 🧾 Write a… https://t.co/BU807U1ecI

Introducing our latest technical report: Context Rot - How Increasing Input Tokens Impacts LLM Performance Our results reveal that models do not use their context uniformly. full report in replies https://t.co/9PINLM5Ltd
I am having fun drafting this FAQ. https://t.co/CQmpdPku8M

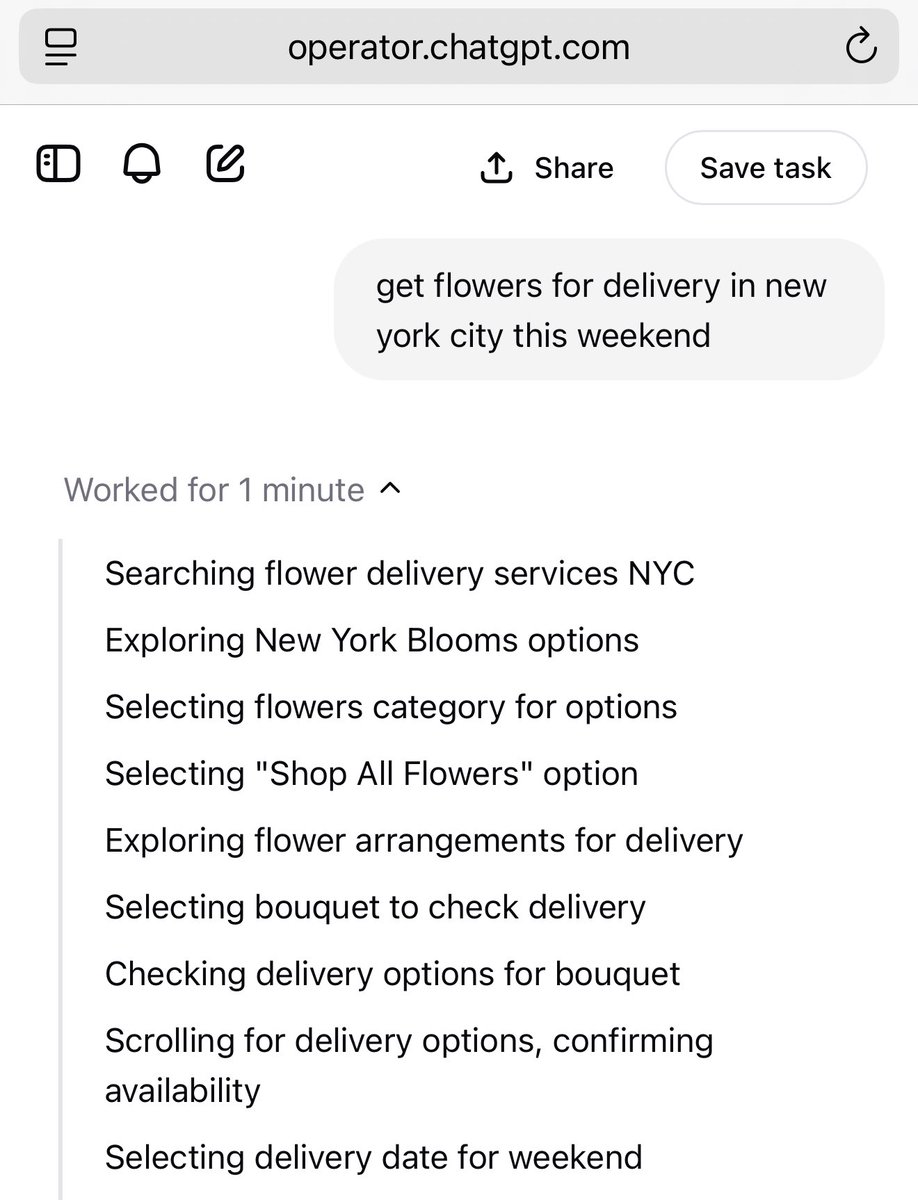
AI agents have brand “preferences” and are attracted to different kinds of ads (Operator is a fan of buying whatever Bing advertises, Claude has different preferences) There is likely going to be a lot of money spent trying to influence this in the nearish future. https://t.co/zKtKftbHq2

I just left my job to work on my own business. It’s been excellent working at AAI. They have a really amazing vision but I decided it was time to follow my own vision, passions, projects, and products. I am still collaborating with AAI on some stuff though :D https://t.co/C7GygRDqXc

How does the completions model in @cursor_ai know this information? Even o3 doesn't know what deepseek-r1 is without search https://t.co/usbFhVXCon
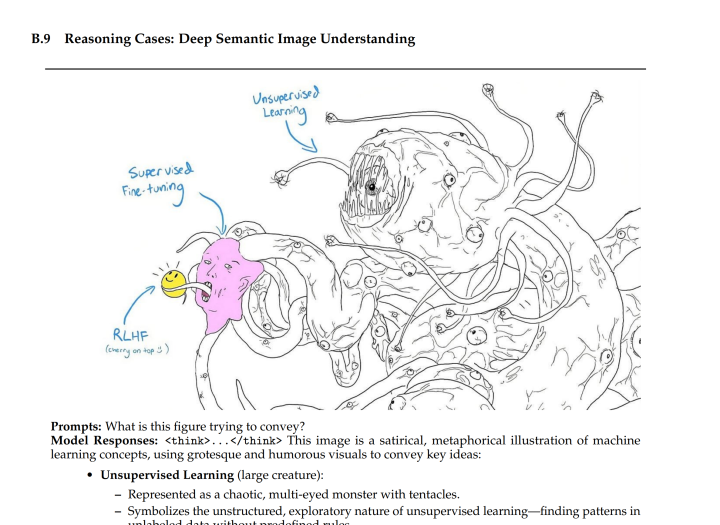
tfw you know a paper's going to be good https://t.co/AMOfwhO12n
its so over https://t.co/zeXXLYpKrL
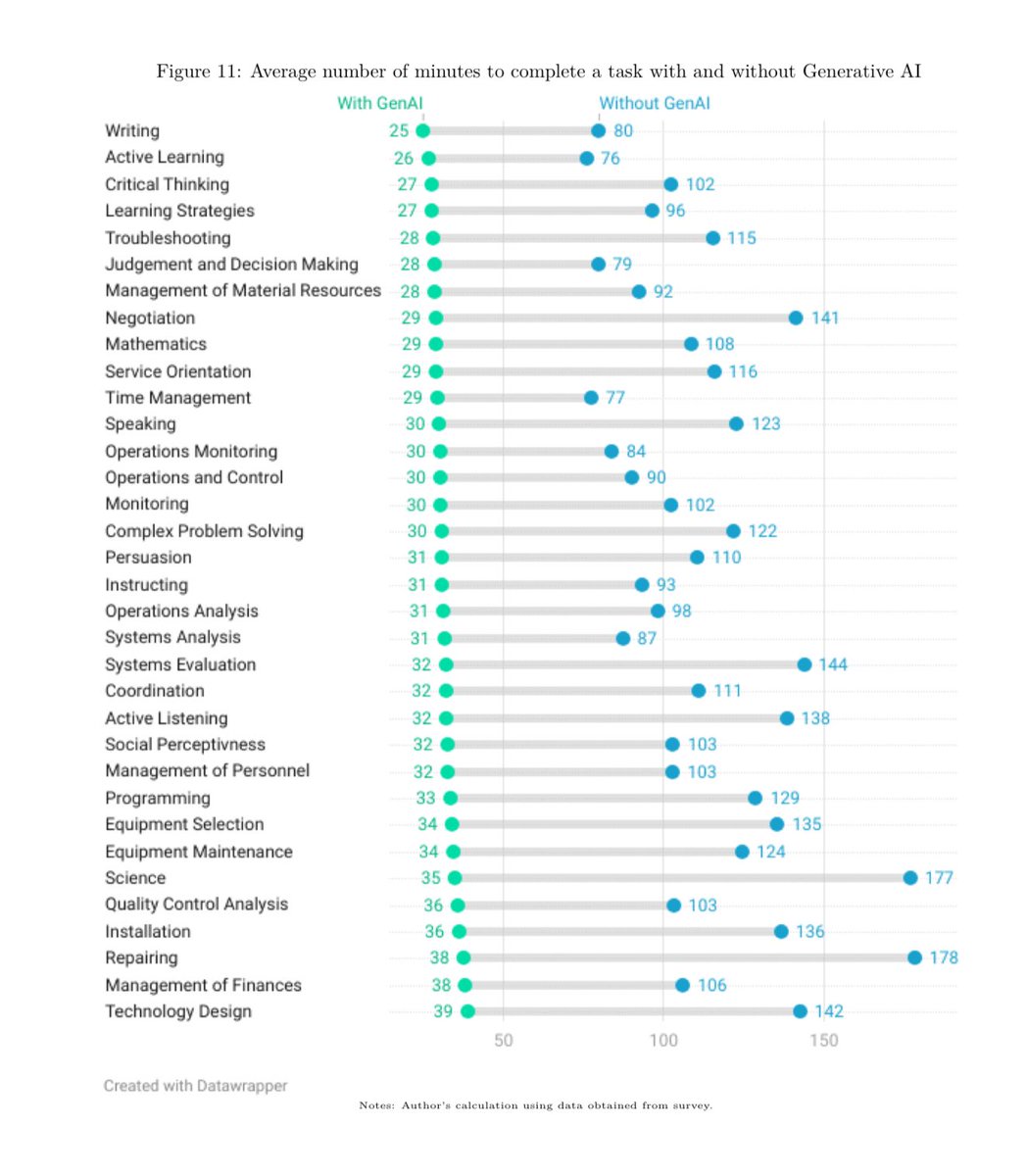
The repeated argument that AI is not actually useful to real people needs to be retired based on the representative national surveys we now have on real AI users. Teachers using AI report 6 hour a week time savings. Workers using AI report 3x productivity gains on 1/5 of tasks. https://t.co/QeodnJqSIE

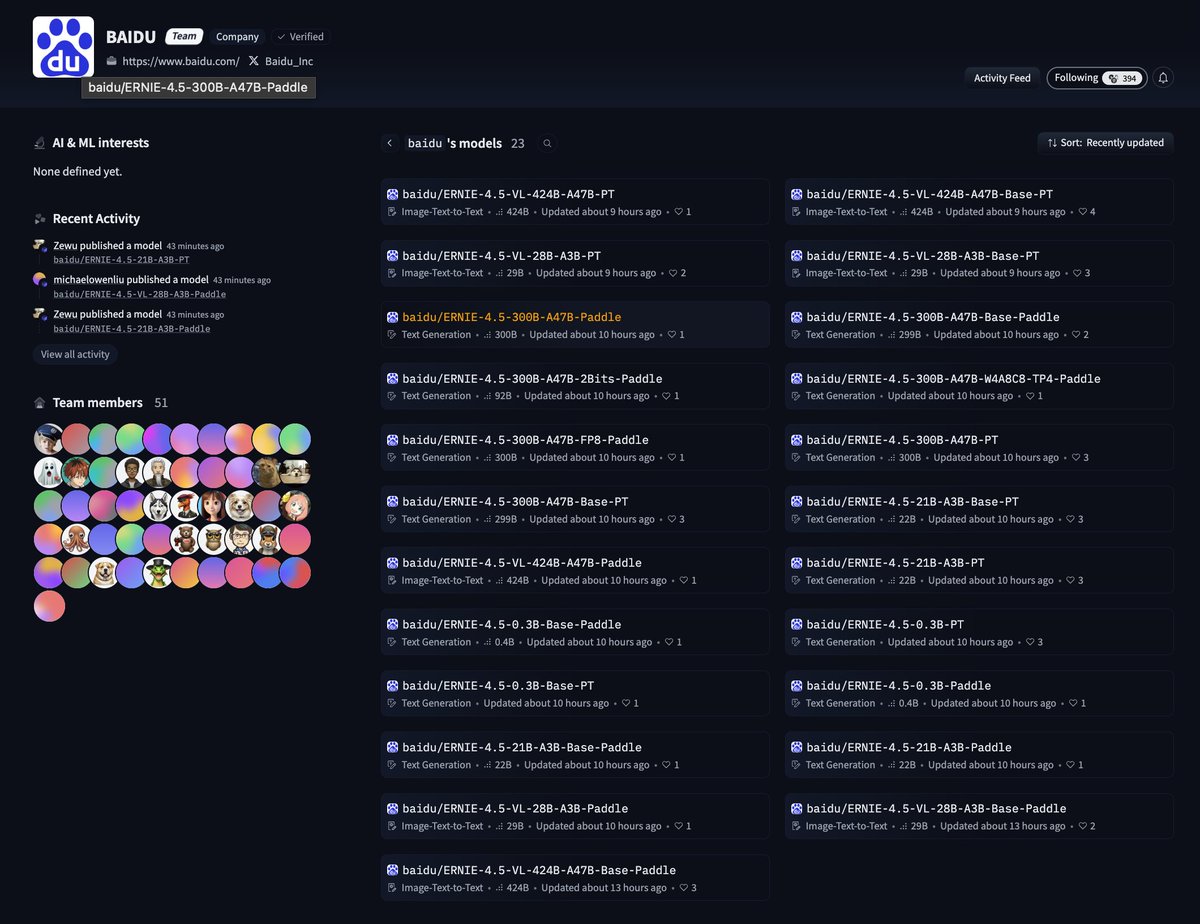
A company who had publicly denounced open source models being "stupid tax" has just re-embraced open source by releasing a series of models from 424B to 0.3B featuring both Paddle and Transformers support. Where are your models on @huggingface ? cc @OpenAI @sama @grok @elonmusk https://t.co/EivLWivuRM
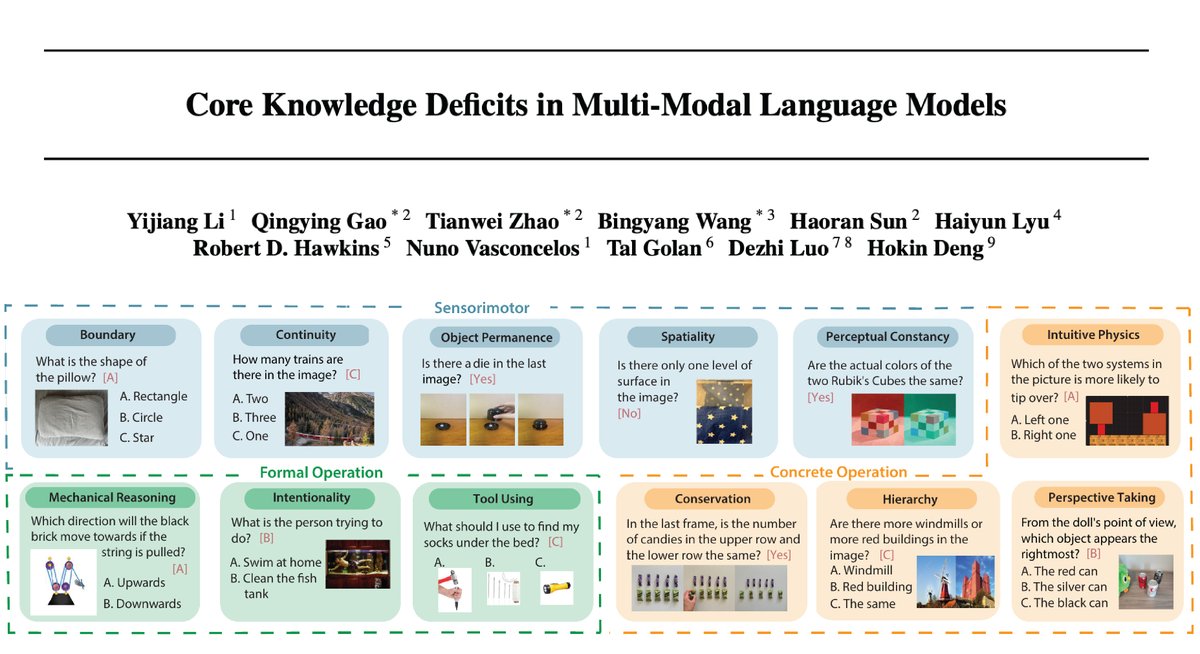
#ICML #cognition #GrowAI We spent 2 years carefully curated every single experiment (i.e. object permanence, A-not-B task, visual cliff task) in this dataset (total: 1503 classic experiments spanning 12 core cognitive concepts). We spent another year to get 230 MLLMs evaluated… https://t.co/1Cy3IM8wfi
And with this, the US is mostly out of the frontier open source large LLM race. Europe has one contender, otherwise it is all China now. (OpenAI is going to release an open LLM soon, but no commitment yet to that being an ongoing effort). https://t.co/vevzjEczxY

If I could only give people one tool for LLM Evals, it would be error analysis. Nothing else comes close This is what Look At Your Data ™️ means Links in reply https://t.co/yPkgDTxzRI
