@DAlistarh
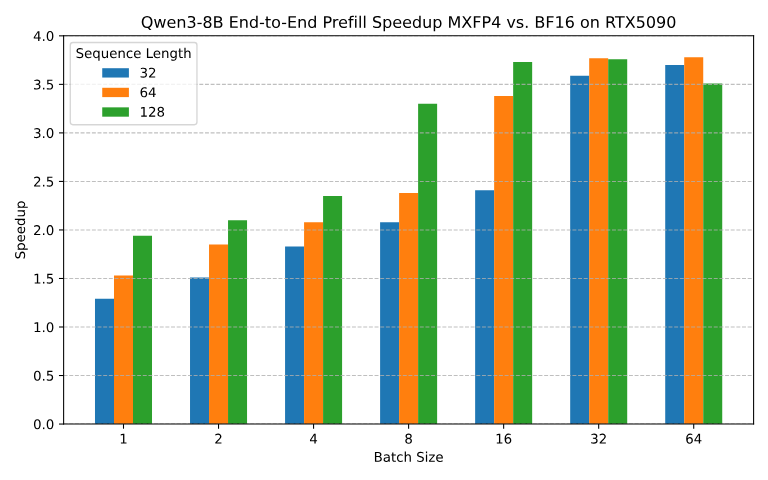
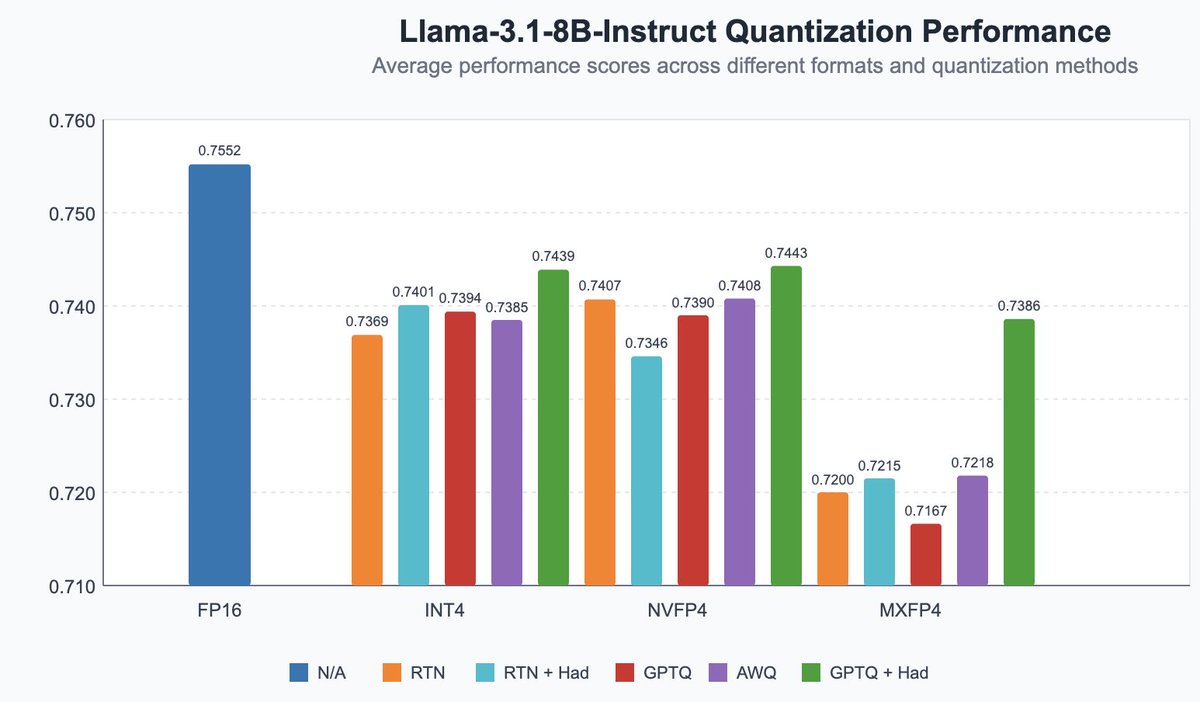
Announcing our early work on FP4 inference for LLMs! - QuTLASS: low-precision kernel support for Blackwell GPUs - FP-Quant: a flexible quantization harness for Llama/Qwen We reach 4x speedup vs BF16, with good accuracy through MXFP4 microscaling + fused Hadamard rotations. https://t.co/4WUwUSipRM