Your curated collection of saved posts and media
might use this on my profile as overheard in @HamelHusain 's course https://t.co/jVcZmbPJnJ
Serving Large Language Models on Huawei CloudMatrix384 - Integrates 384 Ascend 910C NPUs, interconnected via an ultra-high-bandwidth, low-latency UB network, optimized for large-scale MoE and distributed KV cache access - DeepSeek-R1 on CloudMatrix-Infer hits 2k tokens/s decode… https://t.co/zZuEAdu7Gn

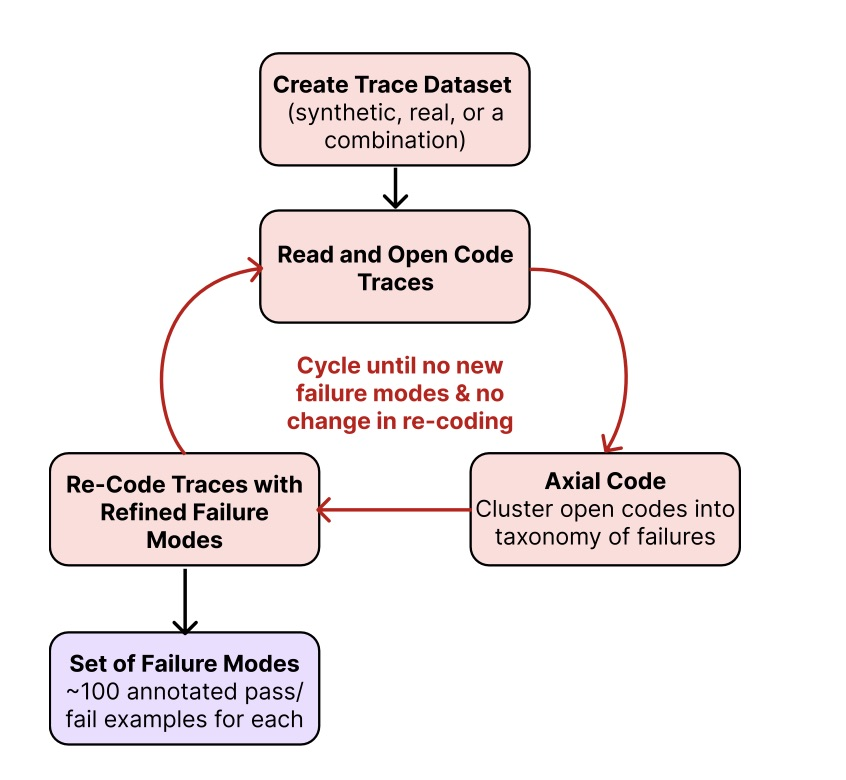
Stop wasting time guessing why your AI fails. The most valuable skill I learned recently: error analysis https://t.co/e5XWJB1L1a Hamel & Shreya teach you how to diagnose what's going wrong with your pipeline, and build evals you can trust at scale. Error analysis is just the… https://t.co/D2ptDf7fEF
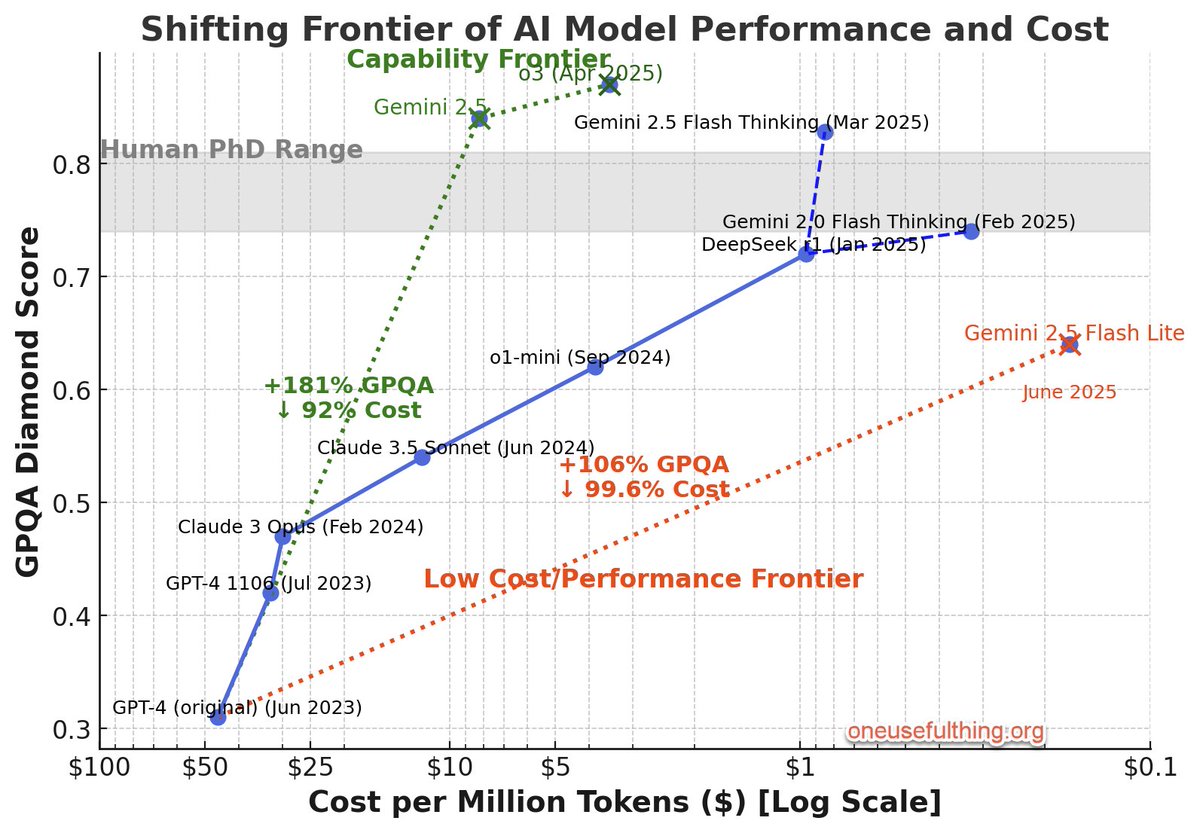
No signs of an end to rapid gains in AI ability at ever-decreasing costs yet I did my best to update my chart to take into account the price drop in o3 & the new models released by Google. GPT-4 was 2.25 years ago,so its worth noting the trend when considering the future of AI. https://t.co/mF4CZ5eqQp
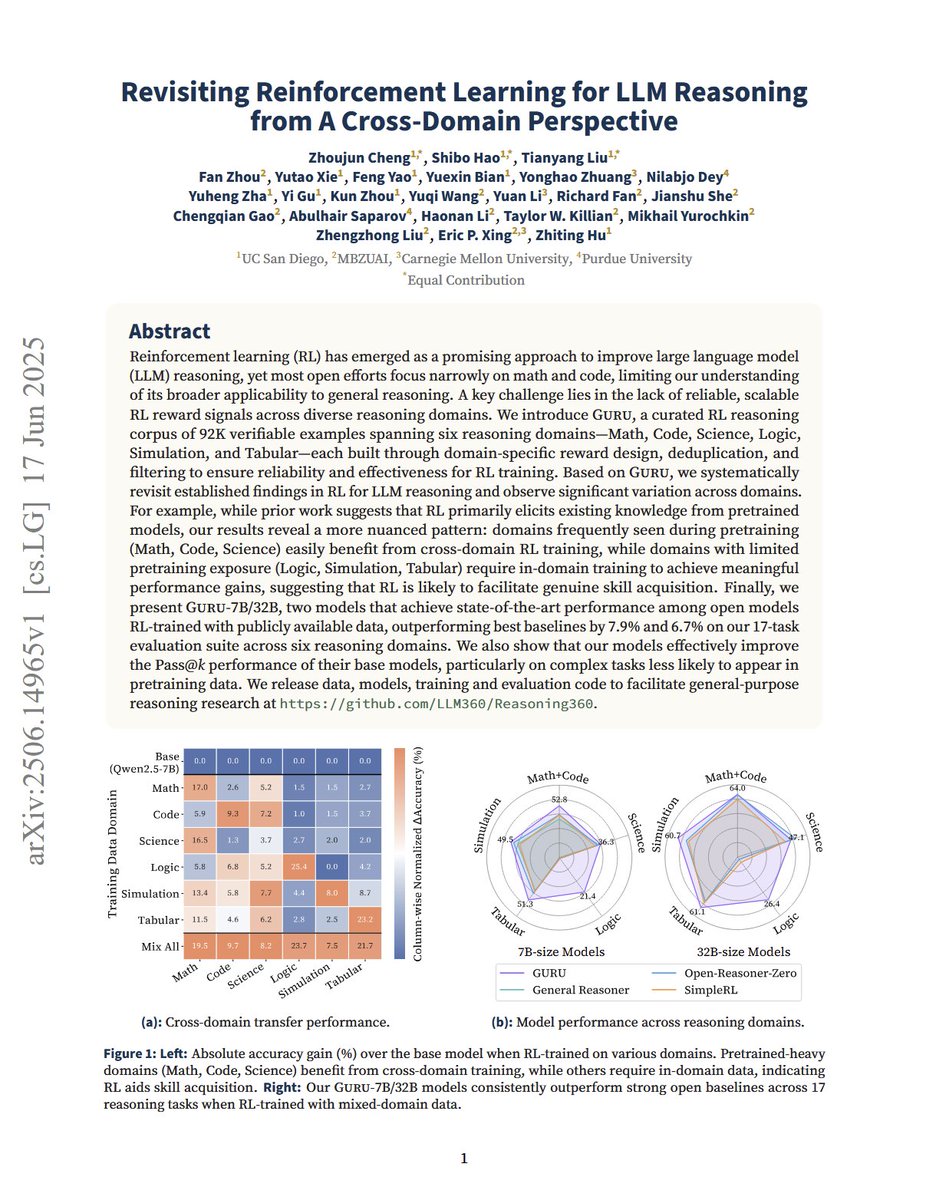
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective "We introduce GURU, a curated RL reasoning corpus of 92K verifiable examples spanning six reasoning domains—Math, Code, Science, Logic, Simulation, and Tabular—each built through domain-specific… https://t.co/Toc6SAkTXA
From Bytes to Ideas Avoids using predefined vocabs and memory-heavy embedding tables. Instead, it uses Autoregressive U-Nets to embed information directly from raw bytes. This is huge! Enables infinite vocab size and more. More in my notes below: https://t.co/AGonec9SzY

Agents training in RL gym https://t.co/ZvP1SgSrAA
From Bytes to Ideas: Language Modeling with Autoregressive U-Nets Presents an autoregressive U-Net that processes raw bytes and learns hierarchical token representation Matches strong BPE baselines, with deeper hierarchies demonstrating promising scaling trends https://t.co/9ShElZ6GsS

Nice recap of the progress in LLMs. If you want to be a top AI dev, dive deep into these topics. There are tons of opportunities and problems to solve. My notes below: https://t.co/KKHEDXCMsx

sonnet u poor thing https://t.co/m8Ls1PKJMj
veo 3: "three toy ships, one made of iron, the other of wood, and one out of loosely packed sugar, are dropped into a pool of water" AI video tools really do seem to be able to simulate physics well (but not perfectly) without having an underlying physics engine. A world model? https://t.co/Qen5S4VyoN
Providing “cognitive tools” to GPT-4.1 increases performance on AIME2024 from 26.7% to 43.3%. Damn! That's very close to the performance of o1-preview. Reasoning as a tool goes hard! Here are my notes: https://t.co/a6o2Cd5swC

Every machine in a Hospital that diagnoses your body without cutting you open is based on a principle of Physics, discovered by a Physicist who had no interest in Medicine. If you think the world doesn’t need Basic Science, or that somehow Science has failed you, think again. https://t.co/fvcdwnpKza
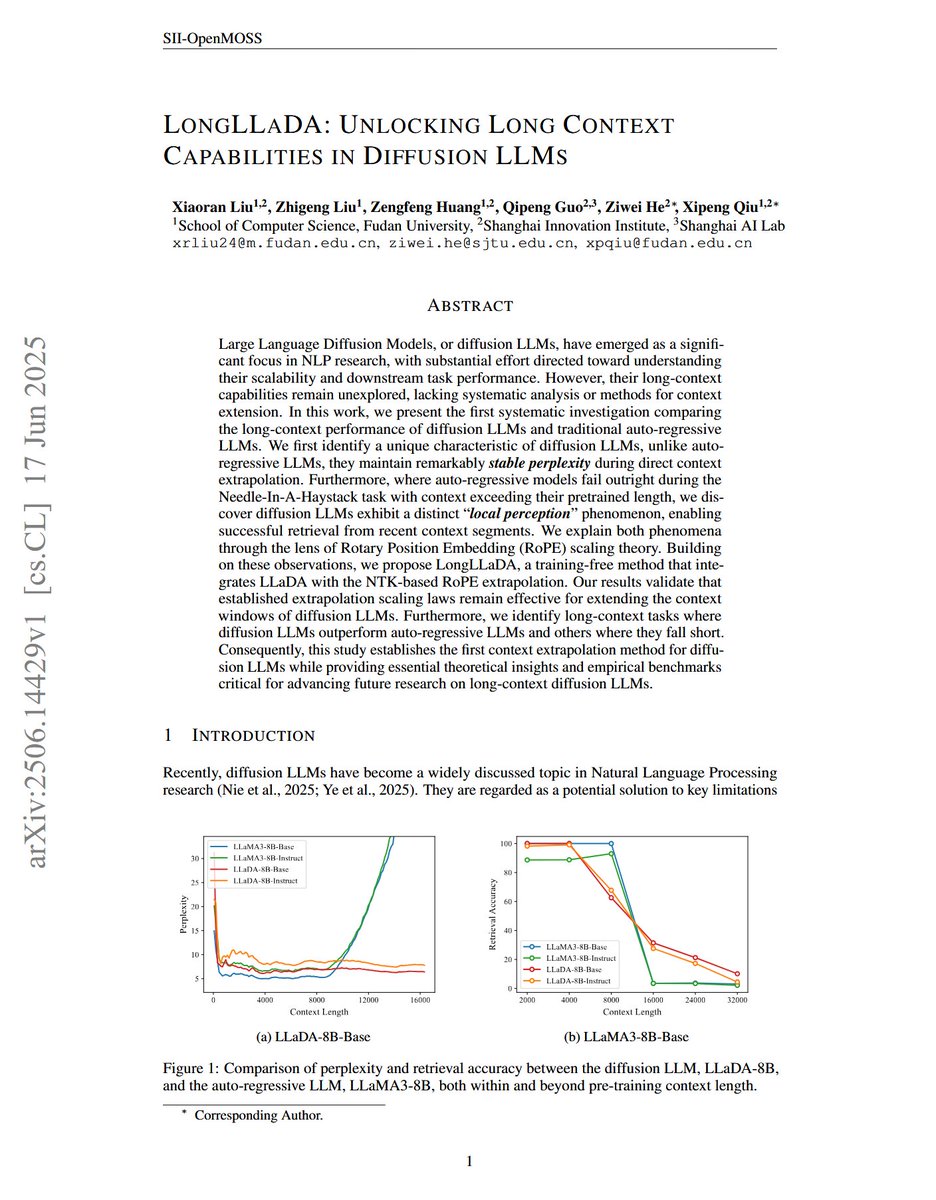
LongLLaDA: Unlocking Long Context Capabilities in Diffusion LLMs "we propose LongLLaDA, a training-free method that integrates LLaDA with the NTK-based RoPE extrapolation. Our results validate that established extrapolation scaling laws remain effective for extending the… https://t.co/DDDl1L4dDc
We’re building the most advanced agentic AI assistant for clinicians. Today, we’re announcing a $70M Series C to accelerate our mission: restoring the human connection at the heart of healthcare through AI that delivers real clinical and financial impact. Thank you to… https://t.co/VVrOgpzwYu

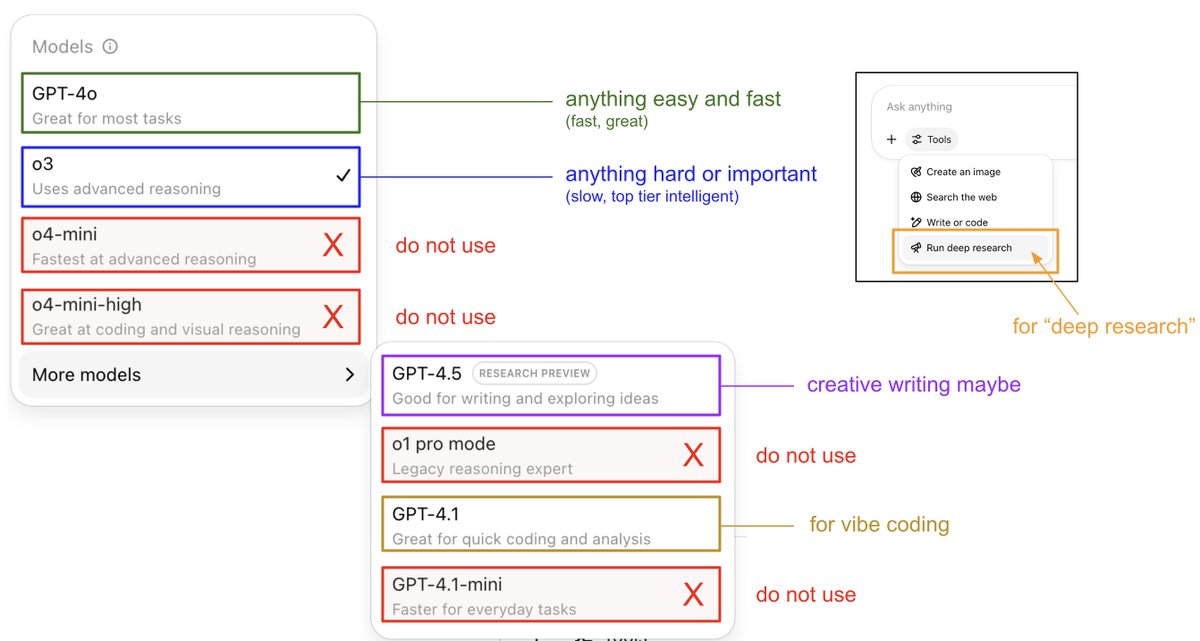
An attempt to explain (current) ChatGPT versions. I still run into many, many people who don't know that: - o3 is the obvious best thing for important/hard things. It is a reasoning model that is much stronger than 4o and if you are using ChatGPT professionally and not using o3… https://t.co/1bQz0frqIc
Serving Large Language Models on Huawei CloudMatrix384 "this paper introduces Huawei CloudMatrix, a next-generation AI datacenter architecture that embodies Huawei’s vision for reshaping the foundation of AI infrastructure." "To fully leverage CloudMatrix384, we propose… https://t.co/8QpwKlZSX1

Great end-to-end platform for teams building with LLMs and using prompts in production. Adaline is a single platform where teams can iterate, evaluate, deploy, and monitor AI prompts. They are also giving $1M in API credits to the first 100 team workspaces this week. 🔄 Use… https://t.co/kyIUoJwegq
lmarena has a competitor Yupp is basically lmarena, but with more granular feedback and a credit system. Each message costs you some credits, but when you give high-quality feedback you get credits back to use on your favorite models. This is their multi-turn (5+ messages) VIBE… https://t.co/1R0zwHqast
I'm surprised this post didn't get more attention. Most papers arguing we are far from AGI just show LLMs failing on tasks too big for their context window. Sergey identifies something more fundamental: while LLMs learned to mimic intelligence from internet data, they never had… https://t.co/SGhOh15OIT

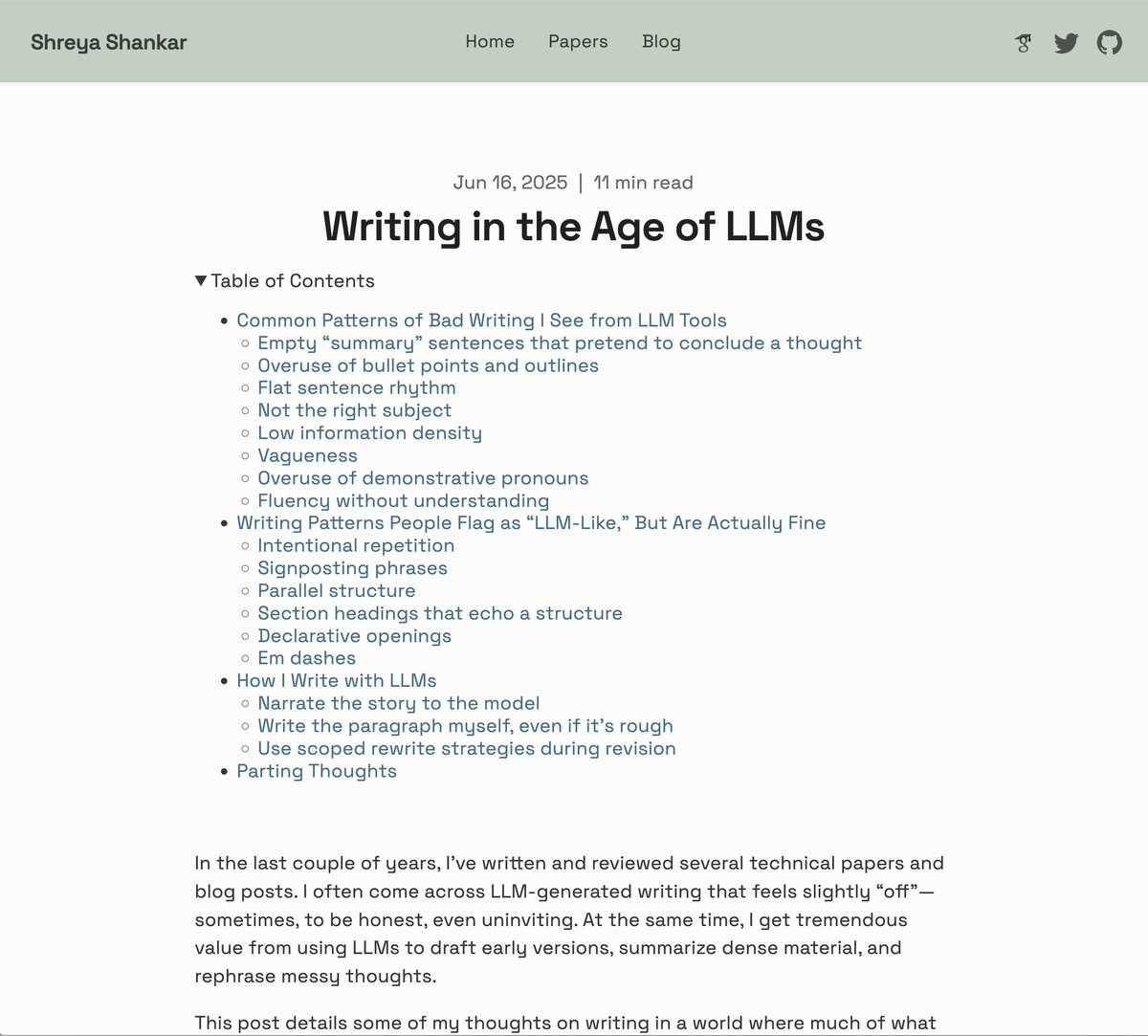
new blogpost on writing in the ~glorious~ age of LLMs https://t.co/EmownEiZ9S
"You can either actually try different ways to make your search results good, or you can just have seven meetings with VectorDB vendors who tell you their way is the best." - @BEBischof https://t.co/dR23WB2cAl https://t.co/hvMtWcvX5d
benchmarking kura on lmsys and claude says the clustering is v v good https://t.co/QG2dmFth5y

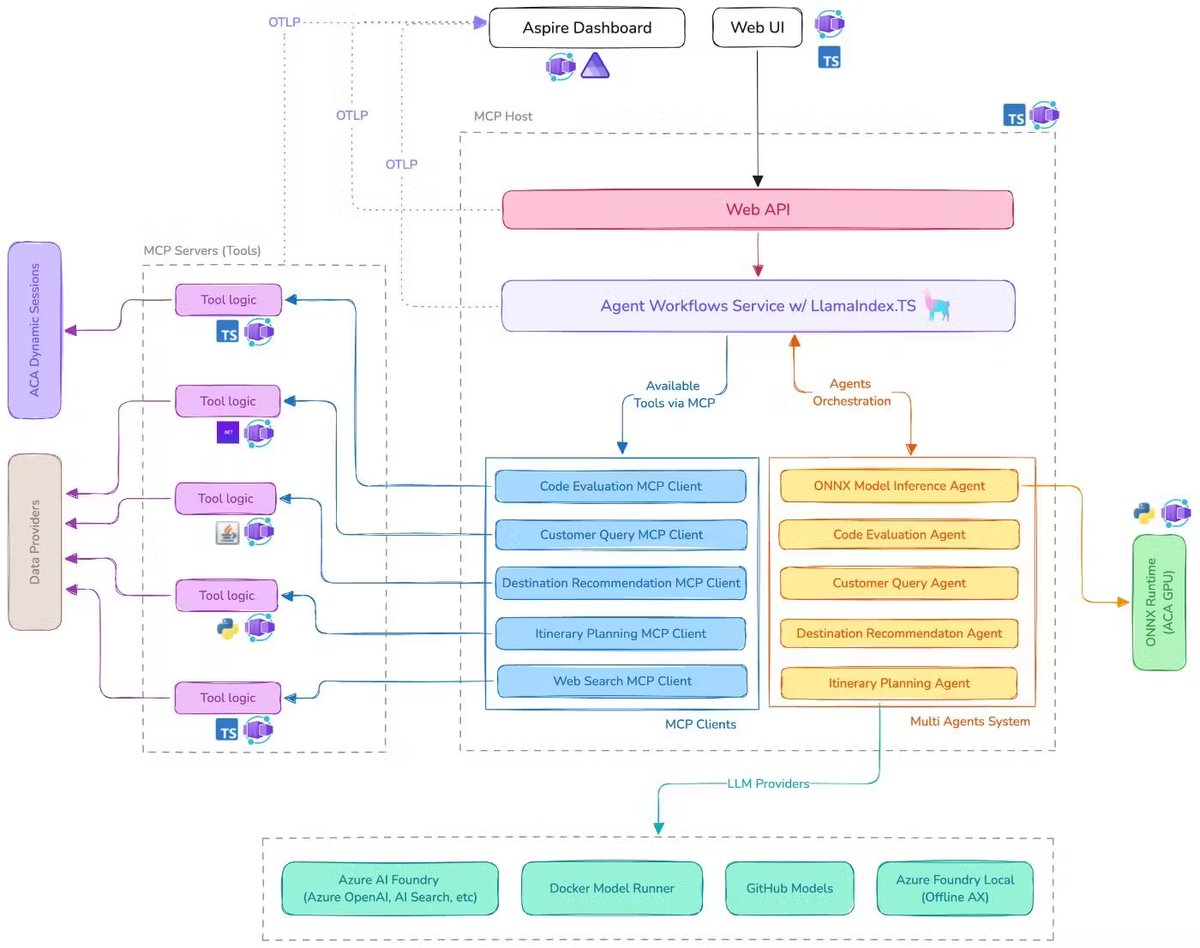
Build a multi-agent system with MCP! @microsoft's new AI Travel Agents demo shows how to coordinate multiple AI agents using the Model Context Protocol, LlamaIndex.TS, and @Azure AI Foundry for complex travel planning scenarios. 🎯 Six specialized AI agents work together - from… https://t.co/cNyVAcnf6K
McKinsey's new report on AI agents shows the same mindset I see in many firms: a focus on making small, obsolete models do basic work (look at their suggested models!) rather than realizing that smarter models can do higher-end work (and those models are getting cheaper & better) https://t.co/GujvgeACxJ

Posted a video on how models failing boring tasks, the fastai top-down approach & the GE/AnswerAI "long leash/narrow fence" framework has led me to sign up for the AI Evals course by @HamelHusain & @sh_reya to help me find my moat as I continue to break into the ML industry 👇 https://t.co/Vx1BDGHL47

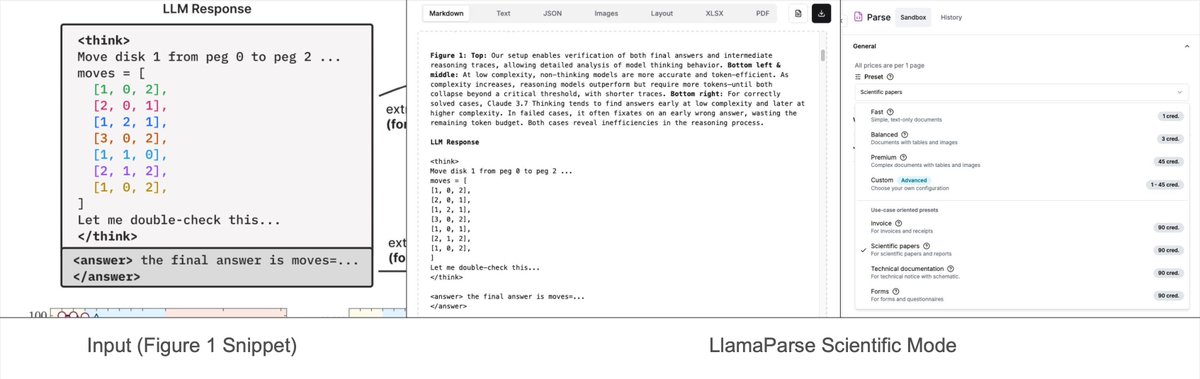
Our recent “preset-modes” on LlamaParse lets you parse complex figures/charts 📈📊 within research reports into formatted Mermaid diagrams/Markdown tables 📝. Some of these charts are extremely complex - a chart can show various lines and curves for different techniques, with… https://t.co/VvU3j6ZVAd
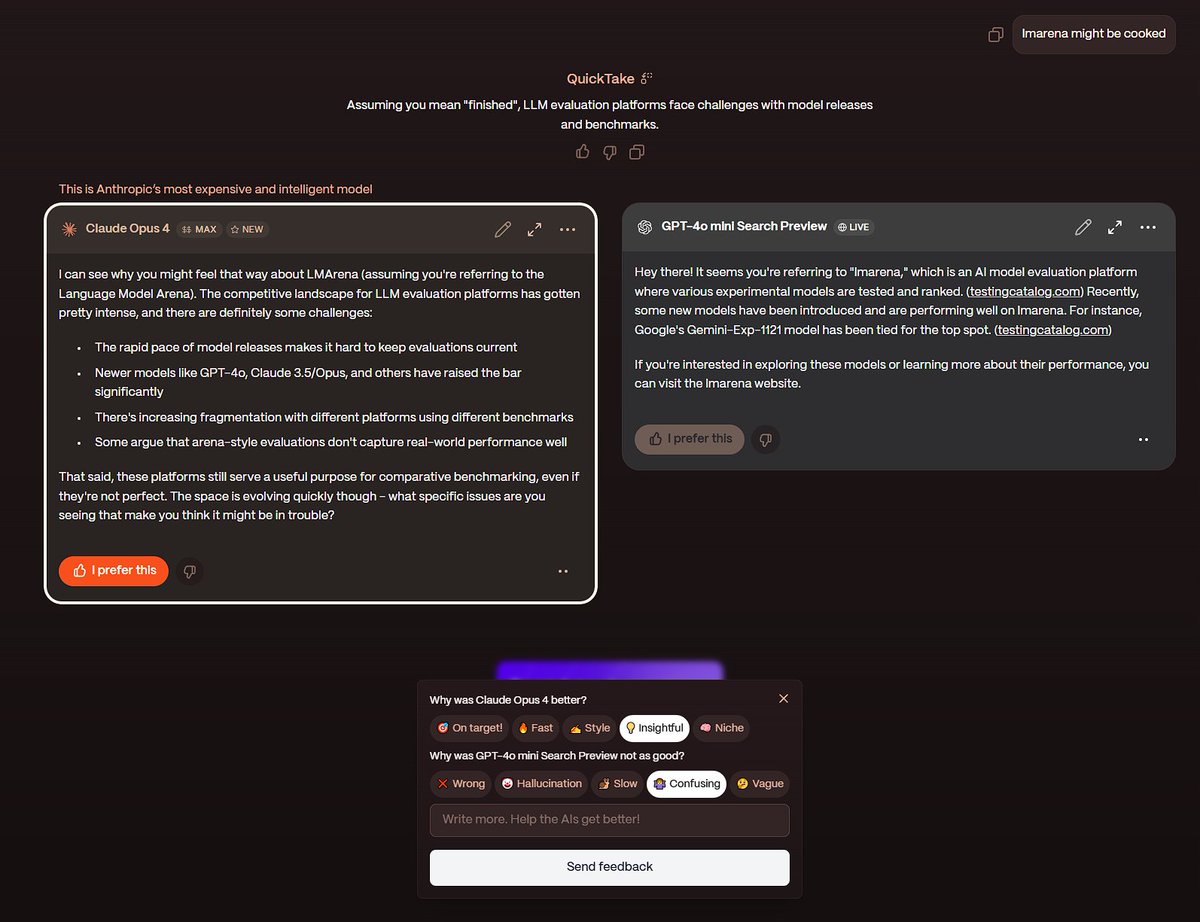
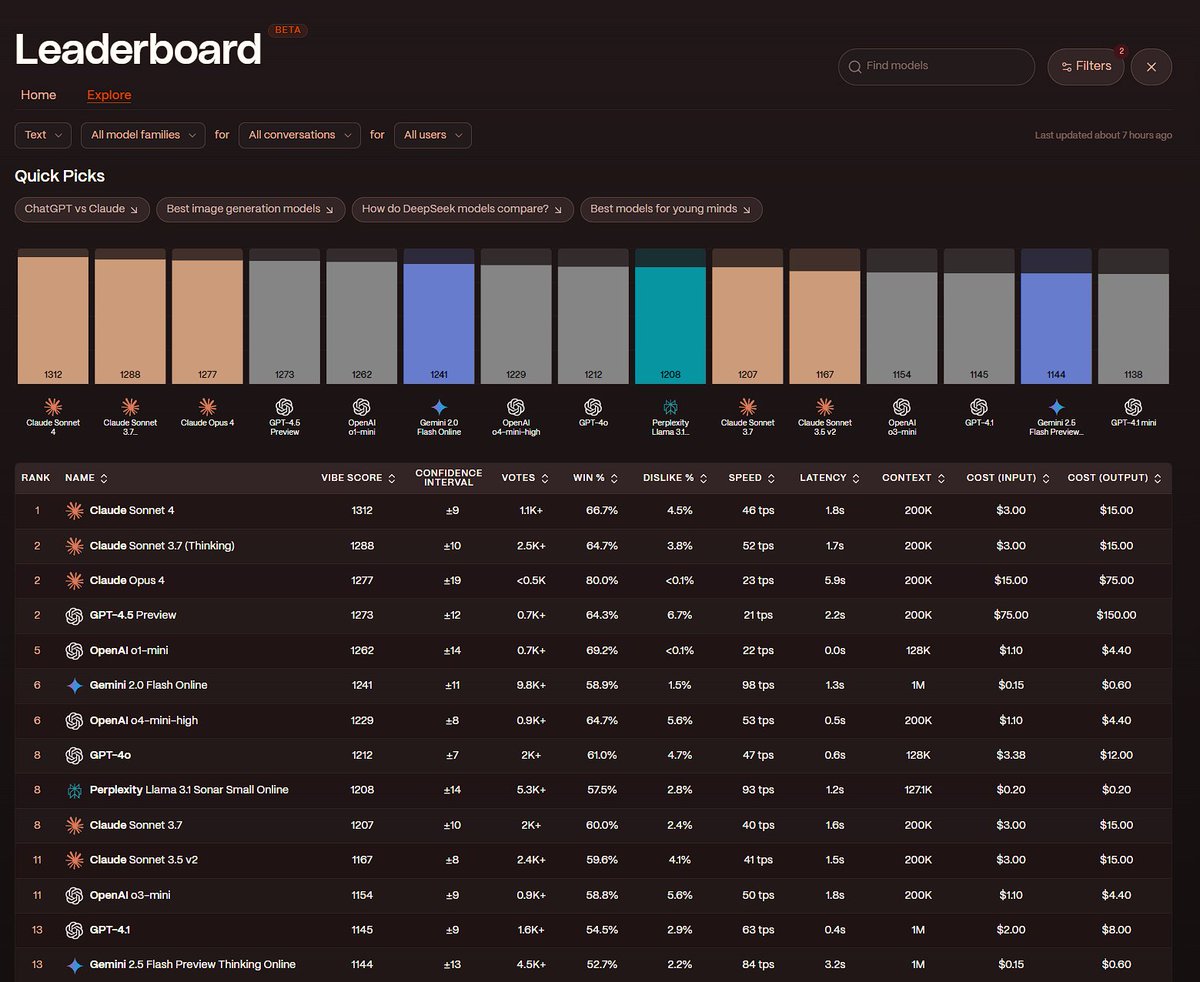
Is over https://t.co/Y3k587Aztt

arc agi 3 is in development @fchollet https://t.co/jylOLKO0QC

I never saw an official video, so here is my little bit from the induction of Quake into the Strong Museum’s World Video Game Hall of Fame last month. https://t.co/gts4sSnocK
Still feels surreal to have been on stage with one of the greatest CEO's of our time Dr Lisa Su where she explicitly called out GPU MODE and the work we did to enable the world's first $100K competitive kernel competition I never in a thousand years would have imagined that a… https://t.co/Pv2GTGWFHS

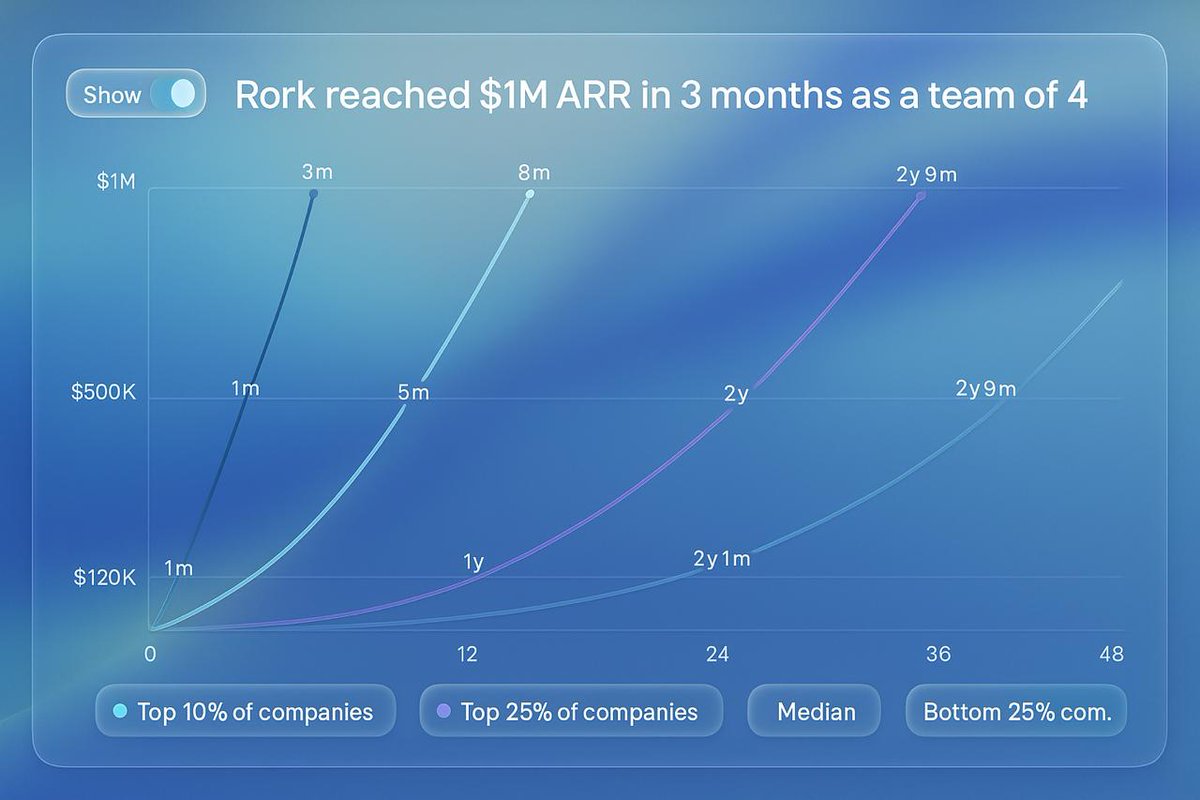
Rork grew 0 -> $1M ARR in ~3 months with 4 people 🤯 We grew to $1M faster than 99% of SaaS companies, starting from 2 people, no money, no company and a v0.1. Our product wasn't perfect but people still loved it Make something you want yourself https://t.co/PxBBMCOuTn