@iScienceLuvr
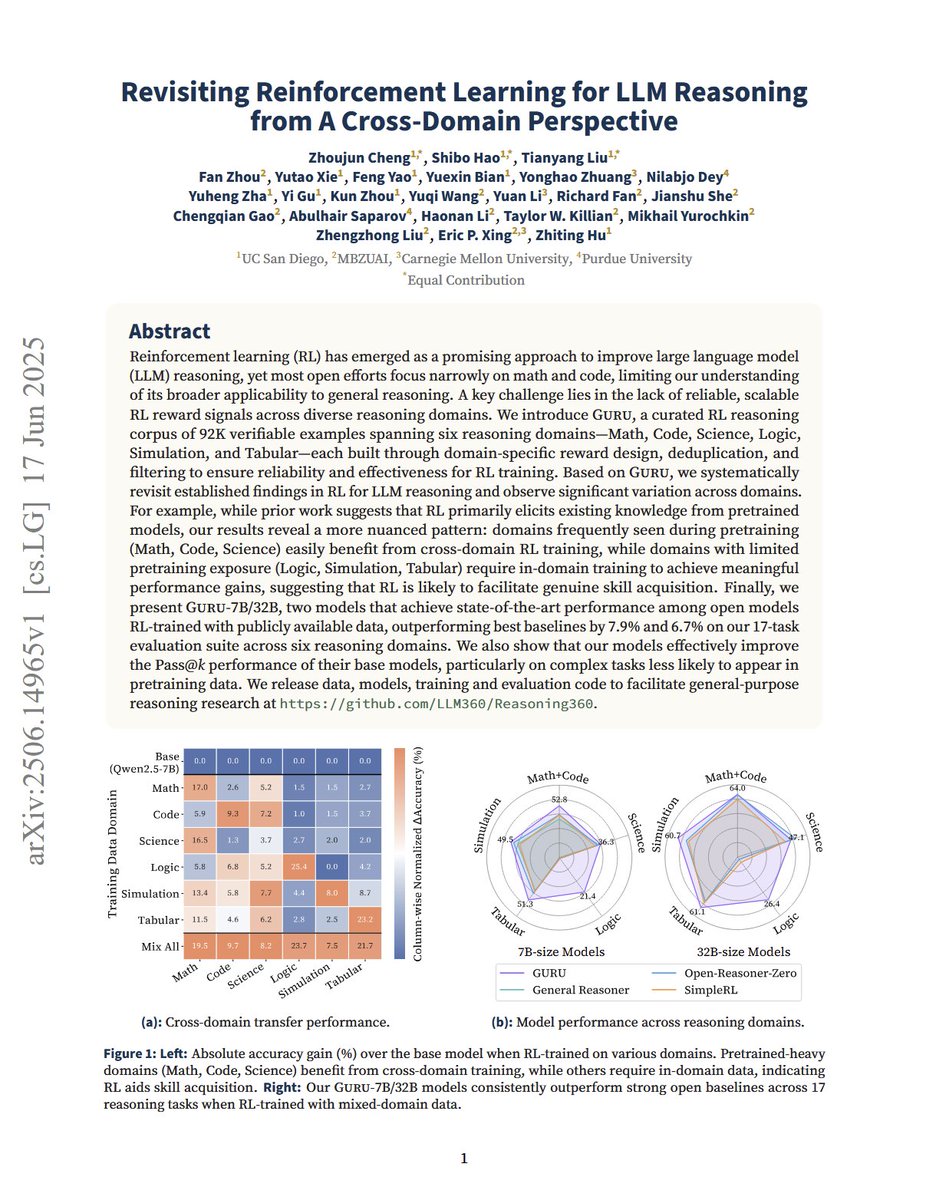
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective "We introduce GURU, a curated RL reasoning corpus of 92K verifiable examples spanning six reasoning domains—Math, Code, Science, Logic, Simulation, and Tabular—each built through domain-specific… https://t.co/Toc6SAkTXA