Your curated collection of saved posts and media
paper: https://t.co/RuxE0wo0W6

PlanBench-XL Evaluating Long-Horizon Planning of LLM Tool-Use Agents in Large-Scale Tool Ecosystems https://t.co/MRaAlMS4Id

paper: https://t.co/yvlfPuYCQn

*taps sign https://t.co/ayNJdwCTOf
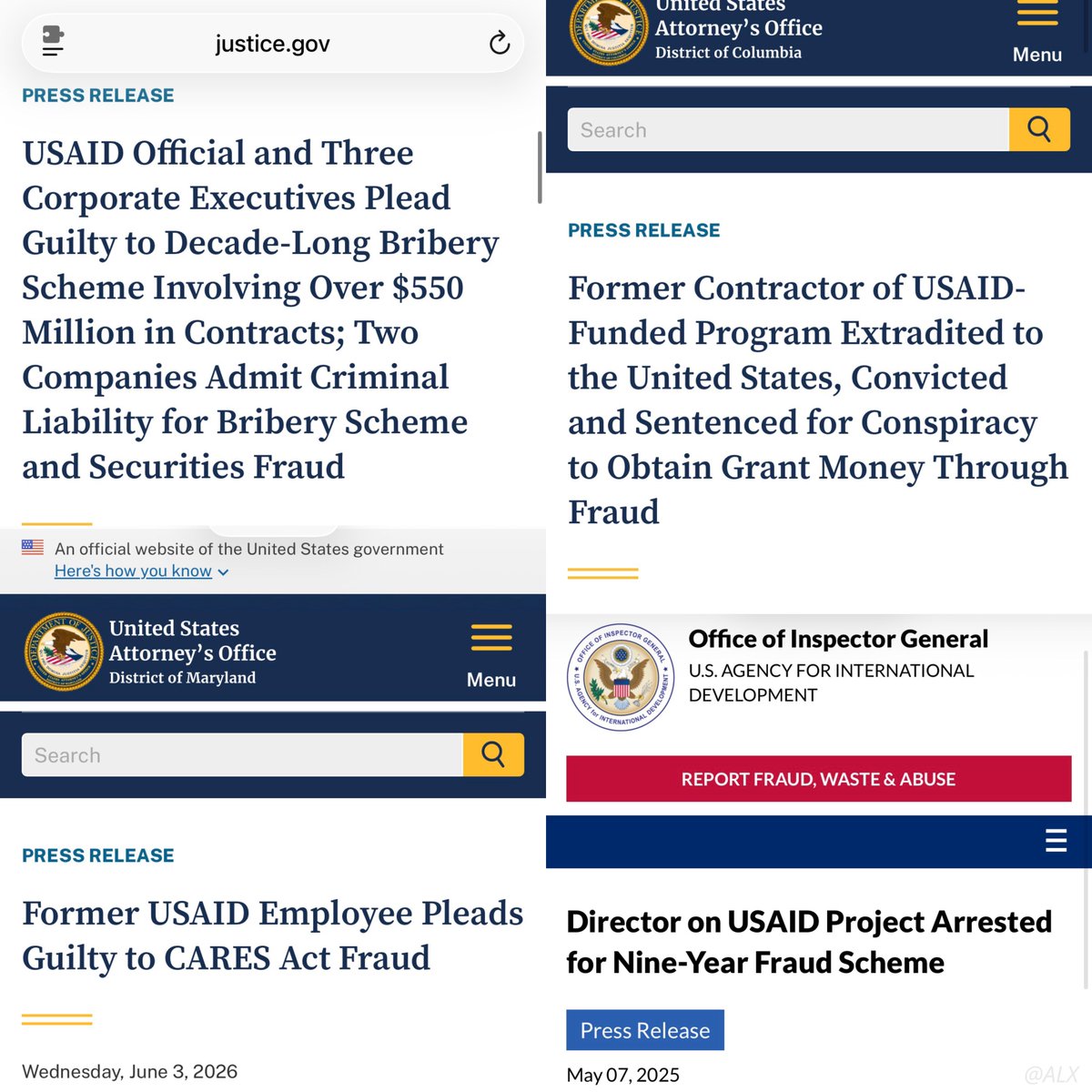
The standard applied by DOGE was very simple and easy: Provide contact information for the recipients of aid, so that we can confirm it is not fraudulent. The reality is that money was being sent to corrupt politicians under the guise of aid! Liars and stock insider traders li
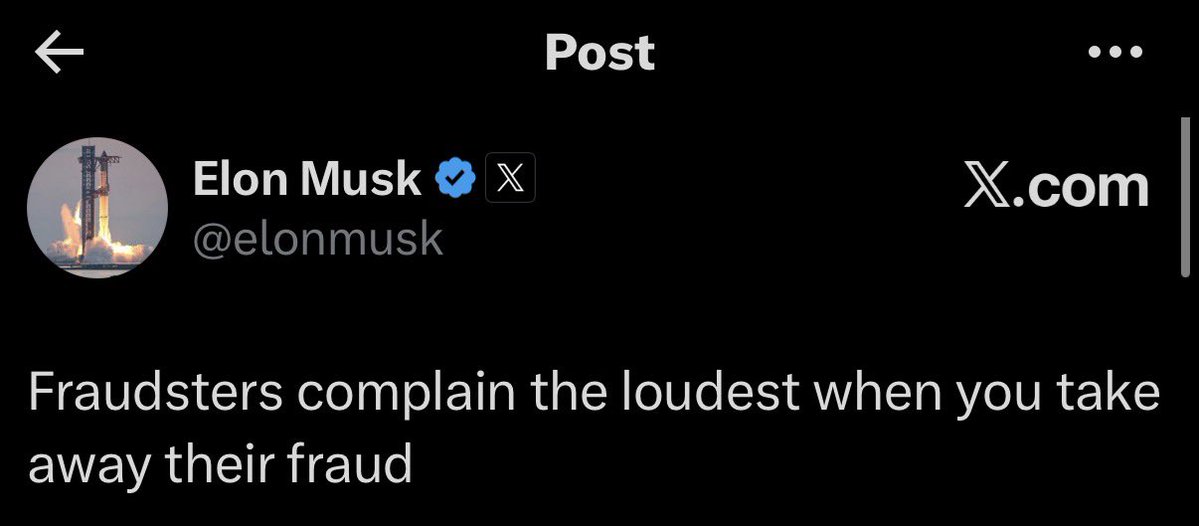
“There's no anti-White bias in in the legal system!” I think there is, mate. https://t.co/94W7WzyCNY
BREAKING: Starlink is helping power education for hundreds of girls in the Democratic Republic of the Congo. 🇨🇩 • School provides free education to 430 girls • Community programs reach 5,000+ people annually • Installed at the Malaika School in Lubumbashi • Supports digital learning and internet access for students The Education Minister Raïssa Malu visited Malaika School and Community Center where Starlink is being used to expand access to online learning.
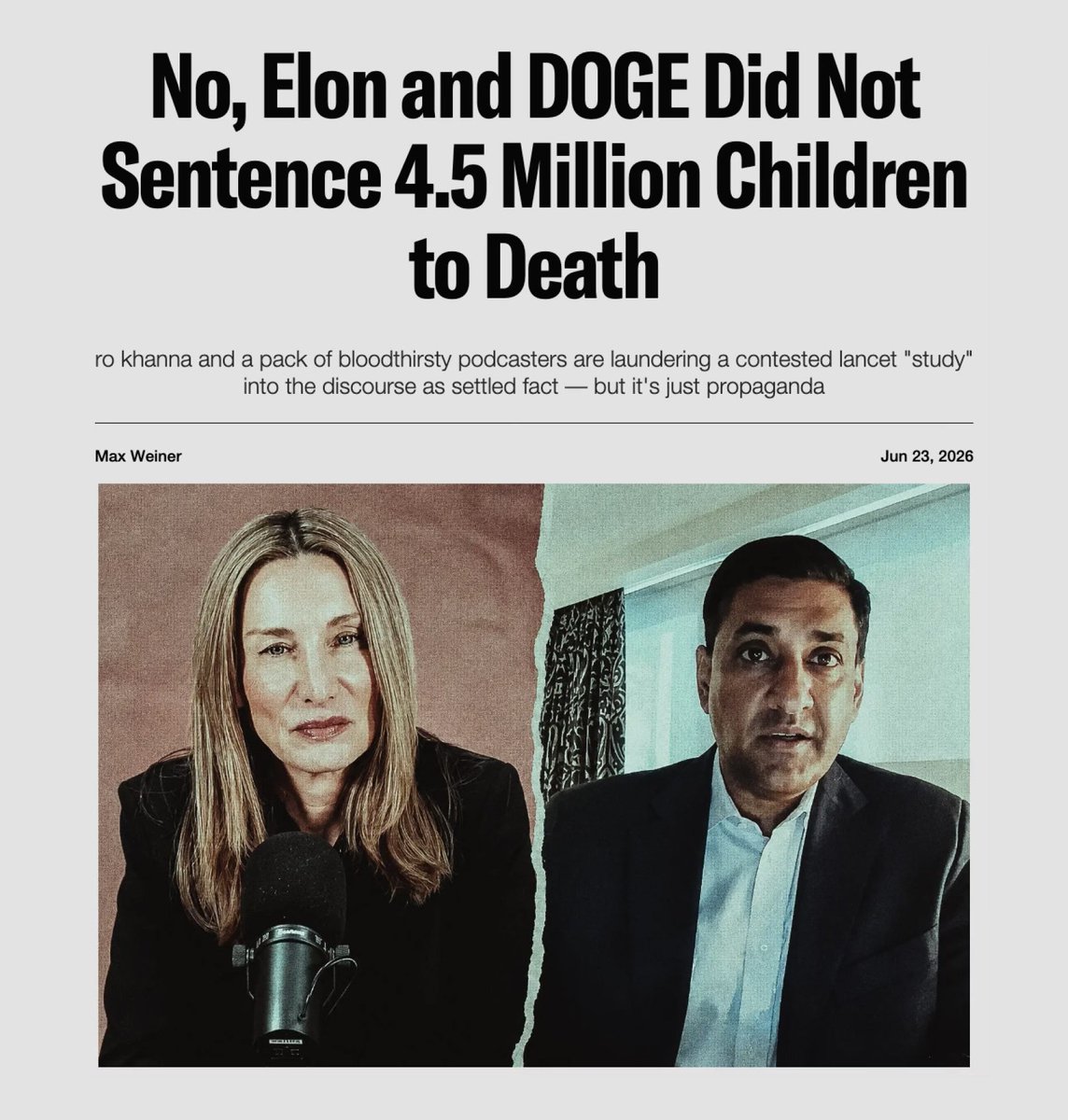
Saturday, Silicon Valley Congressman Ro Khanna sat down with left-wing podcaster Jennifer Welch — who previously cheered on those celebrating the murder of Charlie Kirk — to discuss the future of “progressive” governance. In a now viral clip, Khanna claimed Elon Musk “possibly sentenced to death” 4.5 million children by dismantling USAID, and demanded he be subpoenaed once Democrats retake power. The number traces back to a Lancet study published last summer projecting 14 million deaths by 2030 from USAID cuts. But the study assumes a fake world: one where DOGE’s cuts stay frozen through 2030, where the State Department’s lifesaving waiver doesn’t exist (it does), where Congress never refunds AIDS relief (it did), where two decades of clinics and supply chains vanish the second a grant lapses. It also conveniently ignores some former USAID functions (like funding gain-of-function research at the Wuhan Institute of Virology). Meanwhile, NYU statistician Aaron Brown notes the study credits USAID with preventing 11 million more deaths than the entire global mortality decline over two decades. @planetmaxwell interrogates the claim that Elon and DOGE single-handedly killed millions of children, and explains why Silicon Valley’s congressman is now laundering this as settled fact (when it’s really just propaganda). Full story 👇
And here are some fantasy maps and diagrams. https://t.co/s0IUh7Ofk6
you can download them now from Huggingface: - https://t.co/KcCsO5EiVq - https://t.co/8YBTF8MI6J


you can download them now from Huggingface: - https://t.co/KcCsO5EiVq - https://t.co/8YBTF8MI6J


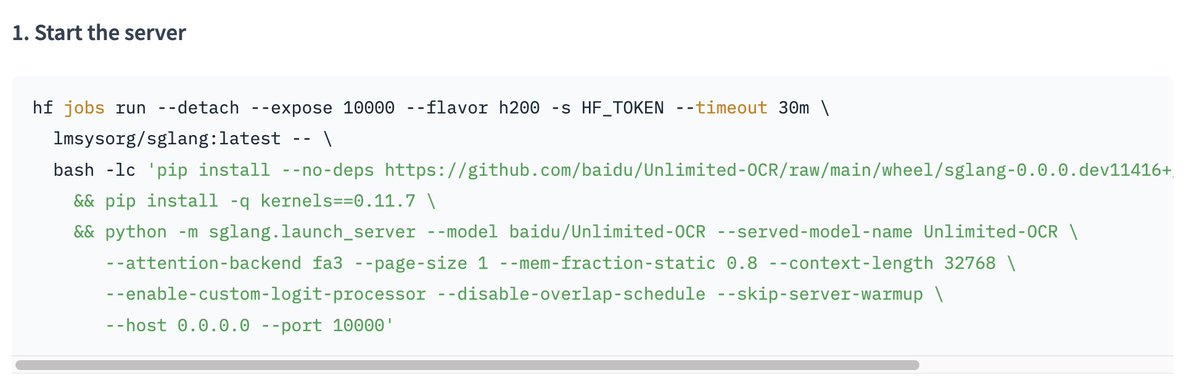
It's raining OCR models again! @Baidu_Inc's Unlimited-OCR is one of the more interesting. You can try it without much effort via a throwaway GPU endpoint on @huggingface Jobs (which recently added port forwarding support) with one command It's OpenAI-compatible, your HF token is the API key, and --timeout makes it self-destruct so you can't leave a GPU running by accident Once it's warm, it's quick and @sgl_project batches concurrent requests, so an agent can boot the model, fire a big async batch at it (say, a whole bucket of newspaper scans), then cancel it. I pointed it at the front page of a 1901 newspaper, "The Commoner" + 6 PDF pages in a single request: tables came back as HTML, equations as LaTeX, figures with captions, reading order preserved across pages. Docs here: https://t.co/mApuKalqSN

Perplexity users, this one's for you. The Ramp MCP is live and brings you 50+ tools to bring all your Ramp data right into your research workflow. Try it out: https://t.co/tXtWO3WMsX https://t.co/KBqFVtBK5t
ever since i was a little girl i knew i wanted to computer https://t.co/iOHK59SO2A

ever since i was a little girl i knew i wanted to computer https://t.co/iOHK59SO2A

https://t.co/IjYzhdQvkq
Post your best codex billboard

https://t.co/IjYzhdQvkq

@jxnlco https://t.co/08eQxMpLRy

@jxnlco https://t.co/08eQxMpLRy

Falcon 9 launches the Starfall Demo mission from Florida https://t.co/Pkh9HiKj1e


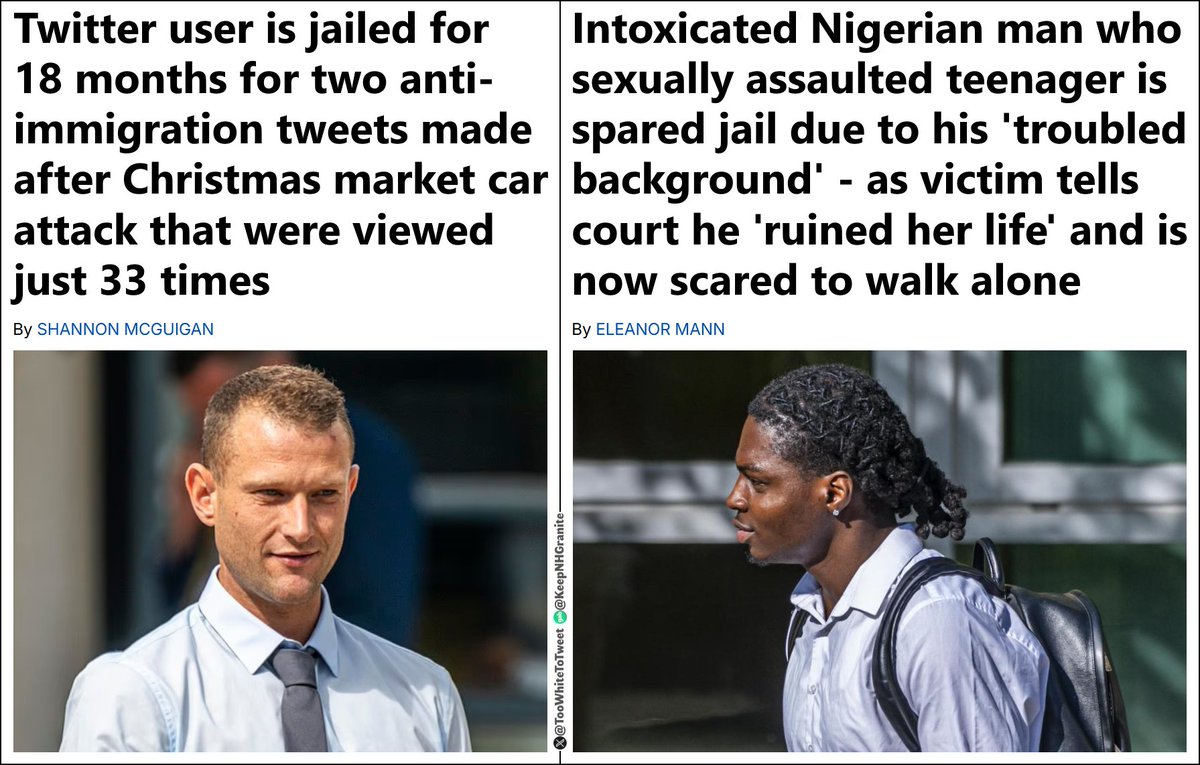
Riddle me this, @RoKhanna. If closing USAID could cause so many child deaths in Africa, why would the African Union's top diplomat in DC celebrate USAID's shutdown? Does she like dead babies? Is she ignorant? How else do you explain her arriving at the same conclusion as DOGE? https://t.co/fNVzT1FElM
This is the real reason they’re mad at Elon Musk and DOGE for shutting down USAID. https://t.co/Tyw10xBM6J
🔥 Two days. Hundreds of #AI practitioners. One community. #PyTorchCon North America is coming to San Jose, California, October 20-21. Register by July 31 to save $400 & join the conversations shaping #OpenSource AI. 🎟️ https://t.co/AVHdaIFT20 https://t.co/34wK6B9hyD
The Keras team is gonna be at the AI Systems DevLabs in Sunnvale tomorrow. Come say hi if you're around! https://t.co/tHtGXd53fC

For our free newsletter this week, we write about the humanoid robot safety race. @IrenaCronin and I write this newsletter every week. Humanoid robots are moving closer to real-world use, but safety will matter more than impressive demos. To be trusted in factories, warehouses, hospitals, and public spaces, robots need strong testing, safety software, clear standards, and predictable behavior around people. The companies that prove their robots can operate safely and reliably will have the real advantage. Read and subscribe: https://t.co/HHwYy7NoAl

1-bit GLM-5.2 GGUF vs. Claude 4.8 Opus vs. GPT-5.5 We gave 3 models the same prompt and compared one-shot outputs. The 1-bit GLM-5.2 GGUF ran locally on a Mac Studio M3 Ultra with 256GB RAM at ~21.6 tok/s. Which output do you like best? GGUF: https://t.co/BMkxswdj5N https://t.co/UoXsCSh4Gn
GLM-5.2 can now be run locally!🔥 The 2-bit model retains ~82% accuracy after we shrunk it from 1.51TB to 238GB (-84% size). Run on a 256GB Mac or RAM/VRAM setups. GLM-5.2 is the strongest open model to date. Guide: https://t.co/bI7FeeKHDd GGUF: https://t.co/BMkxswdj5N https:/

Live Stream: Welcome to open source AI Lots of new folk are starting out on their journey with open models. Come join our livestream with all your questions about local models, open coding agents, and owning your AI. Thursday 8am PST/ 5pm CEST HF X and YT https://t.co/UlLUTXrsZb

Today’s mission includes a demo of a new vehicle that will enable affordable, routine access to the microgravity environment for scientific research and in-space manufacturing. After demonstrating controlled flight, the spacecraft will splash down in the Pacific Ocean https://t.co/NLwhigtSWC

Microsoft Teams just crossed a line I did not expect this year. It now runs an AI employee that does the work, not one that answers questions. Here is what is new: https://t.co/XyNjkfSuly
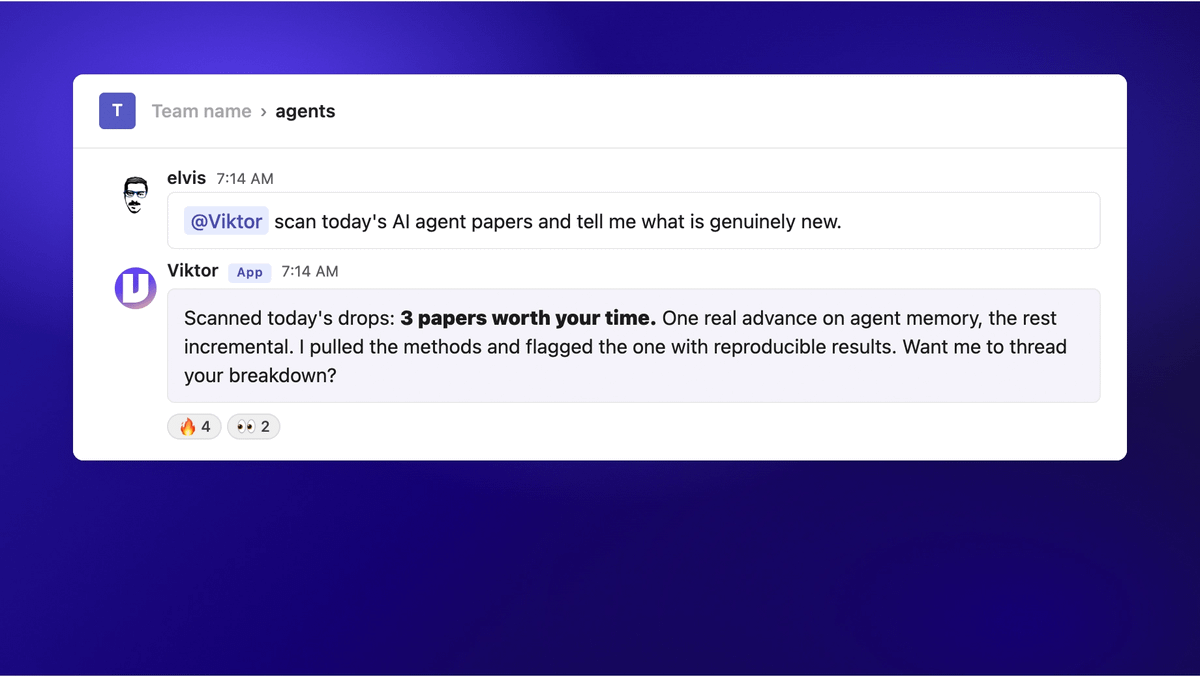
Here is the part most people have not seen. Once it is in your Teams or Slack workspace, it starts coming to you. It remembers what our team has already done, understands what we are working toward, and moves before every instruction is spelled out. Screenshot below. https://t.co/xZSsq8Hg8Z
