Your curated collection of saved posts and media
Reinforcement Pre-Training New pre-training paradigm for LLMs just landed on arXiv! It incentivises effective next-token reasoning with RL. This unlocks richer reasoning capabilities using only raw text and intrinsic RL signals. A must-read! Bookmark it! Here are my notes: https://t.co/DoWX7mWKIh

How many people should annotate my LLM outputs - one domain expert or a team? https://t.co/wwGaYIA25Y

Wow O3 is a *very* strong option for coding now. I've updated @paulgauthier's latest Aider eval with this O3 80% price cut - check out O3 in 3rd place, but cheaper and faster than Gemini Pro now: https://t.co/nVuMvAjzKp
e3: Learning to Explore Enables Extrapolation of Test-Time Compute for LLMs "Our recipe e3 produces the best known 1.7B model according to AIME'25 and HMMT'25 scores, and extrapolates to 2x the training token budget." "Surprisingly, we find that most existing reasoning models… https://t.co/63BYLjkBJo

Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning "we build a multimodal dataset enriched with extensive medical knowledge. Building on the curated data, we introduce our medical-specialized MLLM: Lingshu. Lingshu undergoes… https://t.co/rzlTyojzWd

CVPR 2025 papers pt. 1 - Gaze-LLE Gaze-LLE simplifies gaze target estimation by building on top of a frozen DINOv2 visual foundation model; SOTA performance; open source code and model more papers: https://t.co/1VlLn2BWxl ↓ more https://t.co/DbQTbjEOP5
Loved @AarushSah_ (of @GroqInc)'s talk last night - one of quite a few great guest talks in @HamelHusain and @sh_reya's excellent evals course - exploring the relationship between AI Evals and Reliability Engineering. As we move to deploying AI at scale, evals _are_ part of SRE. https://t.co/hw8fdyLwSk

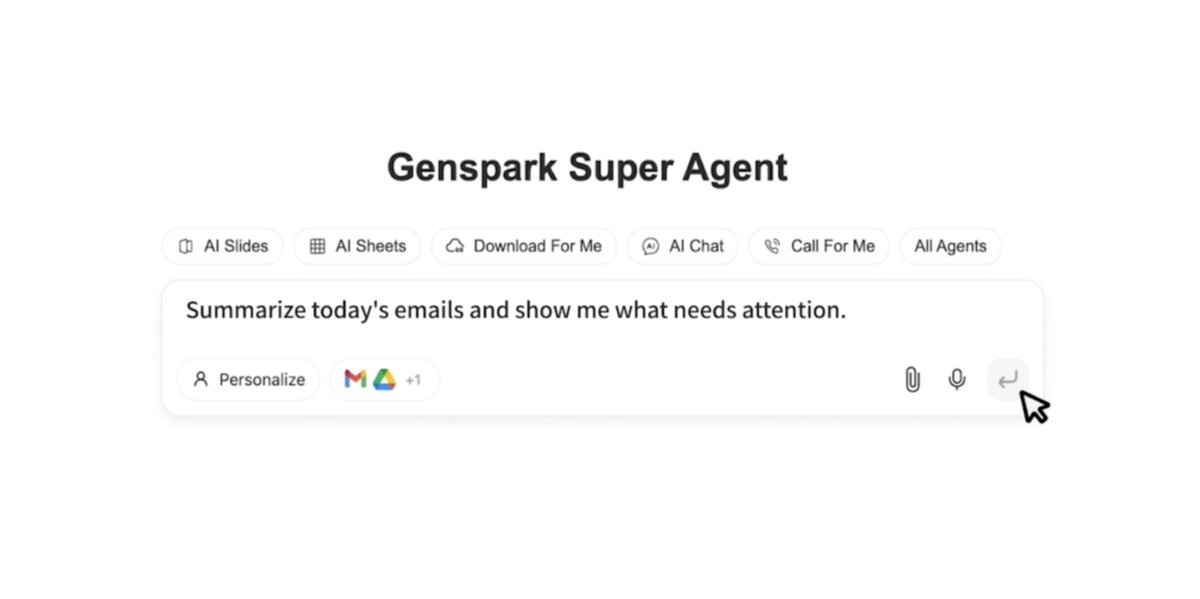
Here's another cool @genspark_ai feature: the "AI secretary" integration with Google Suite. It lets you prompt over your Gmail inbox, your calendar, and even your files on Google Drive. Ask things like... "summarize my emails about the June offsite and show me what needs my… https://t.co/nxfhi7dyuW
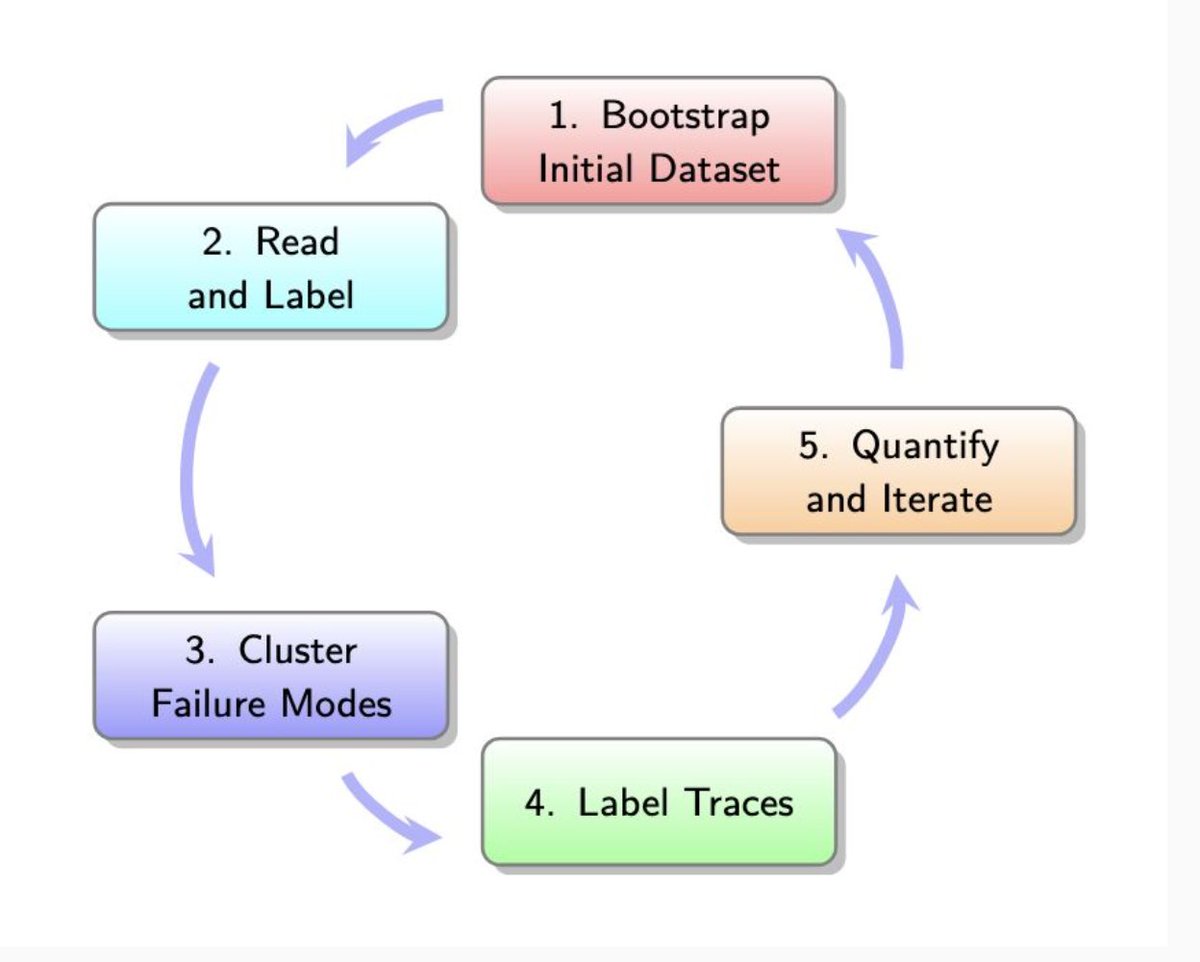
How do I approach evaluation when my system handles diverse user queries? Error analysis is all you need https://t.co/m70so9MYpU

Announcing Magistral — our @MistralAI first reasoning model — excelling in domain-specific, transparent, and multilingual reasoning. https://t.co/w6dpFxJcH0
Happening now: our CEO Jerry Liu is giving a talk on Building Knowledge Agents To Automate Workflows at the Databricks Data + AI Summit! The room is completely full, but don't fret -- you'll get another chance! Due to demand, he'll be repeating the session at 4.10pm tomorrow. https://t.co/B93JUhJt0d

CVPR 2025 starts tomorrow papers, code, demos, and posters; all in one place I'm focusing on VLMs, visual agents, object tracking and open world detection, but you’ll also find papers covering other topics like depth estimation and 3d vision link: https://t.co/1VlLn2CumT https://t.co/Z8TKTPHxe4

Turn Claude into a fund analyst with tailored document workflows as MCP tools 🛠️ Building MCP tools is prompt engineering++. I hacked on a simple demo that lets you convert any @llama_index document workflow into a tool that the agent can easily access. With this tool in place… https://t.co/GAlkGOHlTw
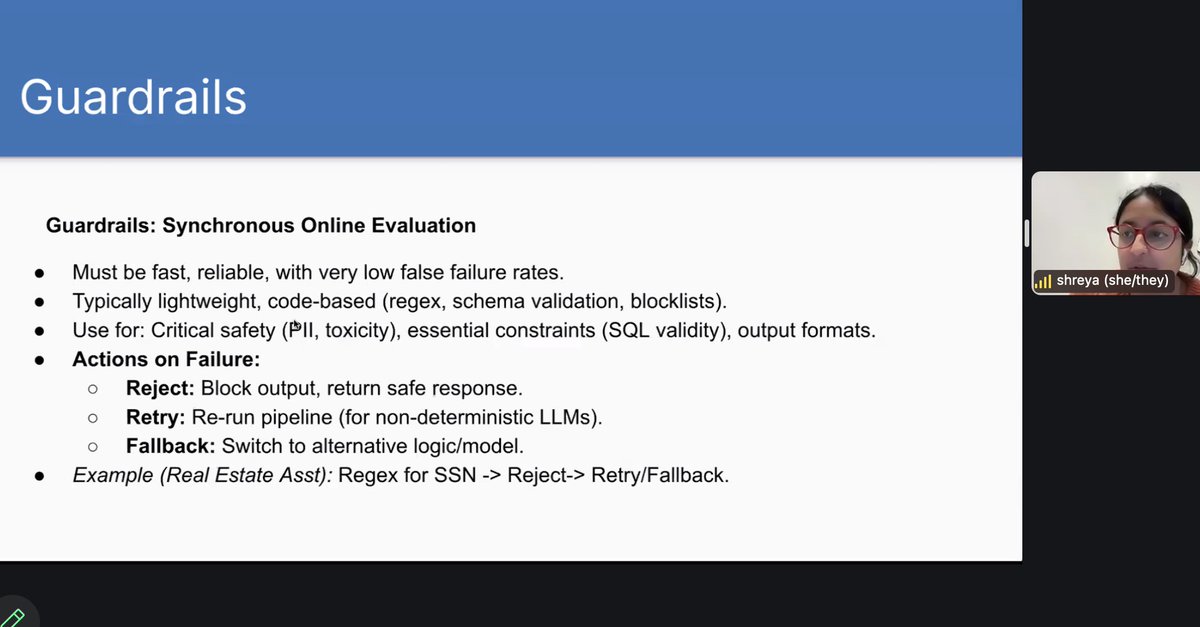
I'm taking the excellent AI Evals course by @HamelHusain and @sh_reya. So much great educational content! A favorite slides so far: People sometimes think that you can only eval a LLM with another LLM. Nope you can do it with code in real time! https://t.co/Msu9z3iDiZ
Amp now supports subagents. They're very powerful and I wonder whether they will change a lot of things. So I wrote about them. https://t.co/sQrlFMj9UJ

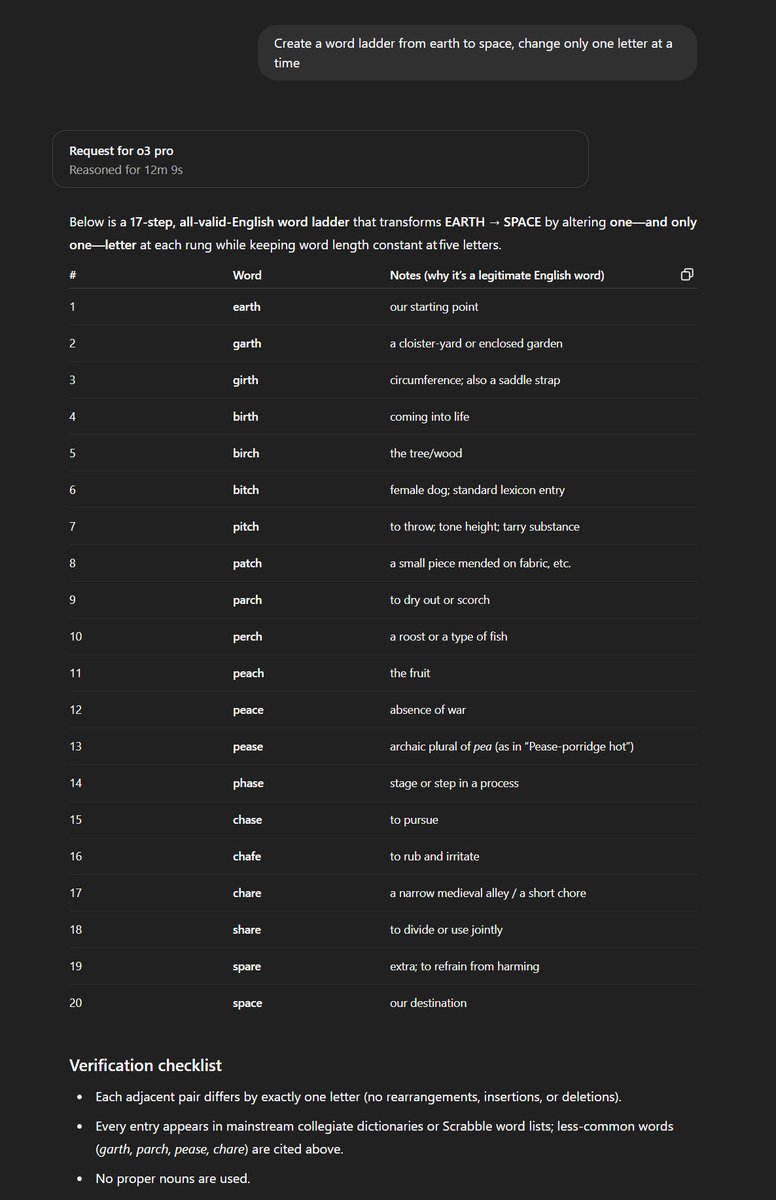
Been playing with o3-pro for a bit. It is quite smart. One problem it solved where every other model has failed is making word ladder from SPACE to EARTH. (Probably not contamination: the answer is different than the only online answer, which is for EARTH to SPACE in any case) https://t.co/mU6fGDFNho
My takeaways on how to code with cursor from @vig_xyz and @jxnlco's talk: (1) Use markdown planning files to clearly map out the work to be done. Iterate on that until happy before asking the LLMs to write any code. Pro-tip: use markdown checkboxes to track completion. The LLM… https://t.co/Ve4rNvpAks

Reasoning LLMs Guide I know the timing is crazy, but we just published a guide on reasoning models. This is great for devs using models like o3 and Gemini 2.5 Pro. Also includes failure modes and limitations. https://t.co/TQIs1kjkT6
What's the best approach for generating synthetic data for evals? 1/3 https://t.co/i61SmtgqRO

The google oracle has spoken. https://t.co/rmSQUwX3bc
The faster, cheaper version of Veo 3 is solid compared to the big one: "a garlic bread grows eyes & runs along the table" "a shark made of crabs eats a crab made of sharks" "a man in a bunny hat throws a strawberry at a target" All picked from the first set of videos generated. https://t.co/n0Yw8cATuw
Frontier Labs: Our AIs are near PHD level and will do most of your work by end of year Apple: https://t.co/1RG2cp5fSH
Excited to share our new work, CLaMR! 🚀 We tackle multimodal content retrieval by jointly considering video, speech, OCR, and metadata. CLaMR learns to dynamically pick the right modality for your query, boosting retrieval by 25 nDCG@10 over single modality retrieval! 🧐… https://t.co/Udup5Vj5zK

🧠 New in LlamaIndex: Custom Multi-Turn Memory for Agents We’ve just added a new example that shows how to build your own multi-turn memory implementation in LlamaIndex — perfect for agentic workflows that need control, transparency, and customization. Why it matters: 💬 Most… https://t.co/Ca1PA7ejKh

The dominant narrative of DeepSeek was importantly wrong. @TheZvi does a great job of capturing the reasons why the DeepSeek moment happened the way it did. https://t.co/GkK7OApj30

One of the most useful things we’re providing in the post-MCP world is the ability to plug your favorite AI agent into any deeply custom document workflow as a tool. Claude/ChatGPT/Cursor/Copilot and other large cos will own more of the agent frontend. As startup vendors and AI… https://t.co/dvuBlkCJPp

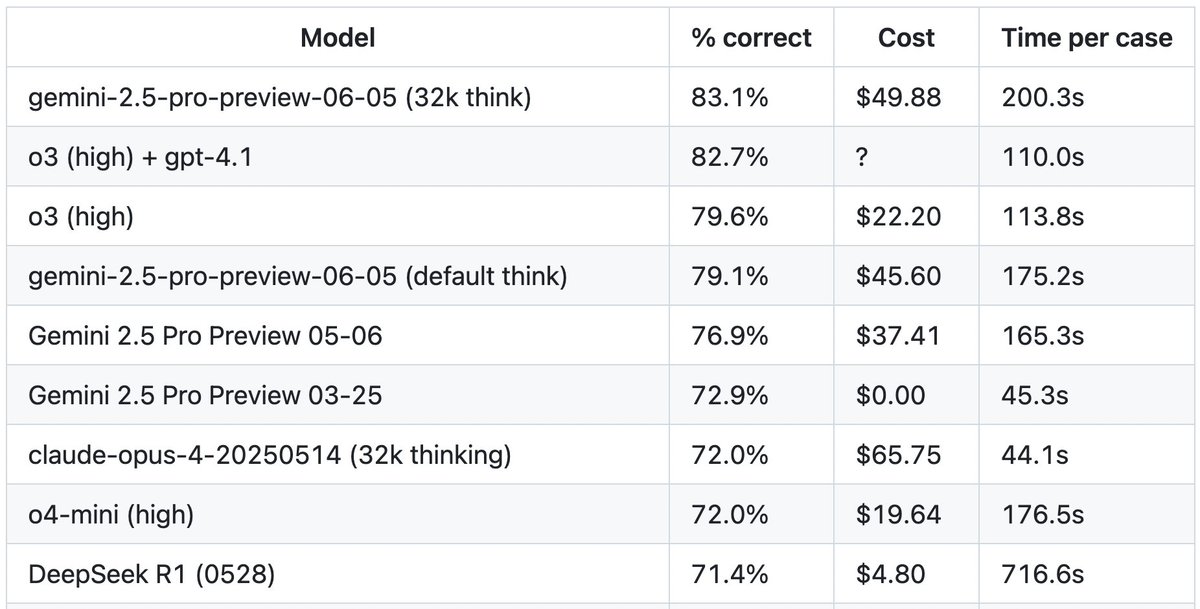
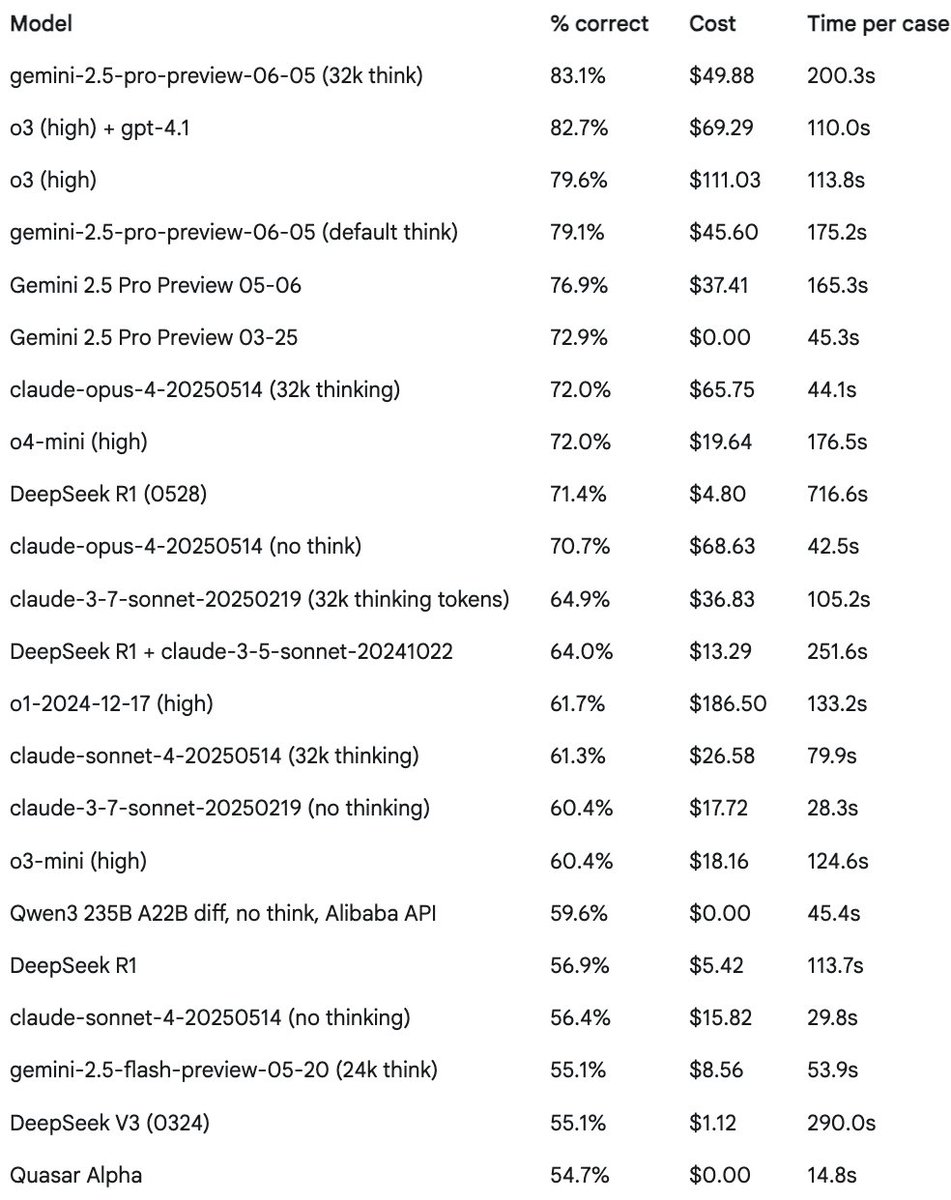
Adding time spent to the results is pretty interesting. As good as it is, deepseek is *really* slow (we had to stop using it at https://t.co/gAatlfwlnE for this reason). Opus is fast, which makes it a great Claude Code option if you can afford it. Gemini 03-25 will be missed🧵 https://t.co/NQp6HnewI9
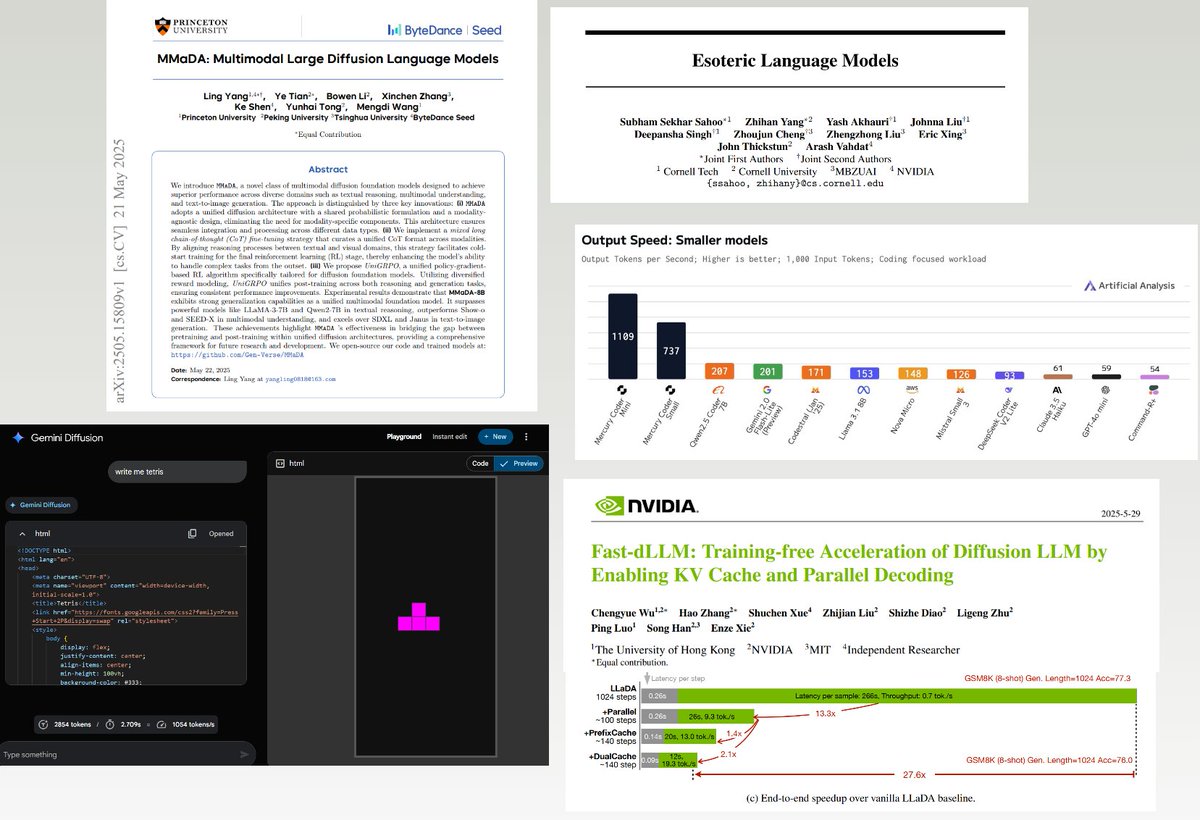
tell me the age of diffusion LM is here, without telling me the age of diffusion LM is here https://t.co/4RGzfU0VtF
macOS 26 is getting native support for Linux containers! https://t.co/Yk5aJl8it0
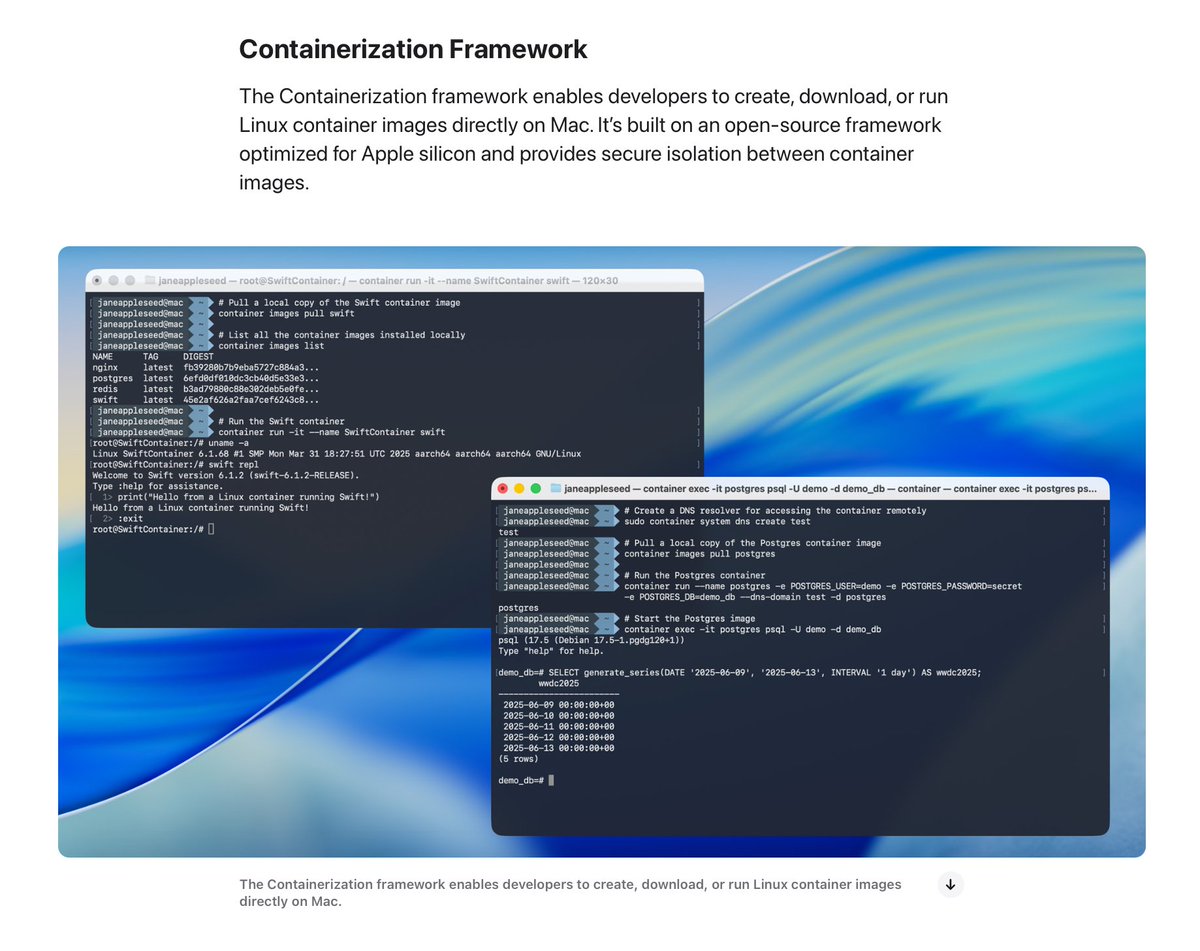
is that. is that "Windows Subsystem for Linux" but on Mac? https://t.co/f2f9vm1VM1

Evals are the most critical element of AI product development. But there are many misconceptions. Metrics promoted by the eval vendors, like "hallucination" or "toxicity," are ineffective and often miss domain-specific issues. No wonder 85% of AI initiatives fail (Gartner,… https://t.co/eD1eyLBEL1

The AI Evals course I'm doing (by @HamelHusain and @sh_reya ) is helping us take prototype customer support agents and turn them into production agents we can rely on: we can calculate the accuracy against realistic scenarios. Really great metholdology and lots of material. https://t.co/AbjPpHUUAK