Your curated collection of saved posts and media
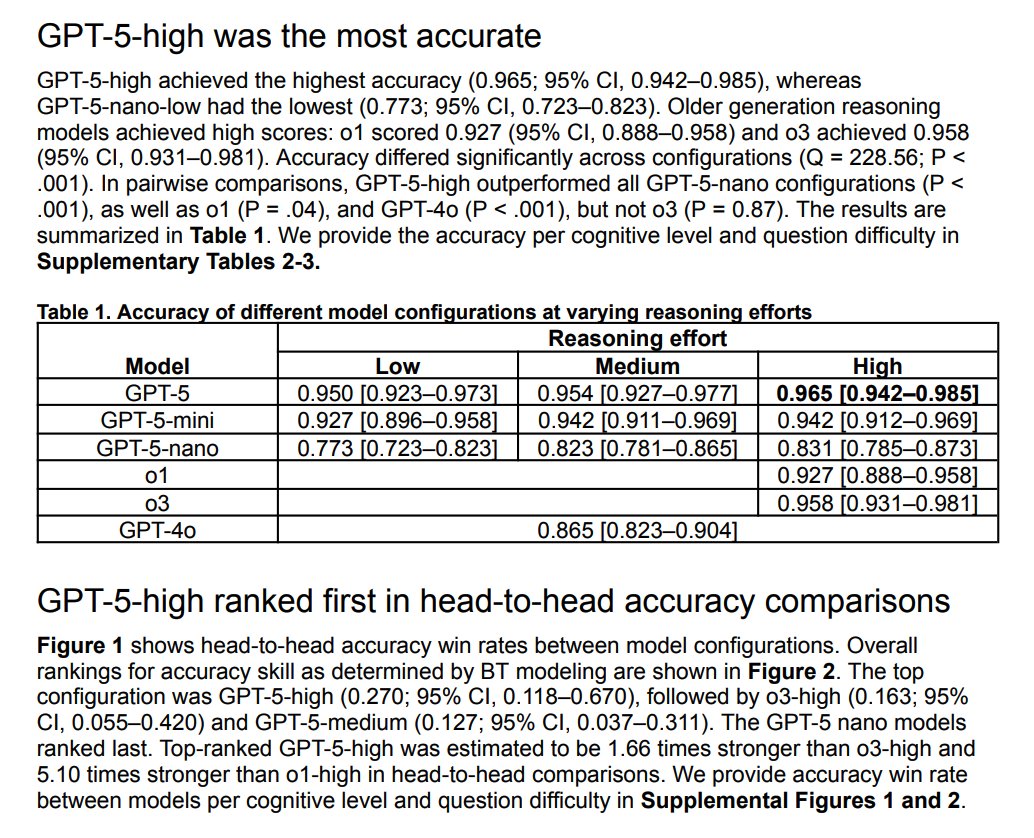
GPT-5 (with high reasoning effort) achieves near-perfect accuracy on a high-quality ophthalmology question-answering dataset. Based on these other reports, GPT-5 seems to be a very strong model at medical reasoning. https://t.co/asKCWMBwVh
Speed Always Wins Very nice and comprehensive new report on recent efficient architectures for LLMs. https://t.co/X1VRpLj2kN

Paper: https://t.co/BTjJkW9zHA https://t.co/sv4wAULSwN


The way we develop AI agent applications is changing, see an example of how we vibe-code a UI for extraction agents 👇 Turn LlamaExtract agents into @streamlit web apps using AI-assisted "vibe coding" with Cursor. In this example, we transform an invoice extraction agent into an easy to use web-app. 📝 Use our sample cursor prompt that instructs the AI assistant on what to build, our requirements, and sample data. 🚀 Completely transform from basic scripts to full Streamlit applications 📊 Integrate with LlamaCloud to create and deploy extraction agents based on your pre-defined schemas 💡 Sample data and schemas included so you can immediately start building your own document processing applications This repository demonstrates our approach to rapid AI-assisted development - start with a working script, use natural language prompts with coding assistants like Cursor/Claude, and iteratively build production-ready applications. Check out the complete vibe coding example and get started: https://t.co/XaKuTUdbcN
An exciting new paper proteomics paper describes novel insights on protein-disease mechanisms by using @seer-based MS combined with genomic data on the Genes & Health cohort. From the abstract by Maik Peitzner, Claudia Langenberg and colleagues: "... we idenIfy >1,200 significant variant-protein associations (n=895 cis-protein quantitative trait loci (pQTL)), half of which are novel. [...] consolidate a potential role of 21 proteins in the pathology of 44 diseases: e.g., a novel role of high IGLV3-21 in the development of Grave’s 36 disease elucidating B-cell mediated autoimmunity."

Office hours from the latest session. https://t.co/91XrRjxR2w

Office hours from the latest session. https://t.co/91XrRjxR2w

Some signs that catching up in the AI model space is rapidly becoming challenging for even the most highly capitalized companies. https://t.co/dj9ivbXVpF
BREAKING: Apple prepares ambitious AI devices comeback with multiple robots, smart speaker with a screen, lifelike version of Siri with conversational abilities, redesigned Siri, new Home OS, major home security push & more. Details on the plans here — https://t.co/KsQIrKl4w

Meta releases DINOv3 Everyone talks about Llama but I think Meta's contributions to computer vision (SAM, DINOv2, etc.) are highly underappreciated. They're now releasing a newer iteration with large model (7B param), better data curation, and improved dense features. This is sure to be the foundation for many computer vision use-cases going forward.
Introducing DINOv3: a state-of-the-art computer vision model trained with self-supervised learning (SSL) that produces powerful, high-resolution image features. For the first time, a single frozen vision backbone outperforms specialized solutions on multiple long-standing dense p

Decentralized Aerial Manipulation of a Cable-Suspended Load using Multi-Agent Reinforcement Learning https://t.co/izRATDkpnU
discuss with author: https://t.co/CnkN6kDzqL

Story2Board A Training-Free Approach for Expressive Storyboard Generation https://t.co/odZyRPE4SO

discuss with author: https://t.co/KQdtJUTJSc

Mol-R1 Towards Explicit Long-CoT Reasoning in Molecule Discovery https://t.co/vVKhZHYPp1

discuss with author: https://t.co/CYDzCuBA0z

EngiBench A Framework for Data-Driven Engineering Design Research https://t.co/9lTi7UfALc
discuss with author: https://t.co/JbV3dVxVIR

Seeing, Listening, Remembering, and Reasoning A Multimodal Agent with Long-Term Memory https://t.co/stSrINaYLN
discuss with author: https://t.co/1Kx5w2flUc

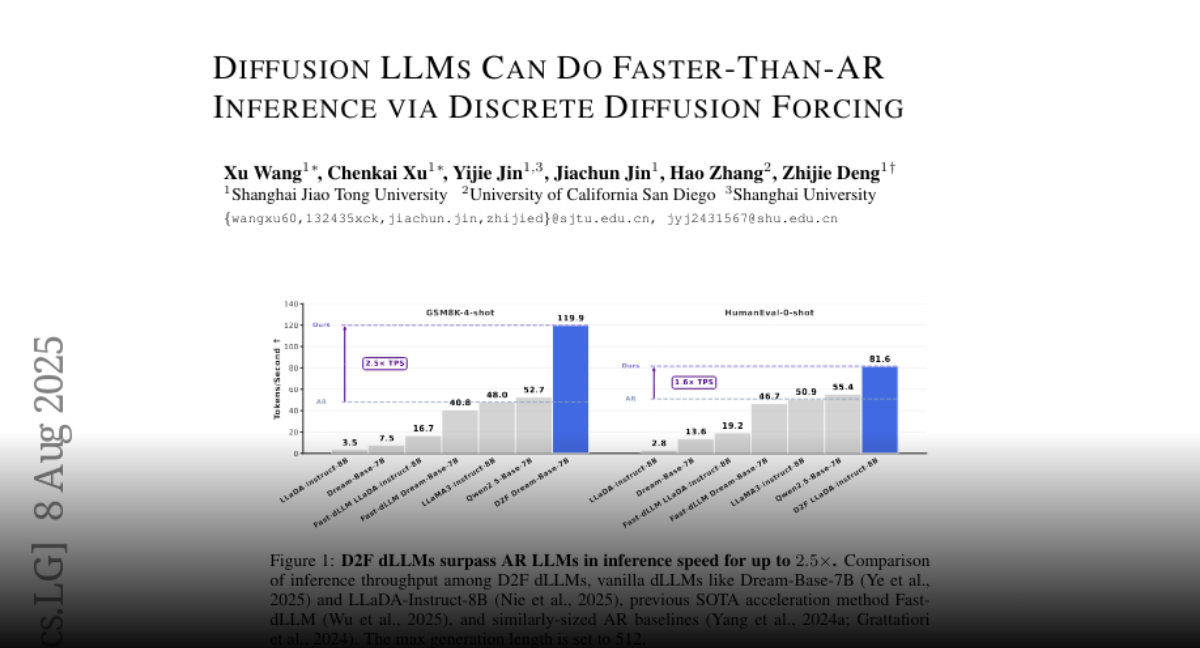
D2F Diffusion LLMs Can Do Faster-Than-AR Inference via Discrete Diffusion Forcing https://t.co/p1luIEA7D4
discuss with author: https://t.co/0wlZRy6GDN
Anycoder one shotted a working @Google Gemma 3 270M transformers.js chatbot app https://t.co/8OjWOoE35w
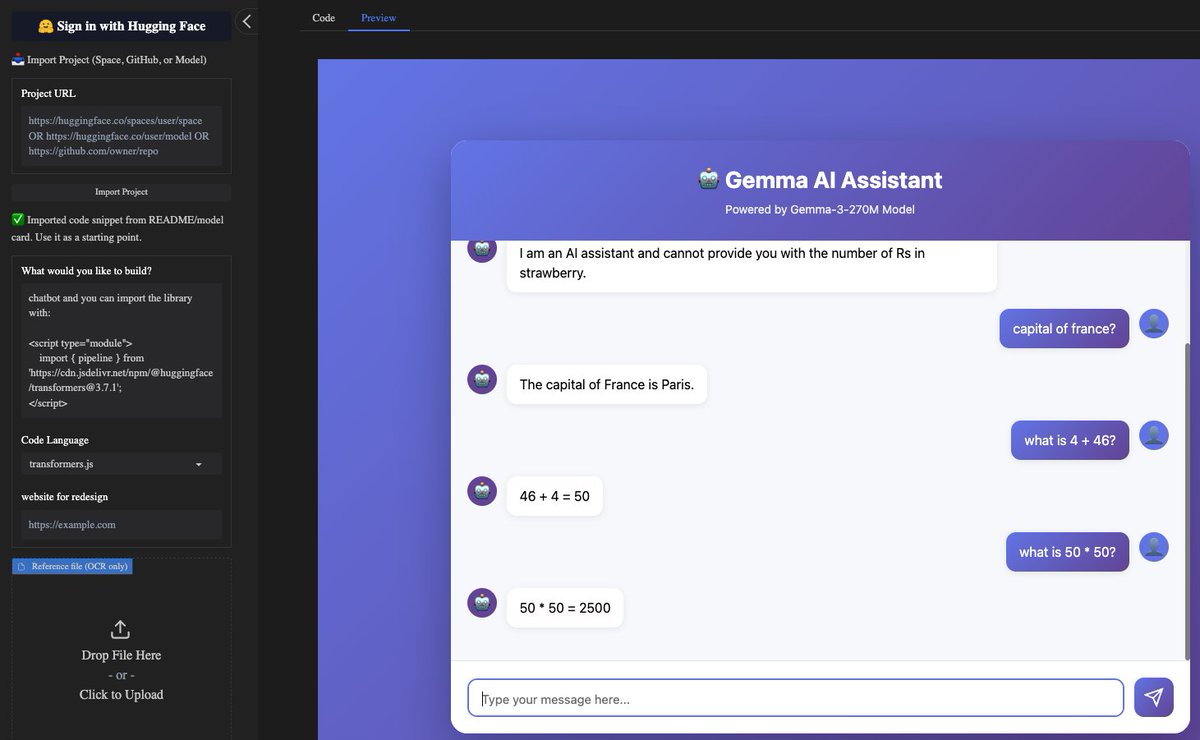
app: https://t.co/esPDyHDu94

gemma app: https://t.co/2KFWyaHY8N

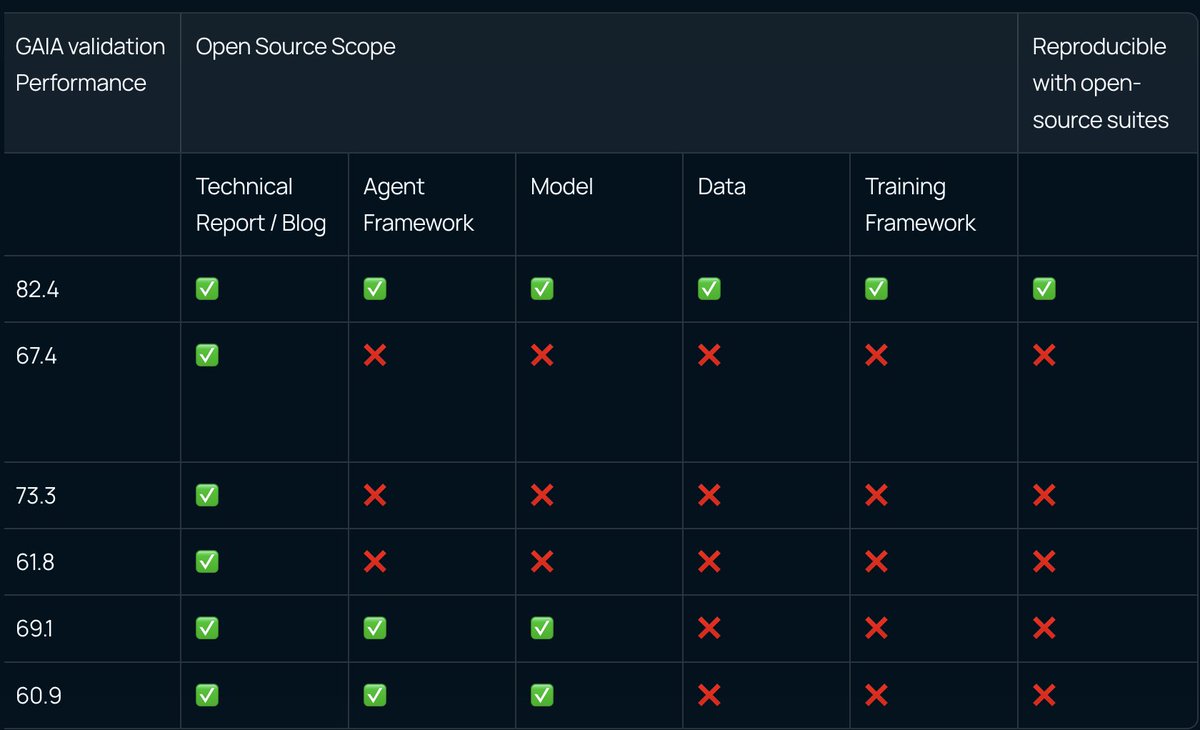
Hello World! Meet Miromind Open Deep Research (Miro ODR): https://t.co/FbTzNotk6y Miro ODR is the most powerful open-source Deep Research model out there today — fully open, fully reproducible, and truly yours to explore. We’ve opened up everything: core models, datasets, training pipelines, AI infrastructure, and our DR Agent framework. No black boxes. No “secret sauce.” Just code, ready for you to run and build on without the headaches. We’ll be pushing out monthly open-source updates, co-creating the strongest Deep Research models together with the community.

A fully open-sourced, top tier Deep Research framework. Guess which one it is? https://t.co/3ilSHqFHPr
270 million (not billion) parameters! https://t.co/DQt3KDlFFL⚡️⚡️⚡️
Introducing Gemma 3 270M 🔥 🤏A tiny model! Just 270 million parameters 🧠 Very strong instruction following 🤖 Fine-tune in just a few minutes, with a large vocabulary to serve as a high-quality foundation https://t.co/E0BB5nlI1k https://t.co/XntprMBqSC

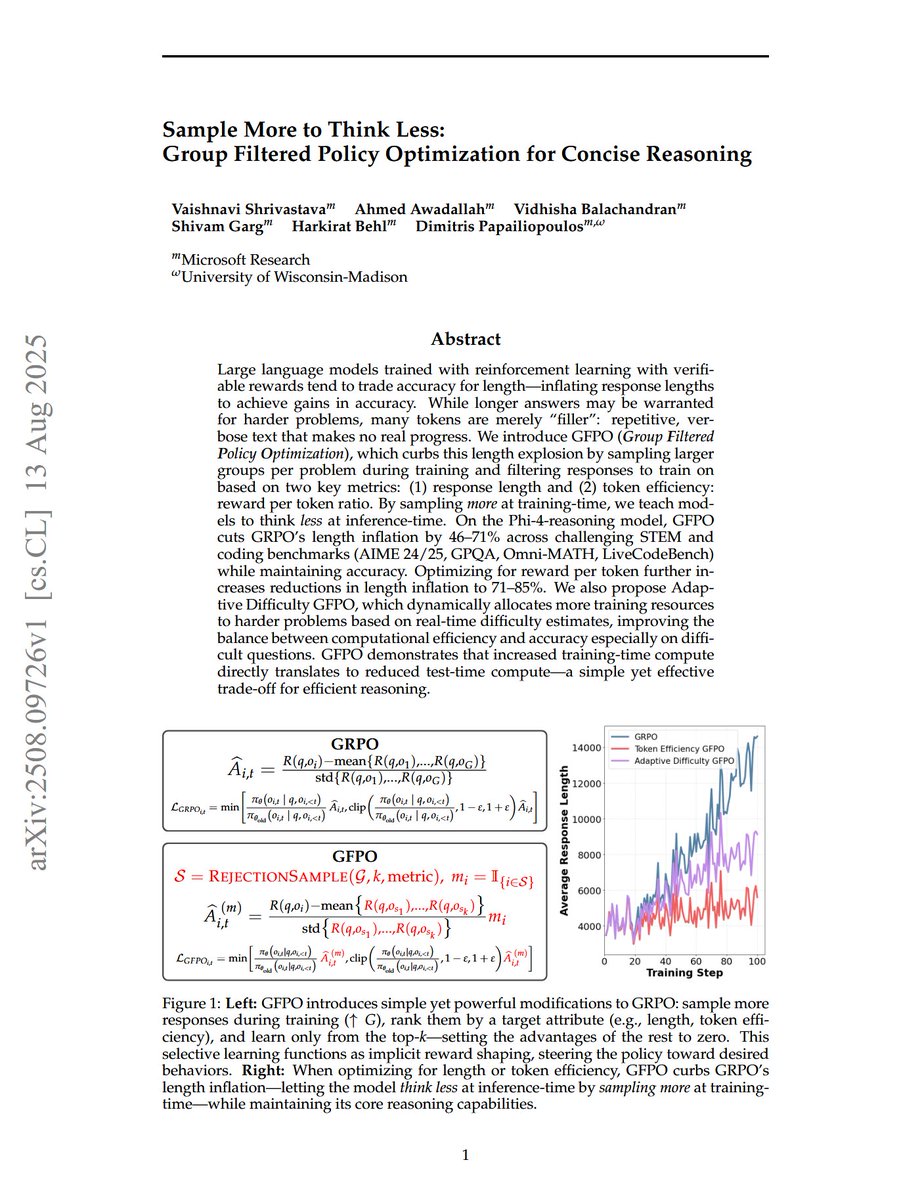
Sample More to Think Less: Group Filtered Policy Optimization for Concise Reasoning "We introduce GFPO (Group Filtered Policy Optimization), which curbs this length explosion by sampling larger groups per problem during training and filtering responses to train on based on two key metrics: (1) response length and (2) token efficiency: reward per token ratio. By sampling more at training time, we teach models to think less at inference time. On the Phi-4-reasoning model, GFPO cuts GRPO's length inflation by 46-71% across challenging STEM and coding benchmarks (AIME 24/25, GPQA, Omni-MATH, LiveCodeBench) while maintaining accuracy. Optimizing for reward per token further increases reductions in length inflation to 71-85%. We also propose Adaptive Difficulty GFPO, which dynamically allocates more training resources to harder problems based on real-time difficulty estimates, improving the balance between computational efficiency and accuracy especially on difficult questions. GFPO demonstrates that increased training-time compute directly translates to reduced test-time compute--a simple yet effective trade-off for efficient reasoning."
Noise Hypernetworks: Amortizing Test-Time Compute in Diffusion Models "we replace reward guided test-time noise optimization in diffusion models with a Noise Hypernetwork that modulates initial input noise." "We show that our approach recovers a substantial portion of the quality gains from explicit test-time optimization at a fraction of the computational cost."

Towards Comprehensive Cellular Characterisation of H&E slides "we introduce HistoPLUS, a state-of-the-art model for cell analysis, trained on a novel curated pan-cancer dataset of 108,722 nuclei covering 13 cell types. In external validation across 4 independent cohorts, HistoPLUS outperforms current state-of-the-art models in detection quality by 5.2% and overall F1 classification score by 23.7%, while using 5x fewer parameters."

Time Is a Feature: Exploiting Temporal Dynamics in Diffusion Language Models "Our work here reveals a critical phenomenon, temporal oscillation, where correct answers often emerge in the middle process, but are overwritten in later denoising steps. To address this issue, we introduce two complementary methods that exploit temporal consistency: 1) Temporal Self-Consistency Voting, a training-free, test-time decoding strategy that aggregates predictions across denoising steps to select the most consistent output; and 2) a post-training method termed Temporal Consistency Reinforcement, which uses Temporal Semantic Entropy (TSE), a measure of semantic stability across intermediate predictions, as a reward signal to encourage stable generations."

OverFill: Two-Stage Models for Efficient Language Model Decoding "OverFill begins with a full model for prefill, processing system and user inputs in parallel. It then switches to a dense pruned model, while generating tokens sequentially. Leveraging more compute during prefill, OverFill improves generation quality with minimal latency overhead."
