@iScienceLuvr
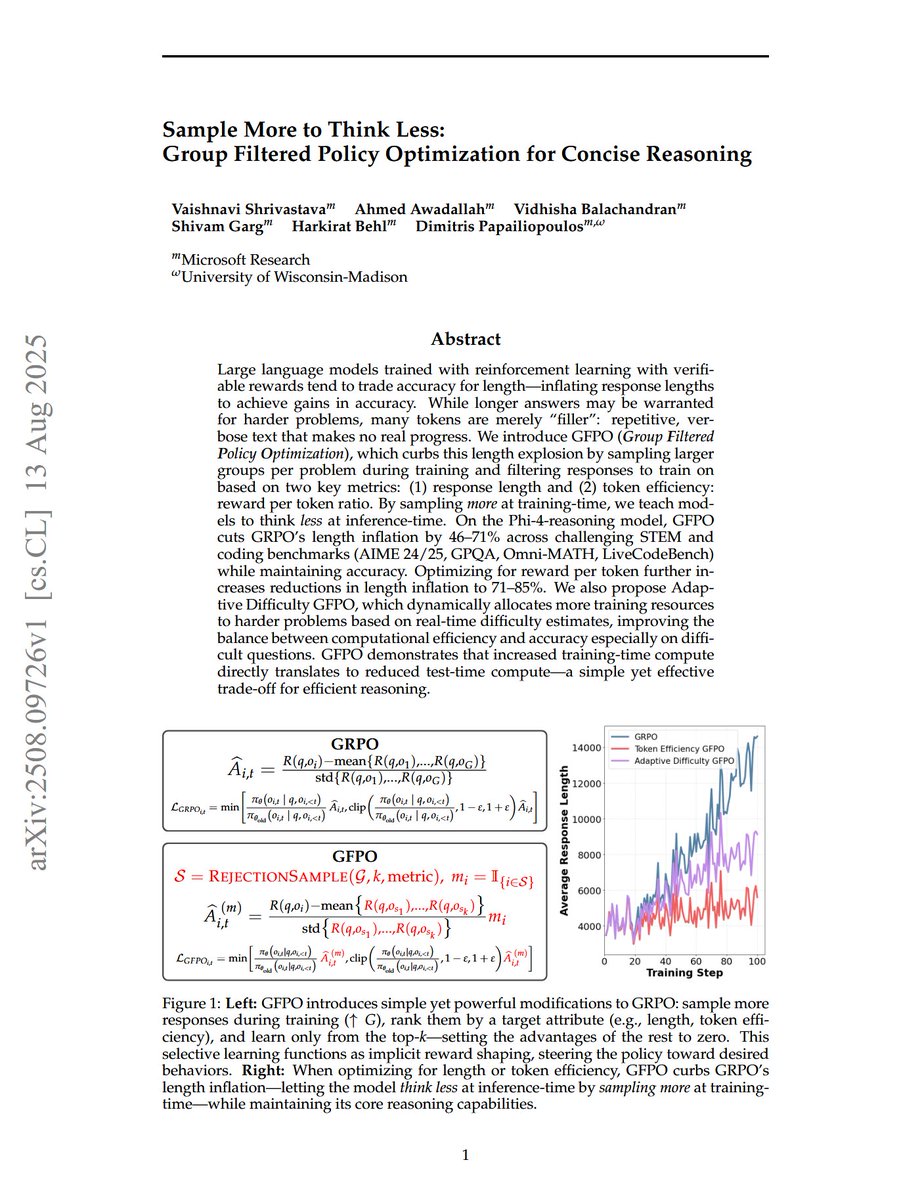
Sample More to Think Less: Group Filtered Policy Optimization for Concise Reasoning "We introduce GFPO (Group Filtered Policy Optimization), which curbs this length explosion by sampling larger groups per problem during training and filtering responses to train on based on two key metrics: (1) response length and (2) token efficiency: reward per token ratio. By sampling more at training time, we teach models to think less at inference time. On the Phi-4-reasoning model, GFPO cuts GRPO's length inflation by 46-71% across challenging STEM and coding benchmarks (AIME 24/25, GPQA, Omni-MATH, LiveCodeBench) while maintaining accuracy. Optimizing for reward per token further increases reductions in length inflation to 71-85%. We also propose Adaptive Difficulty GFPO, which dynamically allocates more training resources to harder problems based on real-time difficulty estimates, improving the balance between computational efficiency and accuracy especially on difficult questions. GFPO demonstrates that increased training-time compute directly translates to reduced test-time compute--a simple yet effective trade-off for efficient reasoning."