Your curated collection of saved posts and media
"Teach Yourself Computer Science" is the best resource to learn CS. 2 weeks into vibe coding and non-technical people feel the pain. "I really wish I was technical. I just don't know how to proceed." It takes ~1000hrs across 9 topics to understand CS with any depth. https://t.co/hOc7CrR2oV

Many of my female friends started taking creatine for the first time this year and the bubblegum pink gummies and drink packets are very lol The Erewhon-ification of everything is pretty impressive https://t.co/At1RyCSx93

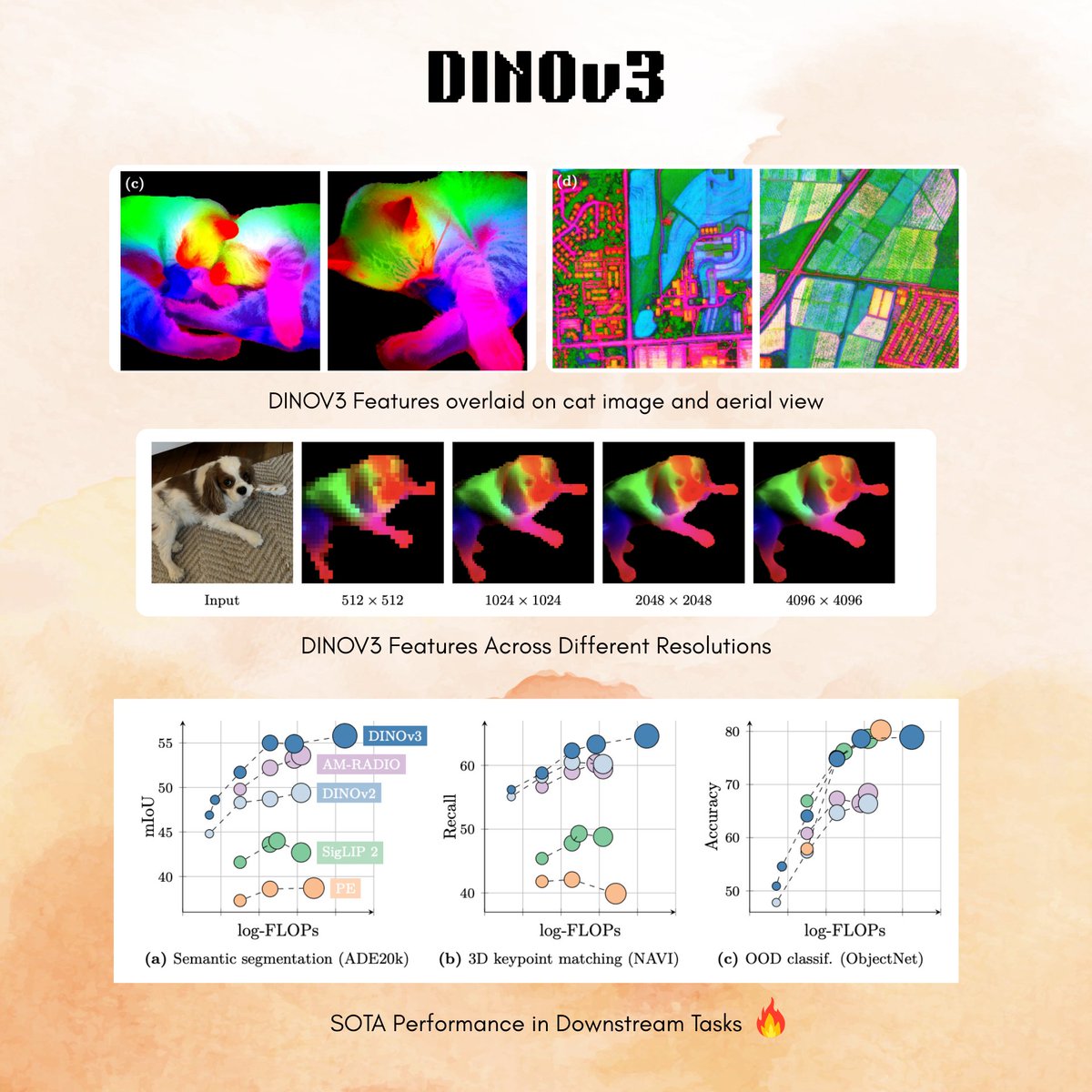
Meta released DINOv3 🔥 > 12 sota image models (ConvNeXT and ViT) in various sizes, trained on web and satellite data! > use for anything: image classification to segmentation, depth or even video tracking 🤯 > day-0 support from transformers 🤗 > allows commercial use! 😍 https://t.co/6C0oJmEfWe
Google releases Gemma 3 270M, a new model that runs locally on just 0.5 GB RAM.✨ Trained on 6T tokens, it runs fast on phones & handles chat, coding & math. Run at ~50 t/s with our Dynamic GGUF, or fine-tune via Unsloth & export to your phone. Details: https://t.co/CuD1KaxkDf
Introducing Gemma 3 270M 🔥 🤏A tiny model! Just 270 million parameters 🧠 Very strong instruction following 🤖 Fine-tune in just a few minutes, with a large vocabulary to serve as a high-quality foundation https://t.co/E0BB5nlI1k https://t.co/XntprMBqSC

"Just fine-tune your embeddings" they said. "It'll fix your RAG system" they said. They were wrong. Here's what actually works: After working with countless retrieval systems, I've noticed a pattern: teams often jump straight to fine-tuning when their vector search underperforms. But that's like replacing your car engine when you might just need better tires. 𝗙𝗶𝗿𝘀𝘁, 𝗱𝗲𝗯𝘂𝗴 𝗯𝗲𝗳𝗼𝗿𝗲 𝘆𝗼𝘂 𝗳𝗶𝗻𝗲-𝘁𝘂𝗻𝗲: Before spending time and compute on fine-tuning, ask yourself: • Do many queries need exact keyword matches? → Try hybrid search first • Are your chunks oddly split or lacking context? → Experiment with different chunking techniques like late chunking • Is the model missing general semantic relationships? → Try a larger model or one with more dimensions • Is it only failing on your specific domain terminology? → NOW we're talking fine-tuning territory 𝗪𝗵𝗲𝗻 𝗳𝗶𝗻𝗲-𝘁𝘂𝗻𝗶𝗻𝗴 𝗺𝗮𝗸𝗲𝘀 𝘀𝗲𝗻𝘀𝗲: Fine-tuning shines when off-the-shelf models can't grasp your domain-specific language. Pre-trained models learn from Wikipedia and web crawls - they don't know your company's product names or industry jargon. The payoff can be substantial: • Better retrieval = better RAG performance • Smaller fine-tuned models can outperform larger general ones • Lower costs and latency for domain-specific tasks 𝗧𝗵𝗲 𝘁𝗲𝗰𝗵𝗻𝗶𝗰𝗮𝗹 𝗱𝗲𝗲𝗽-𝗱𝗶𝘃𝗲: Fine-tuning embedding models isn't like fine-tuning LLMs. It's all about adjusting distances in vector space using contrastive learning. Three main approaches: 1. 𝗠𝘂𝗹𝘁𝗶𝗽𝗹𝗲 𝗡𝗲𝗴𝗮𝘁𝗶𝘃𝗲𝘀 𝗥𝗮𝗻𝗸𝗶𝗻𝗴 𝗟𝗼𝘀𝘀: Just needs query-context pairs. Treats other examples in the batch as negatives - elegant and popular 2. 𝗧𝗿𝗶𝗽𝗹𝗲𝘁 𝗟𝗼𝘀𝘀: Requires (anchor, positive, negative) triplets. Great for precise control but finding good hard negatives is tricky 3. 𝗖𝗼𝘀𝗶𝗻𝗲 𝗘𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴 𝗟𝗼𝘀𝘀: Uses similarity scores between sentence pairs. Perfect when you have gradients of similarity 𝗣𝗿𝗮𝗰𝘁𝗶𝗰𝗮𝗹 𝗰𝗼𝗻𝘀𝗶𝗱𝗲𝗿𝗮𝘁𝗶𝗼𝗻𝘀: • Start with 1,000-5,000 high-quality samples for narrow domains • Plan for 10,000+ for complex specialized terminology • Good news: fine-tuning can run on consumer GPUs or free Google Colab for smaller models • Always evaluate against a baseline - use metrics like MRR, Recall@k, or NDCG 𝗣𝗿𝗼 𝘁𝗶𝗽: The MTEB leaderboard is your friend for finding base models, but remember - leaderboard performance doesn't always translate to your specific use case. The bottom line? Fine-tuning is powerful but it's not a magic bullet. Sometimes your retrieval problems need a different solution entirely. Debug systematically, and when you do fine-tune, start small and iterate. Check out the full technical blog - it includes code examples for both Hugging Face and AWS SageMaker integrations: https://t.co/PH1djlDFDt

Announcing Open Lovable 🔥 We've built an open-source AI web app builder that can transform any website URL into a working, editable clone, giving you a foundation to build on instantly. All powered by @GroqInc, @e2b, and Firecrawl. https://t.co/GjOXb6yjB6
NASA published a free Systems Engineering book that you can self study. It’s definitely worth to touch on this topic, it turns you into a hiring magnet for many companies. Also, systems thinking is absolutely critical for every AI application. https://t.co/jrDdwQaAzK


🚀We are thrilled to open-source Hunyuan-GameCraft, a high-dynamic interactive game video generation framework built on HunyuanVideo. It generates playable and physically realistic videos from a single scene image and user action signals, empowering creators and developers to "direct" games with first-person or third-person perspectives. Key Advantages: 🔹High Dynamics: Unifies standard keyboard inputs into a shared continuous action space, enabling high-precision control over velocity and angle. This allows for the exploration of complex trajectories, overcoming the stiff, limited motion of traditional models. It can also generate dynamic environmental content like moving clouds, rain, snow, and water flow. 🔹Long-term Consistency: Uses hybrid history condition to preserve the original scene information after significant movement. 🔹Significant Cost Reduction: No need for expensive modeling/rendering. PCM distillation compresses inference steps, boosting speed and lowering costs. This allows the quantized 13B model to run on consumer-grade GPUs like the RTX 4090. Project Page: https://t.co/uAbiu9FRzF Code: https://t.co/WgppVz1KUq Technical Report: https://t.co/aO8plomaTr Hugging Face:https://t.co/2ZOUWm6KKQ

Awesome week for computer vision @huggingface🔥 Besides DINOv3 we added support for LLMDet, the SOTA for zero-shot object detection (@CVPR '25 highlight) Detect instances in scenes just via prompting, no training involved. https://t.co/N1KeXeP9x6
🚨 Big news! We decided that @huggingface’s post-training library, TRL, will natively supports training Vision Language Models 🖼️ This builds on our recent VLM support in SFTTrainer — and we’re not stopping until TRL is the #1 VLM training library 🥇 More here 👉 https://t.co/gjO5npVT5t Huge thanks to @mervenoyann , @SergioPaniego , and @ariG23498 🔥


Qwen3-30B-A3B-Instruct — with just 3B active parameters, it’s closing in on the performance of far larger models. Easily deploy locally or Try it now: https://t.co/AmiW3QgjM4 https://t.co/MmQ1DJ88lc
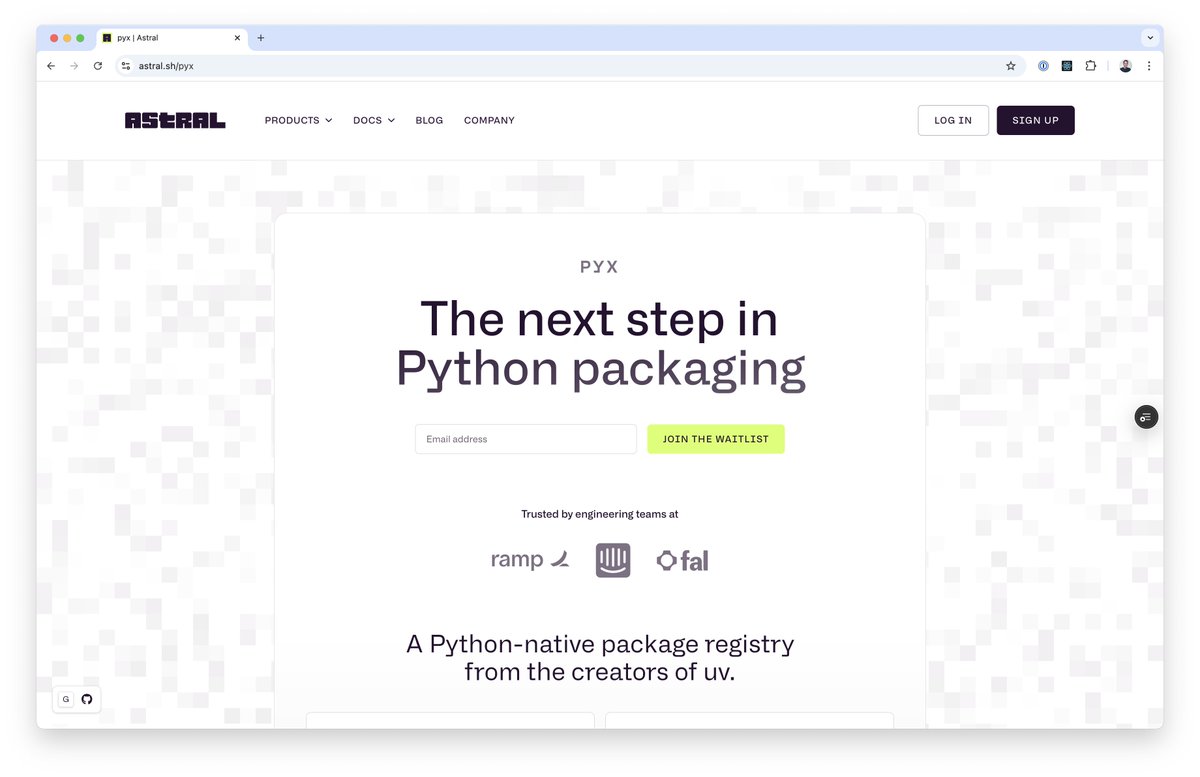
Today, we're announcing our first hosted infrastructure product: pyx, a Python-native package registry. We think of pyx as an optimized backend for uv: it’s a package registry, but it also solves problems that go beyond the scope of a traditional "package registry". https://t.co/ZYQe06uZTD
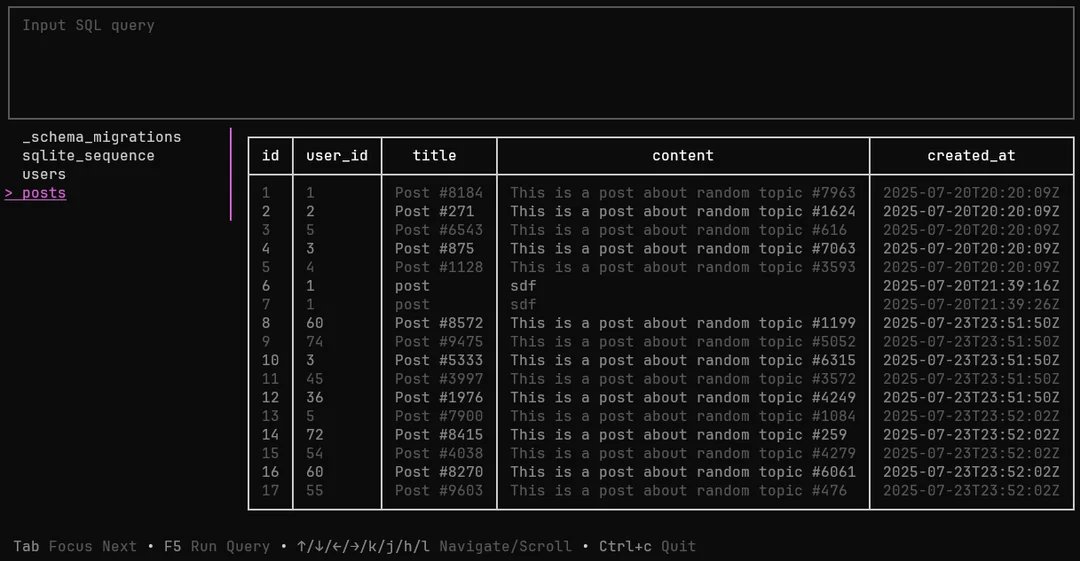
A CLI (with a TUI option!) for working with databases including SQLite, libSQL, PostgreSQL, MySQL, and MariaDB. Oh yessss 💅🏽 Built with ❤️ and - Bubble Tea: TUI framework - Lipgloss: Styling and layout https://t.co/XHE4wlPxiz
You can now fine-tune OpenAI gpt-oss for free with our notebook! Unsloth trains 1.5x faster with -70% VRAM, 10x longer context & no accuracy loss. 20b fits in 14GB & 120b in 65GB GPU. Guide: https://t.co/kdLMAfBwsw GitHub: https://t.co/2kXqhhvLsb Colab: https://t.co/0ErdGWkhgH

I am SUPER EXCITED to publish the 127th epsiode of the Weaviate Podcast featuring Lakshya A. Agrawal (@LakshyAAAgrawal)! 🎙️🎉 Lakshya is the lead author of GEPA: Reflective Prompt Evolution can Outperform Reinforcement Learning! GEPA is a huge step forward for automated prompt optimization, @DSPyOSS, and the broader scope of integrating LLMs with optimization algorithms! The podcast discusses all sorts of areas of GEPA from the Reflective Prompt Mutation to Pareto-Optimal Candidate Selection, Test-Time Training, the LangProBe Benchmark, and more!! 📜 I had so much fun chatting about these things with Lakshya! I really hope you enjoy the podcast! 🎙️

If you aren't looking at your data this guy shows up @vishal_learner https://t.co/9JXr32xZK1

@gregce10 @vishal_learner Sound on https://t.co/AfDEqj3Lbf
We launched a Claude Code learning mode! Claude Code not only makes you more productive, but can now also help you get better at coding. Whether you're a CS student or seasoned programmer, it will push you to think deeper about the code you're generating. https://t.co/WCWhmOSXFx
Introducing DINOv3: a state-of-the-art computer vision model trained with self-supervised learning (SSL) that produces powerful, high-resolution image features. For the first time, a single frozen vision backbone outperforms specialized solutions on multiple long-standing dense prediction tasks. Learn more about DINOv3 here: https://t.co/lQpKhJLTZQ
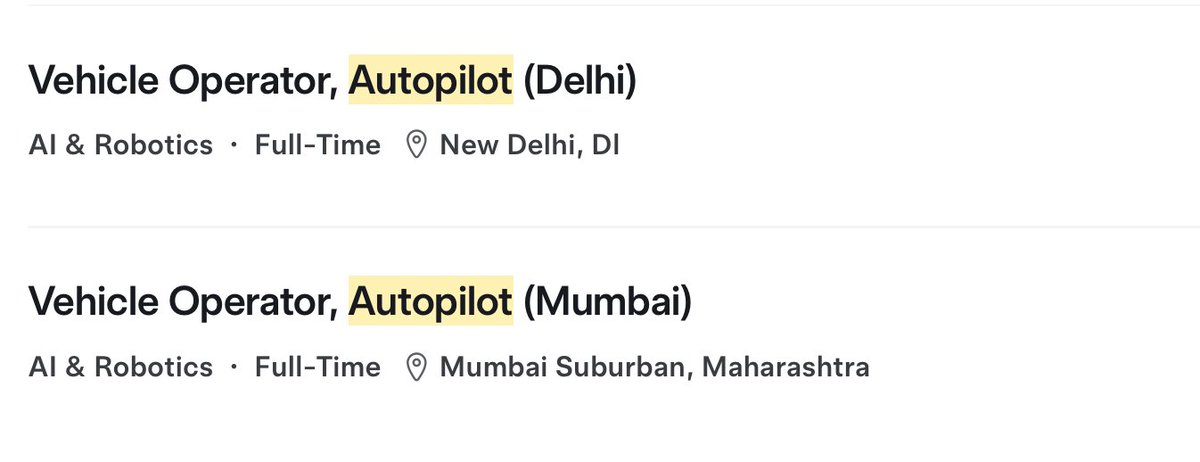
🚨BREAKING! Tesla is now hiring Vehicle Operators in Delhi and Mumbai. 🇮🇳👀 https://t.co/U7UGP1Ryjm
Speed Always Wins Very nice and comprehensive new report on recent efficient architectures for LLMs. https://t.co/X1VRpLj2kN

New walkthrough: Build web-scraping AI agents with @brightdata and LlamaIndex's agentic framework. 🌐 Learn how to give your AI agents reliable web access 🔧 Set up robust web scraping workflows that can handle dynamic content 🤖 Build intelligent agents that can navigate, extract, and process web data at scale Read the full walkthrough: https://t.co/66cfh6tdzx

Introducing Gemma 3 270M 🔥 🤏A tiny model! Just 270 million parameters 🧠 Very strong instruction following 🤖 Fine-tune in just a few minutes, with a large vocabulary to serve as a high-quality foundation https://t.co/E0BB5nlI1k https://t.co/XntprMBqSC
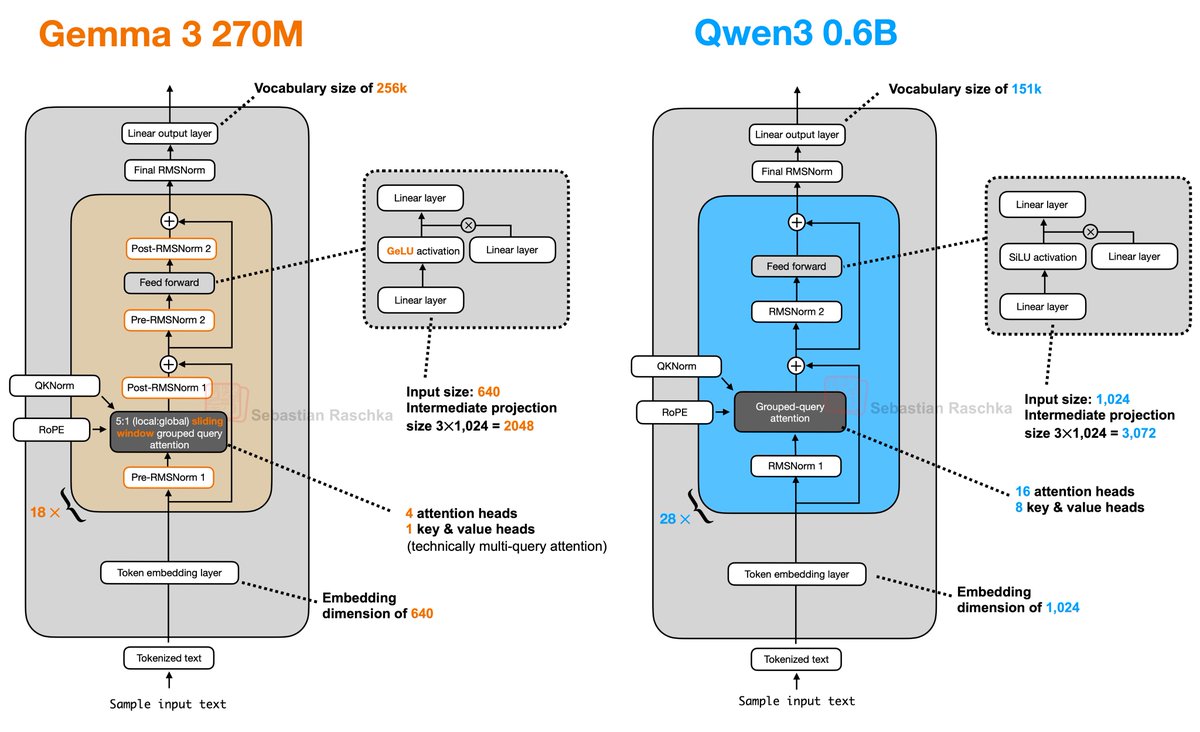
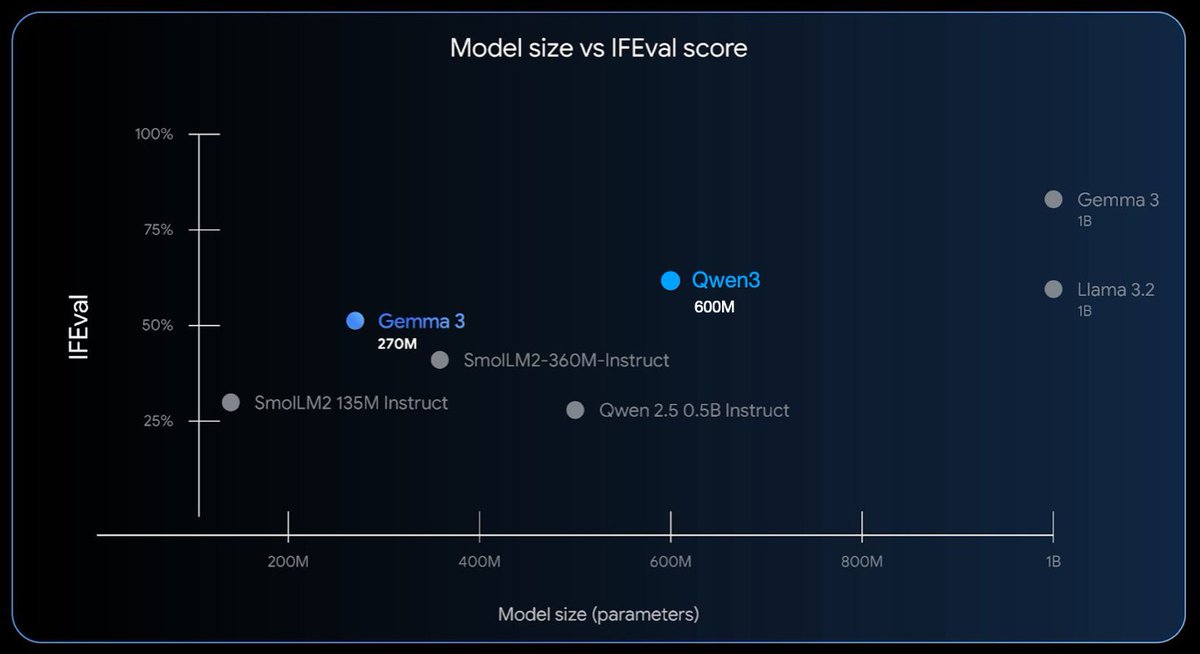
Gemma 3 270M! Great to see another awesome, small open-weight LLM for local tinkering. Here's a side-by-side comparison with Qwen3. Biggest surprise that it only has 4 attention heads! https://t.co/Iy7O0DsQGu
Introducing Gemma 3 270M 🔥 🤏A tiny model! Just 270 million parameters 🧠 Very strong instruction following 🤖 Fine-tune in just a few minutes, with a large vocabulary to serve as a high-quality foundation https://t.co/E0BB5nlI1k https://t.co/XntprMBqSC
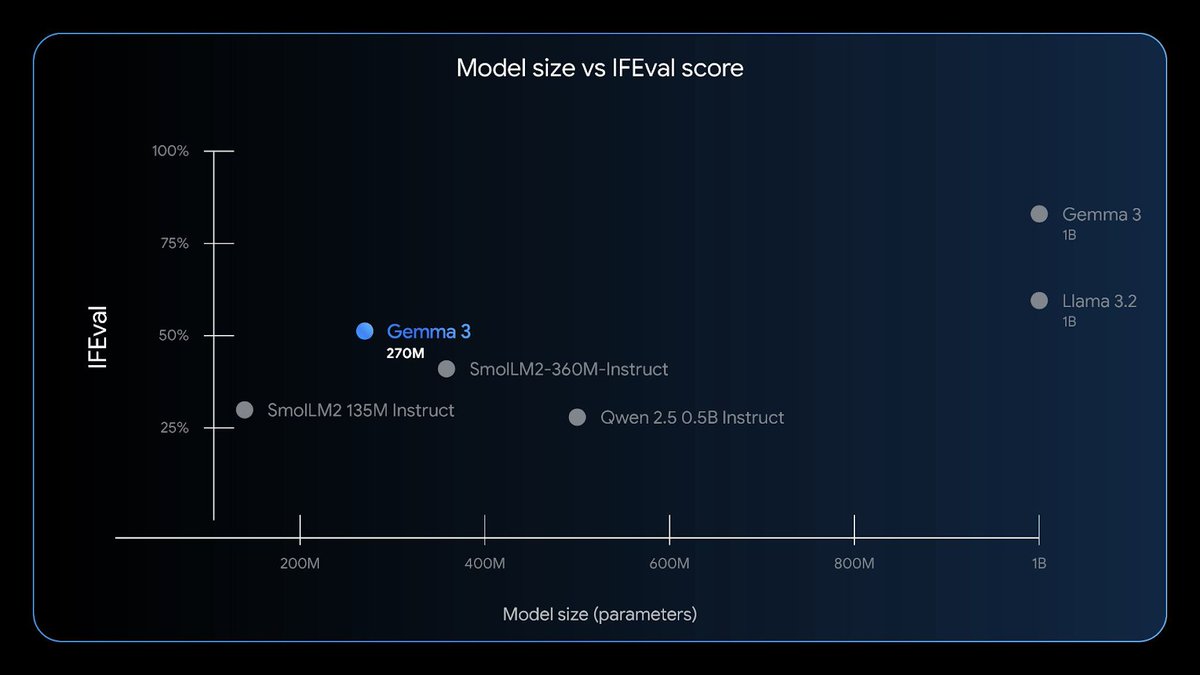
Adding it to the benchmark figure, it doesn't fair that badly against the >2x larger Qwen3: https://t.co/kT6yrdJ6UT
Trust in vertical AI isn't about model accuracy, it's about proving you understand the customer's context. Chris Lovejoy shared with us how dynamic knowledge retrieval + domain expert reviews create systems that adapt to how organizations actually operate, not how we think they do. Talks like the one that happened today and so much more, starting up again in September. https://t.co/BlKvx4tH16


if you want to check out the full 6 week course just enroll here for 20% off https://t.co/5k1FfU7q9O

https://t.co/yX2iSK9dyr

https://t.co/yX2iSK9dyr

How can I get a @tbpm hat :( https://t.co/D2giV6TTmX

@0xcoconutt The prequel https://t.co/3IuZsCzk74

Here’s a selfie with Irene. Can we now close that partnership? https://t.co/nID0SbKufh
