Your curated collection of saved posts and media
Shared prefix is the big win, but not the only one. Maxing out packed sequence length and tuning the parallelism setup got us further, up to 35 trajectories/s on 4 GPUs. We published the configs so you can use them as a starting point for your own runs. 🫡 https://t.co/S7jomILSRi
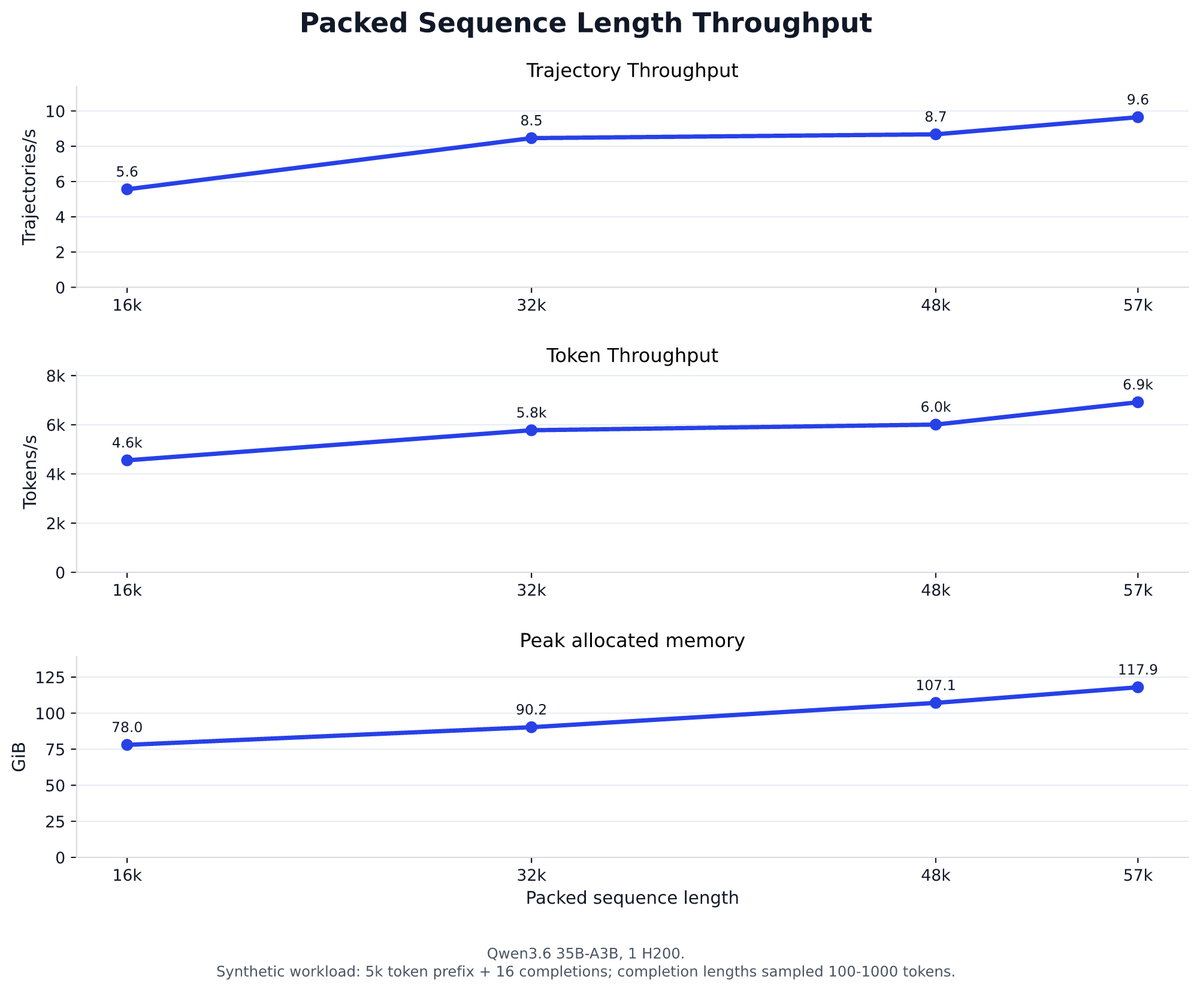
It's all open source in ART. If you're running GRPO-style RL with a heavy shared prompt, the speedup is right there. Give it a try. Blog: https://t.co/FafhwPgeVa @OpenPipeAI ART Github: https://t.co/SHx8iBxYNv


10/10 💥 https://t.co/6nNmmA0uyM
The Cross App Access (XAA) ecosystem just got a lot bigger. Today, we’re announcing 25+ new integrations with some of the industry’s most critical applications. For teams, this means improved IT visibility and robust access control into what employees’ AI agents and apps are accessing. For end users, this means fewer consent prompts and a smoother experience, so agents can keep working on their behalf. Learn more here: https://t.co/6rcLT25C77

@WayneGlows your foul language and ignorance is of no help, and you will be blocked for it, but fyi: https://t.co/kF6otU5Lc0

In today's video we walk through how to use MAI-Code-1-Flash, a small, fast, Copilot-native coding model, to ship a real feature end to end: explore the codebase, build it, run it, and test it, all from Copilot Chat! ▶️ https://t.co/ABR2UZkLFS https://t.co/okTEO2Zv5U

lesgo! https://t.co/o4vMJLtMtM
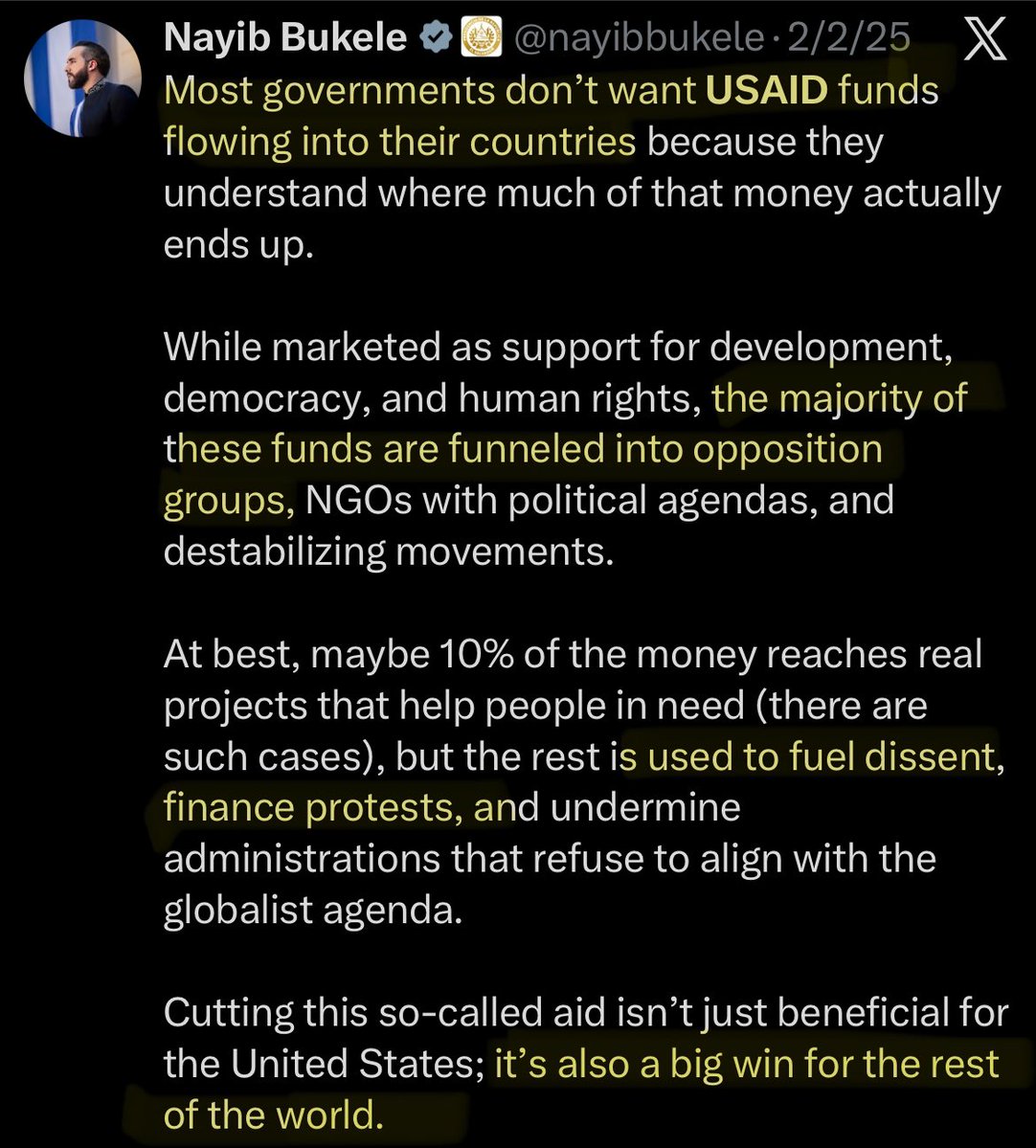
More riddles for @RoKhanna. The President of El Salvador came to the same conclusion as DOGE and celebrated the shutdown of USAID. Are you accusing the President who reduced his country’s murder rate by 95% of supporting the murder of children? https://t.co/69JDO8rdw6
SpaceX has cool star names for stuff. • Starfall: Will enable access to microgravity environment for scientific research & in-space manufacturing • Stargaze: Tracks objects in orbit to prevent collisions • Starshield: Secured satellite network designed specifically for government, military, and intelligence agencies • Starbase: Official incorporated city and private spaceport located in Boca Chica, Texas • Starfactory: 1+ million-square-foot advanced manufacturing facility located at Starbase • Starship: Largest and most powerful rocket ever • Starlink: Satellite internet constellation


A case study in why organizations should both incentivized their employees to explore AI uses that help them & have a Lab of dedicated AI builders Here, Cornell's finance & AI teams created a /treasury Claude skill that recovered $100k in back payments. https://t.co/d5zNMQJu7S https://t.co/TQqcNvixV8


Baidu just released Unlimited-OCR https://t.co/oxvNrDg1SC
https://t.co/Paq8smSRQ9

lesgo! https://t.co/o4vMJLtMtM
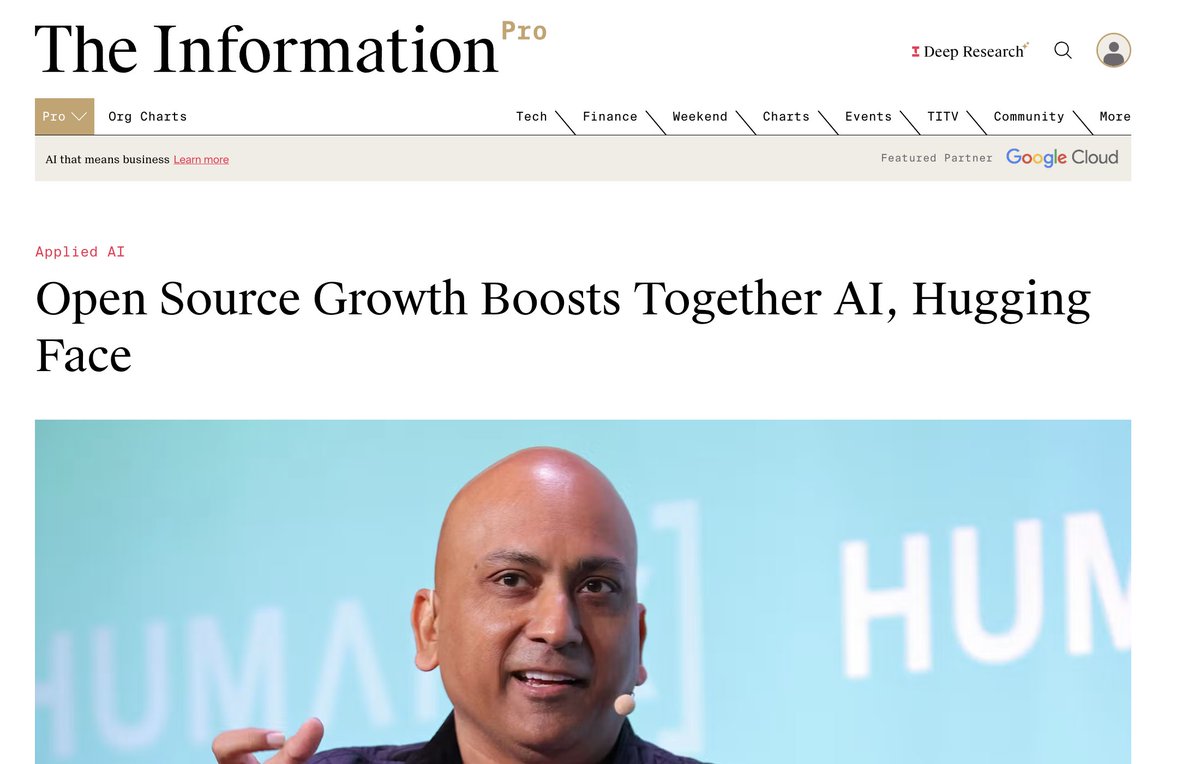
lesgo! https://t.co/o4vMJLtMtM
Join us in our Discord this time tomorrow for Office Hours! Our topic will be the @NVIDIAAI × @stripe × @NousResearch Hermes Agent Accelerated Business Hackathon which concludes at the end of the month. https://t.co/avq295YPIm https://t.co/861E43CH4q


Discord server link: https://t.co/5EoJ4EBecb

@Sur3_Altus The rise of the robots is here! https://t.co/9DSOYjID55

Lift4D Harmonizing Single-View 3D Estimation for 4D Reconstruction In-the-Wild https://t.co/RAqnNEKhas
paper: https://t.co/AY9F2mZA7T

Ling and Ring 2.6 Technical Report Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale https://t.co/kdr2wT4TAo

paper: https://t.co/NH8TYhD0Yf

The open society and its enemy, Soros. While he named his Open Society Foundations after Karl Popper’s “The Open Society and Its Enemies,” his project stands as a philosophical inversion of everything Popper defended. Popper’s open society rested on critical rationalism, the recognition that no one possesses final truth, that institutions must remain open to criticism and piecemeal reform, and that democracy functions as a method for removing rulers without bloodshed. He rejected historicism, the belief in iron laws of history that justify sacrificing present generations for a utopian future, and warned that such thinking inevitably produces closed, authoritarian societies. Soros has repurposed the label to advance a grand project of engineered demographic transformation. Through mass immigration, multiculturalism as official policy, and diversity mandates that prioritize group identity over individual merit and assimilation, his foundations actively dissolve the cultural continuity and social trust that make rational criticism and incremental change possible. Popper understood that openness requires a stable framework, a shared language of reason, basic cohesion, and institutions citizens feel they collectively own. Soros treats those foundations as obstacles to be overcome in the name of an abstract, borderless openness. The concrete results are visible. Parallel societies that operate under different norms, public spaces where debate on the scale and selection of immigration is treated as illegitimate, and the rise of identity based hierarchies that close off dissent in the name of equity. These are certainly not expansions of the open society, but new forms of closure, tribal in character, enforced through institutional capture rather than overt dictatorship, yet hostile to the very critical spirit Popper placed at the center of civilized life. Philosophically, Soros replaces Popper’s falsification and humility before reality with a new historicism, the conviction that global multiculturalism and open borders represent inevitable moral progress, and that resistance from actual existing communities constitutes the new enemy. The machinery funded in the name of openness does not test its own assumptions against evidence, it suppresses the questions. Those who still value the ideal of an open society should read Popper on their own terms. They will find that Soros has not extended the open society, but has supplied its most sophisticated contemporary enemies.


The first @SouthwestAir flight with Starlink has taken off, connecting passengers and crew with reliable, high-speed Wi-Fi from gate to gate 🛰️✈️ https://t.co/Lhg69BvXsd


OpenAI DevDay 2026 applications are now open! Our biggest developer event gets even bigger. 📍 San Francisco 📅 September 29 Apply by July 10: https://t.co/BJyK2EbKuu

"Instead of allowing for greater focus, the latest AI tools are overwhelming workers, frazzling minds and shredding attention spans." https://t.co/RkOirUWh1s

HF is quietly becoming the best place to store data, public AND private, especially for brutal domains like robotics and video AI where the files are massive, append-only, and never stop growing. Example? Public robotics datasets exploded from 1,000 in early 2025 to 60,000 today, and there's twice as many private ones. Why? A single robot records at 140 MB/s, all day, forever. That data has to be stored, streamed to GPUs, and shipped back to hardware on repeat. Get it wrong and your GPUs sit idle at 0 MB/s waiting for a dataset to land. Get it right (stream straight from the Hub, pre-warmed cache) and those same GPUs scream along at ~1,326 MB/s, fully fed. 🚀 Here's how LeRobot + Hugging Face Storage Buckets pull it off: https://t.co/SOUPAUpiZc
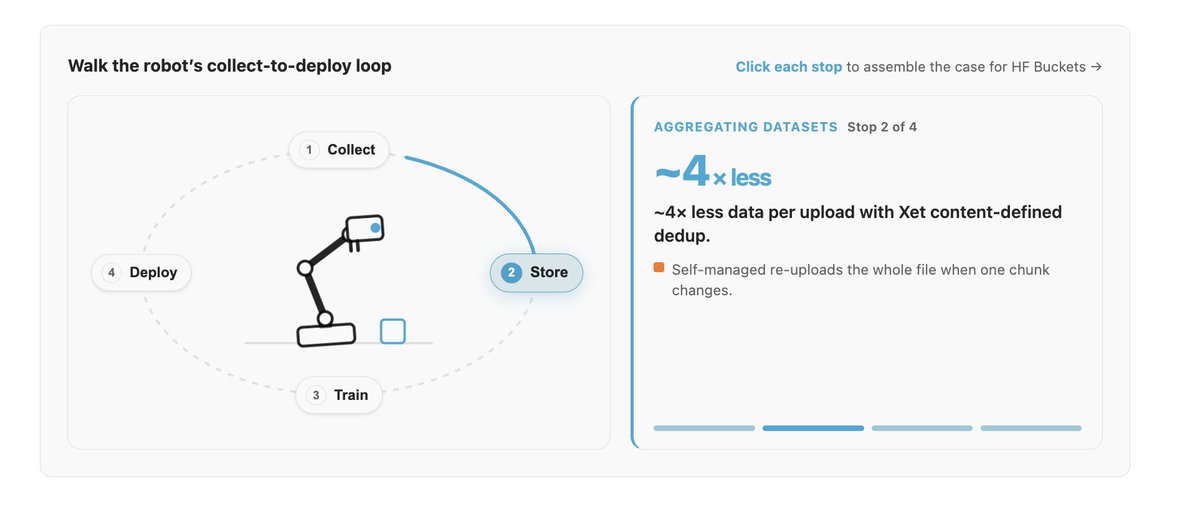

Shot a video this morning to announce a new collaboration with ... https://t.co/MF9qJY7HsK
Shot a video this morning to announce a new collaboration with ... https://t.co/MF9qJY7HsK
Just finished my @wandb Lego set!! Got it at the AWS Summit last week https://t.co/uNqMtEEvyg

Just finished my @wandb Lego set!! Got it at the AWS Summit last week https://t.co/uNqMtEEvyg

Super excited for what's cooking 🔥 Smaller and Better 🚀 cc: @c_elolabs https://t.co/B2GaOzzPhd