Your curated collection of saved posts and media
https://t.co/rseHjBQLnV

More opportunities are popping up, and that’s something we should all take note of. Source: https://t.co/w9eYzeTNby

Source: https://t.co/cqaeVLFDIg

The Danxia mountain trail Open the video to see it all 🤯 What’s your comfort level https://t.co/0dhT2GzIor
The Danxia mountain trail Open the video to see it all 🤯 What’s your comfort level https://t.co/0dhT2GzIor
AI-powered stuffed animals are coming for your kids https://t.co/Pf77WzFjTw @techcrunch

RIP Terence Stamp, face of 60s British cinema and star of The Limey and Superman, dies at 87 https://t.co/70lhqu5WiP

This CEO laid off nearly 80% of his staff because they refused to adopt AI fast enough. 2 years later, he says he'd do it again https://t.co/NTLZNgCGLa @fortunemagazine

An early member of Google's generative AI team says it's too late to get a Ph.D. to cash in on the AI hype https://t.co/Gd6dRkRQSn @tankwanwei @businessinsider

The era of AI hacking has arrived https://t.co/LhjMyhG5js @kevincollier @nbcnews

White House AI czar David Sacks says 'AI psychosis' is similar to the 'moral panic' of social media's early days https://t.co/tIBrhyySHS @businessinsider @laurensimone_95

AI has created a new breed of cat video: addictive, disturbing and nauseatingly quick soap operas https://t.co/93bwoktAdG

The new ChatGPT has some AI fans rethinking when to expect ‘superintelligence’ https://t.co/FYTFMPJdsp @GerritD @WashingtonPost

On GPS: Will AI save the economy? https://t.co/vweXmYxW8x @FareedZakaria @DKThomp

I'm a psychiatrist who's had patients with 'AI psychosis.' Here are the red flags. https://t.co/609a2LBM2Z @kashmiragander @businessinsider

AI Data Centers Are Coming for Your Land, Water and Power https://t.co/f8itq7Mdll @cnet https://t.co/7wTFDDTrh6
Why generative AI can't seem to help marketers build their brands https://t.co/vkv6DrfKc0 @Digiday

If AI takes most of our jobs, money as we know it will be over. What then? https://t.co/7lbJKulxTb @bspiesbutcher @ConversationEDU

Will AI Replace Human Creativity? https://t.co/XHZydTC5rF @bernardmarr https://t.co/KvRVdTWYy1


Google Might Not Believe It, But Its AI Summaries Are Bad News for Publishers https://t.co/7JqprY4xQn @WillMWrites717 @pcmag
Scientists Taught a Robot to Play the Drums and He Is Shockingly Horrible at It https://t.co/B68iepSkWu @futurism

The era of superintelligence is here. Didn't predict the medical field would be first. Amazing work by team @EvidenceOpen in scoring a perfect 100% on the US Medical Licensing Exam https://t.co/9J8vOYGzHy

The "AI Existential Risk" map got an update. Organizations/projects still spring up like mushrooms after the rain. https://t.co/oNo3CUWdPk

An introduction to Jazz in 25 records. A thread🧵 The following list offers an excellent starting point for any music enthusiast seeking exploration. 1. Miles Davis – Kind of Blue https://t.co/24pyCpVOVN

🧠💥 The future of AI is in good hands. Congrats to the 2025-2026 #AI150 honorees — bold, innovative, and transforming industries!🔗 Full list: https://t.co/x7qMPiwfnm 👀 Meet them live at #AIForum25 Sept 30: https://t.co/dtBW2R1lxn @rwang0 @MMinevich https://t.co/S0SrrQJHS0


#BREAKING: United States to impose 80% tarrif on India shortly, will be largest ever on any Asian country. https://t.co/PB0OBWWx4C

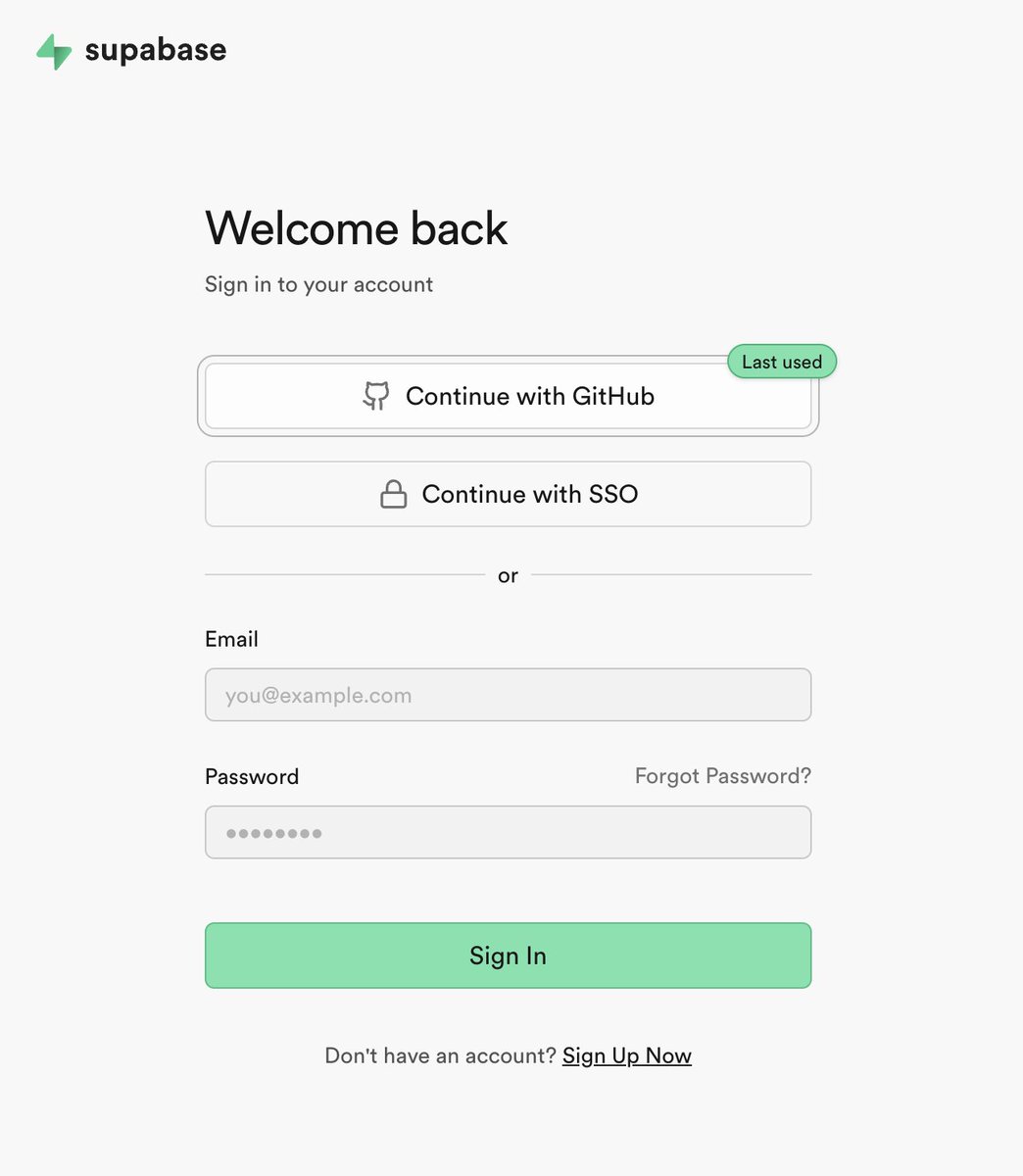
Kudos to @supabase for this "Last used" badge on the login options! I've never seen this before, but it's so simple & elegant. I hope it becomes standard practice across the web! https://t.co/4ZhZO70aWU
This talk from @ttorres busts myths about LLM Evals You don't need ❌ ... to be technical ❌ ... fancy tools or infra ❌ ... to spend weeks (you can have evals in < an hour) https://t.co/5O9vrdP6Pw

The beatings (free books) will continue until everyone looks at their data: 1. LLM Evals FAQ: https://t.co/BzEHwvobz5 2. Beyond Naive RAG: Practical Advanced Methods https://t.co/x2870kdHoZ

There’s a difference between doing AI and doing AI that actually works. I’ve done evals before but @sh_reya & @HamelHusain's Maven course gave me the systematic framework & rigor to make them truly effective. Course - https://t.co/Baie4pBN1D Eval-driven AI=trustworthy AI 🚀

We have done 2 cohorts and ~800 people have meaningfully engaged with the AI evals course. Hamel shared a bunch of testimonials with me yesterday. I was really astounded that they are not just generic testimonials; people mentioned very specific results and concepts. It seems like people have been really unblocked and are able to get a lot further in their AI projects, legitimately. E.g., "I often ran into code quality issues when using AI assistants, but I didn’t have a structured way to make sense of them. Before this course, I would just label outputs as “messy code” without really digging into the underlying problems....After this course, I now analyze them systematically across dimensions—things like hardcoded tests, long methods, poor formatting, bad naming, poor architecture choices, duplication, dead code, or ignoring available quality tools." - SWE "The axial coding just hit different. Before this course, my approach to failures was more of a “vibe investigation,” poking around without a clear structure.After this course, I now cluster failures systematically and trace them back to their core issues... I finally feel like I have a proper way to identify the root problems in my agent instead of just guessing." - Staff SWE "Some of my favorite highlights: - Build a custom data annotation app! I was so intimidated by this, but I finally made the leap and vibe-coded something out in an afternoon. It has 10x'd my ability to review conversations." - Senior PM "It's really hard to build LLM judges so be really thoughtful about what you build them for. Often, the biggest impact comes from talking disagreements out and figuring out why there is a disagreement in the first place: are your goals unclear? This seemingly technical course has made me a better PM." - Senior PM "I have been following Hamel's and Shreya's work for quite some time and it was really awesome to learn from them all the concepts of error analysis, measurement best practices, LLM as Judge + how to make sure it is reliable with human evaluations, collaborative analysis of errors, evaluation of multiturn chats, creation of datasets for CI/CD etc. The last topic on accuracy and cost optimization is really useful as we are seeing in our applications when scaling." - Director of ML "I was making the common mistake of jumping straight to LLM-as-a-judge without first figuring out what I actually needed to measure. The sections on calibrating LLM judges with TPR/TNR methods were exactly the technical content I was looking for." - ML Engineer "We kept testing judge models on the same examples we used to build them; obviously they looked great until they hit production." - ML Engineer "The cost optimization stuff alone could pay for the course (they showed examples of 60%+ savings)" - ML Engineer
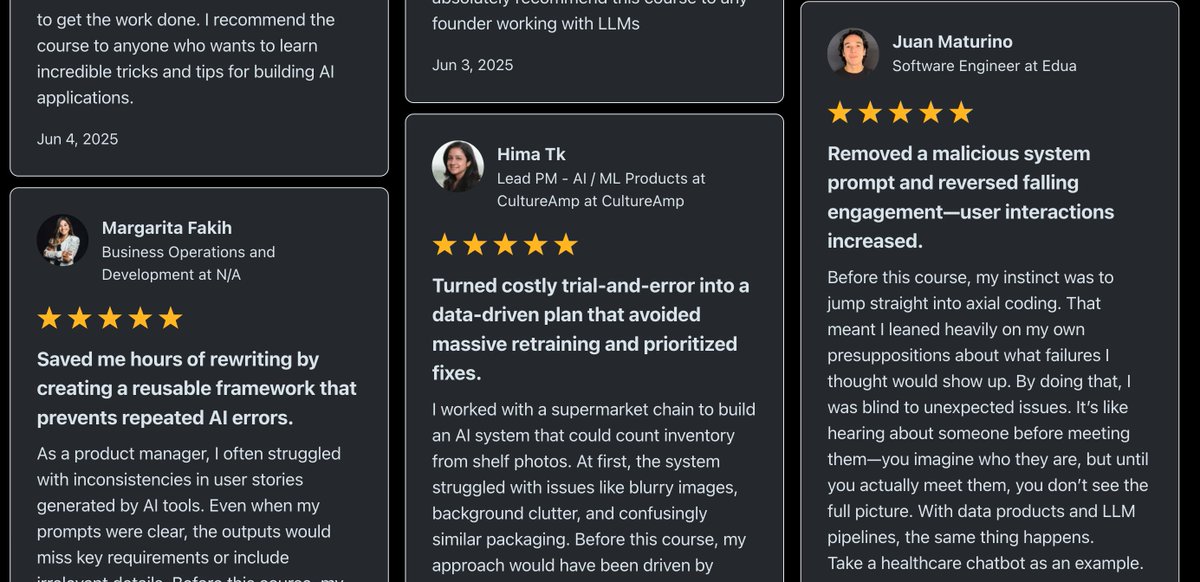
Link to all testimonials: https://t.co/a5qR3zRKKJ I am now motivated to revise the curriculum for a 3rd time. Thanks everyone for the positive reception
