Your curated collection of saved posts and media
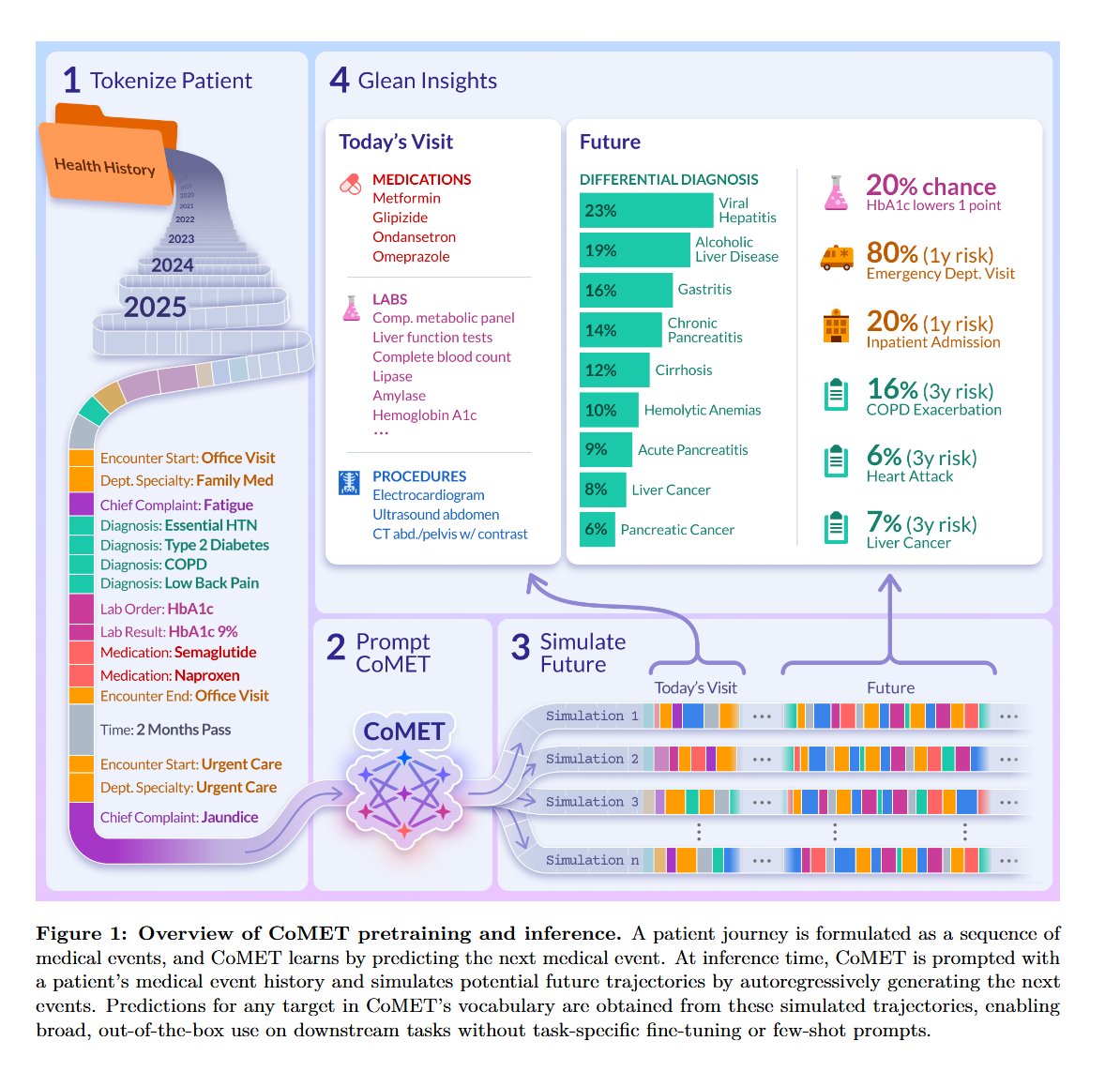
Generative Medical Event Models Improve with Scale "we introduce the Cosmos Medical Event Transformer (CoMET) models, a family of decoder-only transformer models pretrained on 118 million patients representing 115 billion discrete medical events (151 billion tokens). We present the largest scaling-law study for medical event data, establishing a methodology for pretraining and revealing power-law scaling relationships for compute, tokens, and model size. Based on this, we pretrained a series of compute-optimal models with up to 1 billion parameters. Conditioned on a patient's real-world history, CoMET autoregressively generates the next medical event, simulating patient health timelines. We studied 78 real-world tasks, including diagnosis prediction, disease prognosis, and healthcare operations. Remarkably for a foundation model with generic pretraining and simulation-based inference, CoMET generally outperformed or matched task-specific supervised models on these tasks, without requiring task-specific fine-tuning or few-shot examples."

QuarkMed Medical Foundation Model Technical Report "medical tasks often demand highly specialized knowledge, professional accuracy, and customization capabilities, necessitating a robust and reliable foundation model. QuarkMed addresses these needs by leveraging curated medical data processing, medical-content Retrieval-Augmented Generation (RAG), and a large-scale, verifiable reinforcement learning pipeline to develop a high-performance medical foundation model. The model achieved 70% accuracy on the Chinese Medical Licensing Examination, demonstrating strong generalization across diverse medical benchmarks."

MDPO: Overcoming the Training-Inference Divide of Masked Diffusion Language Models "We propose a novel Masked Diffusion Policy Optimization (MDPO) to exploit the Markov property diffusion possesses and explicitly train the model under the same progressive refining schedule used at inference. MDPO matches the performance of the previous state-of-the-art (SOTA) method with 60x fewer gradient updates, while achieving average improvements of 9.6% on MATH500 and 54.2% on Countdown over SOTA when trained within the same number of weight updates. Additionally, we improve the remasking strategy of MDLMs as a plug-in inference replacement to overcome the limitation that the model cannot refine tokens flexibly. This simple yet effective training-free strategy, what we refer to as RCR, consistently improves performance and yields additional gains when combined with MDPO"

Signal and Noise: A Framework for Reducing Uncertainty in Language Model Evaluation "In this work, we analyze specific properties which make a benchmark more reliable for such decisions, and interventions to design higher-quality evaluation benchmarks. We introduce two key metrics that show differences in current benchmarks: signal, a benchmark's ability to separate better models from worse models, and noise, a benchmark's sensitivity to random variability between training steps. We demonstrate that benchmarks with a better signal-to-noise ratio are more reliable when making decisions at small scale, and those with less noise have lower scaling law prediction error. These results suggest that improving signal or noise will lead to more useful benchmarks, so we introduce three interventions designed to directly affect signal or noise."

code: https://t.co/yxaRoH7TsT huggingface: https://t.co/8OTIGyvfnL abs: https://t.co/KxeBNd3qrH

Reinforcement Learning with Rubric Anchors "we extend the RLVR paradigm to open-ended tasks by integrating rubric-based rewards, where carefully designed rubrics serve as structured, model-interpretable criteria for automatic scoring of subjective outputs. We construct, to our knowledge, the largest rubric reward system to date, with over 10,000 rubrics from humans, LLMs, or a hybrid human-LLM collaboration. Implementing rubric-based RL is challenging; we tackle these issues with a clear framework and present an open-sourced Qwen-30B-A3B model with notable gains: 1) With only 5K+ samples, our system improves by +5.2% on open-ended benchmarks (especially humanities), outperforming a 671B DeepSeek-V3 model by +2.4%, while preserving general and reasoning abilities. 2) Our method provides fine-grained stylistic control, using rubrics as anchors to mitigate the "AI-like" tone and produce more human-like, expressive responses. We share key lessons in rubric construction, data selection, and training, and discuss limitations and future releases"

model: https://t.co/VWWX3ZdN3g abs: https://t.co/Jh1w7bR1Hc


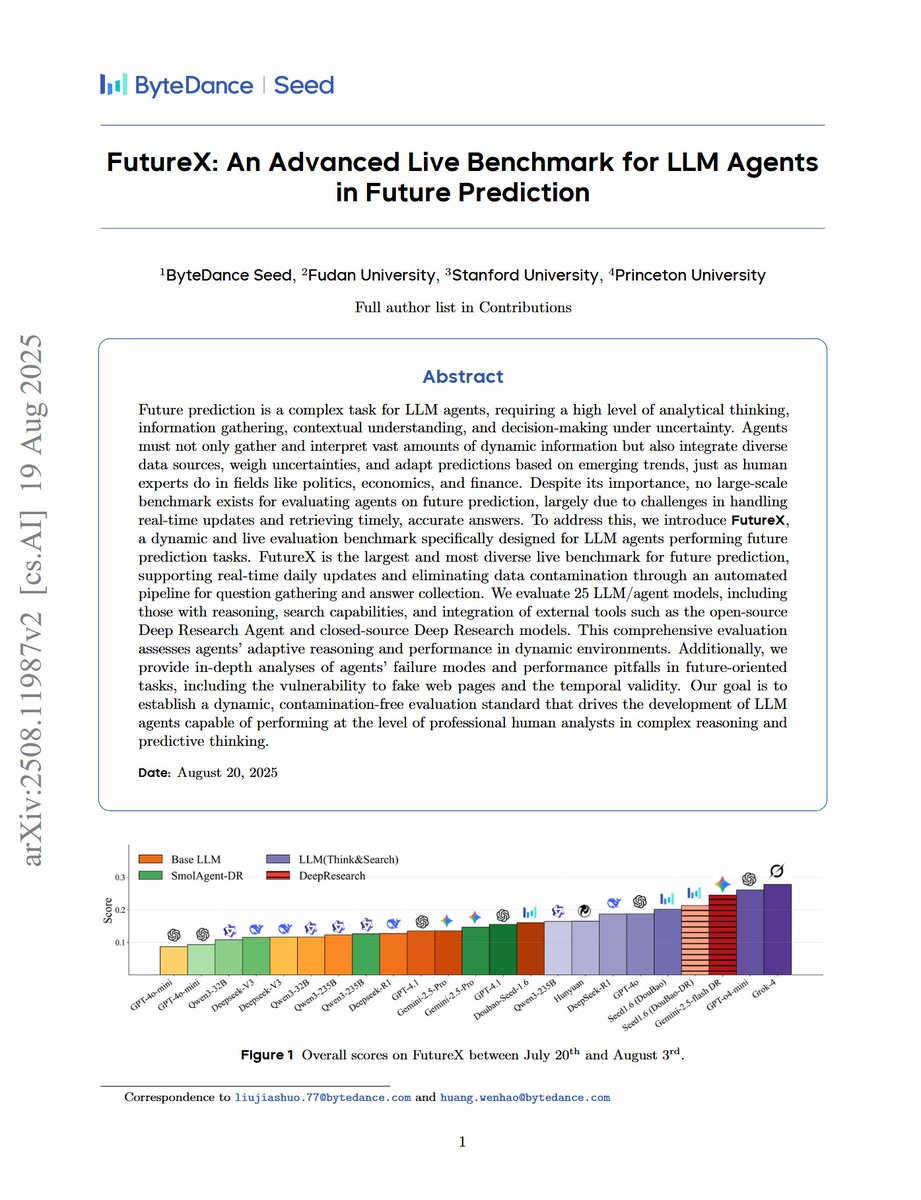
FutureX: An Advanced Live Benchmark for LLM Agents in Future Prediction "we introduce FutureX, a dynamic and live evaluation benchmark specifically designed for LLM agents performing future prediction tasks. FutureX is the largest and most diverse live benchmark for future prediction, supporting real-time daily updates and eliminating data contamination through an automated pipeline for question gathering and answer collection. We evaluate 25 LLM/agent models, including those with reasoning, search capabilities, and integration of external tools such as the open-source Deep Research Agent and closed-source Deep Research models."
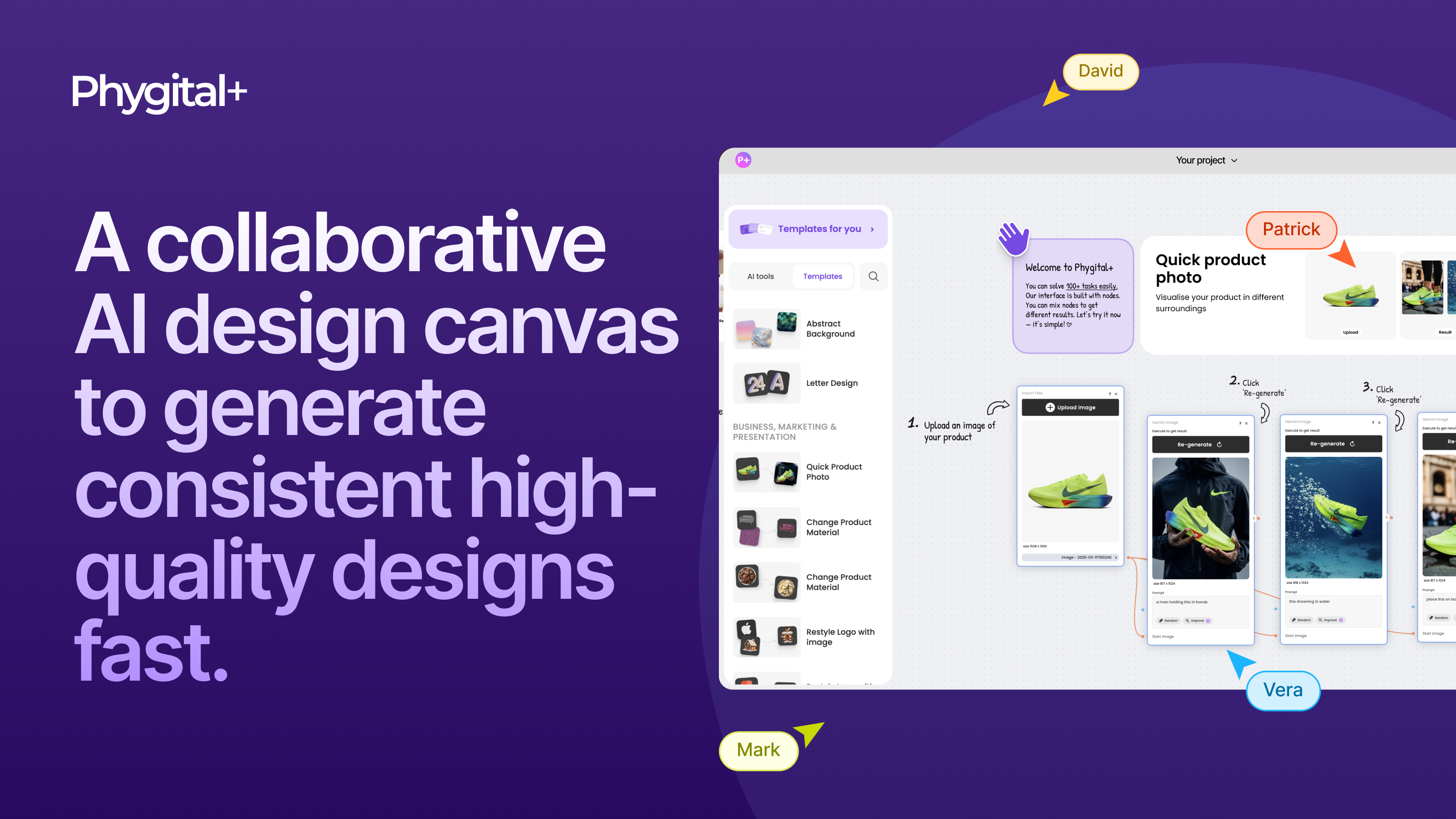
We are launching on Product Hunt Phygital+ AI Design Canvas: work with 30+ AI models in one space! Support us please https://t.co/FlftA6FBEQ https://t.co/Bm1vIt5ufC

https://t.co/2P23goJMLU is now the #1 open-source AI Agent on SWE-bench https://t.co/p5jaXemFnA I had never heard of it before
https://t.co/2P23goJMLU is now the #1 open-source AI Agent on SWE-bench https://t.co/p5jaXemFnA I had never heard of it before

Medivis’ technology transforms complex 2D imaging, like MRI and CT scans, into real-time 3D visualizations that can be superimposed onto the patient's body in real-time at the bedside. Video Credit: @Medivis_AR #engineering #technology #hologram #augmentedreality -------------------------------- Stay ahead of the curve! Follow us now on our WhatsApp (https://t.co/YBAHioUWe6) and Telegram (https://t.co/pszbf78JMc) channels and stay updated about the cutting edge.

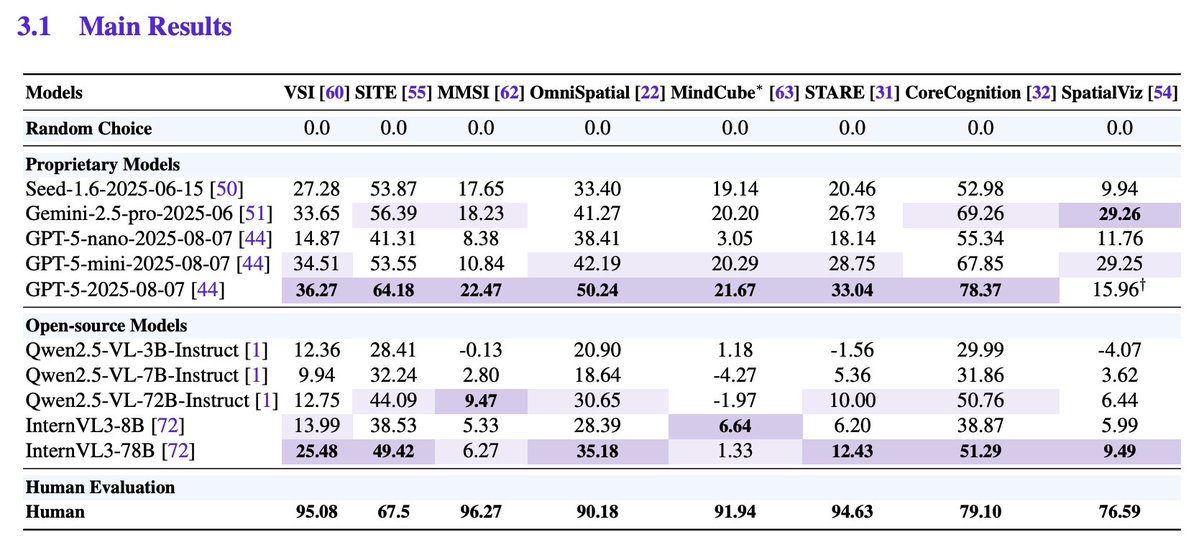
GPT‑5 sets SOTA but not human‑level SI. GPT‑5 tops aggregate scores and sometimes reaches human parity on Metric Measurement and Spatial Relations, yet shows significant gaps on Mental Reconstruction, Perspective‑taking, Deformation & Assembly, and multi‑stage Comprehensive Reasoning.
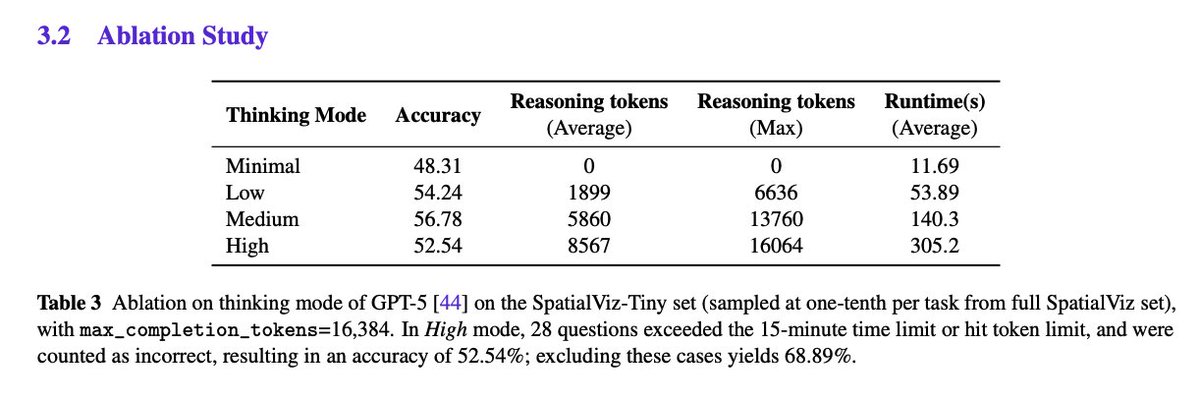
Thinking Modes "In High mode, 28 questions exceeded the 15-minute time limit or hit token limit, and were counted as incorrect, resulting in an accuracy of 52.54%; excluding these cases yields 68.89%." High could lead to better results, but I understand the token limit issues. https://t.co/LRrU7SP65p
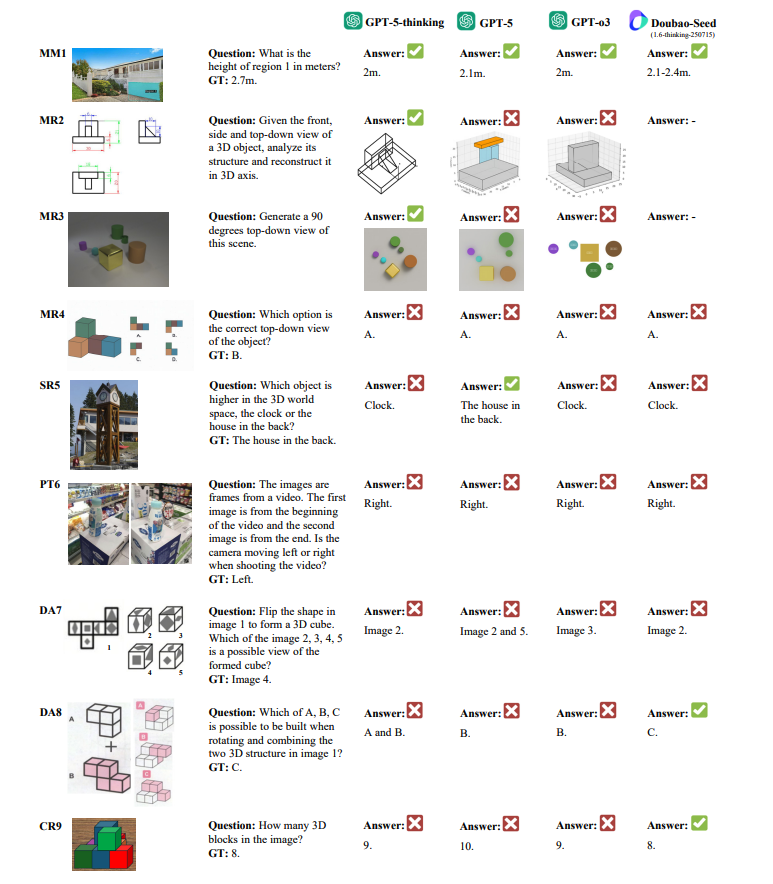
Qualitative analysis exposes failure modes Case studies show prompt sensitivity for novel‑view generation, blind spots with perspective effects and size constancy, persistent failures on paper‑folding/assembly, and difficulty inferring occluded objects during counting. Paper: https://t.co/9KZL0VgjYp

Firecrawl /v2 is here! I got early access, and it's hands down one of the most advanced search APIs. Context engineering for AI agents just got a whole lot simpler. Search the web, news, and images all in one shot. It's impressive for building advanced deep research agents. https://t.co/mzoCmjnWV3
We have a new comprehensive Model Context Protocol (MCP) documentation section, to help you connect your AI applications to external tools and data sources through a standardized interface. 🔌 Learn how MCP works - connecting LLMs to databases, tools, and services through a simple client-server architecture 🛠️ Use existing MCP servers with LlamaIndex workflows or convert your own workflows into MCP servers for broader ecosystem compatibility ☁️ Access LlamaCloud services like LlamaExtract and LlamaParse through our official MCP servers ⚡ Get started quickly with our llama-index-tools-mcp package and integrate with agents, Claude Desktop, and other MCP hosts Start with the overview: https://t.co/oL2Ohh6IV5
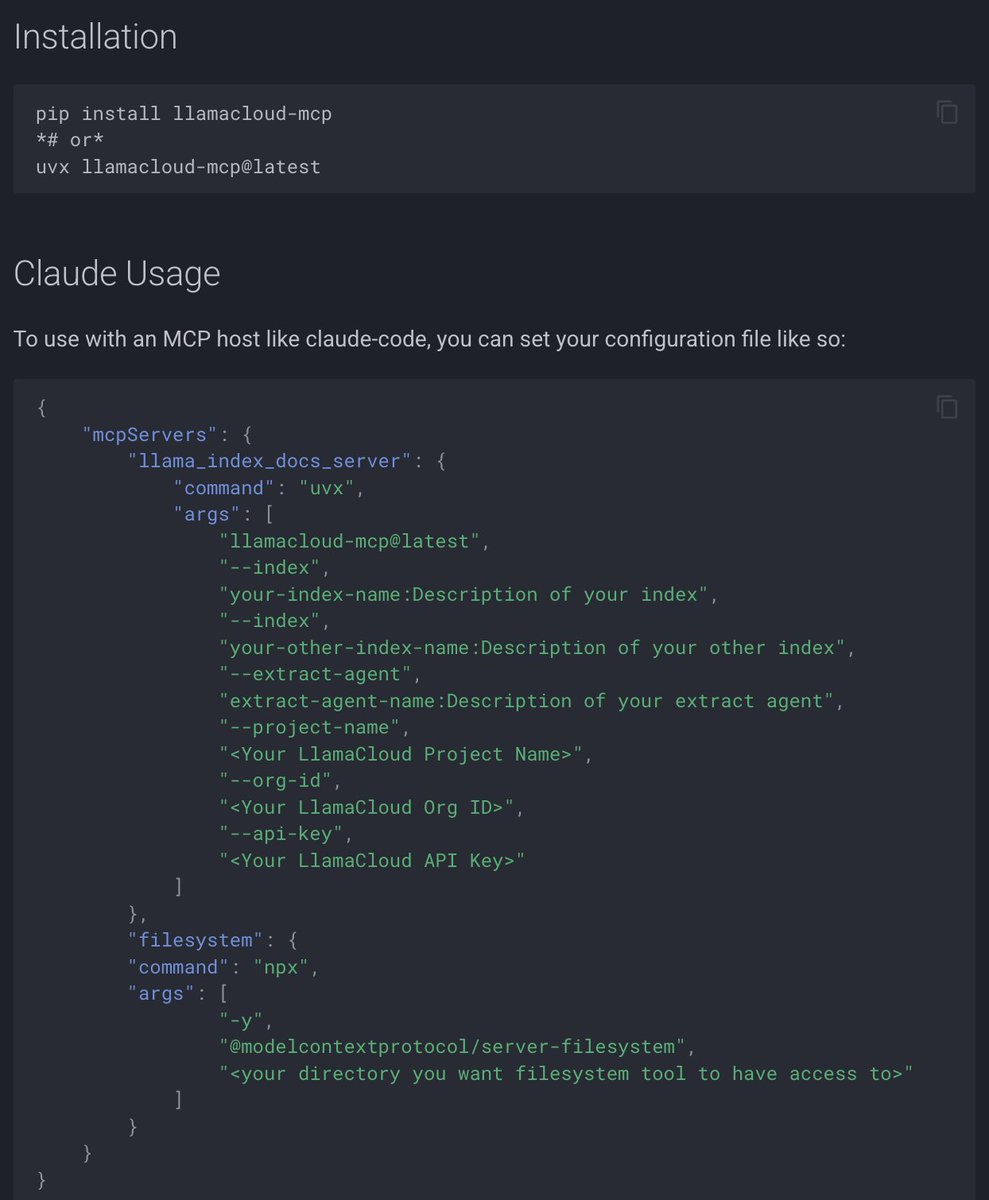
Build data-aware AI applications that can query your private documents and datasets using LlamaIndex with @heroku AI's managed infrastructure. @heroku's new AI platform combines perfectly with our RAG capabilities to create powerful applications that can analyze financial reports, process insurance claims, or power customer support chatbots: 🚀 Use @heroku's managed @anthropicai Sonnet and @cohere embeddings through @OpenAI-compatible APIs - no infrastructure setup required 📊 Store and search vectors in @heroku Postgres with pgvector extension for seamless data retrieval 🔧 Deploy complete RAG pipelines with just a few commands using our Python integration 💼 Build real-world applications like insurance claim assessment agents that combine document retrieval with external APIs Read the full technical guide with code examples: https://t.co/8mdMWlC6cK
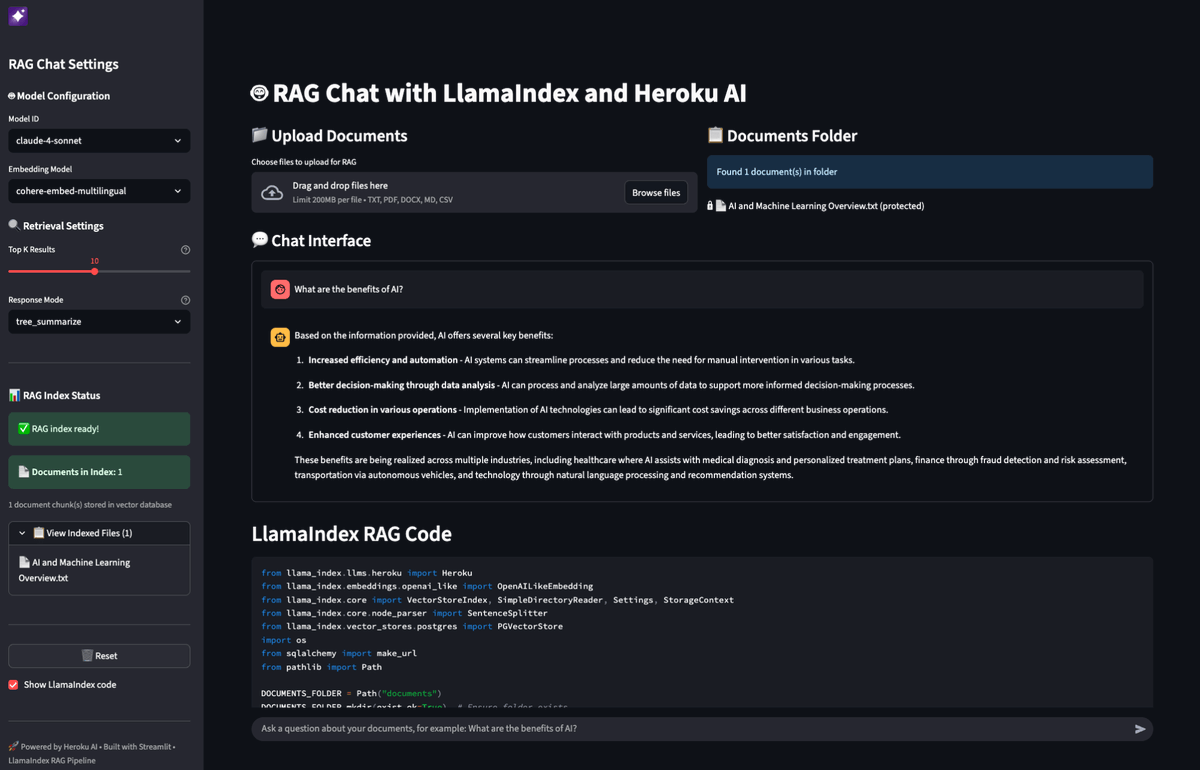
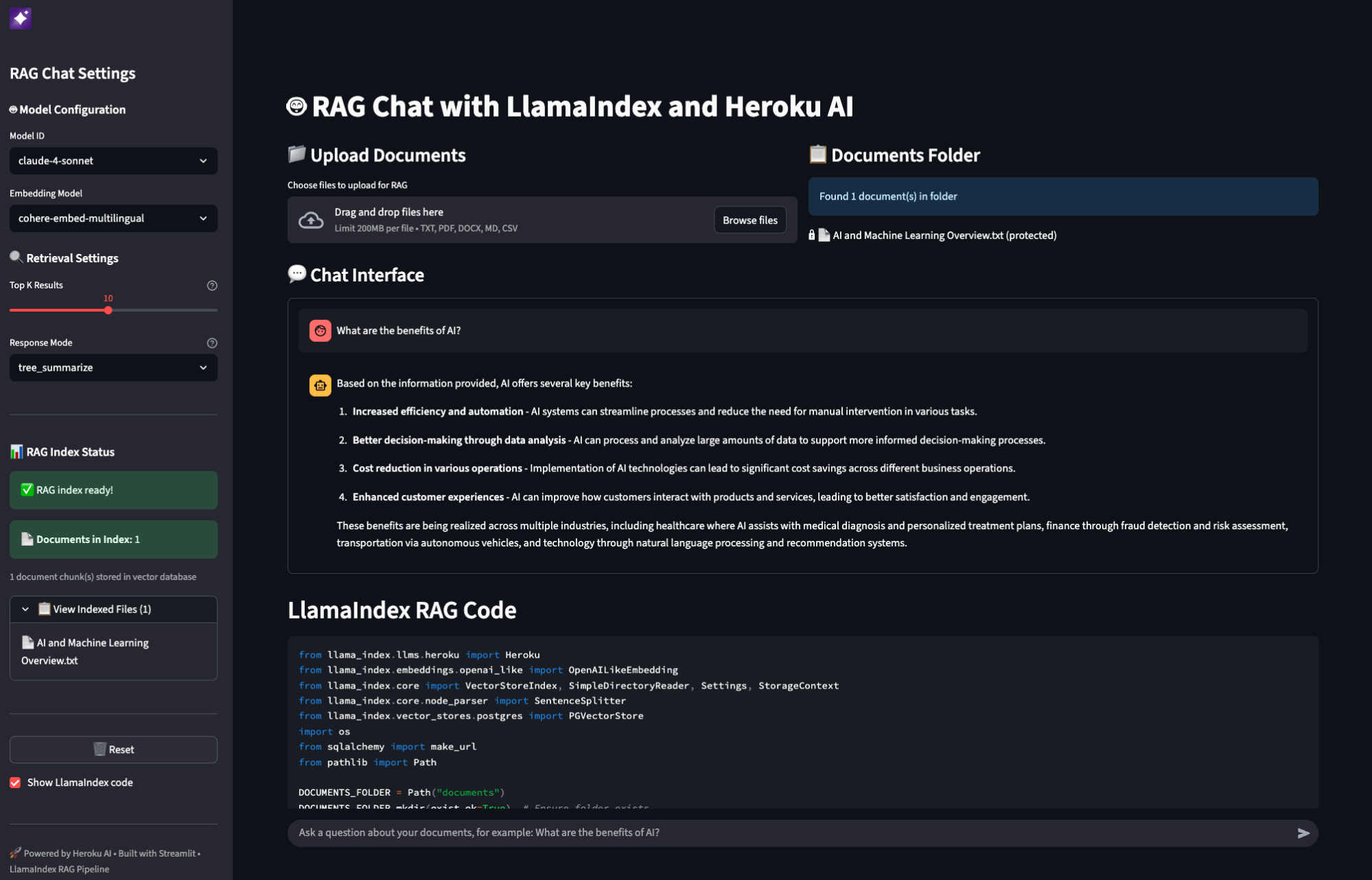
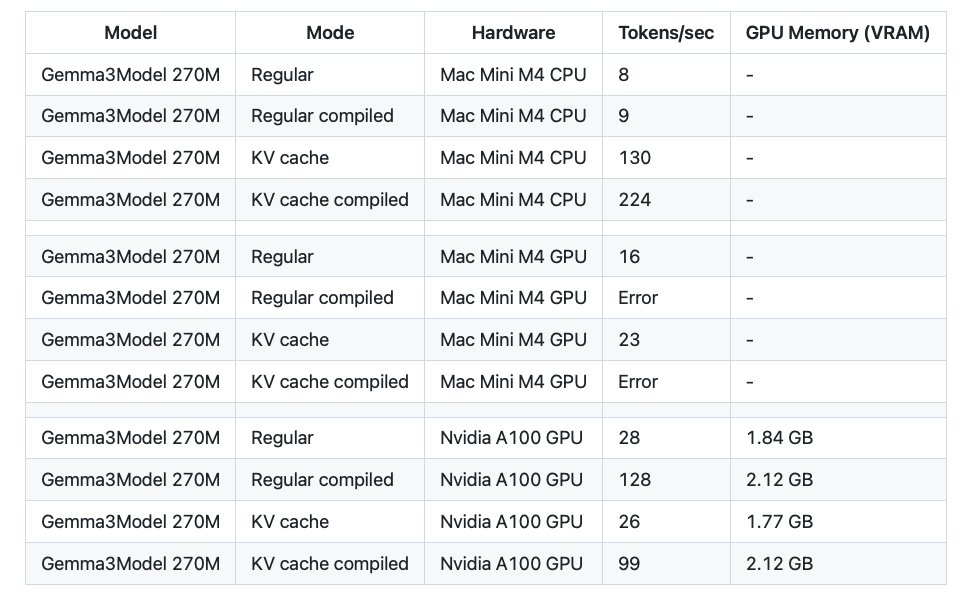
Just added a KV cache to boost the tok/sec efficiency: https://t.co/ybiCGiCPJp
@teortaxesTex Maybe I missed something, but I could only find the Base model, and no model card. Where did they upload the Thinking/Reasoning model? https://t.co/xH2xvIvQEp
Speakers include @clattner_llvm on the open future of AI compute and Mojo, Feifan Fan on voice AI in production, and Chris Hoge on optimizing matmul with the Modular stack. Tune into the livestream: https://t.co/kDm7CpHfxz

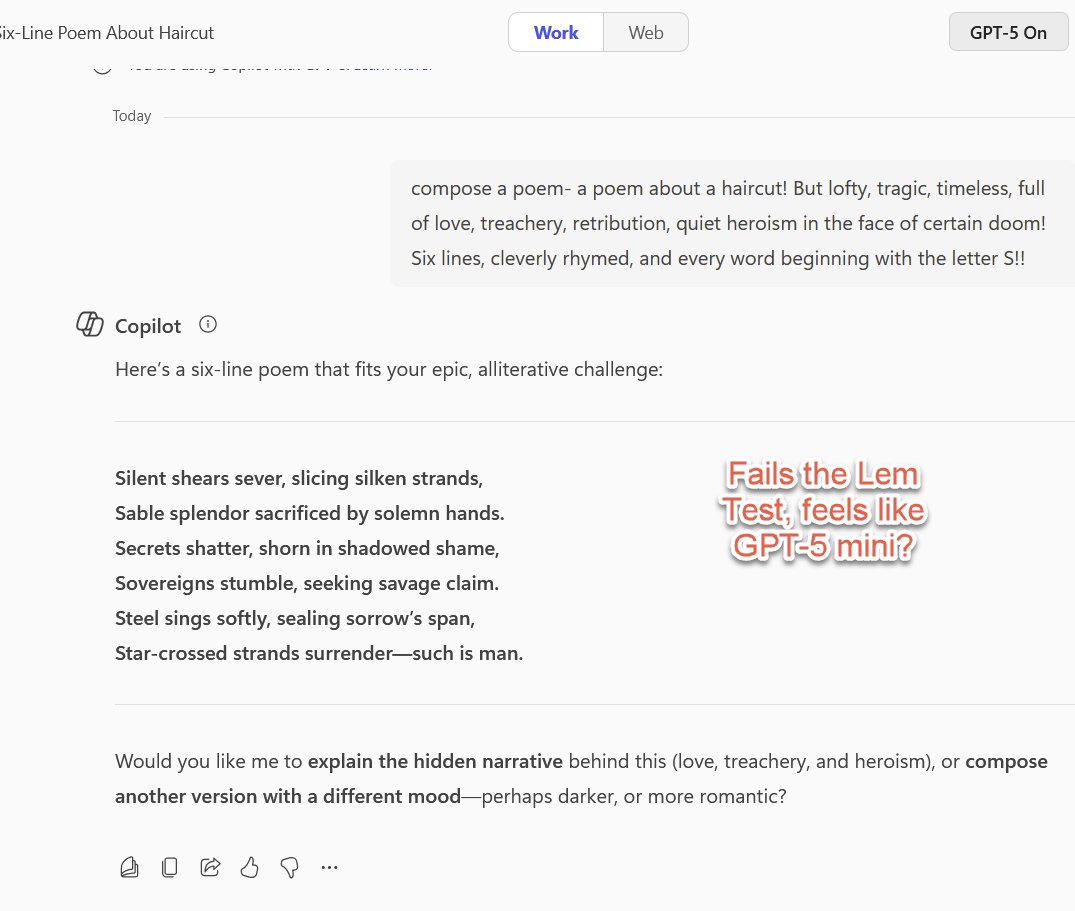
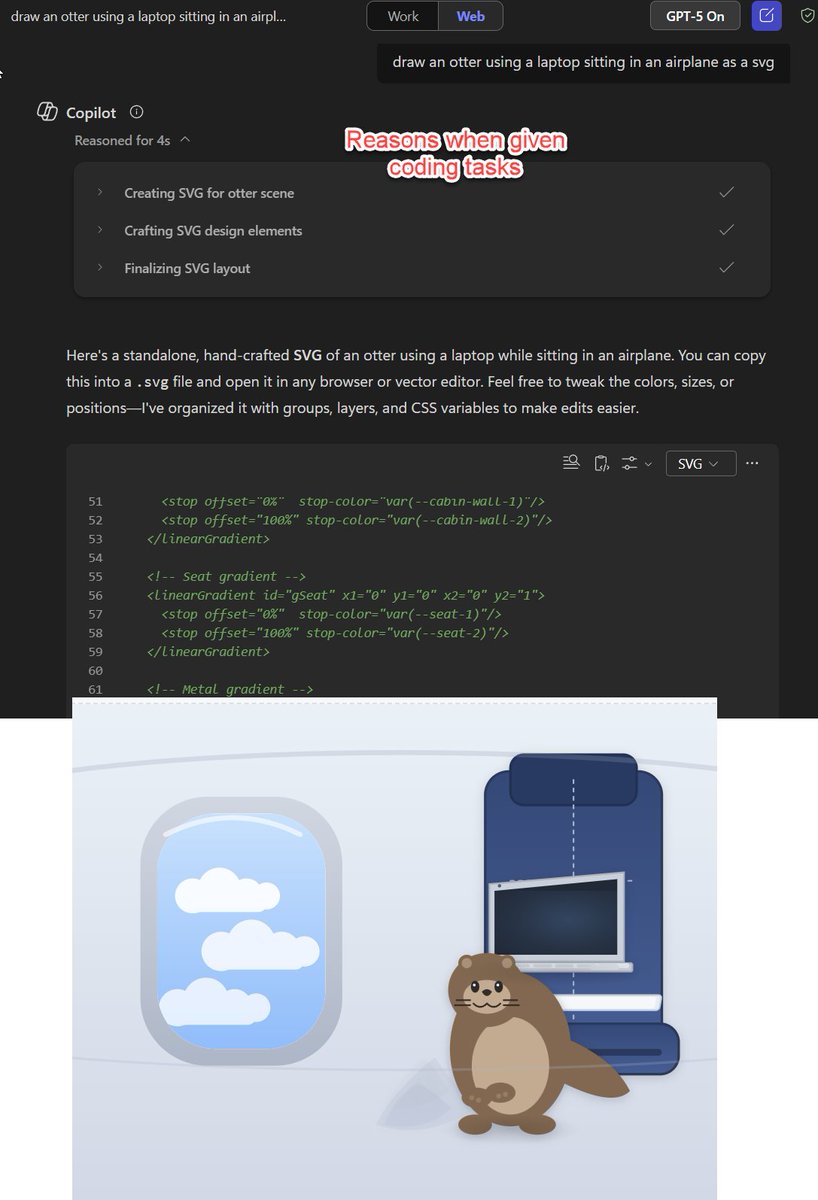
Does Microsoft Copilot use the same GPT-5 router as OpenAI does? I can't get their "GPT-5" to pass me to any good model unless it is explicitly a coding or math task, with no indication of which model I get, which makes the quality of outputs feel very uneven in confusing ways. https://t.co/98HyxA1vXo
Sure, you could use AI to summarize papers and explain them at a level anyone could understand... or you can turn the abstracts into music videos for no reason. The tools are not perfect yet, but the disparate elements (consistent characters, lip syncing, etc.) are evolving fast https://t.co/zq6OLfMRY8
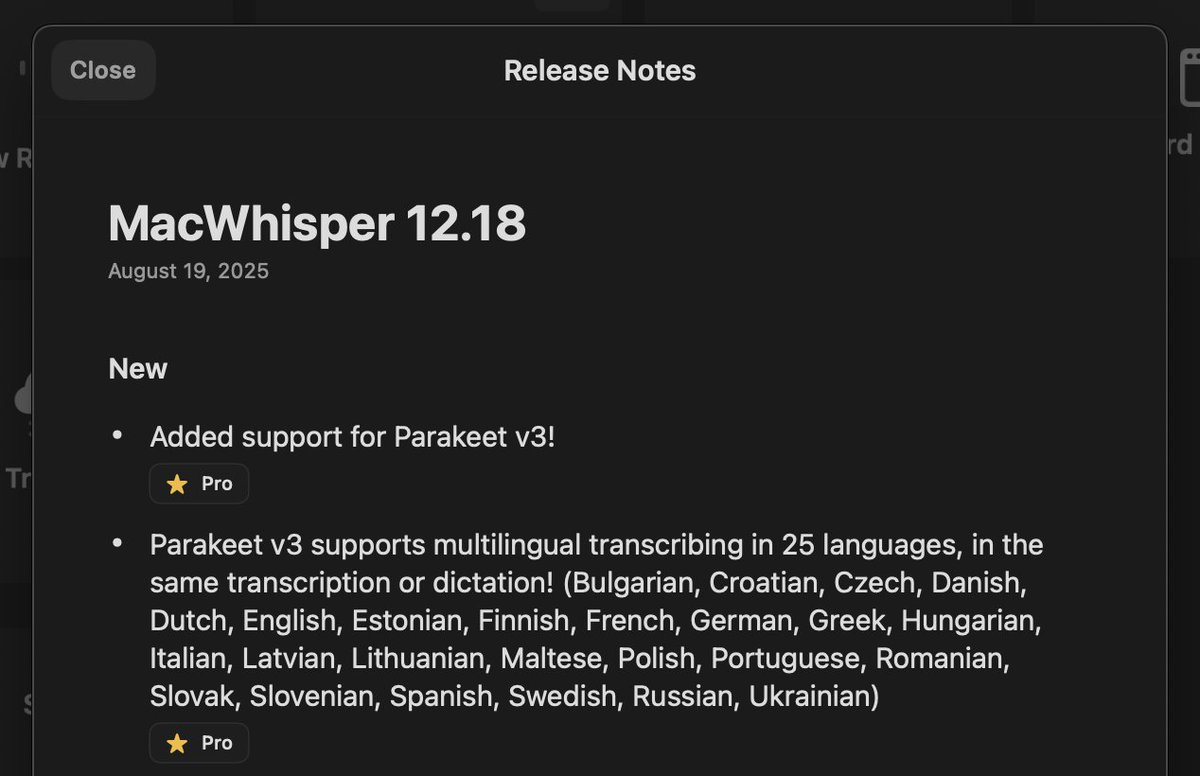
Macwhisper is probably the first app in the market to add the latest @NVIDIAAI Parakeet v3 speech-to-text model, ~3 days after launch. Congrats @id @jordibruin! https://t.co/pG3UUOV4qU
Watched a factory tour of @allencontrol - here are 4 things I learned about their counter-drone tech: 1️⃣ Their "Bullfrog" system uses computer vision + neural networks to distinguish drones from birds, then lets human operators select targets. 2️⃣ The tech is impressive from an engineering standpoint: 360° sky scanning, edge processing, and mechanical safety stops. But it raises the usual questions about autonomous weapons that our industry grapples with. Key insight: they're solving economics - $2 bullets vs $200k interceptor missiles. 3️⃣ The drone threat they're addressing is real - fibre optic tethered drones can't be jammed. But every defence creates a new offence. Classic arms race dynamics.
The wait is over. The world’s first AI detection app is here. 🚨📱 AI or Not application is now available on both the App store and Google play store. Download now!!!🚀 https://t.co/nUfq7DPDsN
✅ Half a million downloads? No big deal. #NVIDIACosmos Reason — an open, customizable, 7B-parameter VLM — is helping shape the future of physical AI & robotics. 🤖 See why it's one of the top 10 most downloaded NVIDIA models on @huggingface right now ➡️ https://t.co/Fio0fSeUK6

SailGP RaceScape XR delivers an expansive volumetric dashboard for Apple Vision Pro owners to learn more about competitive high-speed sail racing: https://t.co/VztcxTxju3

https://t.co/6iZZQ9OYvN

Ovis2.5 Technical Report https://t.co/0QIhnGI7O4

discuss with author: https://t.co/cS4bBSF6vh

ComoRAG A Cognitive-Inspired Memory-Organized RAG for Stateful Long Narrative Reasoning https://t.co/9VFR9TglKz
