@llama_index
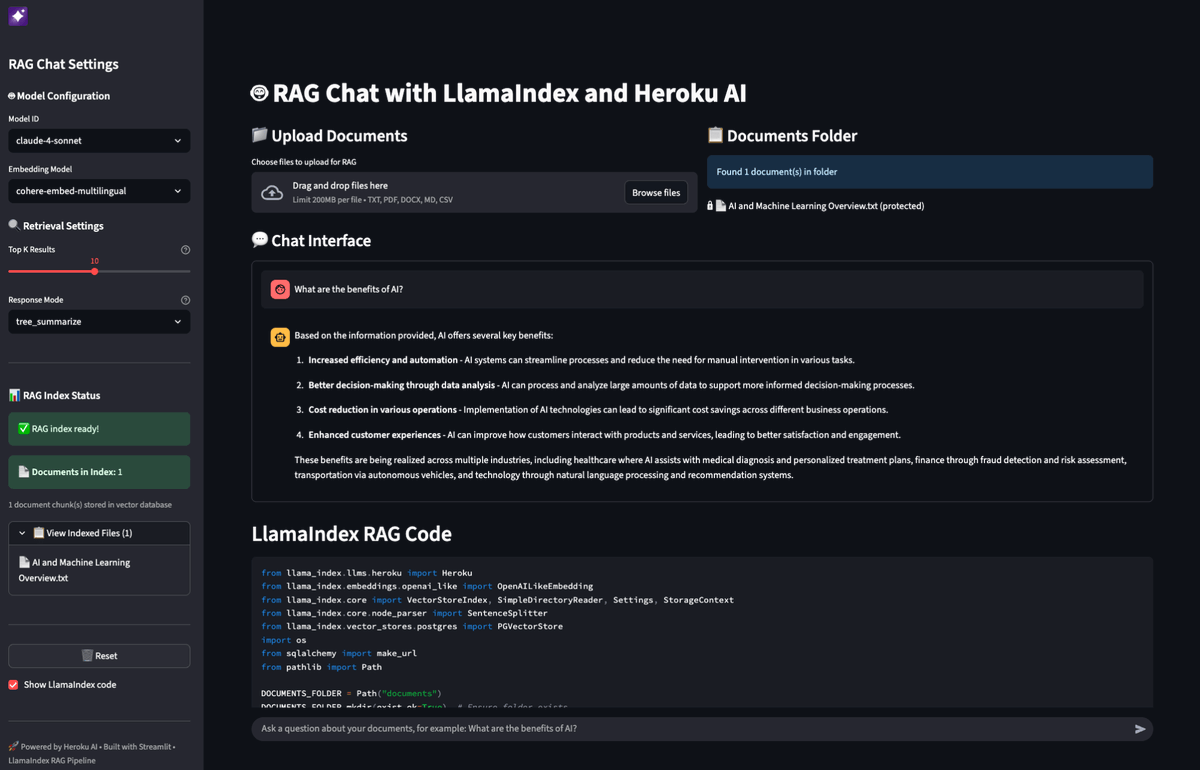
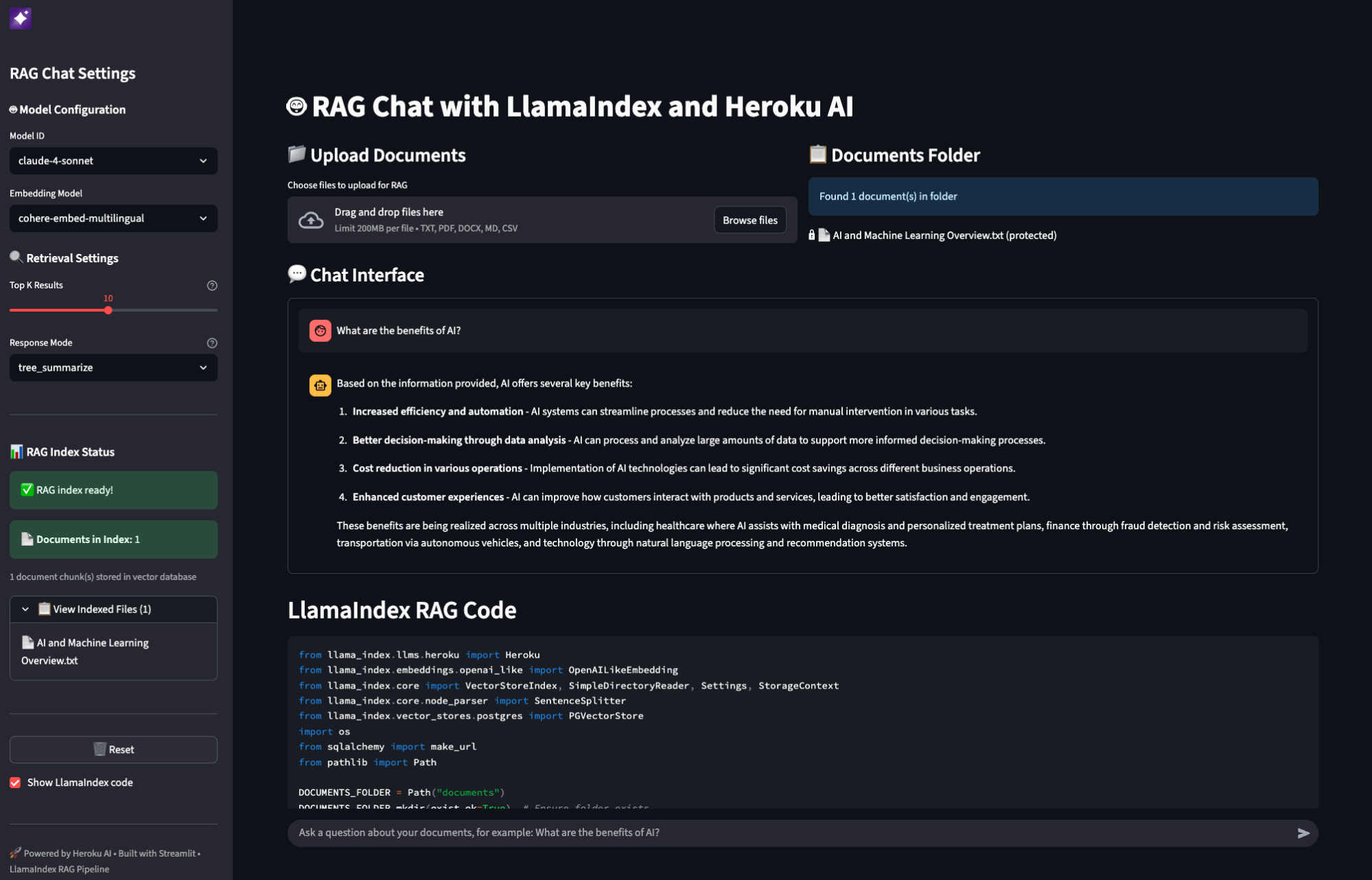
Build data-aware AI applications that can query your private documents and datasets using LlamaIndex with @heroku AI's managed infrastructure. @heroku's new AI platform combines perfectly with our RAG capabilities to create powerful applications that can analyze financial reports, process insurance claims, or power customer support chatbots: 🚀 Use @heroku's managed @anthropicai Sonnet and @cohere embeddings through @OpenAI-compatible APIs - no infrastructure setup required 📊 Store and search vectors in @heroku Postgres with pgvector extension for seamless data retrieval 🔧 Deploy complete RAG pipelines with just a few commands using our Python integration 💼 Build real-world applications like insurance claim assessment agents that combine document retrieval with external APIs Read the full technical guide with code examples: https://t.co/8mdMWlC6cK