Your curated collection of saved posts and media
Today, we're launching the Runway Game Worlds Beta. Over the last few months, we have been working on research and products that are moving us closer toward a future where you will be able to explore any character, story or world in real time. While generating the pixels of these experiences is one aspect of this new frontier, another is the need for novel mechanics and interfaces. From how stories unfold to how your choices affect the worlds you’re simulating. Today’s beta release marks a first step in this direction, learn more below. (1/5)
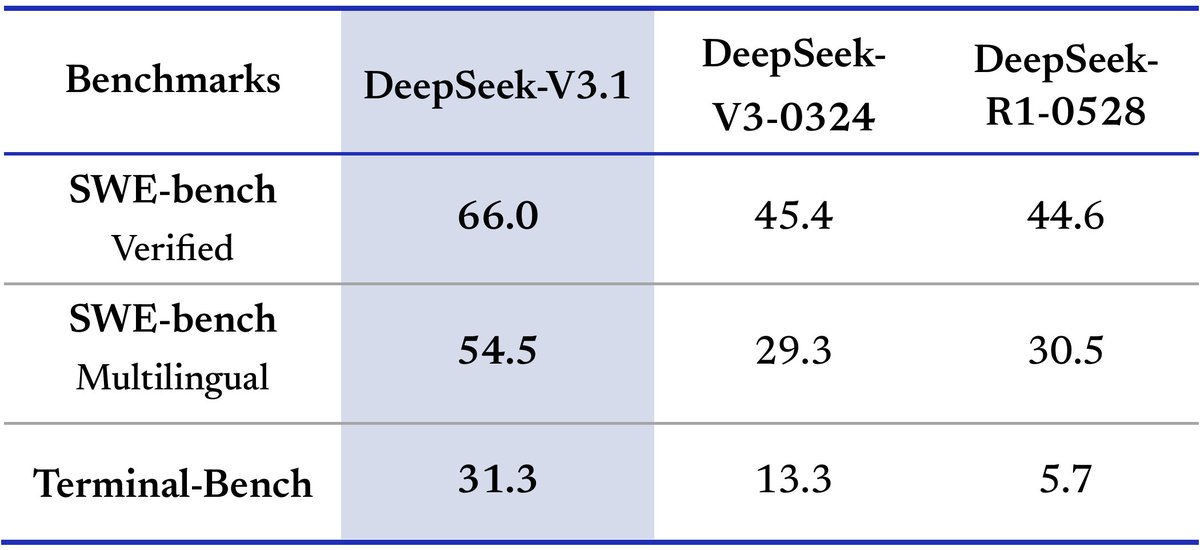
🚨 China's DeepSeek is at it again, with the best open source model drop, V3.1 scoring 66% on SWE-Bench and costing.. $0.56/M input (2x cheaper than GPT-5) $1.68/M output (6x cheaper) The whale is back. https://t.co/NTirIMpJOu
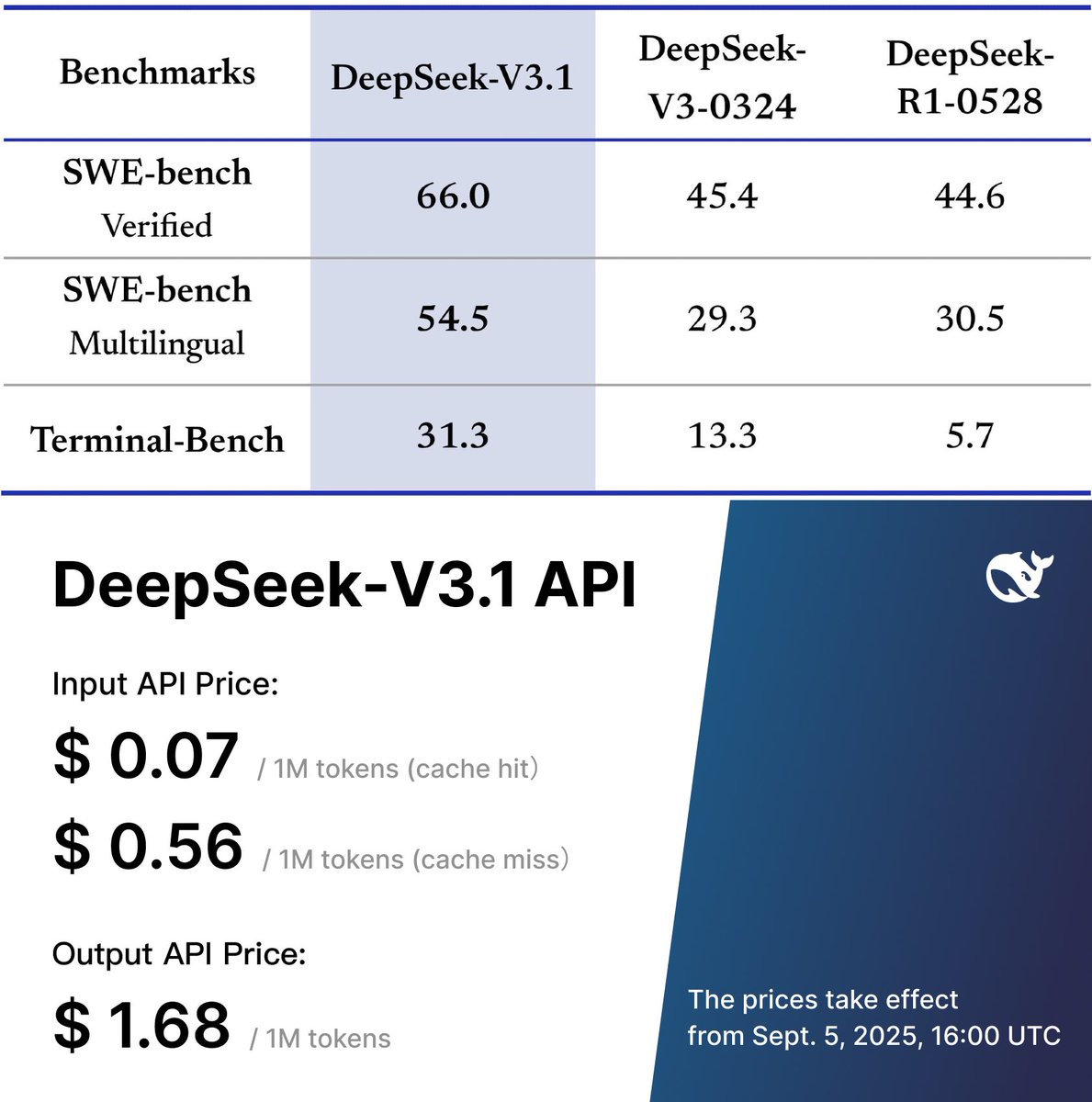
DeepSeek-V3.1 is now available in anycoder Hybrid inference: Think & Non-Think — one model, two modes Stronger agent skills: Post-training boosts tool use and multi-step agent tasks https://t.co/gv4FEdJMuY
app: https://t.co/esPDyHDu94

@deepseek_ai Now Available and default model in anycoder: https://t.co/esPDyHDu94

DeepSeek-V3.1 ball bouncing inside a spinning hexagon with @FireworksAI_HQ in anycoder, one shot https://t.co/67rVlpictJ
app: https://t.co/esPDyHDu94

I love them so much https://t.co/grkPvVpW1P
@zcbenz Yeah that's how they used to be implemented, using im2col(). It's also how we started teaching implementing them in https://t.co/GEOZunWoXj.

DEEPSEEK V3.1 INSTRUCT IS OUTTT!! https://t.co/CpKlbSYn8O

DEEPSEEK V3.1 INSTRUCT IS OUTTT!! https://t.co/CpKlbSYn8O

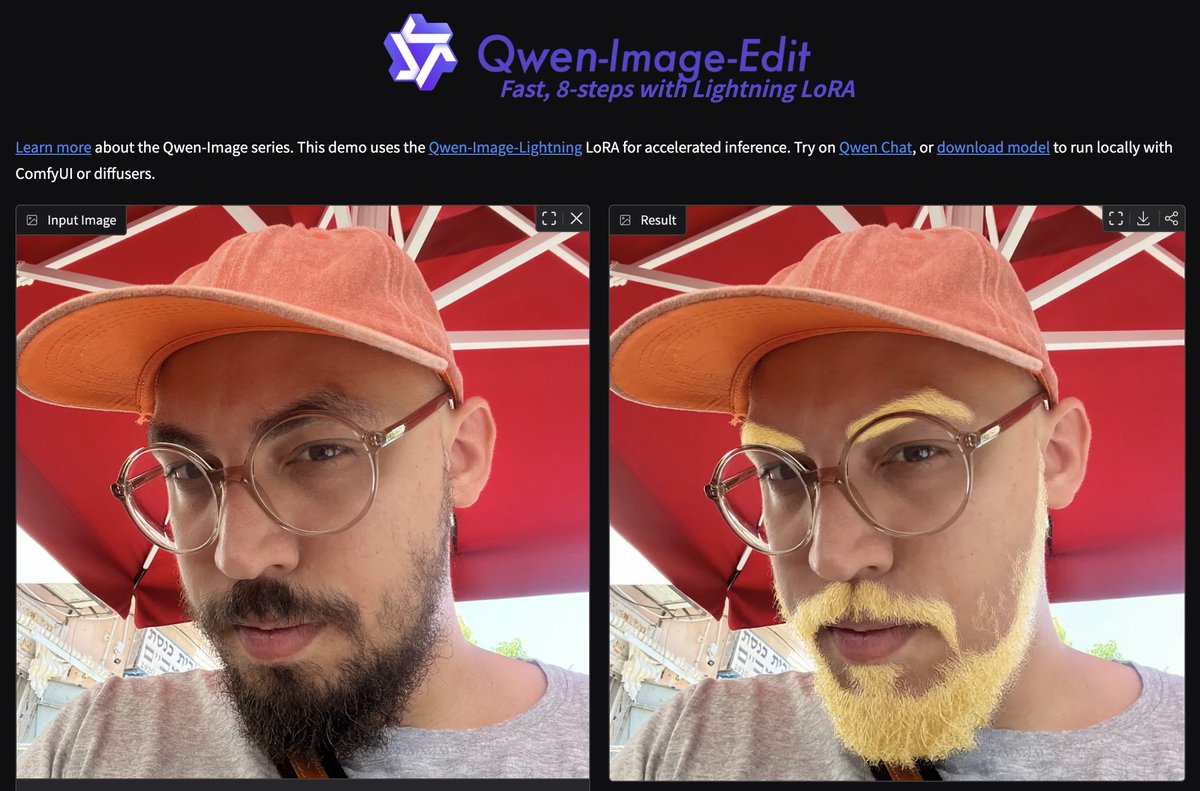
Qwen Image Edit works too well with lightx2v LoRA to run with just 8 and 4 steps, wtf? in my experience, 8 steps keeps the quality of the edits at the same level as the original model, at a 12x speedup 💨 (ofc i built a demo for it) https://t.co/jrO8kdoJ48
The beatings (free books) will continue until everyone looks at their data: 1. LLM Evals FAQ: https://t.co/BzEHwvobz5 2. Beyond Naive RAG: Practical Advanced Methods https://t.co/x2870kdHoZ

Generic evals and metrics don’t reflect real-world failure modes. You need customized, domain-specific evals explicitly tailored for your application or agents for true reliability. On this week’s Chain of Thought podcast, AI consultant and evaluation expert @HamelHusain breaks down why most teams experience “the illusion of monitoring” when using generic metrics that don’t account for real production failures. Instead of chasing dashboards, Hamel argues for: – Manual error analysis grounded in real user logs – Custom metrics aligned to product risks, not vanity – Iterative feedback loops that surface failure modes over time Learn more about creating customized evals tailored to your domain-specific risks in this week’s episode with Hamel, our COO and Co-founder @atinsanyal, and host @ConorBronsdon 👇
Loved the "AI Evals for Engineers & PMs" course https://t.co/f5WVix8Qs0 by @HamelHusain and @sh_reya. It takes “look at your data” from slogan to method: inspect interaction traces closely, build error taxonomies, rigorously tune automated evals, then optimize your prompts & pipeline. Highly recommended!

Loved the "AI Evals for Engineers & PMs" course https://t.co/f5WVix8Qs0 by @HamelHusain and @sh_reya. It takes “look at your data” from slogan to method: inspect interaction traces closely, build error taxonomies, rigorously tune automated evals, then optimize your prompts & pipeline. Highly recommended!

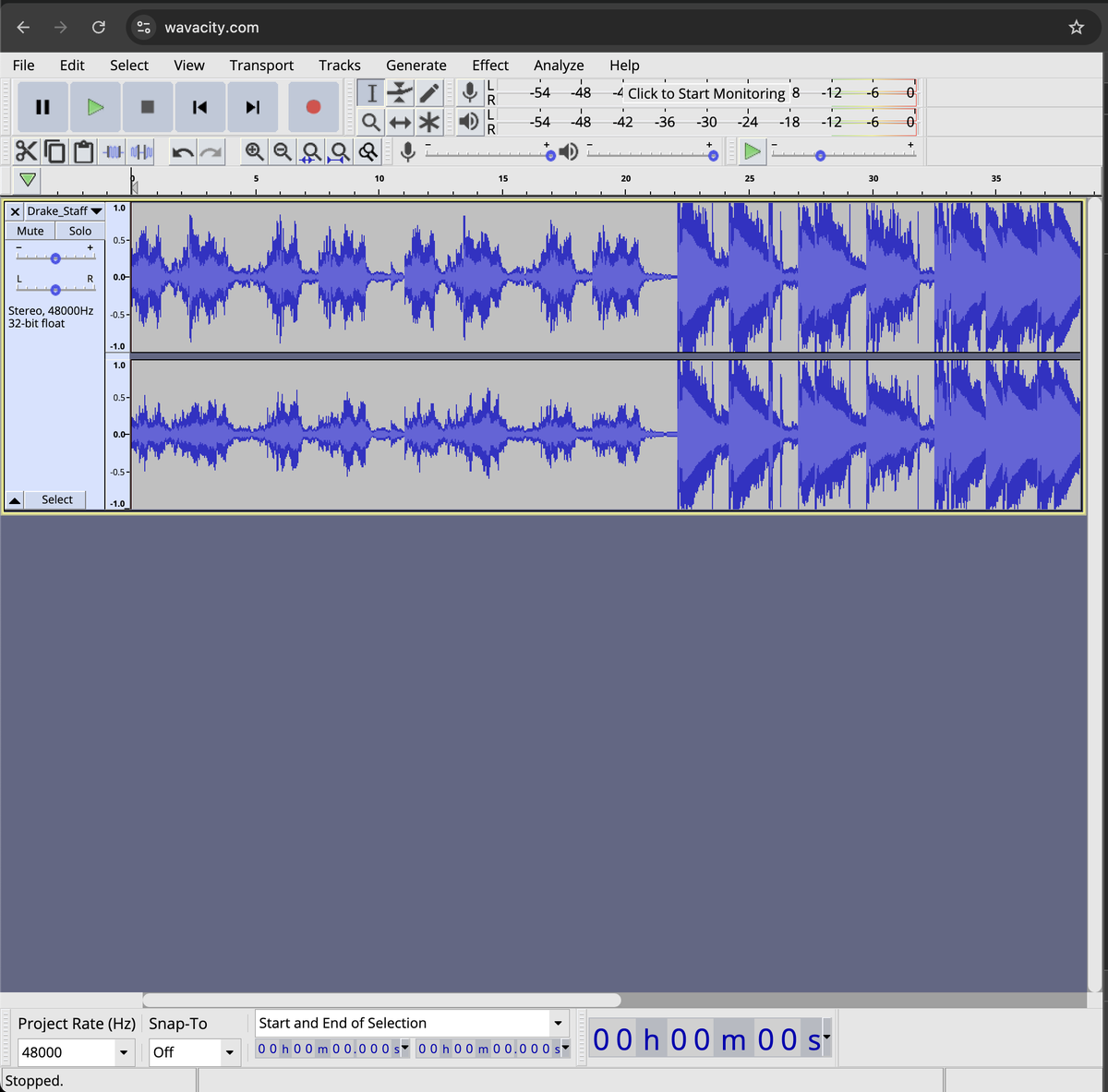
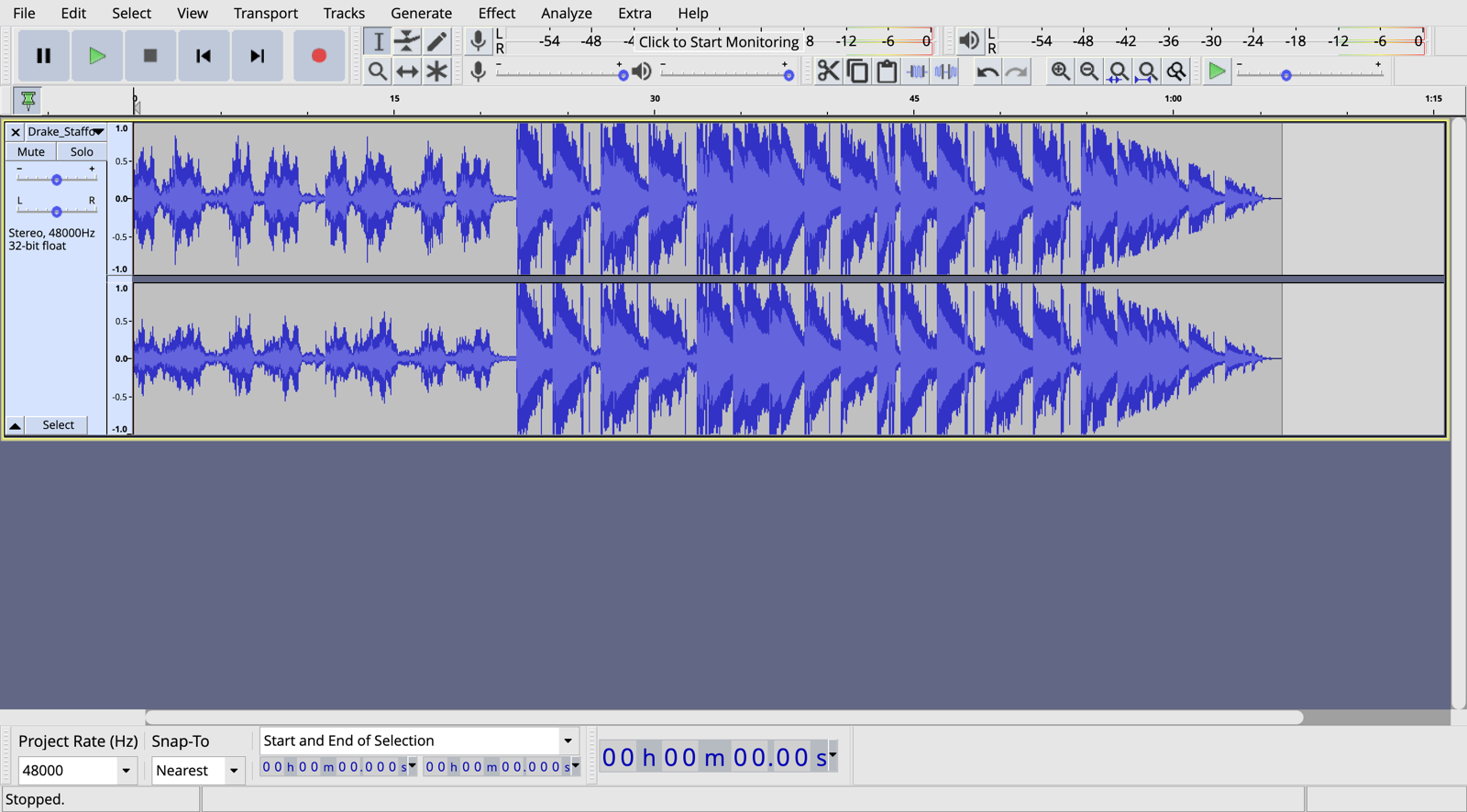
Oh yes! This is exactly what I wanted Audacity ported to web So cool: https://t.co/F5BfPTc2w9 https://t.co/p7SG1CIStb
Hunyuan-GameCraft builds on the Hunyuan-Video model adding the ability to integrate egocentric and third-person perspective camera movements into generated videos. An open weight "Genie-like" model! My first experiments on a single NVidia 5090 (32G). Leverages a history-conditioned training strategy for long-term consistency.
The website of Alec Radford. Inventor of GPT. https://t.co/HkYz6cnYiG
Yann LeCun: "If you are interested in human-level ai, don't work on LLMs" https://t.co/lX0dXWTemh

Small businesses, listen up! Just in time for the San Francisco “summer,” you no longer have to pay to put tables and chairs on the sidewalk. A quick, free registration is all it takes, and you’re good to go. Through our permit reform initiative, PermitSF, my administration is cutting red tape and making it easier for small businesses to thrive.
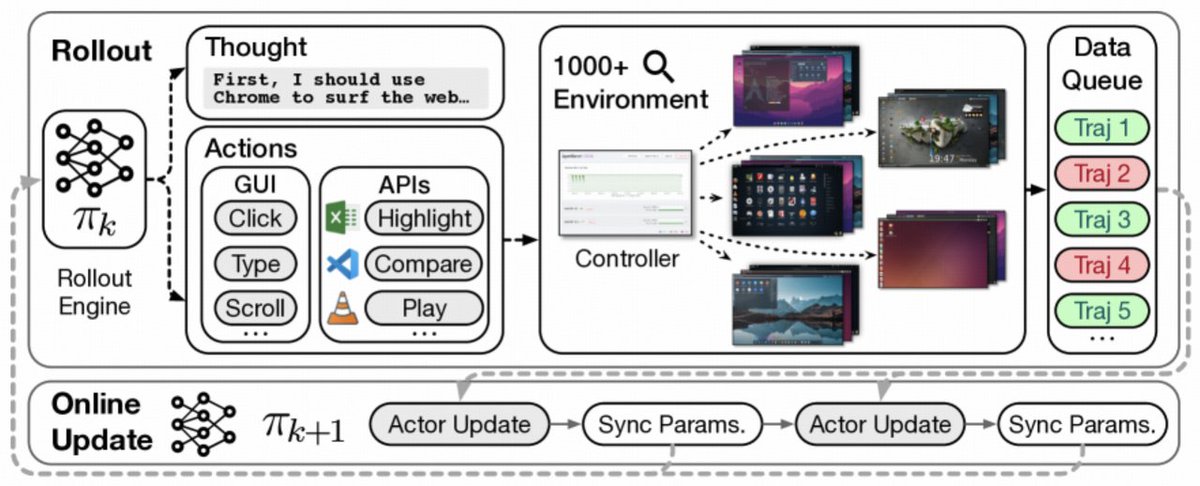
Introducing ComputerRL, a framework for autonomous desktop intelligence that enables agents to operate complex digital workspaces skillfully. https://t.co/86XVYd9xCb ComputerRL features the API-GUI paradigm, which unifies programmatic API calls and direct GUI interaction to address the inherent mismatch between machine agents and human-centric desktop environments.
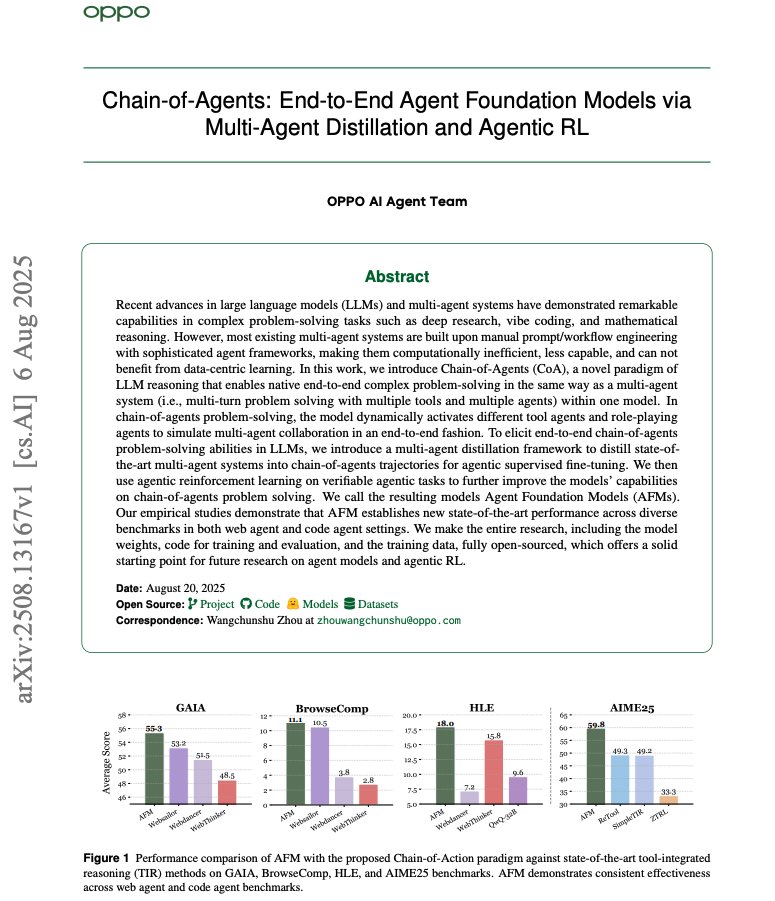
Overview This work proposes training single models to natively behave like multi‑agent systems, coordinating “role‑playing” and tool agents end‑to‑end. They distill strong multi‑agent frameworks into CoA trajectories, then optimize with agentic RL on verifiable tasks. https://t.co/hR4PTUEQpa
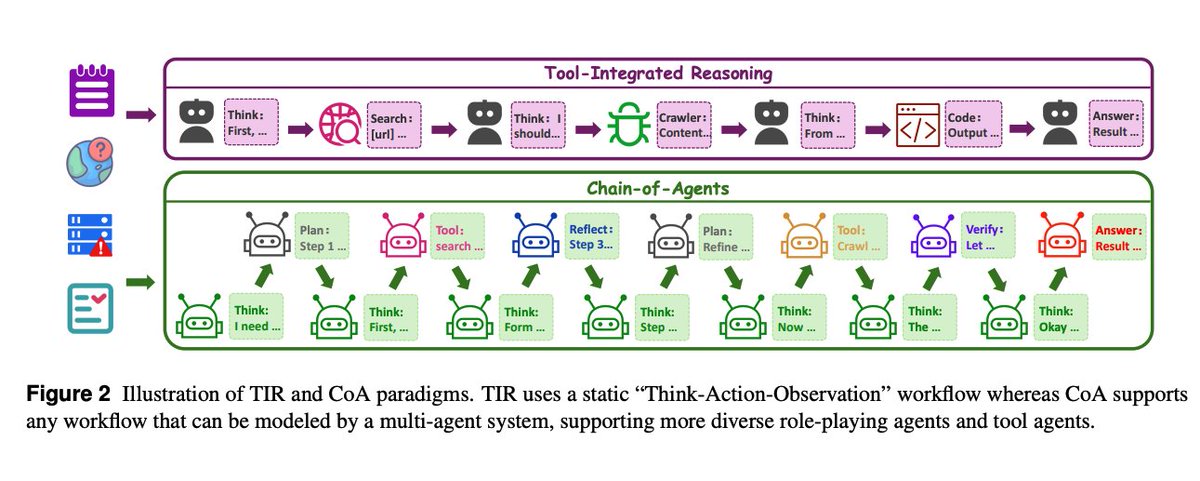
Paradigm shift CoA generalizes ReAct/TIR by dynamically activating multiple roles and tools within one model, preserving a single coherent state while cutting inter‑agent chatter. https://t.co/uYeDRhPqKl

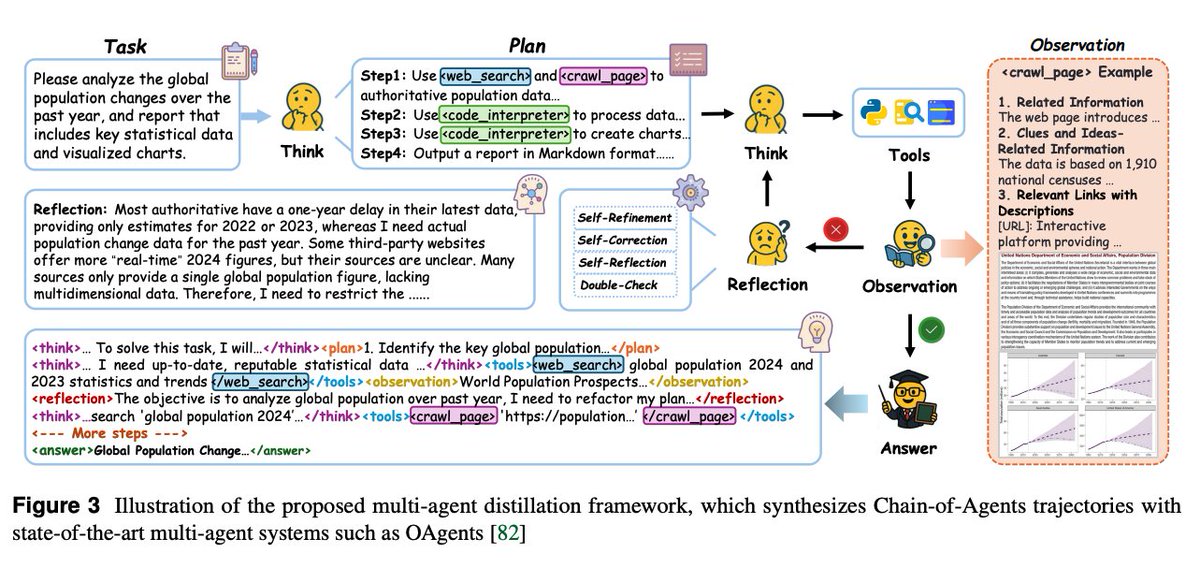
Training recipe 1) Multi‑agent distillation turns successful OAgents runs into CoA‑formatted traces with planning, tool calls, observations, and reflection, filtered for difficulty and quality; 2) Agentic RL targets hard queries where tools matter, with simple binary rewards via LLM‑as‑Judge for web tasks and executable or exact‑match rewards for code/math.
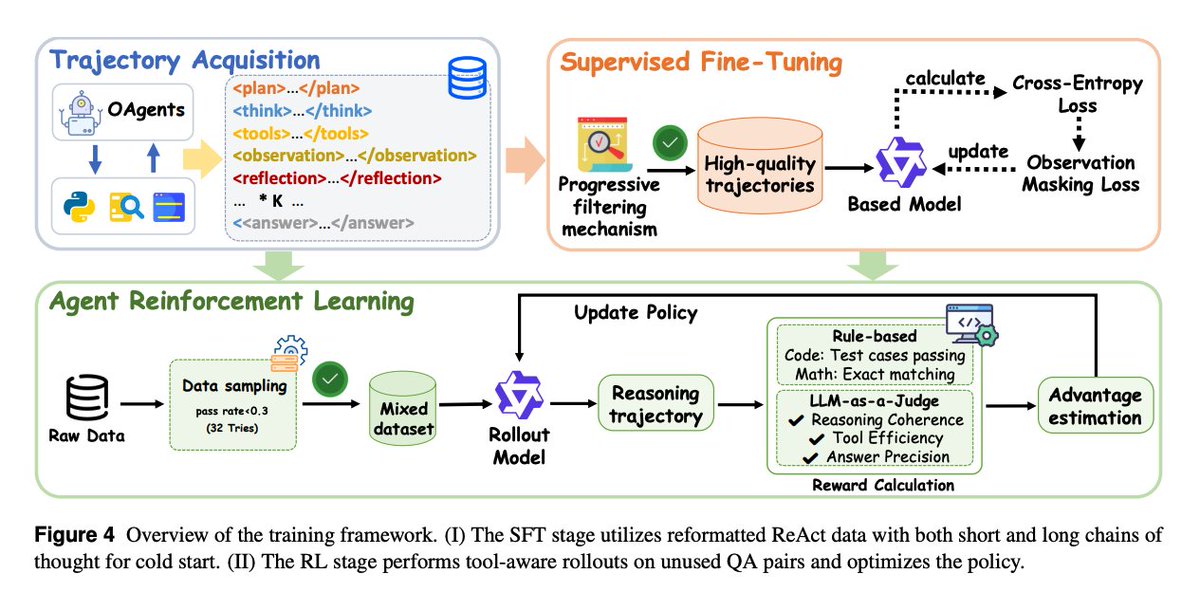
Training framework Stage 1 (SFT) – uses reformatted ReAct-style data (both short and long reasoning chains) to give the model a solid “cold start.” Progressive filtering ensures only high-quality trajectories are used, emphasizing coherence, tool efficiency, and reflective reasoning. Stage 2 (RL) – builds on the SFT base. The model performs tool-aware rollouts on unused QA pairs. Rewards are computed from task correctness (via LLM-as-Judge, exact match, or test cases), and policy updates improve tool coordination and reasoning robustness.
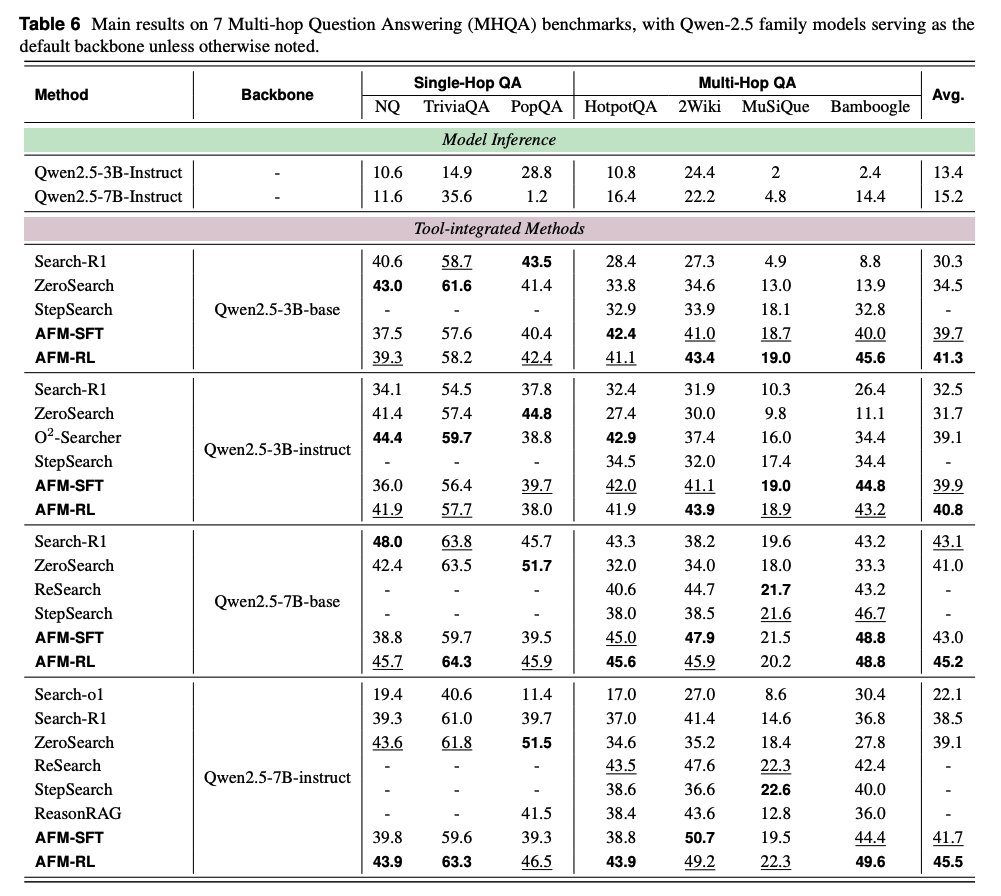
Main results With Qwen‑2.5‑32B backbones, Agent Foundation Models (AFM) sets new pass@1 on GAIA 55.3, BrowseComp 11.1, HLE 18.0, and leads WebWalker 63.0; it also tops multi‑hop QA suites across sizes. https://t.co/60HHo1wUj2
Code + math AFM‑RL‑32B reaches AIME25 59.8, MATH500 94.6, OlympiadBench 72.1, and LiveCodeBench v5 47.9, beating prior TIR methods including ReTool and Reveal. https://t.co/Rg9RWIMSVW
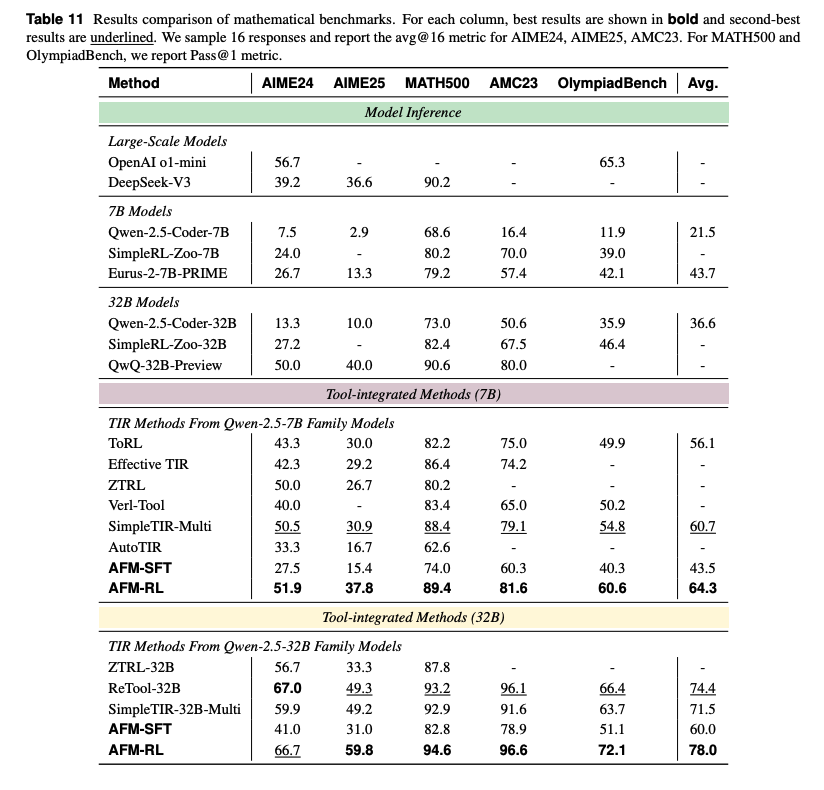
Efficiency and robustness Compared to traditional multi‑agent systems, AFM cuts inference tokens and tool calls substantially. The paper reports an 84.6% token cost reduction while staying competitive. It also generalizes to unseen tools better when strict formatting is required.
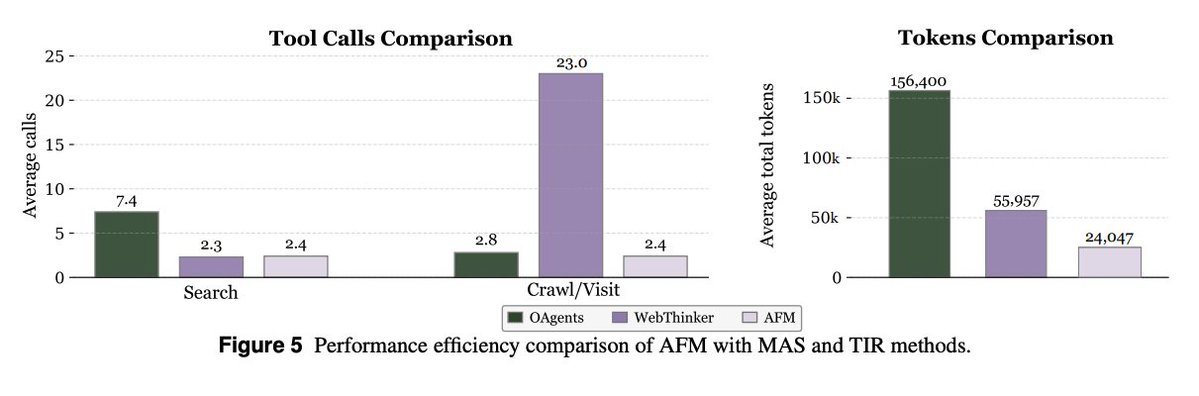
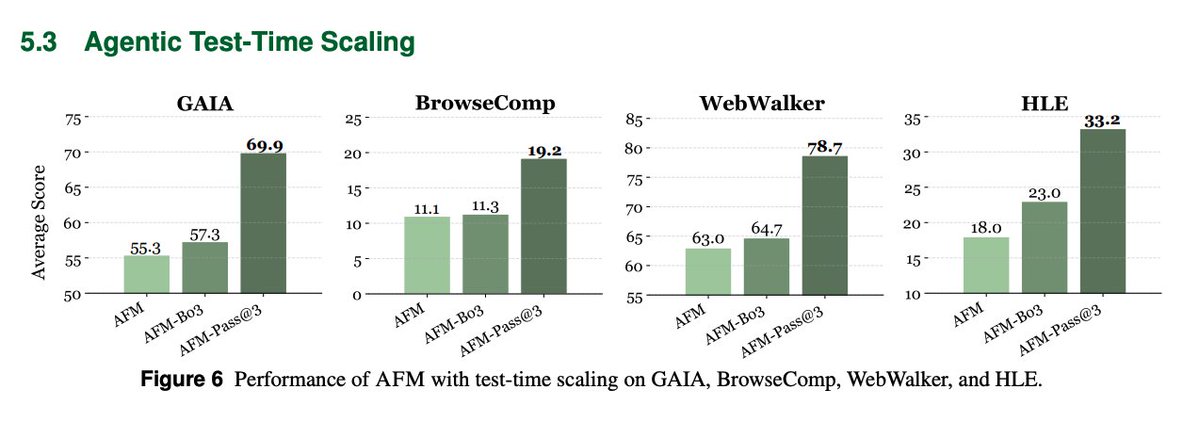
Test‑time scaling Best‑of‑3 and pass@3 markedly boost AFM, e.g., GAIA 69.9 and HLE 33.2, closing the gap with larger proprietary agent stacks. Overall, Chain-of-Agents enables training single-agent foundation models that natively simulate multi-agent collaboration, combining multi-agent distillation with agentic RL to achieve state-of-the-art results Project + Code + Models: https://t.co/yeI0JTO6ok Paper: https://t.co/vxzeM4x1dy

Chain-of-Agents Interesting idea to train a single model with the capabilities of a multi-agent system. 84.6% reduction in inference cost! Distillation and Agentic RL are no joke! Here are my notes: https://t.co/cwHNROfoR2
🚀 New case study: @StackAI_HQ + LlamaCloud ✔️ 1M+ docs processed with high-accuracy parsing ✔️ Faster, smarter enterprise document agents ✔️ Trusted by finance, insurance & more Full story 👉 https://t.co/r6NFPZJVFs #GenAI #AIagents #EnterpriseAI
