@omarsar0
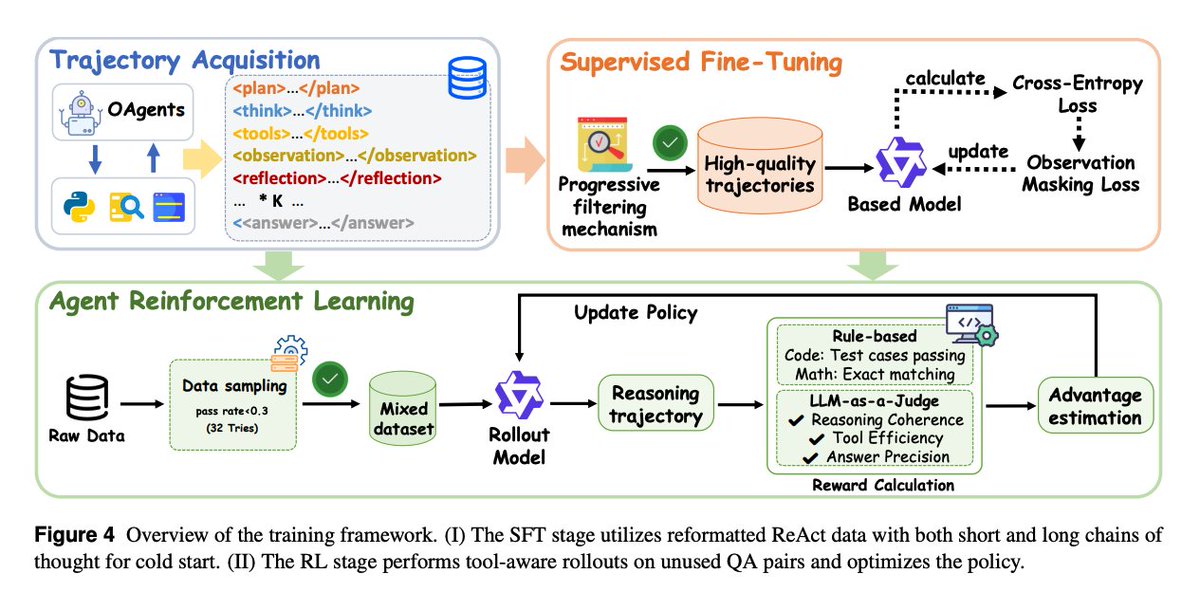
Training framework Stage 1 (SFT) – uses reformatted ReAct-style data (both short and long reasoning chains) to give the model a solid “cold start.” Progressive filtering ensures only high-quality trajectories are used, emphasizing coherence, tool efficiency, and reflective reasoning. Stage 2 (RL) – builds on the SFT base. The model performs tool-aware rollouts on unused QA pairs. Rewards are computed from task correctness (via LLM-as-Judge, exact match, or test cases), and policy updates improve tool coordination and reasoning robustness.