Your curated collection of saved posts and media
Why it matters With comparable cost, Avengers‑Pro outperforms GPT‑5‑medium by about 7% average accuracy; with comparable accuracy, it reduces cost by about 27%. Hitting ~90% of GPT‑5‑medium’s accuracy costs ~63% less. https://t.co/ZIbNOoc9Nx
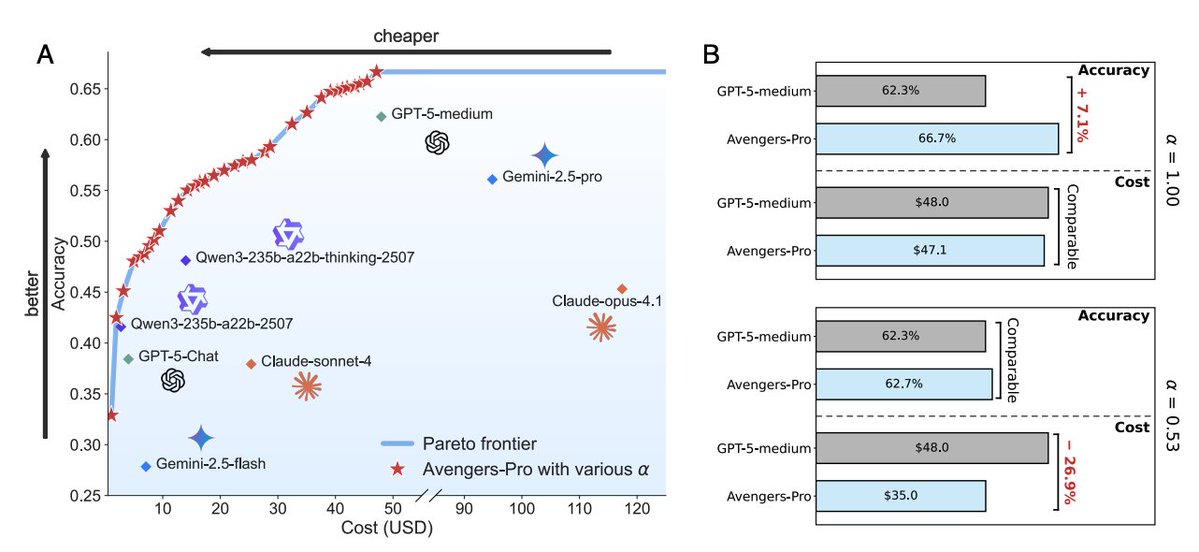
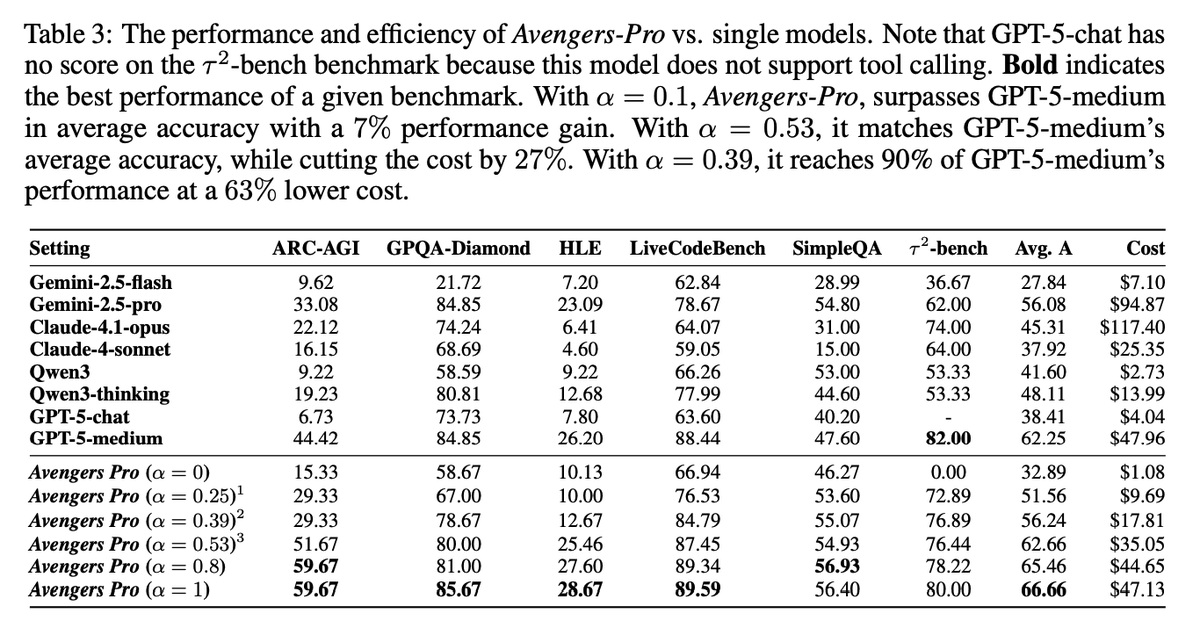
Setup Ensemble of 8 models (GPT‑5‑chat/medium, Claude‑4.1‑opus/Sonnet‑4, Gemini‑2.5‑pro/flash, Qwen3 235B and thinking). Evaluated on GPQA‑Diamond, HLE, ARC‑AGI, SimpleQA, LiveCodeBench, and τ²‑bench. Pricing via OpenRouter informs per‑cluster cost scoring. Avengers-Pro consistently outperforms or matches the strongest single models while lowering costs. With α=1 it achieves the highest accuracy (66.66%, +7% over GPT-5-medium), and with α=0.53 it matches GPT-5-medium’s accuracy at 27% less cost; notably, with α=0.39 it sustains 90% of GPT-5-medium’s performance at 63% lower cost.
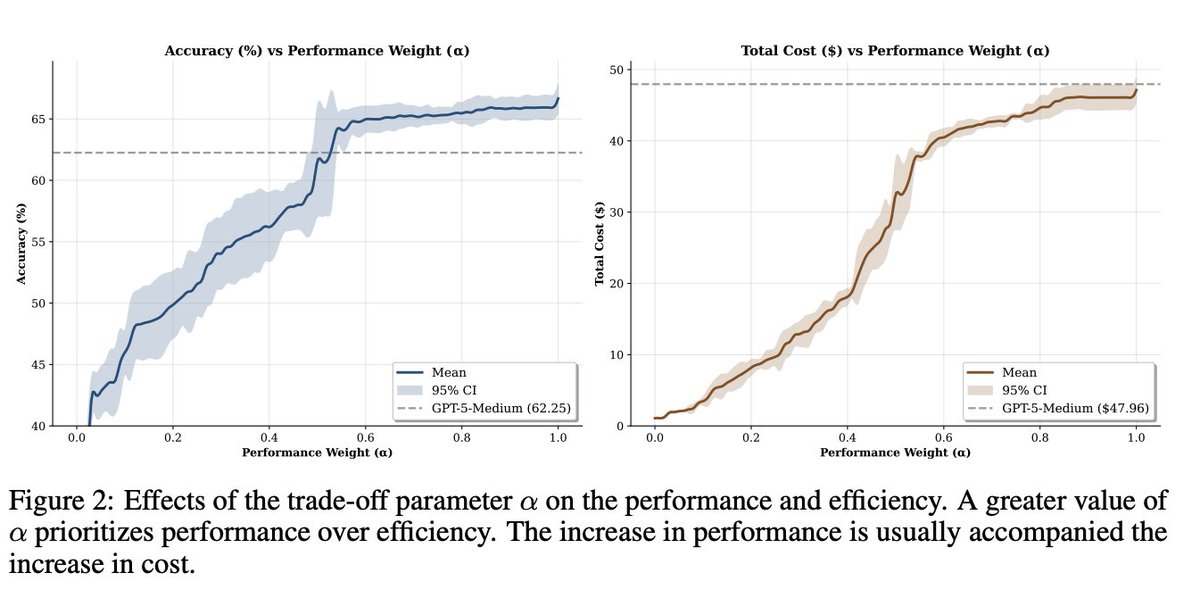
Knobs that matter α tunes performance vs efficiency; accuracy rises fast until ~0.6 while cost stays low until ~0.4 then climbs. Implementation uses k‑means with k=60, Qwen3‑embedding‑8B (4096‑d) and top‑p=4 nearest clusters at inference. https://t.co/ExTscN7AeU
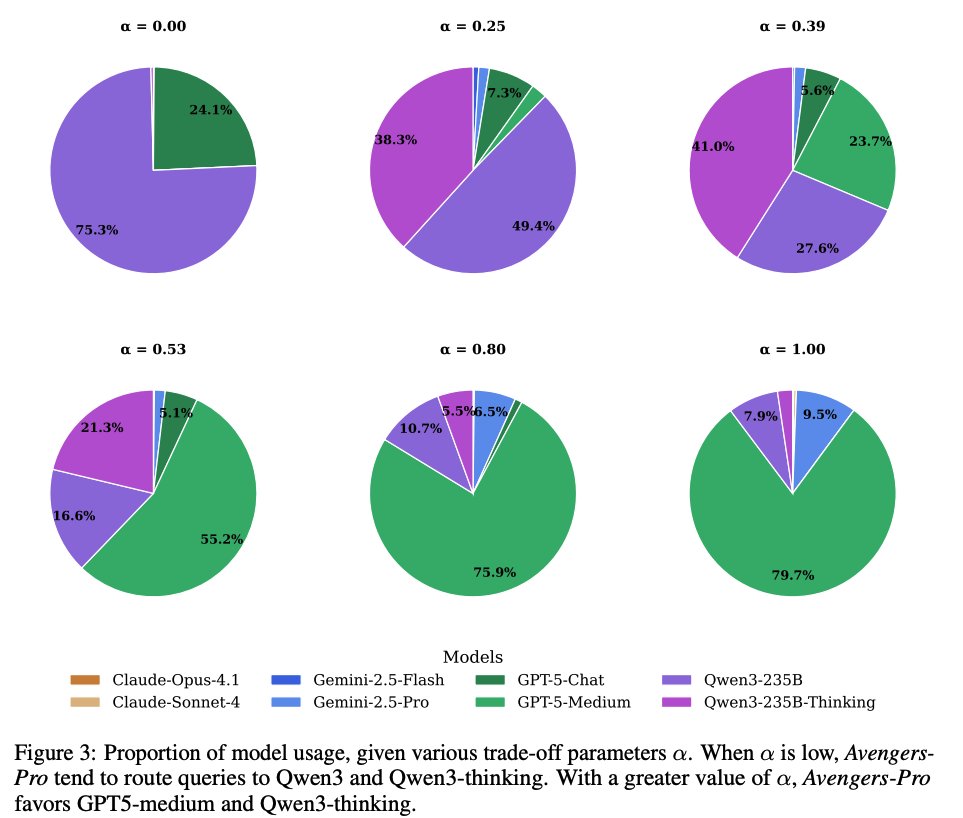
Routing behavior Routing decisions shift as the trade-off parameter α increases. At low α, Avengers-Pro heavily routes to cheaper Qwen3 and Qwen3-thinking models, but as α rises, usage shifts toward GPT-5-medium and, eventually, higher-priced models like Gemini-2.5-pro and Claude-opus-4.1, which excel at complex reasoning. Paper: https://t.co/EQeo6wMGZm

Obsidian has really impressed me, and I like that I can customize it, build my own plugins, and more. Been using it directly with Claude Code as well. I will share the extended breakdown for my academy subs next week: https://t.co/yHVttRKGM7 https://t.co/3OzdOX49dv


How to bring your bookmarks to life with ambient agents. I just built a little Obsidian plugin to take links and summarize them in the background using Claude Code SDK. I've been exploring how to best bring agents to the tools I use every day. https://t.co/VOB4Mznanl
Its a wrap - the first in-person event for #MLRC2025 successfully concluded yesterday - we witnessed some of the best talks I have ever heard on reproducibility issues in AI, ranging from issues regarding leakage and irreproducibility in ML-based science (@random_walker), determinism issues and data access restrictions (@soumithchintala), evaluations and how to make them robust/reproducible (@BlancheMinerva), & real world challenges of deploying LLM agents in production (@jefrankle). The panel discussion among the speakers and @adinamwilliams led by @sayashk painted a picture of the shortcomings in reproducibility and the road ahead. We heard from best +outstanding paper awardees, and the poster session had a lot of footfall! Outstanding support by @PrincetonAInews for hosting the event, and thanks @AIatMeta and @OpenAI for sponsoring it! I hope our efforts further encourage reproducibility research, which in turn strengthen our understanding of ML science! Stay tuned for the release of talk recordings, and looking forward to the next iteration!
Awesome #MLRC2025 talks kicking us off this morning! I'm learning lots @repro_challenge about science with ML and reproducibility for real world applications (@random_walker), and software/firmware and data concerns for reproducibility (@soumithchintala) Slides coming soon! https


The moral panic over data center water usage is out of control. This is just not that much water: https://t.co/SnyQkBHa1R
The US uses around 322 billion gallons of water each day. This week on Construction Physics, I look at where it all goes. https://t.co/aORBJPSa0B

The moral panic over data center water usage is out of control. This is just not that much water: https://t.co/SnyQkBHa1R

"we have the agency to shape [AI] as normal technology. We have the agency to ensure that the path through which it diffuses through society is not governed by the logic of the technology itself but rather by humans and institutions" @random_walker https://t.co/3W9GEd5hZM

Introducing 𝘃𝗶𝗯𝗲-𝗹𝗹𝗮𝗺𝗮 to streamline your LlamaIndex development with context-aware coding agents. A command-line tool that that automatically configures your favorite coding agents with up-to-date context and best practices about LlamaIndex framework, LlamaCloud and workflows Running 𝘶𝘷𝘹 𝘷𝘪𝘣𝘦-𝘭𝘭𝘢𝘮𝘢@𝘭𝘢𝘵𝘦𝘴𝘵 𝘴𝘵𝘢𝘳𝘵𝘦𝘳 will automatically generates rule files for 16 of your favorite coding agents (including @cursor_ai, @claudeai Code and @github Copilot) to get started with building your awesome LlamaIndex-powered app right away, with all the relevant docs and info readily available to them. 🔍 Check out the repo: https://t.co/lsPL280fKk 🦙 ☁️ Get started with LlamaCloud: https://t.co/zqUqveKp6b
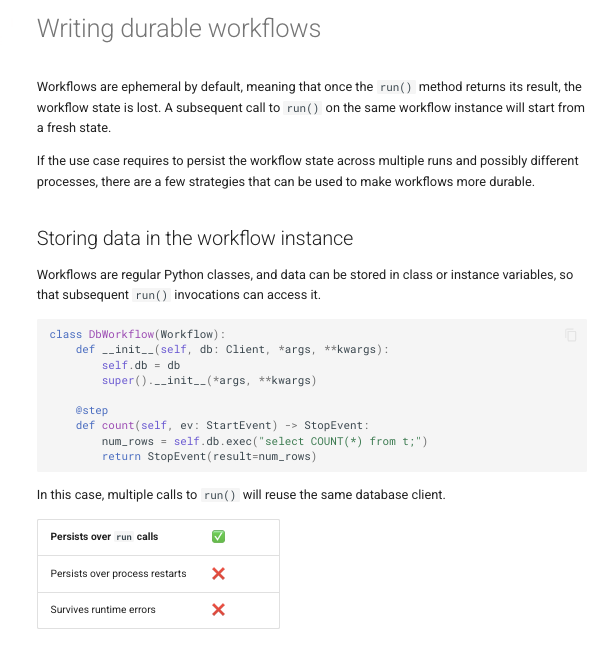
Build durable workflows that persist across multiple runs 👇 By default, LlamaIndex workflows are ephemeral - but production applications need persistence. Our new guide shows you three strategies: 🔄 Store data in workflow instances for simple persistence across multiple runs 💾 Use the Context object's state store for async-safe, serializable workflow state that survives process restarts 🚨 Implement external checkpointing to resume exactly where you left off ⚡ Bonus: inject dependencies directly into workflow steps to reduce boilerplate code Perfect for long-running document processing, multi-step AI agents, or any workflow that can't afford to start over from scratch. Learn how to write durable workflows: https://t.co/JnH9alMCoy
For about ~4 years or so, we've had a dream to launch a GPU marketplace. This week it finally came true after a ton of hard work from the Lightning team. The vision is simple, enable you to use the best ML platform on any cloud of your choice. In the worst case, simply come get a GPU VM, ssh, and you're done. In the best case, you grow into the full enterprise-grade features we offer to manage teams, budgets, RBAC, observability, monitoring, etc... Please try it out and let me know your feedback!
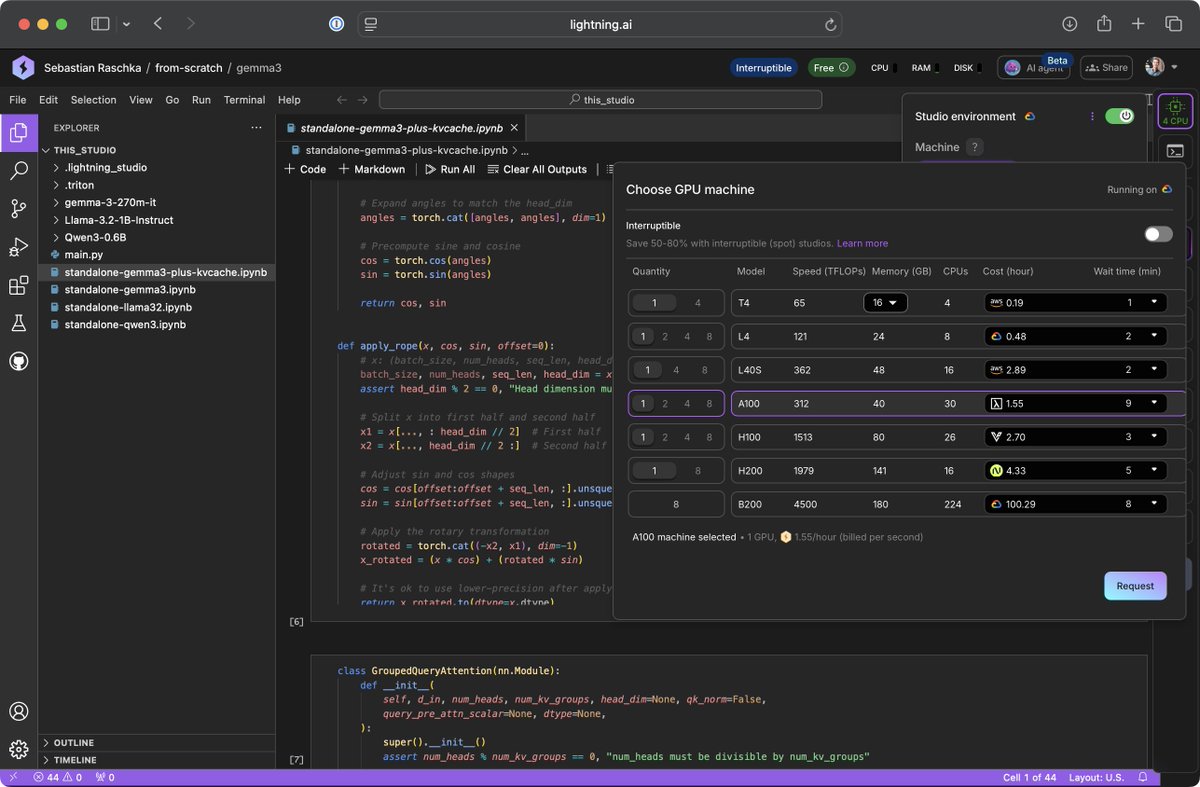
I love this upgrade. Lightning AI is my go-to cloud compute platform due to its user-friendliness (great UI, persistent environment, multi-GPU and multi-node support, etc), and now the prices are also really great. An A100 for $1.55/hour through Lambda Labs or an H100 for $2.70 through Voltage Point. What's not to like! Disclaimer: This is NOT a sponsored post (I have never done those!). And I was NOT asked or contacted to say this; it's genuinely my preferred platform. I did work at Lightning AI at one time though.
For about ~4 years or so, we've had a dream to launch a GPU marketplace. This week it finally came true after a ton of hard work from the Lightning team. The vision is simple, enable you to use the best ML platform on any cloud of your choice. In the worst case, simply come get
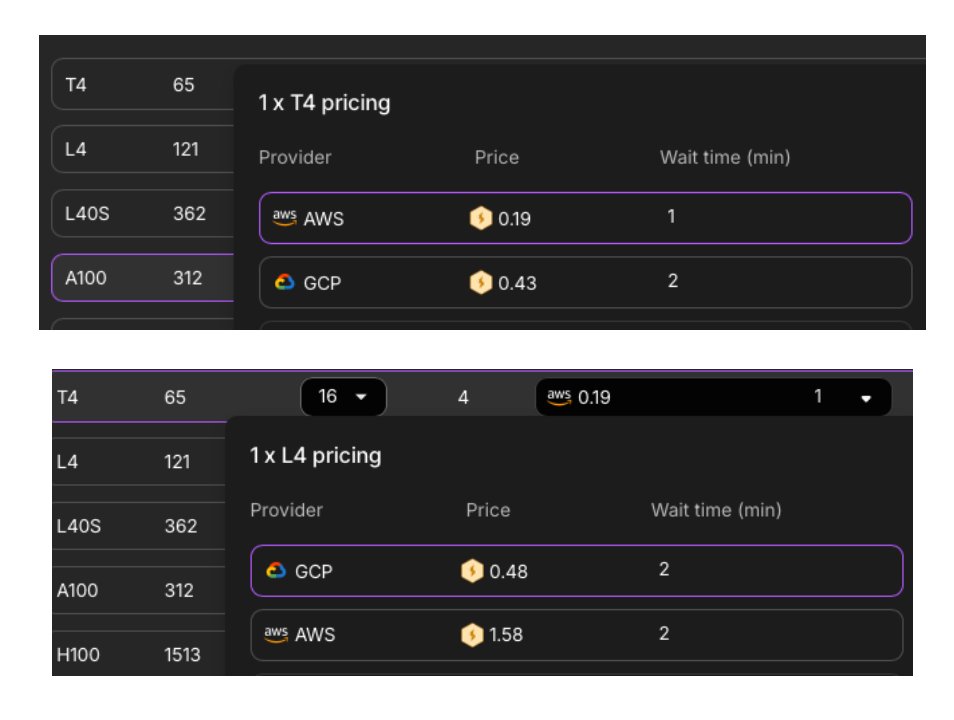
@jasonth0 I guess different providers have different margins for different cards. For instance, GCP is cheaper than AWS for some cards, but more expensive for others etc. The trick here is you are not locked into using one of the providers but the one that offers your preferred GPU the cheapest at a given time.
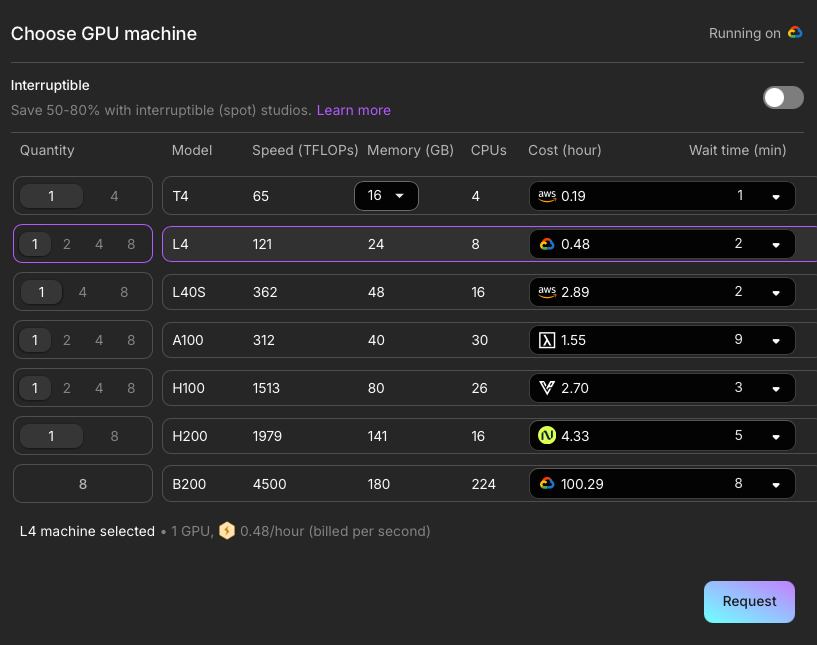
@jasonth0 Like GCP has cheaper L4's but AWS has cheaper T4's https://t.co/NLEHDUhRJG
@rishabh063 Based on the main website (https://t.co/U1SRtfap6h) it seems like this is still supported; probably have to contact them though https://t.co/PCYZUo7UFw


Go beyond correct code with our latest GPU puzzle! Puzzle #30 introduces systematic performance analysis to spot bottlenecks, understand memory system behavior, and optimize your code: https://t.co/b3ECUVgA0h

if you want to see the full talk: https://t.co/vc6EX3cFuo

https://t.co/21WhHBXLtf https://t.co/dqyfdvWWgi
⎿ Read 20 lines (ctrl+r to expand) ⏺ Perfect! I now have a clear understanding of the codebase. https://t.co/ZnqdPUro6d

a joyful brain glitch convinces me I’m watching a child ride a chicken skate across the rink https://t.co/2hKQOUolp4
a joyful brain glitch convinces me I’m watching a child ride a chicken skate across the rink https://t.co/2hKQOUolp4
I'm in SF and want to meet @swyx and users and get feedback on how the team can improve our product if you want to meet me or other vibe coding creators I'd love to meet you impromptu meetup (+ dinner) tomorrow, very informal, link below https://t.co/MgTq4MqJ8m
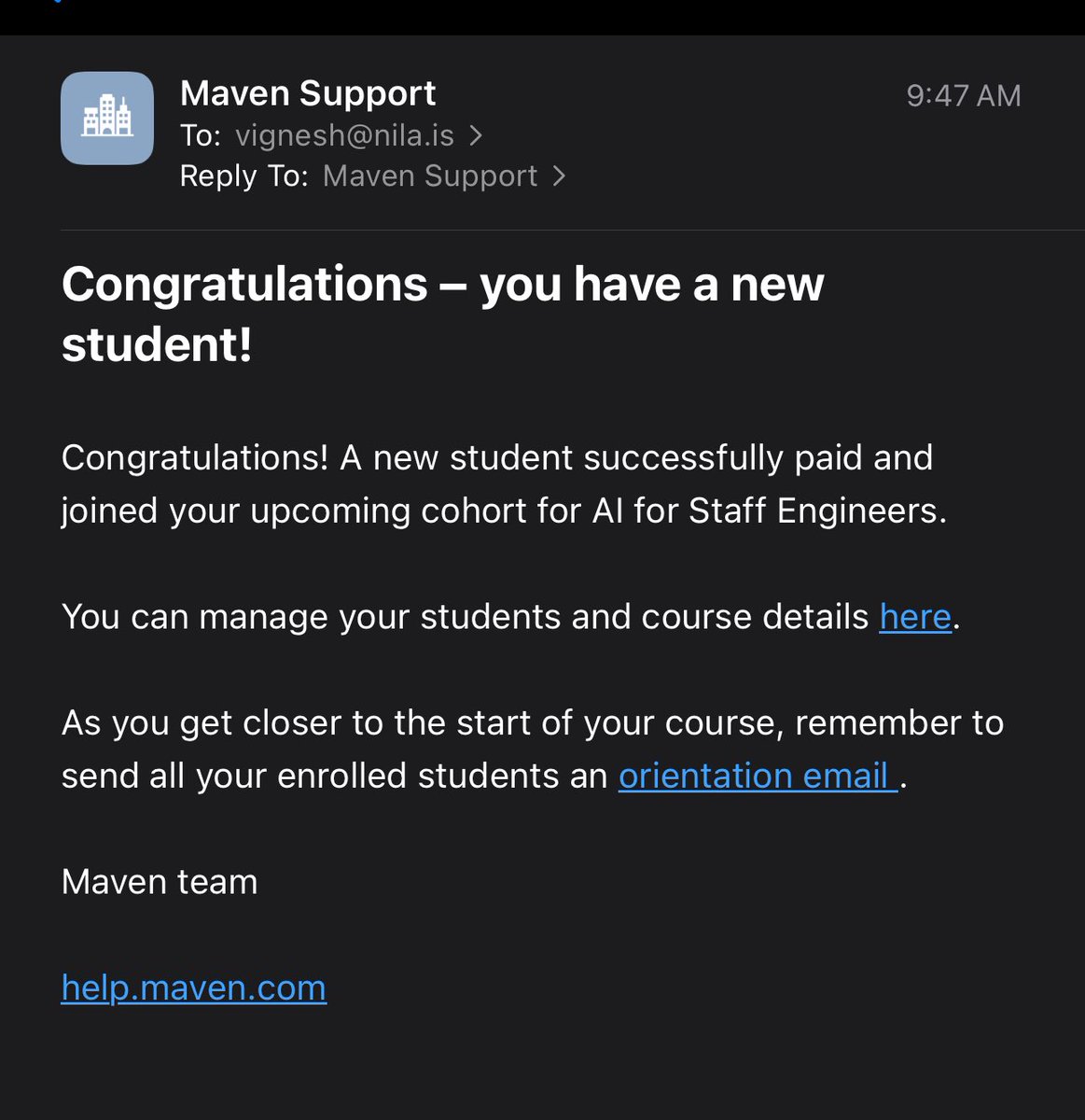
first signup, feels cool. excited for the next couple months https://t.co/E5iLN5UX6n
first signup, feels cool. excited for the next couple months https://t.co/E5iLN5UX6n
Life when u stop chud-maxxing https://t.co/CxijrChA80

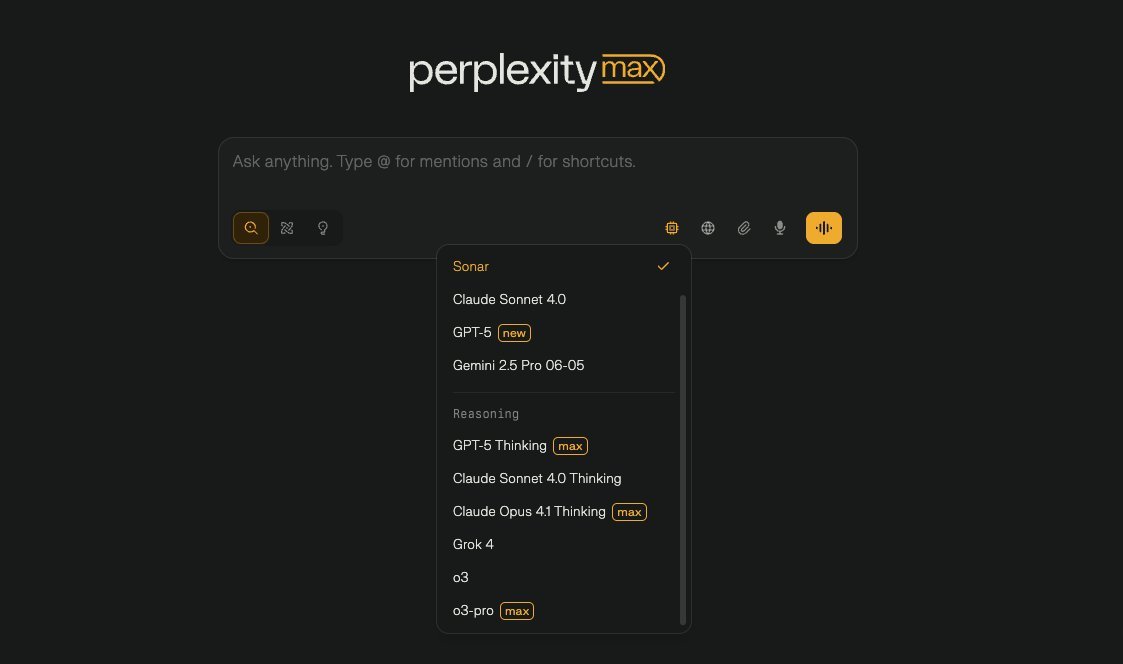
Perplexity Max Subscribers can now use GPT-5-Thinking model for reasoning mode queries https://t.co/5lQaC8tNNy
Update the Perplexity iOS app. You will be pleasantly surprised. Team has cooked. https://t.co/EawowNSyKg
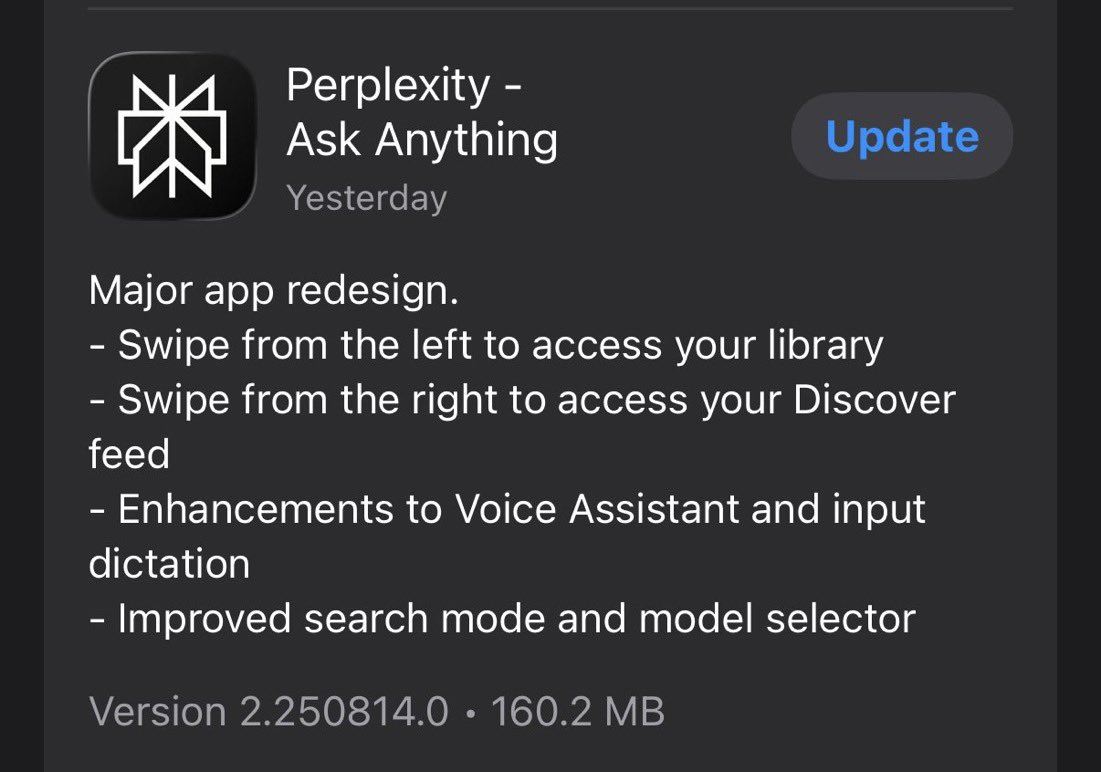
Earlier today, we launched a new version of our Perplexity iOS app, reimagined from the ground up and built with a lot of love. Swipe from the left access your library, swipe right to access Discover. Lots of intuitive gestures and motion. Can't wait for you to try it. https://t.co/aa72KgStzT
I have been dictating most of my queries instead of typing when on the iOS app. The new redesigned updated Perplexity iOS app has a chef’s kiss on voice dictation UX. https://t.co/BcDExjoSxb
Apple-sque design of the library of past threads on the redesigned Perplexity iOS app. https://t.co/LiZhpw1PLc