@omarsar0
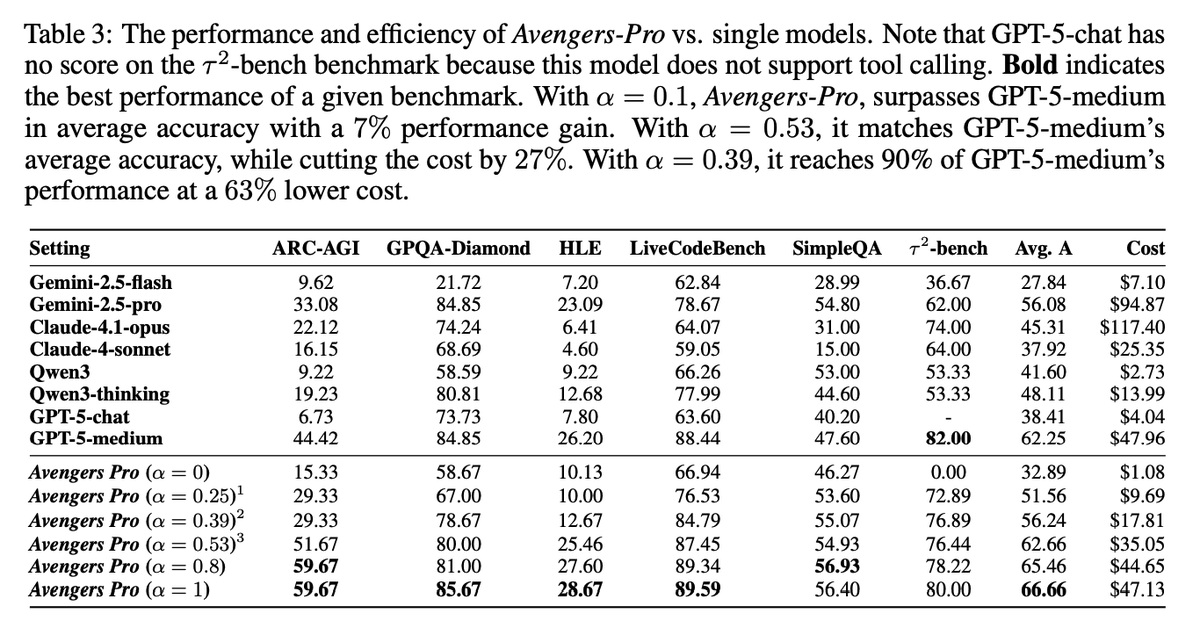
Setup Ensemble of 8 models (GPT‑5‑chat/medium, Claude‑4.1‑opus/Sonnet‑4, Gemini‑2.5‑pro/flash, Qwen3 235B and thinking). Evaluated on GPQA‑Diamond, HLE, ARC‑AGI, SimpleQA, LiveCodeBench, and τ²‑bench. Pricing via OpenRouter informs per‑cluster cost scoring. Avengers-Pro consistently outperforms or matches the strongest single models while lowering costs. With α=1 it achieves the highest accuracy (66.66%, +7% over GPT-5-medium), and with α=0.53 it matches GPT-5-medium’s accuracy at 27% less cost; notably, with α=0.39 it sustains 90% of GPT-5-medium’s performance at 63% lower cost.