Your curated collection of saved posts and media
https://t.co/i1lJ1Bc2da https://t.co/Tx9DhCpjnS
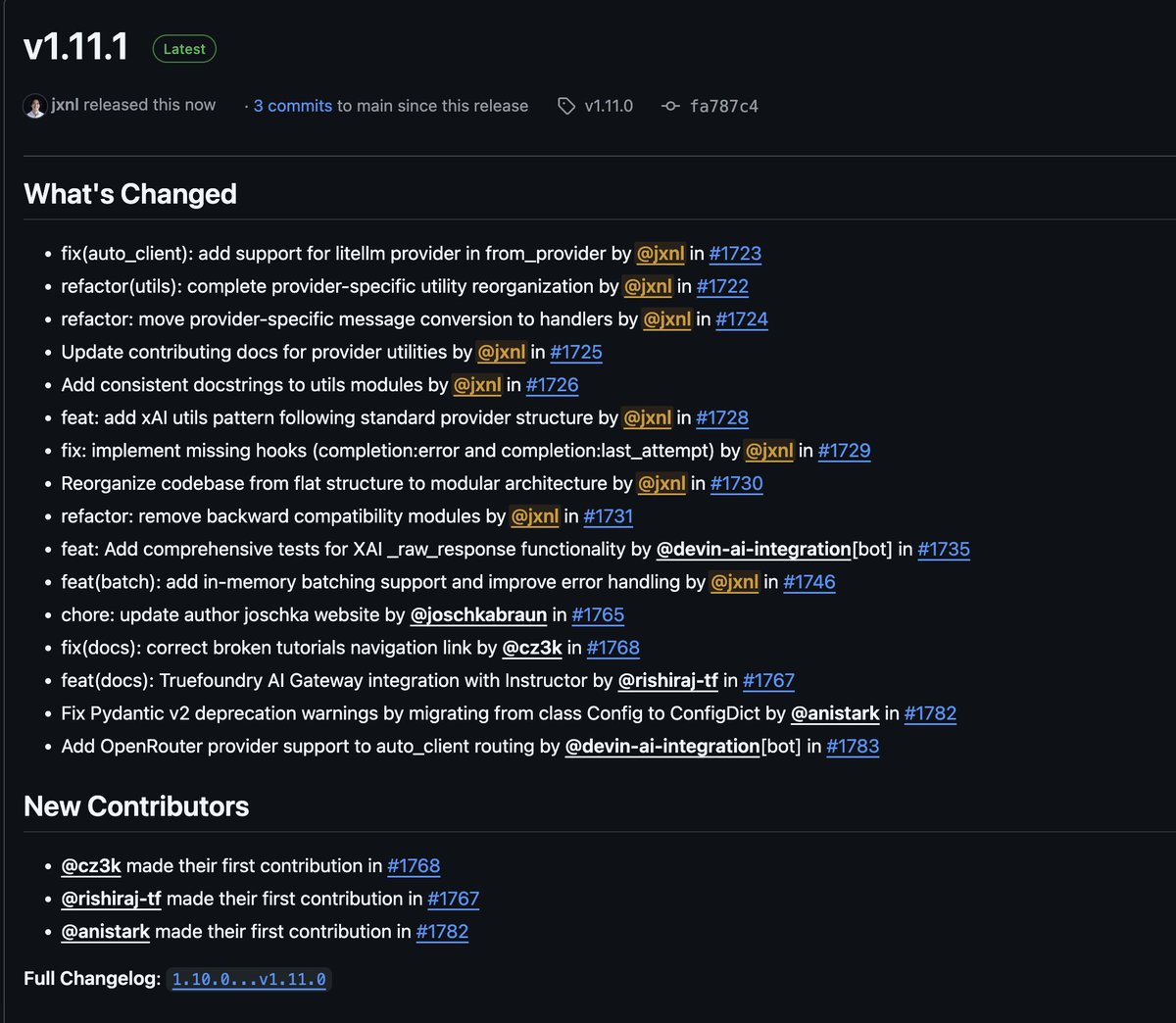
Ruining art with Gemini 2.5 Flash. (These are all the prompts, in their entirety) "make this painting less gloomy" "it is still pretty disturbing, make it less gloomy emotionally" "even less gloomy" https://t.co/IYrItsAGFw


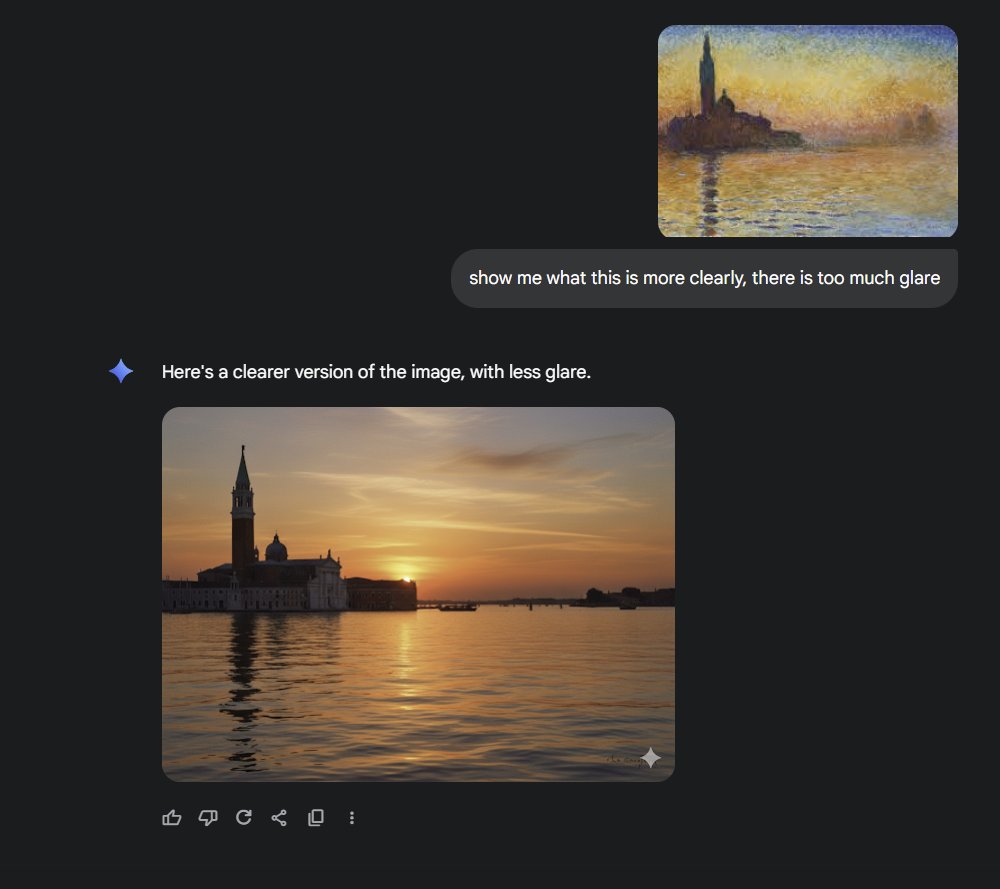
Ruining even more art with Gemini 2.5 Flash. https://t.co/ZCdLebKlne
We taught our AI to watch videos. Which sounds either completely obvious or completely impossible, depending on how you think about it. Our engineering team spent months figuring out how to get AI beyond just transcribing what people say to actually understanding what's happening visually in footage. The result? You can now ask our video agent to find "the clip where someone writes physics equations on a chalkboard," and it'll actually find it. In seconds. A few things this unlocks: - No more naming files "video_5300.mp4" and hoping for the best - Auto B-roll insertion based on what you actually have, not just stock footage - Search across your entire media library for "that time someone clapped" But here's what's really interesting... We went from prototype to production in about 6 weeks. Not because we're geniuses, but because the foundational AI models are getting so good that the hard part isn't the tech anymore—it's figuring out what people actually want to do with it. Turns out, that's a lot weirder than we expected. Recent user requests include "insert a GIF every time someone sneezes" and "chop up this kid's baseball game into clips." The internet remains beautifully strange. What we're building toward isn't just faster video editing—it's the shift from needing to know software to needing to know what story you want to tell. Our engineering team explains the whole journey, including the part where they definitely did not get their cost estimates wrong. (They definitely did.)

Prior to GPT-5, Sonnet & Opus were the undisputed kings of AI coding. It turns out the GPT-5 is significantly better than Sonnet in one key way: the ability to recover from mistakes. Today we're excited to release our latest research at @Letta_AI on Recovery-Bench, a new benchmark for measuring how well model can recover from errors and corrupted states. Coding agents often get confused by past mistakes, and mistakes that accumulate over time can quickly poison the context window. In practice, it can often be better to "nuke" your agent's context window and start fresh once your agent has accumulated enough mistakes in its message history. The inability of current models to course-correct from prior mistakes is a major barrier towards continual learning. Recovery-Bench builds on ideas from Terminal-Bench to create challenging environments where an agent needs to recover from a prior failed trajectory. A surprising finding is that the best performing models overall are clearly not the best performing "recovery" models. Claude Sonnet 4 leads the pack in overall coding ability (on Terminal-Bench), but GPT-5 is a clear #1 on Recovery-Bench. Recovering from failed states is a challenging unsolved task on the road towards self-improving perpetual agents. We're excited to contribute our research and benchmarking code to the open source community to push the frontier of continual learning & open AI.

A new idea: dinners in San Francisco of my fans. https://t.co/5aKxh8H244 Meet five other people who know me, then meet after dinner with me. First one, next Wednesday!

BREAKING: Nvidia earnings just out: > EPS: $1.05 , est: $1.01 > Revenue: $46.7 billion, est: $46.1 billion > EPS +30% YoY > Revenue +56% YoY > New logo design https://t.co/kidxgtuCBj

🚀Go Bananas in Genspark🍌 Nano Banana(Gemini 2.5 Flash Image) is now in Genspark. Faster edits, sharper details, smarter control. Available in Genspark AI Designer, AI Image and Super Agent. 🔥Try it today → https://t.co/2bxGFjw3Zi
It's now posible to do end-2-end ML without leaving the @huggingface Hub, by combining TRL + HF jobs + Trackio!! 🐡We just released a full guide explaining the process. Go check it out! https://t.co/NgFo3fmYiD

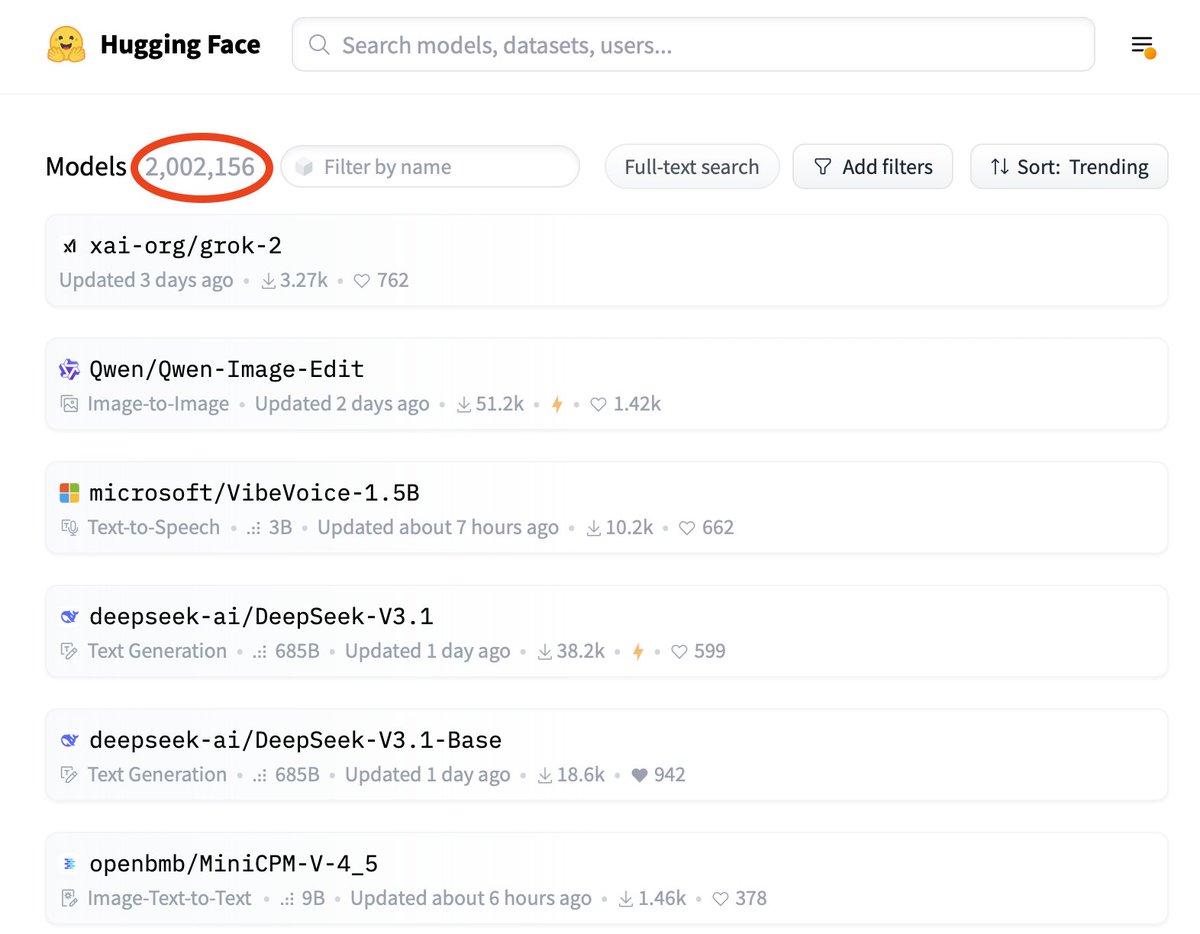
Wow! Hugging Face reached 2M models! 🎉 https://t.co/0sB4Ppbkss
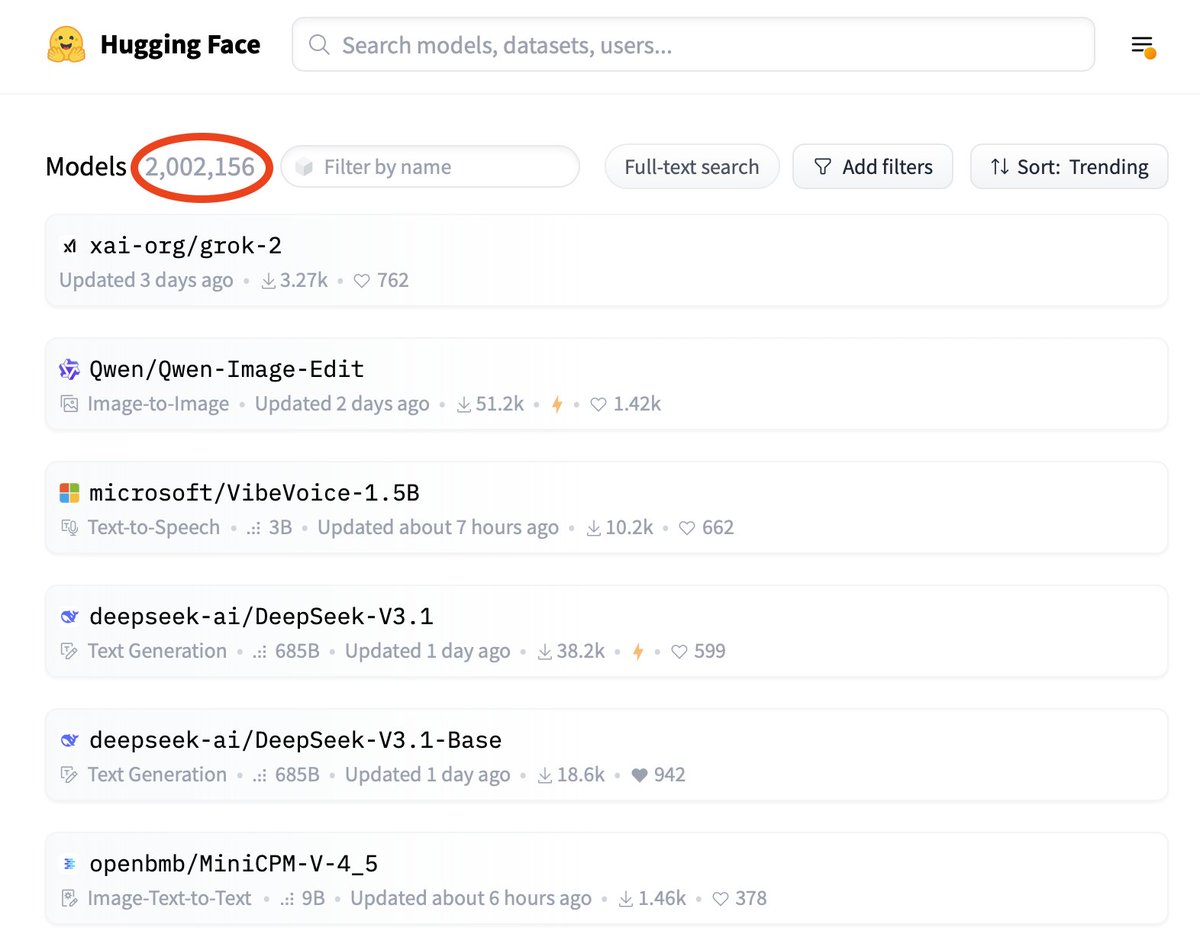
Wow! Hugging Face reached 2M models! 🎉 https://t.co/0sB4Ppbkss
TreePO Bridging the Gap of Policy Optimization and Efficacy and Inference Efficiency with Heuristic Tree-based Modeling https://t.co/OO3NmbnxHt

CMPhysBench A Benchmark for Evaluating Large Language Models in Condensed Matter Physics https://t.co/eZ3XsDhX6W

discuss with author: https://t.co/xLQLKXXZi2

VibeVoice Technical Report https://t.co/80MpsCQ6OZ

discuss with author: https://t.co/W2aeLSk8oi

VoxHammer Training-Free Precise and Coherent 3D Editing in Native 3D Space https://t.co/NkGeimhOdk
discuss with author: https://t.co/Q8cs5f3ZH5

Spacer Towards Engineered Scientific Inspiration https://t.co/nGjUsJwEX0

discuss with author: https://t.co/ohxFw7UWLV

OmniHuman-1.5 Instilling an Active Mind in Avatars via Cognitive Simulation https://t.co/OOOyNyc6BQ
discuss: https://t.co/z8JOFumvLz

Pixie Fast and Generalizable Supervised Learning of 3D Physics from Pixels https://t.co/7HUIgGyc3S
discuss with author: https://t.co/mQi4ZPsPgI

Nvidia presents Autoregressive Universal Video Segmentation Model https://t.co/gw9G22QDOD

discuss with author: https://t.co/HGdRNfQNB3

OpenAI just released HealthBench on Hugging Face. This new dataset is designed for rigorously evaluating large language models' capabilities in improving human health. A vital step for AI in medicine! https://t.co/FNX8ipxLno

Announcing Lindy Build: the new State Of The Art in vibe coding. Using a web browsing agent, it clicks around, finds issues, and fixes them, 100% autonomously. If you’ve tried vibe coding, the first 5 mins of going from prompt to prototype feel magical. What sucks is that you then have to spend hours going back and forth with this blind engineer to fix issues that are obvious to you. Lindy Build is magical end-to-end: describe any complex app, go grab lunch, and have something working and bug-free when you come back.
"Everyone talks about hallucinations, but in enterprise, the real failure is stale or missing data. Most of the time, the right information doesn’t even exist—or it’s outdated or hidden in 100 systems. That’s where things actually break down." – @jainarvind, CEO & Founder, @Glean https://t.co/wDaByELR73
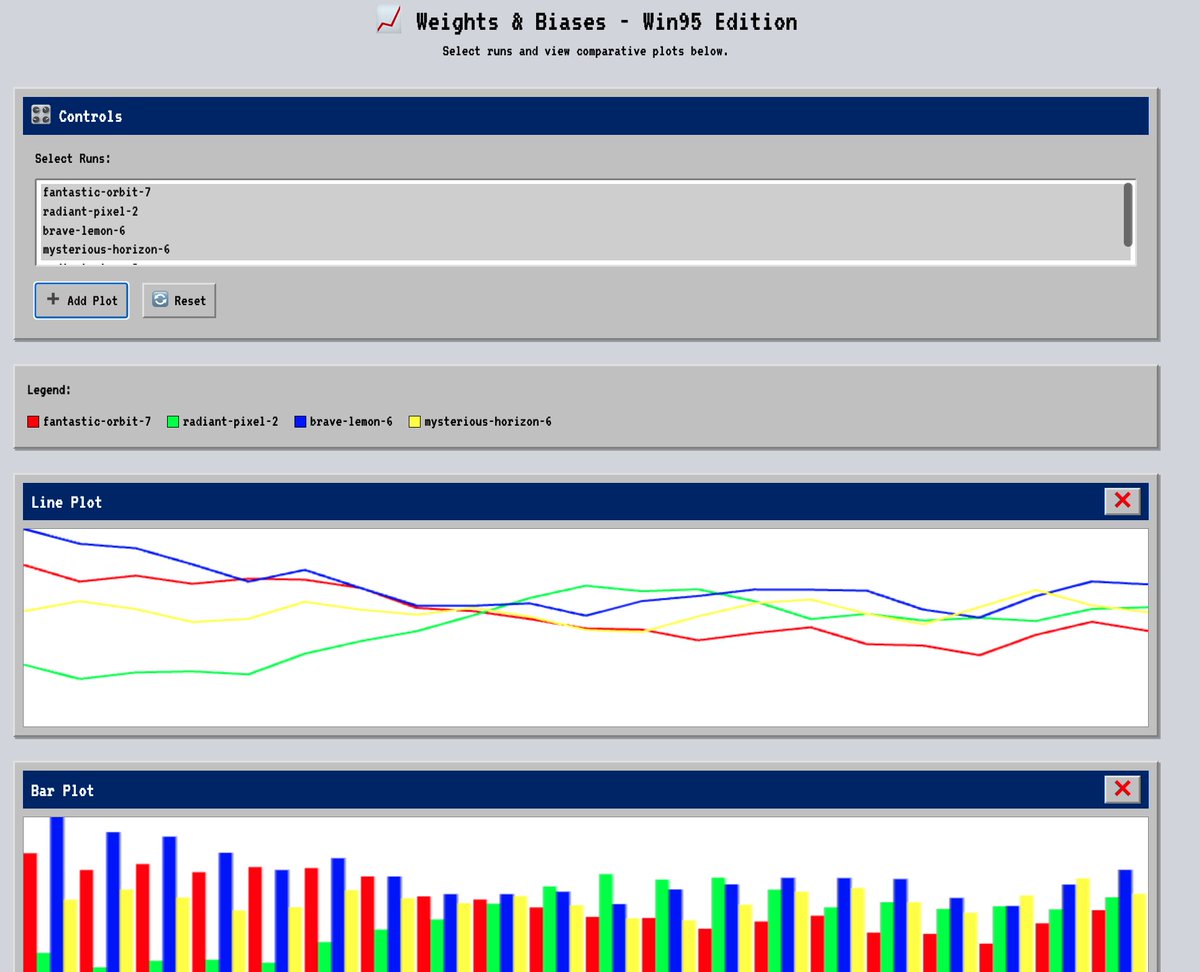
FYI: You can log interactive HTML directly to @weave_wb. We used Qwen3-coder on our W&B Inference platform to render a full "Win95 edition”UI that sits natively inside a trace. https://t.co/UTarNYBEci
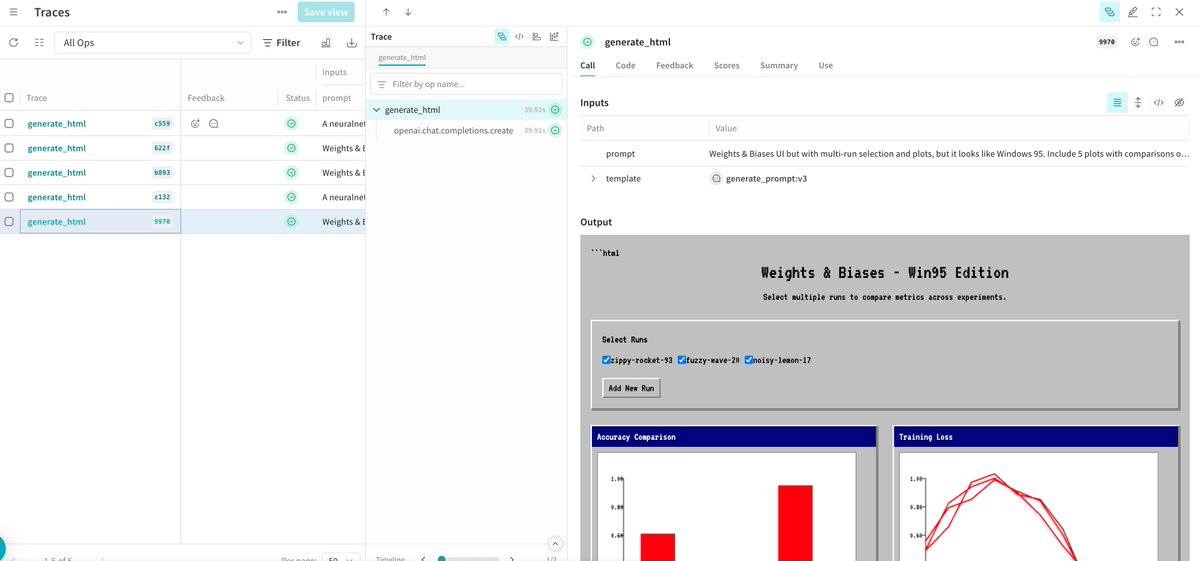
Vibe train an AI model is something people want? Built monostate's first consumer product in the @dedaluslabs YC hackathon, 24hours to ship something and now have to figure out if this is something people would like to use? Why this is useful? A lot of founders want to make AI niche products, make profit and build value beyond wrappers. And also, my intuition is that training small LLMs without code will enable researchers of all fields to tap into scientific discovery. Thanks Hackathon organizers, judges and sponsors for the credits! @itsCathyDi @WindsorNguyen @xdenuzzo @snowmaker @rauchg @dan_goosewin @realchillben @ycombinator @vercel @OpenAIDevs Also Thanks @sammakesthings @weights_biases for support and credits for the new wandb inference servers!
Building AI that answers with confidence requires two things: fresh context and transparent execution. Static agents miss both. We paired @tavilyai (real-time web) with W&B Weave (tracing, evals, ops) to ship research agents that are accurate, current and trustworthy. https://t.co/y7nGqu8Coq
