Your curated collection of saved posts and media
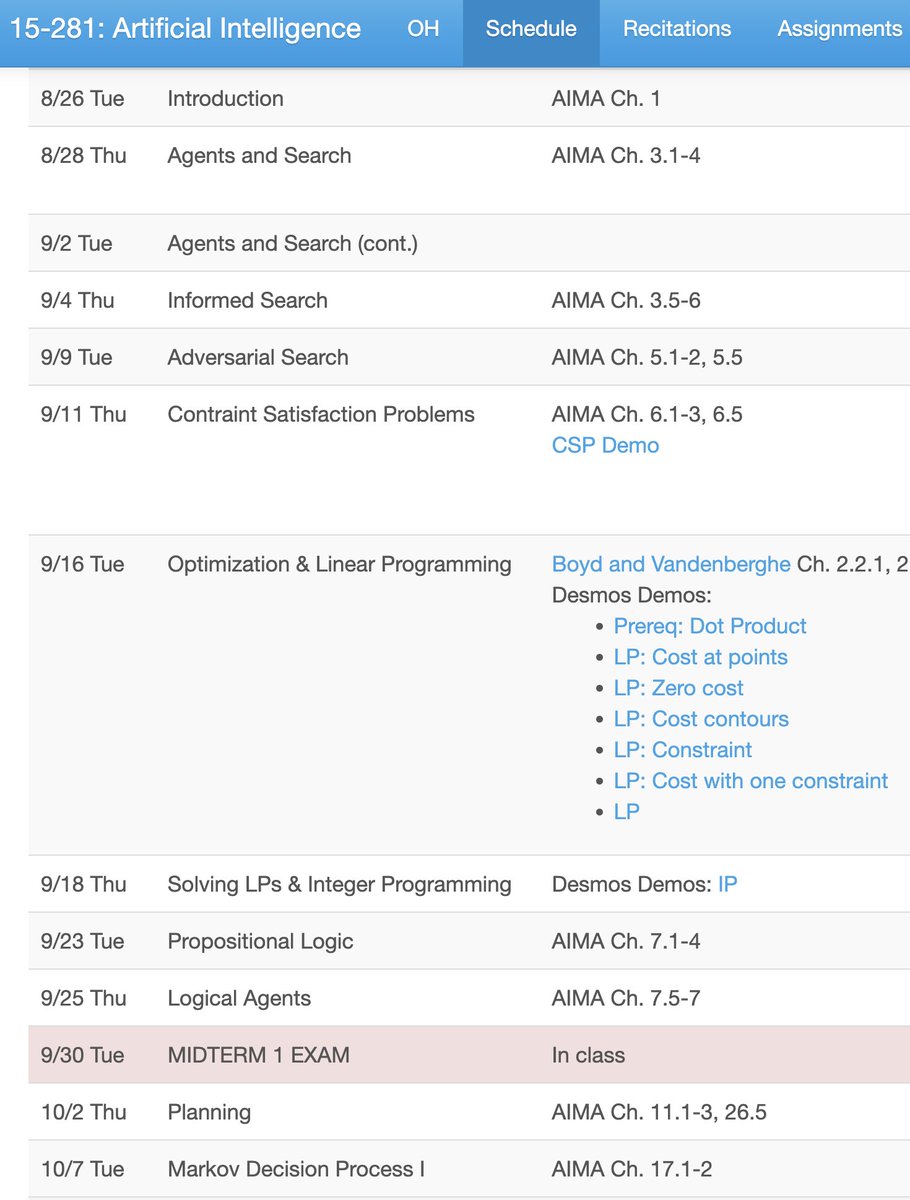
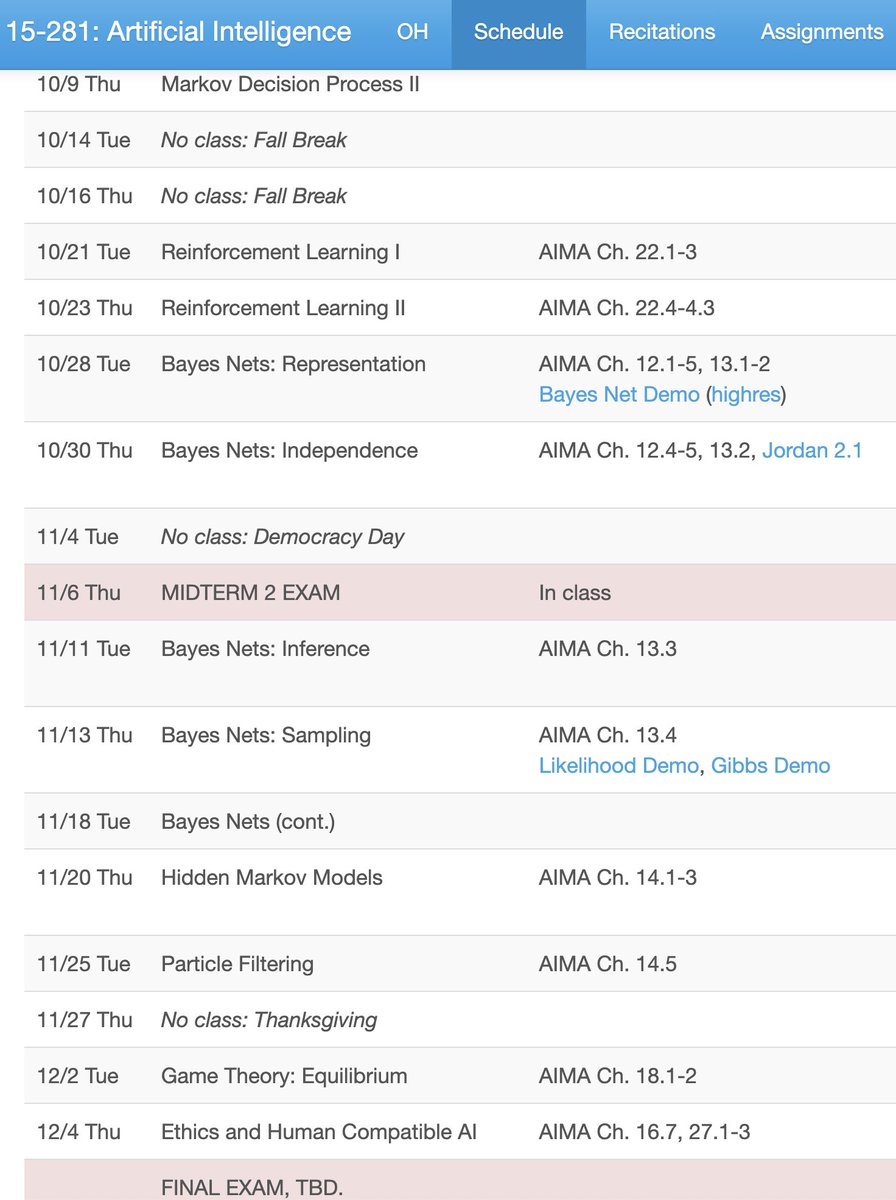
To all undergrads interested in learning about AI: be wary of taking “Intro to AI” as your first AI course. In many programs, the class you actually want first is “Intro to Machine Learning”. AI technology has exploded in the past 15 years thanks to deep neural networks. Yet at many schools, the “Intro to AI” curriculum has barely changed from what it was in 2010, and spends often only a few lectures on machine learning. Unfortunately, revamping “Intro to AI” is controversial at many universities, and inertia tends to dominate. Don’t decide which course to take based on the name alone. Instead, check the syllabus. Ideally, the course covers linear regression, gradient descent, backpropagation, and reinforcement learning. Each university is different and some “Intro to AI” courses will cover all these topics, but most don’t. If you plan to pursue AI as a career, I think it makes sense to take “Intro to AI” later for a broader perspective on intelligence. But if your goal is an intro to the technology powering modern chatbots, image recognition/generation tools, and coding assistants, the class you probably want first is “Intro to Machine Learning”.
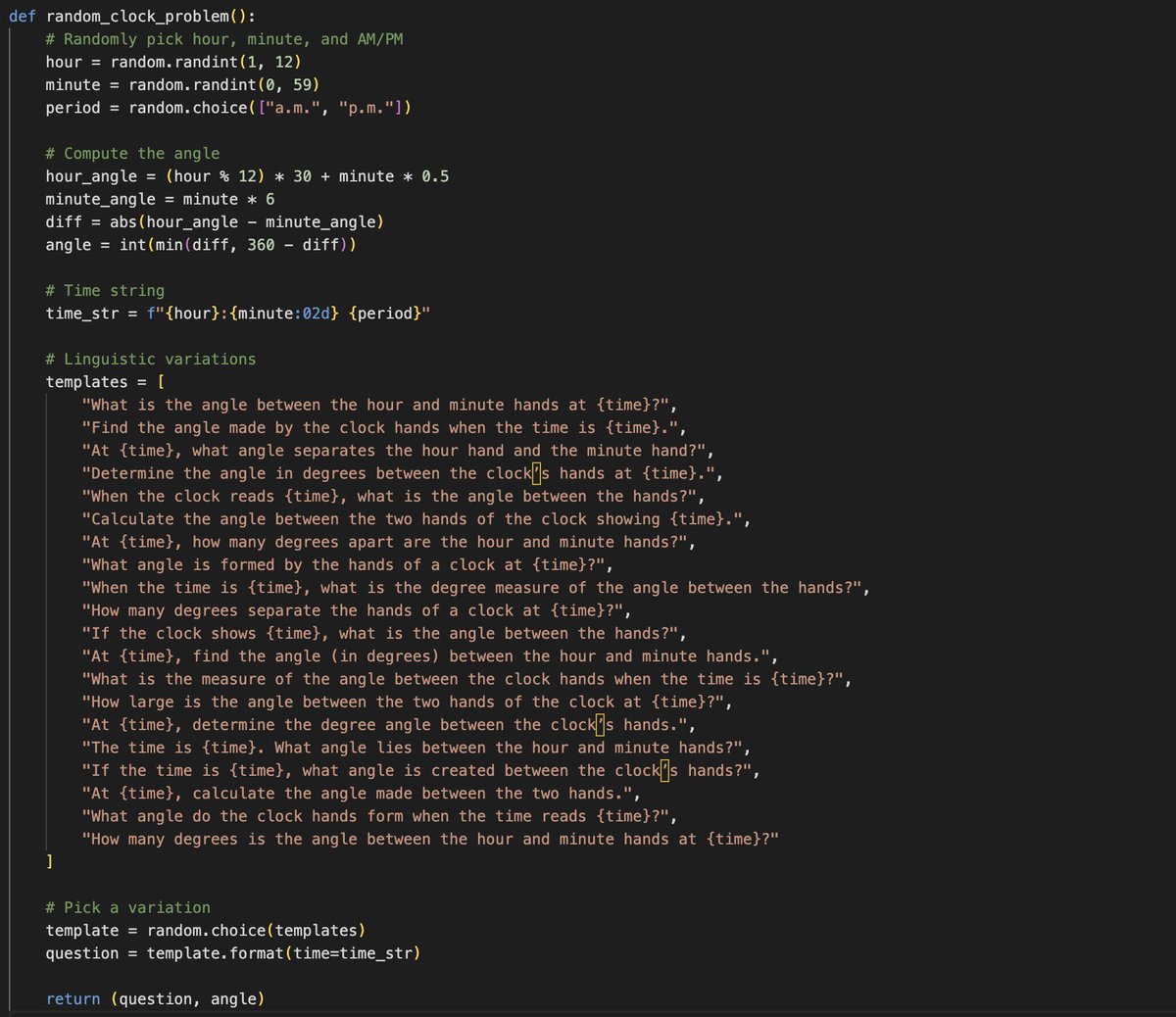
Transforming human knowledge, sensors and actuators from human-first and human-legible to LLM-first and LLM-legible is a beautiful space with so much potential and so much can be done... One example I'm obsessed with recently - for every textbook pdf/epub, there is a perfect "LLMification" of it intended not for human but for an LLM (though it is a non-trivial transformation that would need human in the loop involvement). - All of the exposition is extracted into a markdown document, including all latex, styling (bold/italic), tables, lists, etc. All of the figures are extracted as images. - All worked problems get extracted into SFT examples. Any referenced made to previous figures/tables/etc. are parsed and included. - All practice problems are extracted into environment examples for RL. The correct answers are located in the answer key and attached. Any additional information is added as "answer key" for a potential LLM judge. - Synthetic data expansion. For every specific problem, you can create an infinite problem generator, which emits problems of that type. For example, if a problem is "What is the angle between the hour and minute hands at 9am?" , you can imagine generalizing that to any arbitrary time and calculating answers using Python code, and possibly generating synthetic variations of the prompt text. - All of the data above could be nicely indexed and embedded into a RAG database for later reference, or maybe MCP servers that make it available. Then just as a (human) student could take a high school physics course, an LLM could take it in the exact same way. This would be a significantly richer source of legible, workable information for an LLM than just something like pdf-to-text (current prevailing practice), which simply asks the LLM to predict the textbook content top to bottom token by token (umm - lame). As just a quick and crappy example of synthetic variations of the above example, GPT-5 gave me this problem generator (see image), which can now generalize that problem template to many variations: - When the time is 11:07 a.m., what is the degree measure of the angle between the hands? (Answer: 68) - Determine the angle in degrees between the clock’s hands at 4:14 a.m.. (Answer: 43) - What angle do the clock hands form when the time reads 11:47 a.m.? (Answer: 71) - At 7:02 a.m., what angle separates the hour hand and the minute hand? (Answer: 161) - At 4:14 a.m., calculate the angle made between the two hands. (Answer: 43) - What angle is formed by the hands of a clock at 4:45 p.m.? (Answer: 127) - What is the angle between the hour and minute hands at 8:37 p.m.? (Answer: 36) (infinite practice problems can be created...)
We are closing registration on this event tomorrow! On Sept 4 we’re gathering founders & operators at Flow State: AI Workflows for Peak Productivity — and we have a few slots available for people to demo their unique AI workflows live. If you’ve built something that saves time, unlocks creativity, or changes how you work — this is your chance to showcase it in front of an amazing community. 📅 Sept 4 | 5–9pm 📍 Lighthaven, Berkeley 🎟️ Apply now: https://t.co/LfJwuWtkrZ @HamelHusain @ttunguz @clairevo @gregce10

One of the most pressing questions in our AI Evals course is: "Why can’t I just have an LLM write my LLM pipeline?" The nuanced answer is that you can use LLMs to assist, but not for the whole pipeline. Knowing where to put the LLM in the loop is the hard part. To unpack this, we invited Omar Khattab (@lateinteraction) —creator of DSPy, leading expert on prompt optimization, and now professor at MIT—for a "fireside chat" in the course. He shed light on how he approaches pipeline development in practice. What stood out to us is that Omar spends most of his time on specification—e.g., defining the task clearly, looking at the data, and doing careful error analysis—before letting LLMs automate anything. This up-front rigor is what makes downstream optimization actually work. We've put the recording on YouTube. If you're wondering how Omar thinks about these tradeoffs, this conversation is worth a listen! https://t.co/j3D83hRLKW

I enjoyed reading this LLM-powered data application paper from UCSF: "When the Domain Expert Has No Time and the LLM Developer Has No Clinical Expertise." It gets at the heart of many of my favorite things: accelerating productivity with data analysis, evals in cross-functional teams, pipeline optimization through structured decomposition, improving over long deployments. https://t.co/5N1AVub8cZ

If you want the best way to consistently make a few hundred a month with only about few hours of work and then not having to do anything for months. I would find a niche with a specific problem. And vibe code the solution. I personally use @rork_app. By far not only the best ui + functionality but the best customer support. I had an issue. And the FOUNDER answered said on it, fixed within 20 minutes.
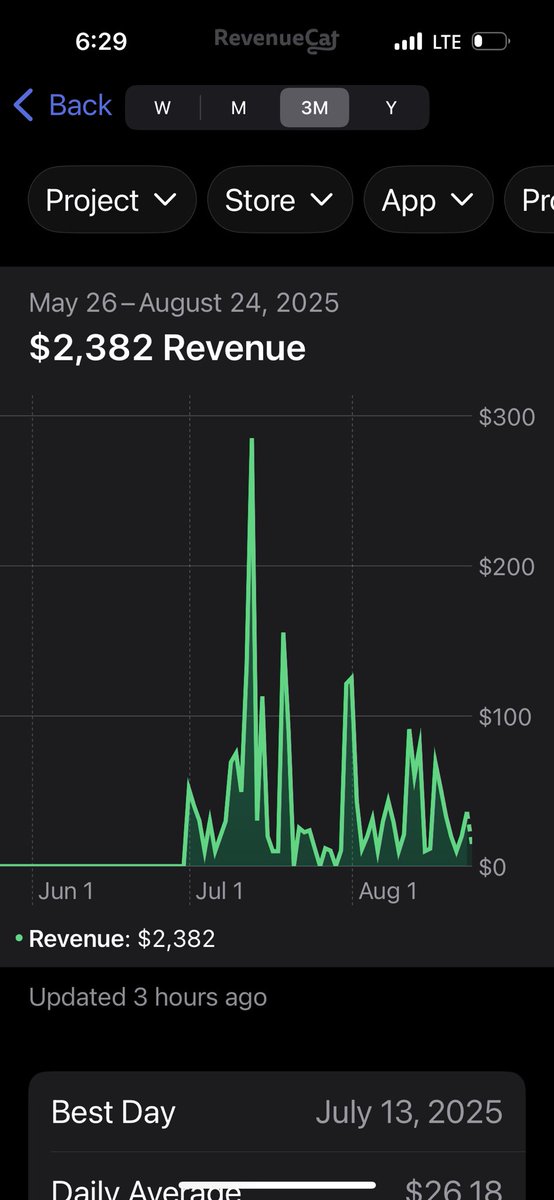
I should write about this. https://t.co/85DJq4Y1TY
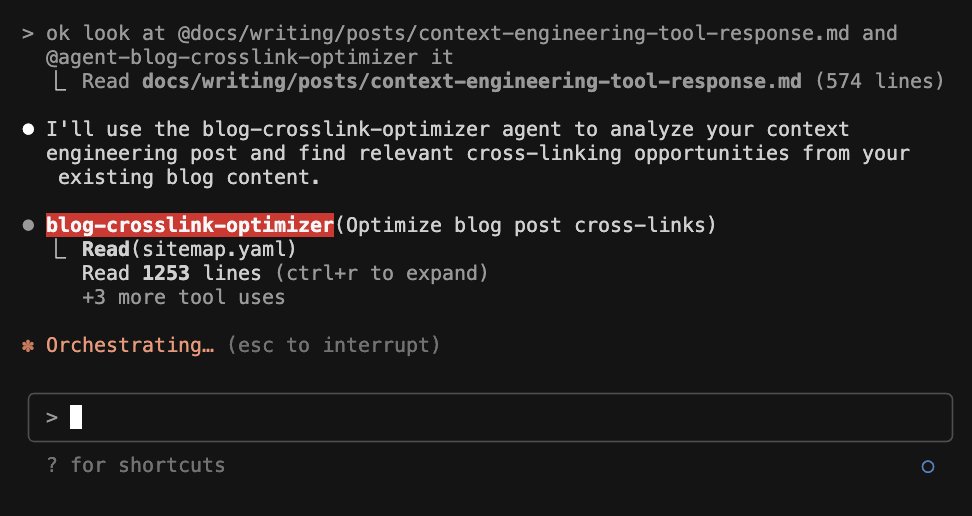
subagent are great when you need to spin a subprocess to burn a lot of agents that would otherwise pollute the main context, Here we created a sub-agent whose job is to simply read the entire site map of my website to propose cross-links. Even a burn, a lot of tokens reading other blog posts to make sure that these crossings are done correctly, but then will ultimately give me a plan to actually make the insertions. This way I can kick up this task without setting up another tab, but then continue my context of actually working on the blog post, which is what the purpose of the main thread is.
Learnt lots about retrieval from @jxnlco, the lesson on segmentation on top of error analysis is probably my fav. Jason is generous with practical advice, and the guest lectures were an unexpected bonus. https://t.co/zZyAQmN1HT

https://t.co/KvVDBWg2wq

vibe coding a NVIDIA-Nemotron-Nano-9B-v2 chat app in anycoder only took a couple a prompts and deployed with zero-gpu on Hugging Face NVIDIA-Nemotron-Nano-9B-v2 is a large language model (LLM) trained from scratch by NVIDIA, and designed as a unified model for both reasoning and non-reasoning tasks.
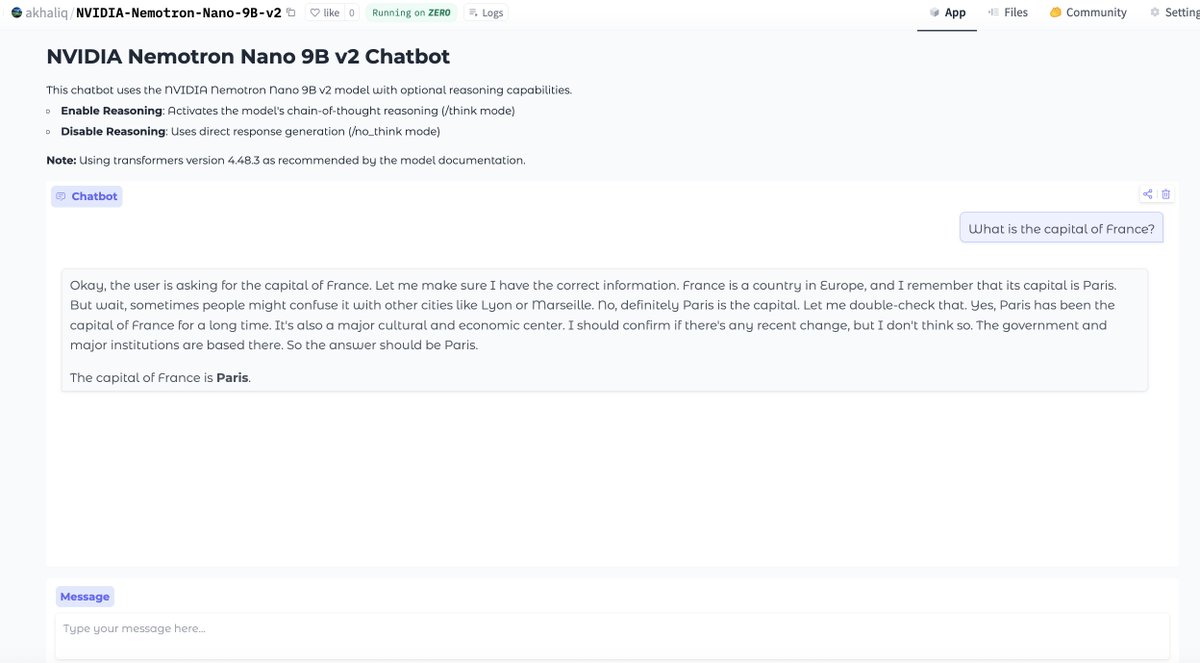
anycoder: https://t.co/esPDyHE1YC

NVIDIA-Nemotron-Nano-9B-v2: https://t.co/36akzVqSVo

app: https://t.co/esPDyHDu94

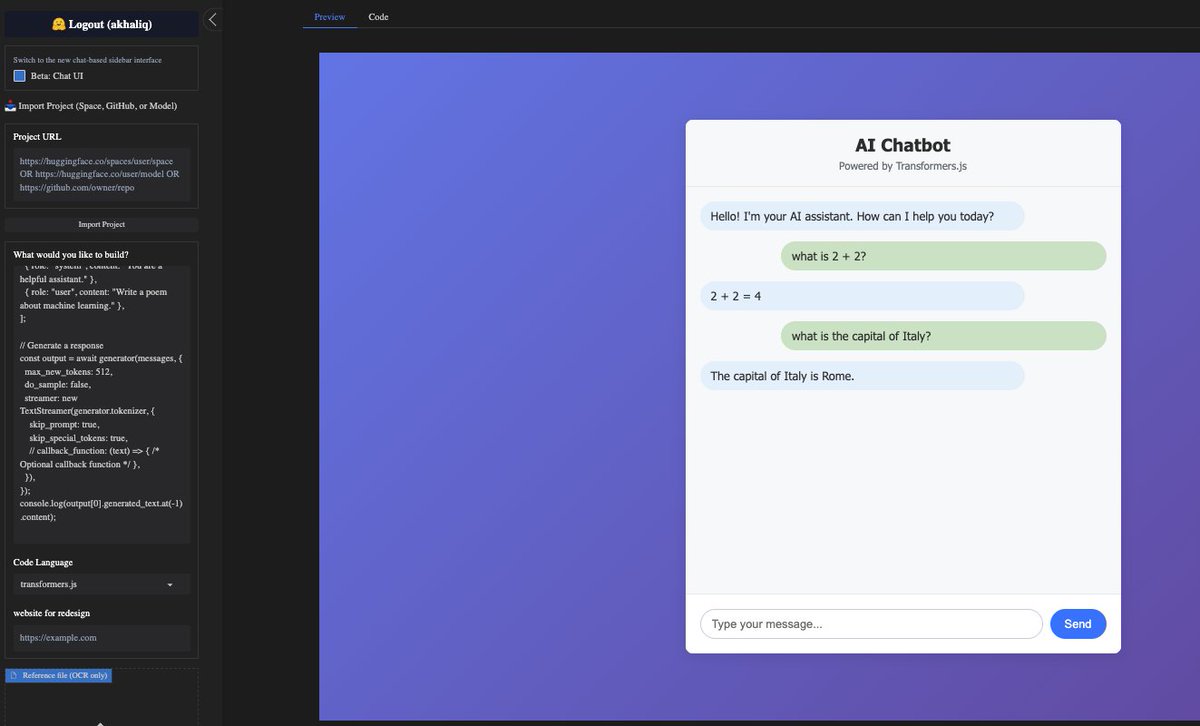
Grok Code Fast 1 is now available in anycoder a speedy and economical reasoning model that excels at agentic coding. one shotted a ai chatbot for gemma-3-270m-it-ONNX using transformers.js in anycoder runs completely in the browser https://t.co/cskpupu96K
CODA Coordinating the Cerebrum and Cerebellum for a Dual-Brain Computer Use Agent with Decoupled Reinforcement Learning https://t.co/mVN0yXRJs0

discuss with author: https://t.co/vlXIEpy8E5

Predicting the Order of Upcoming Tokens Improves Language Modeling https://t.co/2LXw5Vc5Af

discuss with author: https://t.co/90cv9E25kS

Introducing Higgsfield Mini Apps. 2000+ Nano Banana Apps LIVE now. A never-been-done-before drop. The most PRECISE control Nano Banana, works BEST only on Higgsfield. The best part - it's UNLIMITED & FREE for 1 Year. In collab with @RunwareAI. Retweet = full guide in DMs. https://t.co/WIa5lOHU5C
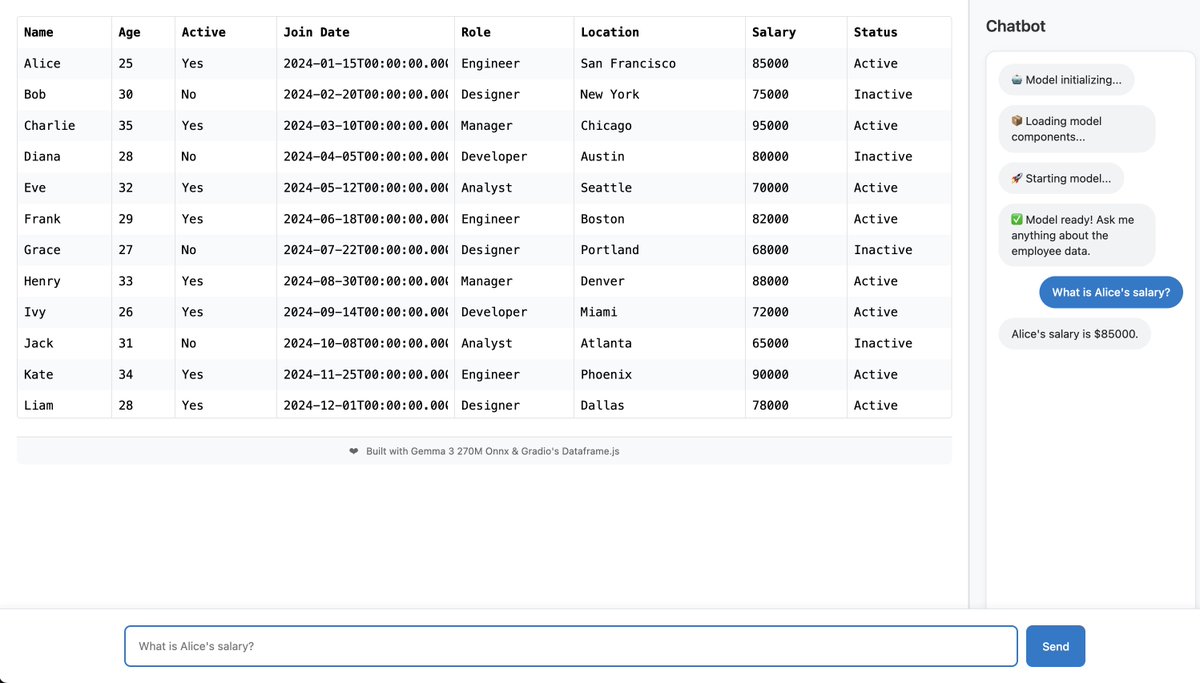
I made a "Chat with Excel" app using Gradio's new Dataframe Svelte component. Running entirely in the browser, thanks to Transformers.js and https://t.co/ECY4fEHwFE! https://t.co/6H6SIz8P58
Isn't this just brilliant? https://t.co/r0y1SjBwP1
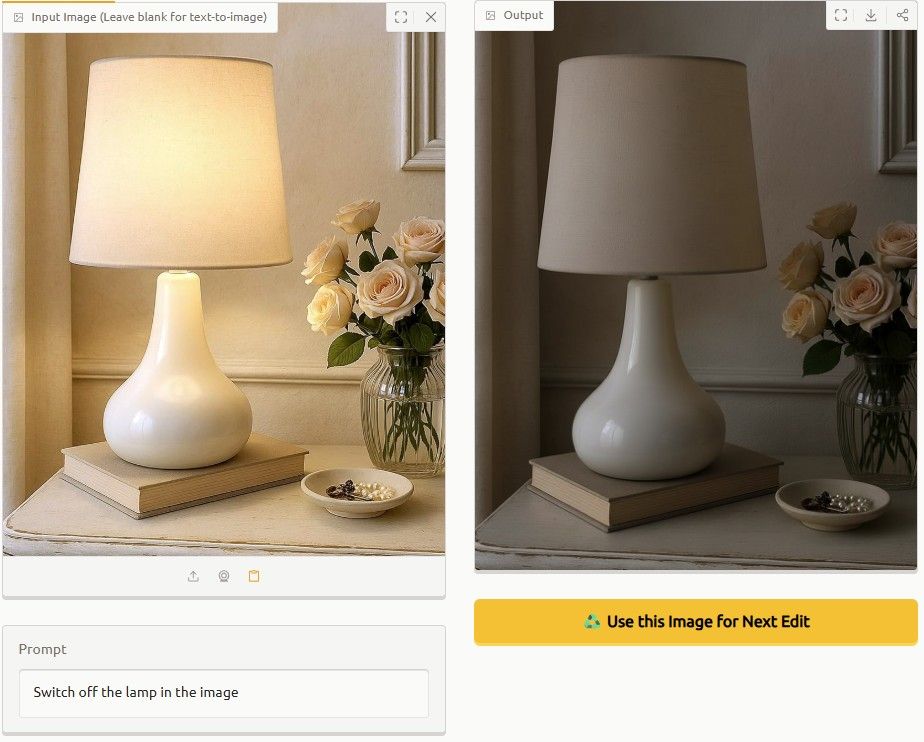
Isn't this just brilliant? https://t.co/r0y1SjBwP1
「湧いてくるGrokをタップで消すゲームアプリ作って」でGrok Coder fastにつくらせた結果がこちらになります。 https://t.co/zULqfhZW7h
「湧いてくるGrokをタップで消すゲームアプリ作って」でGrok Coder fastにつくらせた結果がこちらになります。 https://t.co/zULqfhZW7h
スマホでバイブコーディングしよう https://t.co/j38MFJkX9B

スマホでバイブコーディングしよう https://t.co/j38MFJkX9B

In this episode of the AI Leader Series, we sit down with Daniel, Principal Data Scientist at Cemex, to explore how one of the world’s leading building materials companies is transforming with LlamaIndex. From streamlining supply chains to enhancing customer engagement, Cemex is using AI and LlamaIndex to: ➡️ Automate manual, time-intensive processes. ➡️ Empower intelligent agents with actionable knowledge. ➡️ Improve retrieval accuracy and chatbot performance on technical documents. ➡️ Scale AI solutions across smart operations, health & safety, and commercial efforts. Check out the full video here: https://t.co/iZL4kLthDx

vector search at scale with @turbopuffer https://t.co/HjUCrJ8uOT

@turbopuffer heres a link to the talk! https://t.co/WreuL93G4u https://t.co/TzkKxPaayP


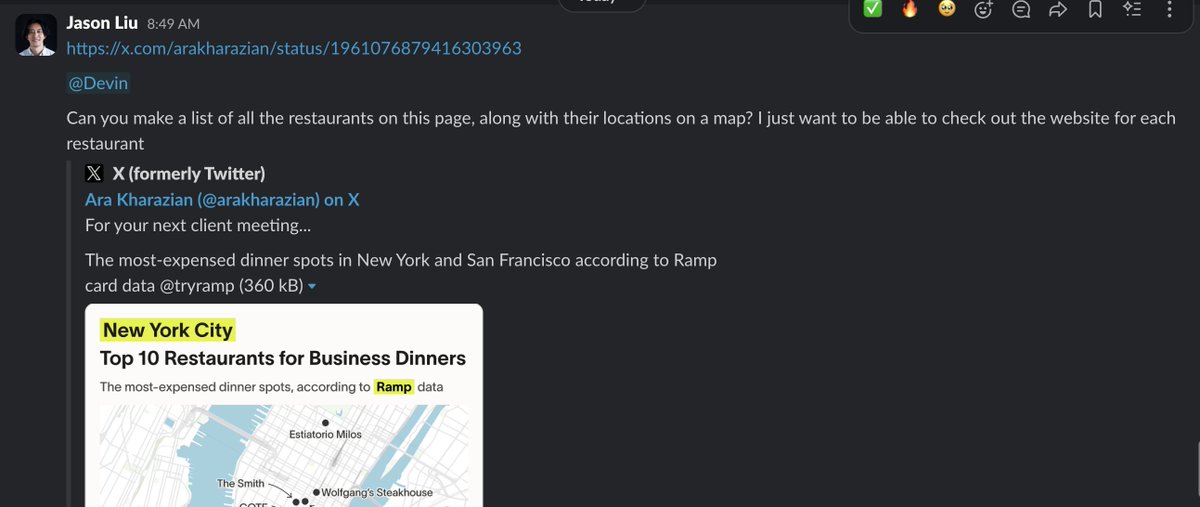
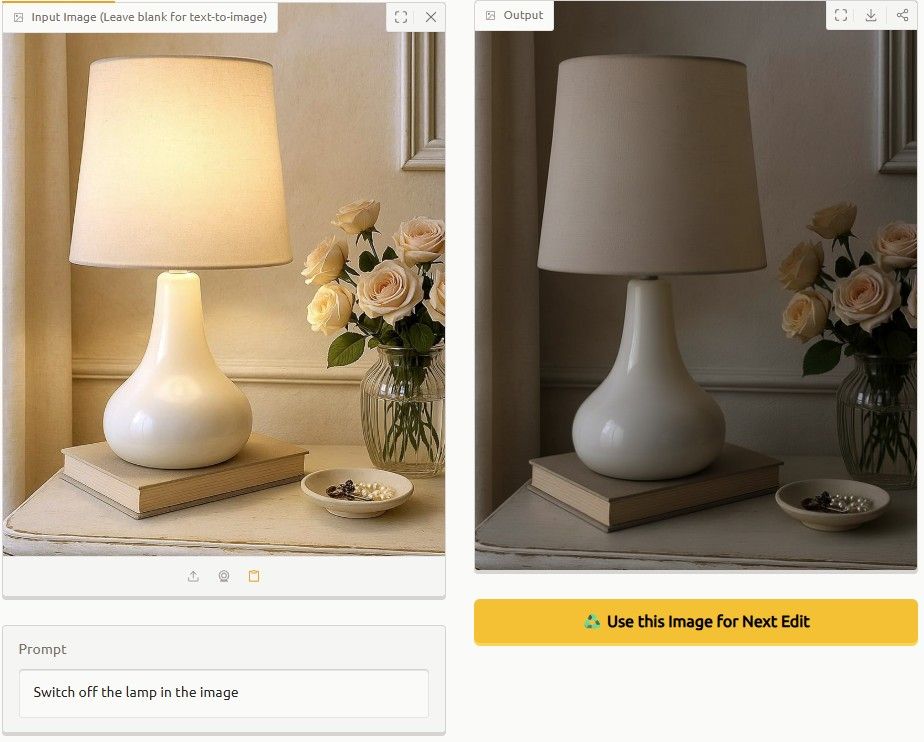
why make shareable threads on ChatGPT. When you can just post this in the general chat on Slack. https://t.co/gpmJPUfmyA
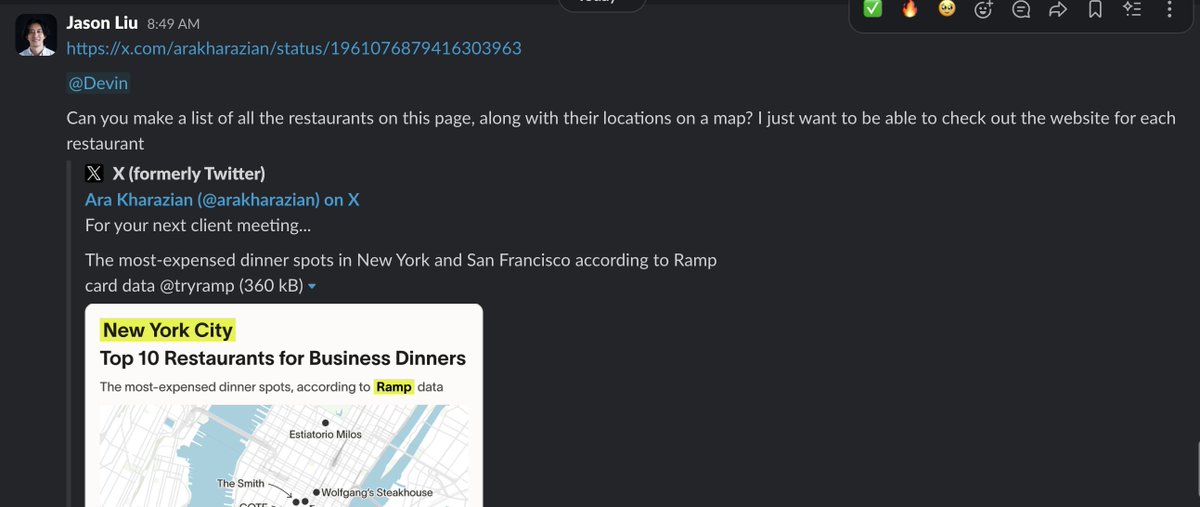
@agniv_s @cognition @augmentcode https://t.co/vKFoRL11kG