Your curated collection of saved posts and media
@emollick it’s certainly not “HUGE” by conventional interpretations; in traditional psychology (Jacob Cohen’s d) .15 is small; even in the context of education I am skeptical, and see quote below from Interpreting Effect Sizes of Education Interventions Matthew A. Kraft), which would still count it as medium, not large and certainly not all caps HUGE. But th thing about effect sizes of 0.15 in my experience is that there is usually enough of a confidence interval around it that you can’t be sure how real it is. That was Cohen’s point. (source for the 6-9 months?)

Microsoft built a voice AI so powerful they had to take it down. Deepfakes. Disinformation. Too dangerous. So they added watermarks, safety controls, and re-released it. For FREE. It's called VibeVoice. Here's what it does: → Clone any voice from 10 seconds of audio → Generate 90 minutes of multi-speaker conversation in one pass → Real-time TTS, first audio in ~200ms → Speech-to-text: 60 min of audio in a single pass, with speaker labels → 50+ languages, 4 speakers, natural turn-taking ElevenLabs: $99/month. Playht: $39/month. VibeVoice: Free. Local. MIT license. 28.5K stars. Backed by Microsoft Research. The fact they had to pull it once tells you everything about how good it is.

Hate to break it to you, but the first LLM was created by Andrey Markov in 1913. he tallied up 20,000 letters from a famous novel and computed p(vowel | vowel) p(consonant | vowel) p(vowel | consonant) p(consonant | consonant) basically 'training' a bigram by hand https://t.co/M1aLF9z2ik
Oh god are we really doing this? Jeff Dean trained an n-gram model on the entire internet in 2007. Jelinek coined the term "language model" in the '70s. It's called "Claude" because Claude Shannon was estimating the entropy rate of the English language in 1951!


Get it here: https://t.co/36PM5Kwfh6
Forgot the obligatory action shot! 🤦♂️ https://t.co/lBx23Fsbq2
For the first time in 150 years of professional baseball, a human official just got publicly overruled by an algorithm. The batter takes strike three and the umpire calls the inning over but instead of walking to the dugout, the batter taps his helmet. That tap triggers a review by twelve high speed Sony cameras installed around the perimeter of the ballpark, tracking the pitch to within one sixth of an inch. The system renders a verdict in fifteen seconds, and the scoreboard shows every person in the stadium a 3D animated replay of exactly where the pitch crossed the plate. In the first week of the 2026 season, more than half of all challenges proved the umpire's call was wrong and even at their best, human umpires still missed roughly eleven calls per game. Veteran umpire C.B. Bucknor, who has worked in this league for decades had multiple calls reversed by the system in a single game. The technology itself originated in a British military lab tracking fighter jets in NATO training exercises, then became the Hawk-Eye platform Sony now deploys across tennis, soccer, cricket, and the Olympics. Tennis ran this exact experiment first, and within fifteen years there were no human line judges left at Wimbledon or the US Open. Sports betting is now legal in 38 states with individual pitch outcomes tied to real-money wagers, turning every missed call into a liability in a regulated billion dollar market. This is what AI is supposed to do, not replace human judgment everywhere, but step in where the stakes are clear, the data is objective and the cost of being wrong is real.
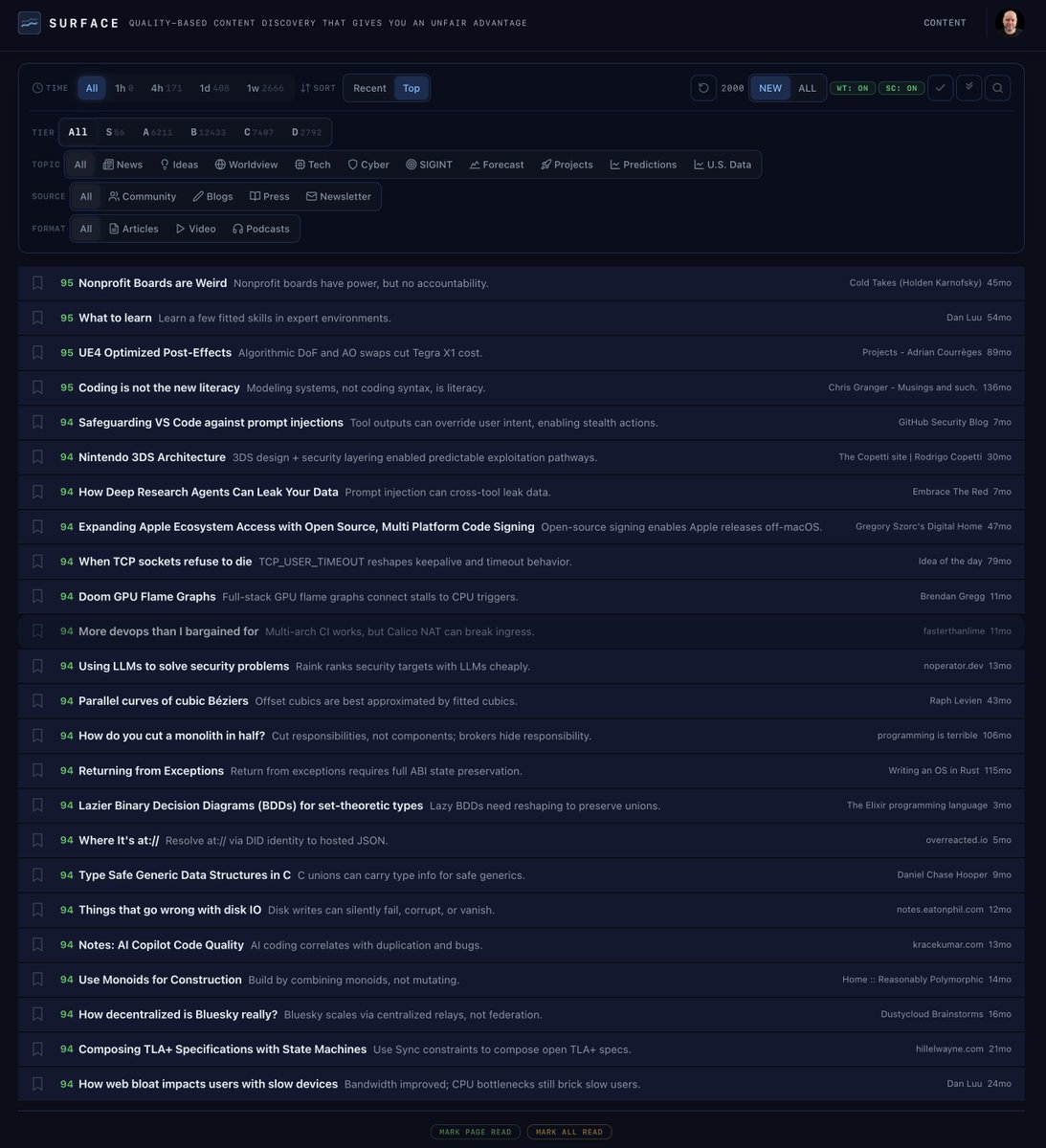
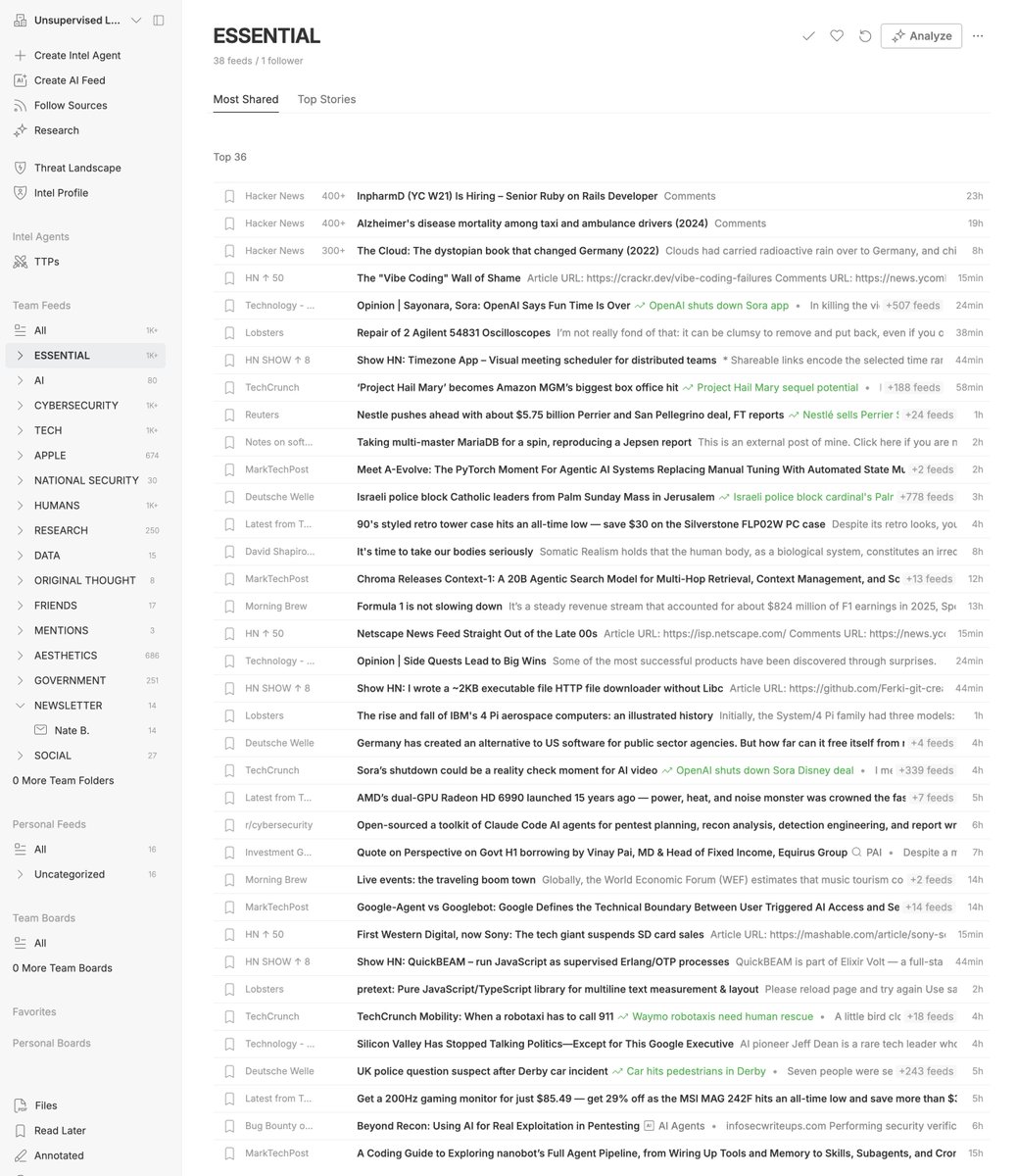
This is the night vs. day difference in how I get news now with my app called Surface. I built it as a replacement for my RSS system built over 20 years. - Over 5,300 sources - Each story rated by quality - The source doesn't matter!
Palantir CEO Alex Karp just named who wins the AI era. Not the people who mastered the system. The people who could never follow it. Karp: “We’re in a non-playbook world, and the playbook’s not that valuable.” For decades, the global economy ran on compliance. Read the manual. Follow the procedure. Execute like the person next to you. AI just automated the manual. If your entire value was executing the playbook, you are now losing to something that does it perfectly, instantly, and for free. Karp understood this before most people had the vocabulary for it. Karp: “If you’re a dyslexic, you can’t follow the playbook, so you invent new and generative things.” Neurodivergent people spent their entire lives inside a system built for a brain they do not have. The front door was locked. So they found other doors. Built new ones. Attacked problems from angles nobody else tried because the standard path was never theirs. That is not a disadvantage. That is decades of forced preparation for the exact world we just entered. The front door is now locked for everyone. The people who spent their lives perfecting the rules are scrambling. The people who spent their lives ignoring them already know how to move. The system spent a century punishing the exact people it needed most. It measured compliance and called it intelligence. It filtered out the builders. The ones who could not sit still. The ones who could not memorize a curriculum designed for someone else’s mind. And called them broken. They were not broken. They were just early.
Don’t wait until it’s too late to wish you had life insurance! @LumaLabsAI https://t.co/jj40QID7D1
I built a new plugin! You can now trigger Codex from Claude Code! Use the Codex plugin for Claude Code to delegate tasks to Codex or have Codex review your changes using your ChatGPT subscription. Start by installing the plugin: https://t.co/u6gBpArwBc https://t.co/HyEdMPWees
BREAKING: Grokipedia begins outranking Wikipedia for certain Google search results. https://t.co/uMM66WGMsf

Computer use is now in Claude Code. Claude can open your apps, click through your UI, and test what it built, right from the CLI. Now in research preview on Pro and Max plans. https://t.co/s2FDQaDmr1
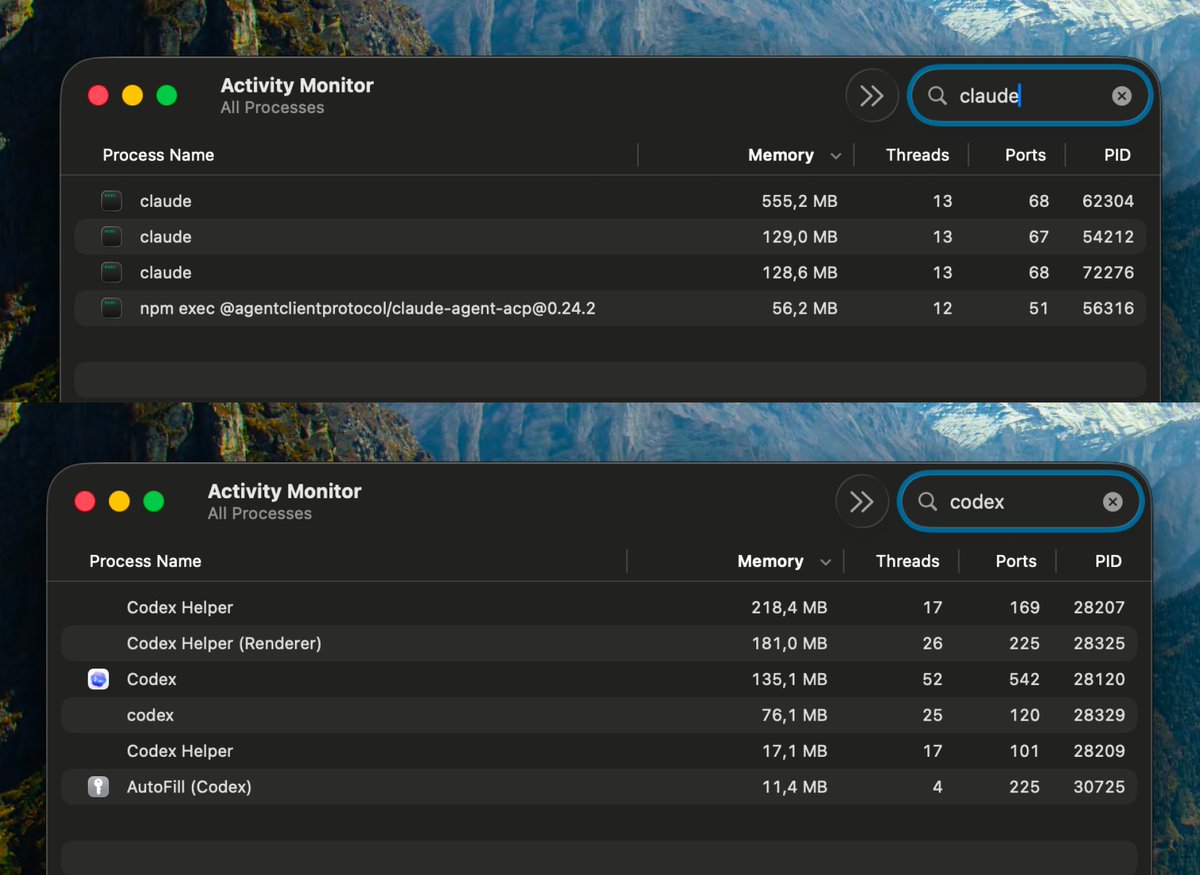
Claude Code on terminal: 868 mb~ Codex desktop app: 638 mb~ It's crazy how Codex desktop app uses less memory than running Claude Code on a terminal on Zed. I tested this on my Macbook Pro M4. I'm not using the agent panel on Zed, it's only Zed's terminal, which is using Alacritty. Both Claude and Codex are working on one task, simply calling read and write tools, and they are not running tasks or subagents. Also I noticed Claude Code memory usage can spike up to 1 GB+ and Codex's usage is way more consistent. Any explanation?
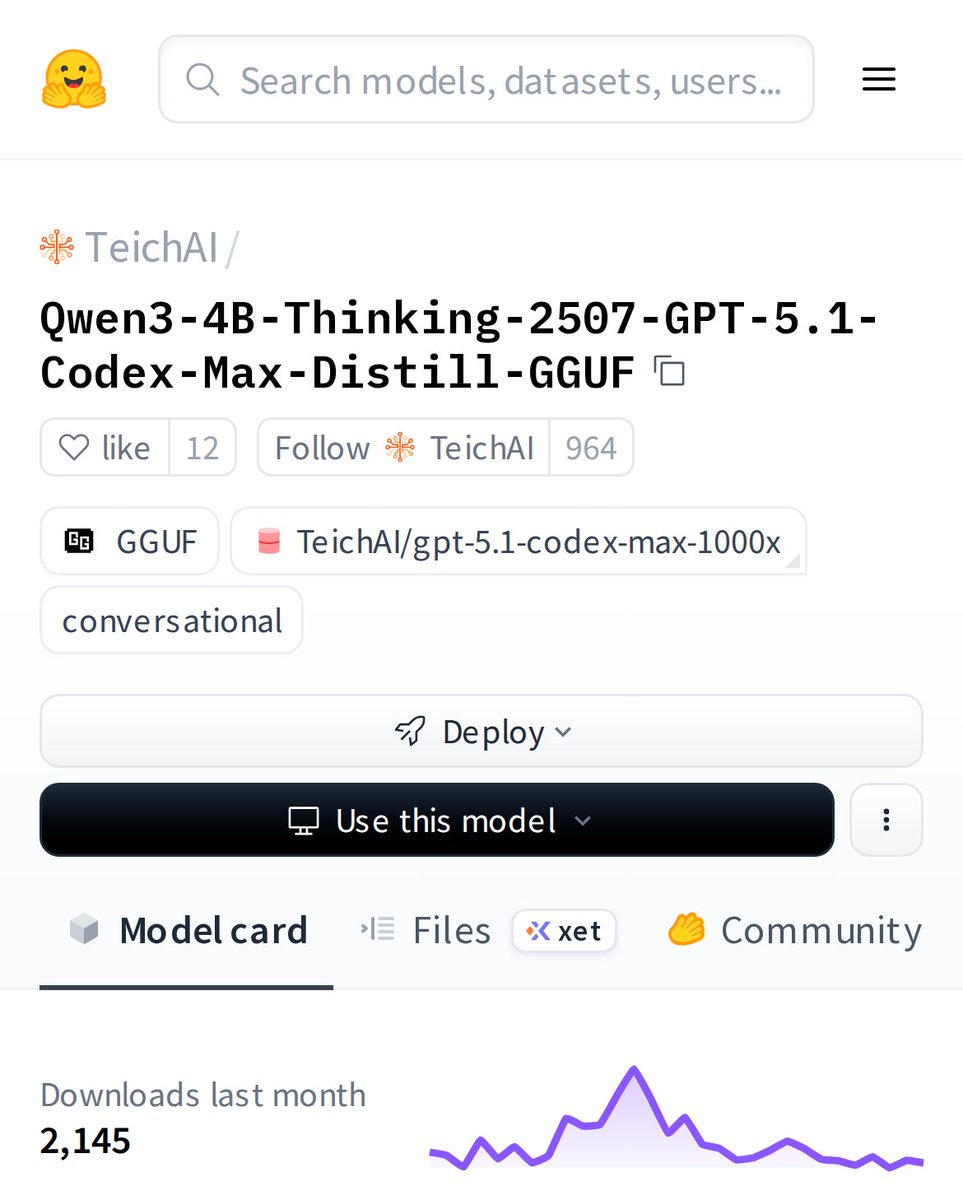
Meet Qwen3-4B-Thinking-2507: a distilled powerhouse that's making waves. This GGUF model brings advanced reasoning to local machines, letting you run sophisticated AI without cloud costs. Perfect for developers wanting cutting-edge capabilities offline. https://t.co/my4iVCA32h
Didn’t expect these to reach that high number https://t.co/SgZ09QiW6G
Didn’t expect these to reach that high number https://t.co/SgZ09QiW6G
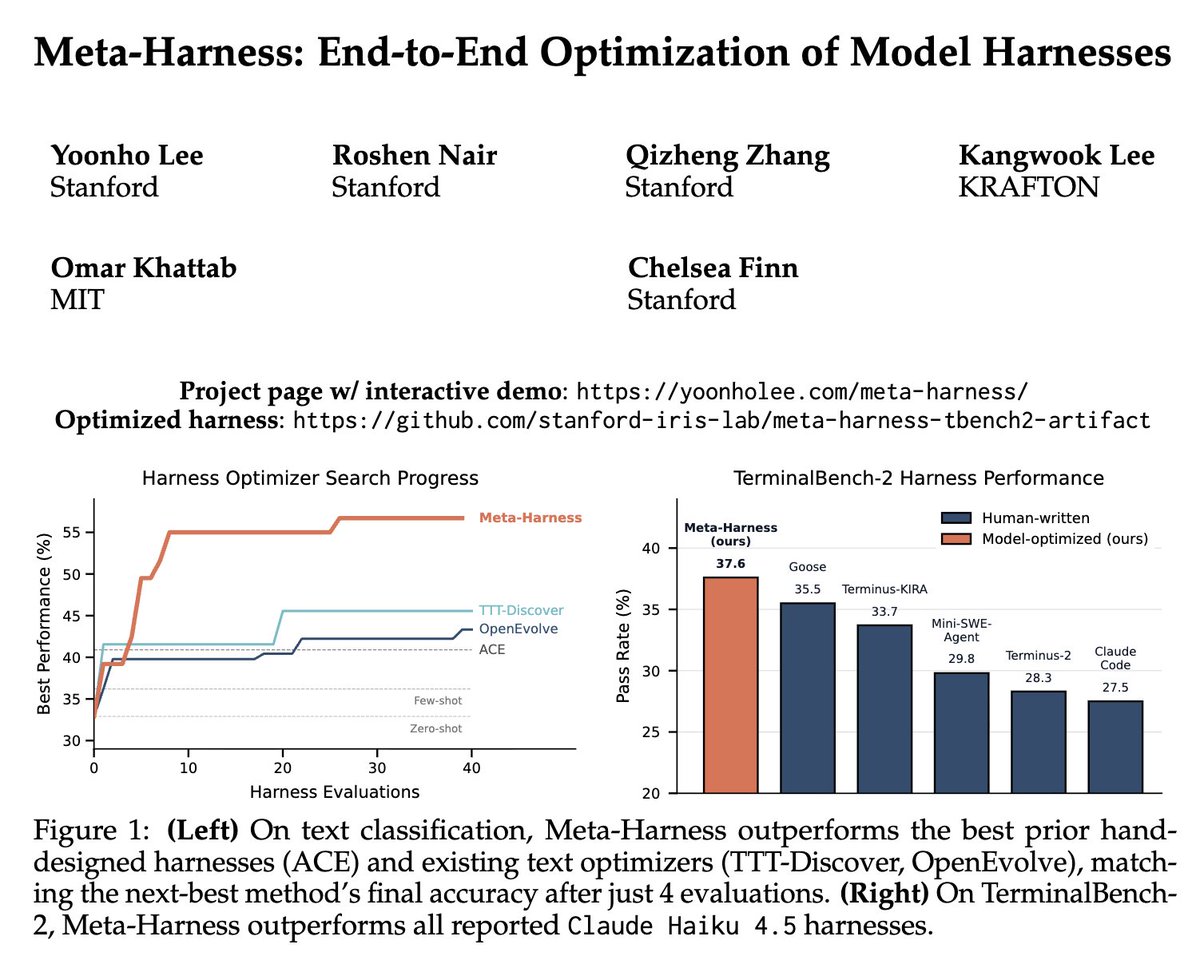
How can we autonomously improve LLM harnesses on problems humans are actively working on? Doing so requires solving a hard, long-horizon credit-assignment problem over all prior code, traces, and scores. Announcing Meta-Harness: a method for optimizing harnesses end-to-end
We made Muon run up to 2x faster for free! Introducing Gram Newton-Schulz: a mathematically equivalent but computationally faster Newton-Schulz algorithm for polar decomposition. Gram Newton-Schulz rewrites Newton-Schulz such that instead of iterating on the expensive rectangular X matrix, we iterate on the small, square, symmetric XX^T Gram matrix to reduce FLOPs. This allows us to make more use of fast symmetric GEMM kernels on Hopper and Blackwell, halving the FLOPs of each of those GEMMs. Gram Newton-Schulz is a drop-in replacement of Newton-Schulz for your Muon use case: we see validation perplexity preserved within 0.01, and share our (long!) journey stabilizing this algorithm and ensuring that training quality is preserved above all else. This was a super fun project with @noahamsel, @berlinchen, and @tri_dao that spanned theory, numerical analysis, and ML systems! Blog and codebase linked below 🧵
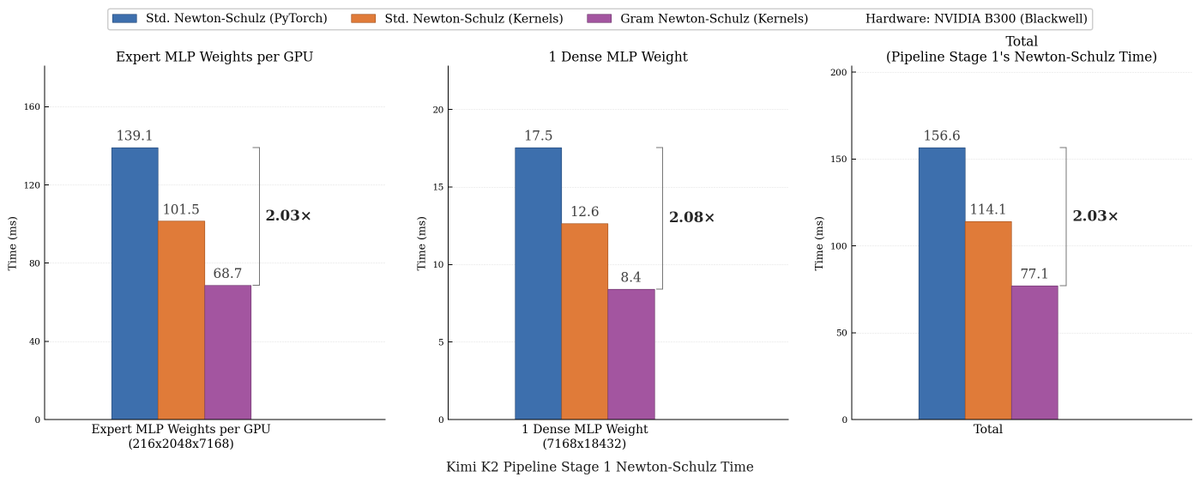
We cooked up Gram Newton-Schulz: a drop-in replacement of Muon’s Newton-Schulz that is up to 2x faster. Building this requires synthesizing ideas from linear algebra, numerical analysis, and kernel design. This makes for a great story and an even better optimizer! Amazing collaborators: @jcz42, @noahamsel, @tri_dao Blog: https://t.co/EyysR6p4Bs Code: https://t.co/5DjwIg7SAc
We made Muon run up to 2x faster for free! Introducing Gram Newton-Schulz: a mathematically equivalent but computationally faster Newton-Schulz algorithm for polar decomposition. Gram Newton-Schulz rewrites Newton-Schulz such that instead of iterating on the expensive rectangul
New blog post: how I used Codex to contribute VidEoMT, a SOTA model for video segmentation, to the Transformers library In December 2025, a shift occurred, and coding agents suddenly succeeded at a task they previously failed at: porting entire models. I list some of my best practices for using coding agents. Link: https://t.co/FFIqDAEdAZ

I'm thrilled to announce @SycamoreLabs, the trusted agent OS for the enterprise. We raised a $65M seed led by @coatuemgmt and @lightspeedvp, with @AbstractVC, @DellTechCapital, @8vc, @Fellows_Fund, @e14fund, and an exceptional group of angel investors. https://t.co/Tdm5gSgA38

Introducing Helena: the world's first autonomous AI marketer. Businesses spend 4,000 hours on marketing…before their first $1M in revenue. We built Helena to solve this. Helena can: ➤ Track competitor ads & create TikTok slideshows, UGC, static ads - all while you sleep ➤ Analyze performance across GA4, Search Console, paid/organic social for daily insights ➤ Research trends to draft GEO optimized blogs directly on WordPress, Framer, Webflow ...and more Helena has her own memory, scheduled tasks, 100+ custom marketing tools and native integrations. No dev. No CLI. No n8n. No API keys needed. Helena doesn't replace CMOs, and every marketer who's demoed it has asked us for early access. Want to hire her? Check the next thread ⬇️
this model is an agentic treasure. it has been #1 trending for 3 weeks on @huggingface as mentioned by @danielhanchen. it's Qwen 3.5 27B fine-tuned on Opus 4.6 distilled data and beats Sonnet 4.5 on SWE-bench verified and more. "Runs locally on 16GB in 4-bit or 32GB in 8-bit." https://t.co/3tM8vk1FGZ
If you liked OpenClaw but weren't a fan of the security risks, try it out: https://t.co/qw8Pi4Whcg

OpenClaw doesn't belong in production. We built PokeeClaw — enterprise-secure AI agents, zero setup, 1,000+ app integrations. Try now: https://t.co/uX6VsZ6p0c First 500 to follow @Pokee_AI, comment “PokeeClaw”, like & repost get 1 month free.

America Isn’t Ready for What #AI Will Do to Jobs #RiseoftheRobots https://t.co/q6ldsXpDSz

The average American worker using AI reports time savings of 6%, or 2.5 hours in a work week. Those are similar to the UK & Netherlands, and slightly more than other EU countries. There some early, non-causal, signs that this is translating into real gains in productivity growth https://t.co/XOspk4fp0Z
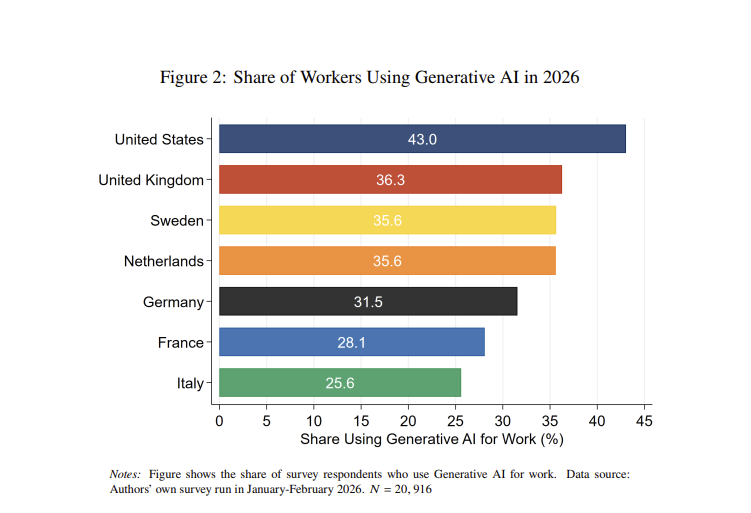
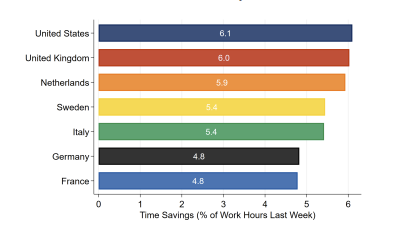
Because US workers use AI more, and gain more from it, the US currently is benefitting most from AI adoption: https://t.co/Fd66KQU9ID

Exclusive: MiniMax AI developer report. TL;DR: It provides more performance for a much lower price. I now do custom reports for companies with the analysis engine that @blevlabs and I built over the past couple of months. You've seen my reports on OpenClaw and other technologies. Here I did one for MiniMax, comparing it to other models: https://t.co/WhnARBnU8c This report was written by using the X API to grab tens of thousands of posts from the AI community (I have the most complete lists of such anywhere: https://t.co/9eRY65x3IQ and Levangie Labs' cognitive architecture does the best job of putting it all together in a report that I've found). Key things from the report: ++"MiniMax has built the most cost-effective frontier-tier coding and agentic model on the market." ++"Architecture: MoE (Mixture of Experts) — 230B total parameters, 10B active. This is the key insight: you get frontier-tier reasoning with the inference cost of a 10B model." ++"What the community said: "Basically Claude Opus performance but 95% cheaper." "80.2% SWE-Bench. 76.8% on agentic tool-calling. Genuinely underrated." One developer burned through 922 million tokens in 3 days on the coding plan across 50+ parallel sessions." ++"The consensus: MiniMax M2.7 matches or exceeds Opus on coding and agentic tasks at 1/50th the price." ++"Bottom Line for Developers: If you're building coding agents, agentic workflows, or any system that makes a lot of API calls, MiniMax is the most important model to know right now. The price-to-performance ratio is genuinely unprecedented at the frontier tier." The complete report comparing it to the other models: https://t.co/WhnARBnU8c Are you using MiniMax? Why not? The AI community here on X is. MiniMax Agent → https://t.co/NWX9GThijF API → https://t.co/lPc0F11xOU Token Plan → https://t.co/EDr6dR38w1


when people ask about custom tools vs. letting users bring MCPs, the answer is always "both". Custom tools take work and taste, MCPs give flexibility but will always lead to lower quality results 1) for high-volume tools (e.g. Read/Write/Edit in a coding agent) build these as first-class tools 2) for long tail stuff like 'fetch data from random saas', let users bring MCPs 3) LOOK AT YOUR F****** DATA (thanks @HamelHusain ) 4) The most popular MCPs, turn these into first-class tools in your system 5) repeat until AGI another dope episode with @vaibcode
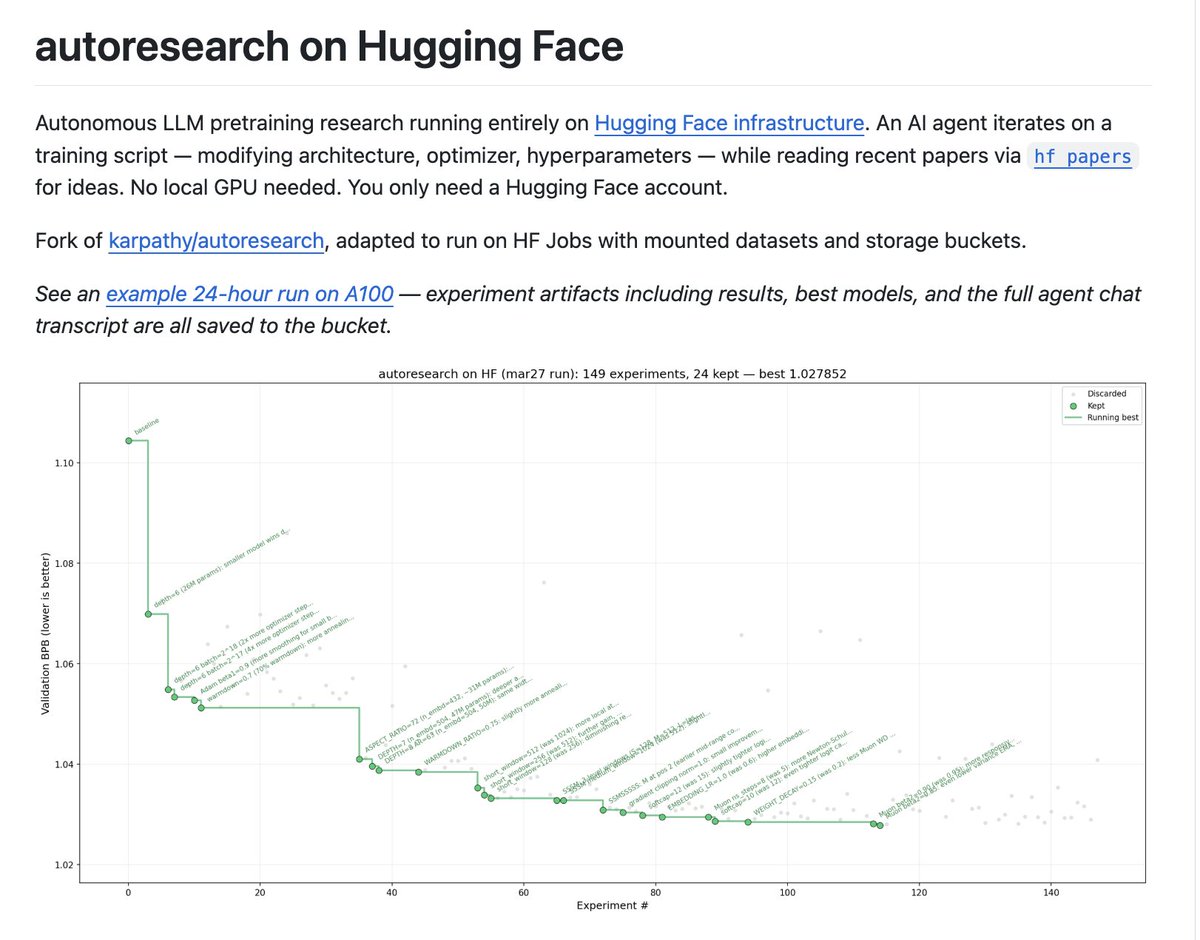
In a world where everyone can build websites, apps and features easily (thank you Cursor, Lovable, Claude and the likes), it will take more for you and your company to differentiate themselves (which is in my opinion the basis for success). That's why we're seeing more and more people and companies starting to train, optimize and run their own models (rather than outsource this to third parties). This is the future we want to enable with Hugging Face: empower millions of people to build AI themselves, not just be API users. Cool new project in this vein from @mishig25: auto-research built on top of @huggingface so that your agents find and push their intermediary checkpoints, datasets, learn from papers and collaborate on the hub: https://t.co/YWCzp5ZIfC Let's make all AI builders rather than AI users!