@kenziyuliu
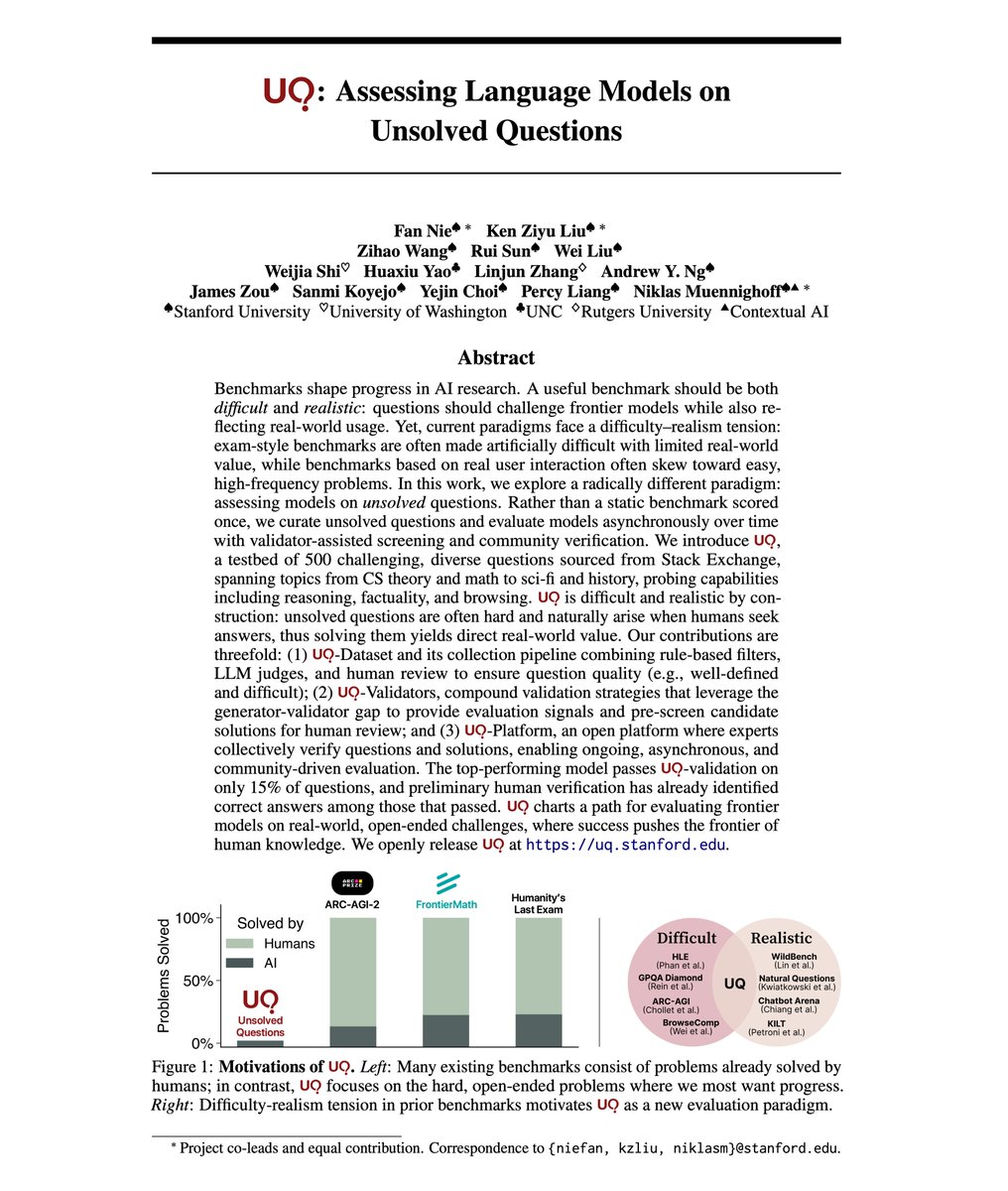
New paper! We explore a radical paradigm for AI evals: assessing LLMs on *unsolved* questions. Instead of contrived exams where progress ≠ value, we eval LLMs on organic, unsolved problems via reference-free LLM validation & community verification. LLMs solved ~10/500 so far: https://t.co/3TzD9ULEtg