Your curated collection of saved posts and media
Meet the new Slack: Where AI works. The place for all your people All your agents And now... Slackbot, your ultimate teammate. https://t.co/H64JMKCaGW
絶対AI時代のたまごっちくるよなー 作りません? https://t.co/xbJklI09rz
絶対AI時代のたまごっちくるよなー 作りません? https://t.co/xbJklI09rz
i made tetris but the board and pieces are attached to your body and it's quite tiring to play https://t.co/yEoA49igpX
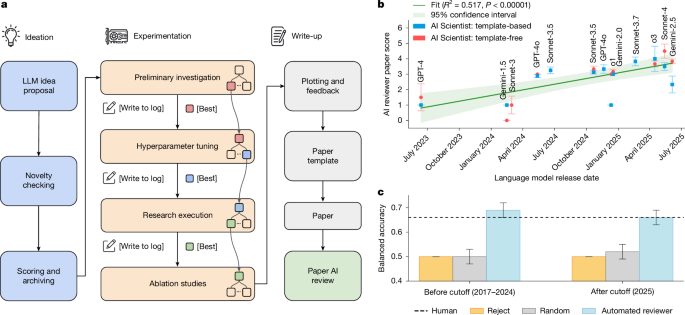
The AI Scientist: Towards Fully Automated AI Research, Now Published in Nature Nature: https://t.co/nNfpSV5e5I Blog: https://t.co/i6h8LVQOdl When we first introduced The AI Scientist, we shared an ambitious vision of an agent powered by foundation models capable of executing the entire machine learning research lifecycle. From inventing ideas and writing code to executing experiments and drafting the manuscript, the system demonstrated that end-to-end automation of the scientific process is possible. Soon after, we shared a historic update: the improved AI Scientist-v2 produced the first fully AI-generated paper to pass a rigorous human peer-review process. Today, we are happy to announce that “The AI Scientist: Towards Fully Automated AI Research,” our paper describing all of this work, along with fresh new insights, has been published in @Nature! This Nature publication consolidates these milestones and details the underlying foundation model orchestration. It also introduces our Automated Reviewer, which matches human review judgments and actually exceeds standard inter-human agreement. Crucially, by using this reviewer to grade papers generated by different foundation models, we discovered a clear scaling law of science. As the underlying foundation models improve, the quality of the generated scientific papers increases correspondingly. This implies that as compute costs decrease and model capabilities continue to exponentially increase, future versions of The AI Scientist will be substantially more capable. Building upon our previous open-source releases (https://t.co/H1tBT14Yx8), this open-access Nature publication comprehensively details our system's architecture, outlines several new scaling results, and discusses the promise and challenges of AI-generated science. This substantial milestone is the result of a close and fruitful collaboration between researchers at Sakana AI, the University of British Columbia (UBC) and the Vector Institute, and the University of Oxford. Congrats to the team! @_chris_lu_ @cong_ml @RobertTLange @_yutaroyamada @shengranhu @j_foerst @hardmaru @jeffclune
やばい、Codexのソースコードまで漏れてる! https://t.co/7BmswMMYWr
やばい、Codexのソースコードまで漏れてる! https://t.co/7BmswMMYWr
If you, like me, just woke up, let me catch you up on the Claude Code Leak (I know nothing, all conjecture): > Someone inside Anthropic, got switched to Adaptive reasoning mode > Their Claude Code switched to Sonnet > Committed the .map file of Claude Code > Effectively leaking the ENTIRE CC Source Code > @realsigridjin was tired after running 2 south korean hackathons in SF, saw the leak > Rules in Korea are different, he cloned the repo, went to sleep > Wakes up to 25K stars, and his GF begging him to take it down (she's a copyright lawyer) > Their team decided - how about we have agents rewrite this in Python!? Surely... this is more legal > Rewrite in Py > Board a plane to SK🇰🇷 > One of the guys decides python is slow, is now rewriting ALL OF CLAUDE CODE into Rust. > Anthropic cannot take down, cannot sue > Is this "fair use?" > TL;DR - we're about to have open source Claude Code in Rust
“When you haven’t heard someone talk for four years, the thought that they might be able to talk again was mind blowing." https://t.co/KasDacgKzs
🌟 Join the TorchTPU session at #PyTorchCon Europe 2026 in Paris on April 7–8. Learn the strategy and roadmap that brings a native @PyTorch experience to TPUs. The program includes infrastructure, applications, and agent-based systems, with sessions on training, inference, gen AI, responsible AI, security, privacy, and frameworks.

i made tetris but the board and pieces are attached to your body and it's quite tiring to play https://t.co/yEoA49igpX
i made tetris but the board and pieces are attached to your body and it's quite tiring to play https://t.co/yEoA49igpX
Justice for the Gays of Hormuz https://t.co/73SFJr5dBD
We @neosigmaai @RitvikKapila are building the future of self-improving AI systems! By closing the feedback loop between production data and system improvements, we help teams capture failures, convert them into structured evaluation signals, and use them to drive continuous improvements in agent behavior. We show how our system works on Tau3 bench across retail, telecom, and airline domains. Agent performance on the validation set (with a fixed underlying model, GPT5.4) improves from 0.56 → 0.78 (~40% jump in accuracy).
In this 2015 interview, the host — a Tsinghua University professor — expressed genuine curiosity about how Elon Musk was able to found SpaceX without prior experience and knowledge in aerospace, especially given that rocket science is one of the most demanding hard sciences — and that Musk was serving as both CEO and CTO. Musk explained that deep expertise can be built outside formal academic programs — by reading extensively, conducting experiments, and speaking directly with experts in the field.
Today, we're launching the Secure Intelligence Institute. SII partners with top cryptography, security, and ML teams to advance security research and industry collaboration. It is led by Dr. Ninghui Li at Purdue. https://t.co/Uga9SxgLBn https://t.co/Bnj5DWYN58

AI is now being used to see what was previously invisible. MIT researchers have developed a model that can detect atomic-level defects in materials, helping improve strength, heat transfer and energy efficiency. This is where AI goes beyond data. It starts to reshape how we design the physical world. https://t.co/6KzxZsgXKM @MIT

big if true https://t.co/wXrG2i33r2
big if true https://t.co/wXrG2i33r2
HandX Scaling Bimanual Motion and Interaction Generation paper: https://t.co/vDI3xTQDMb https://t.co/SQV6ZlQZkE

Try out Veo 3.1 Lite today in @GoogleAIStudio ! We've designed it for folks to tinker with different ideas quickly and cheaply. The best part is that it starts at just $0.05/sec!! That's an 50% drop in price, support for 8s clips and a new model you're not gonna want to miss :) https://t.co/pROMktcG3L

We finally shipped TRL v1.0!! stable APIs, broad integrations, and a design built to absorb whatever the field throws at it next. Let's go! https://t.co/lELxIultJf https://t.co/X3uyBOOkeJ


Is this a flex these days? https://t.co/xDT8j6HknO
Is this a flex these days? https://t.co/xDT8j6HknO
Imagine running Claude 4 Opus-level reasoning but on your own GPU with only 16GB VRAM. This 27B model frontier-level coding it's beating Claude Sonnet 4.5 on SWE-bench locally on 16GB VRAM 4-bit. v2 slashes chain-of-thought bloat by 24% while keeping 96.91% HumanEval accuracy. https://t.co/lC7uuTzWTx
This is either brilliant or scary: Anthropic accidentally leaked the TS source code of Claude Code (which is closed source). Repos sharing the source are taken down with DMCA. BUT this repo rewrote the code using Python, and so it violates no copyright & cannot be taken down! https://t.co/uSrCDgGCAZ
Today, we're announcing Heaviside, our foundation model for electromagnetism. Trained on tens of millions of designs and over 20 years of proprietary simulation data, Heaviside predicts electromagnetic behavior from geometry in 13ms, which is 800,000x faster than a commercial solver. Heaviside is not a language model, and it’s not a surrogate model. Heaviside marks a new class of foundation model for physics which understands the fundamental relationships between materials, the geometries and the electromagnetic fields they generate. We’re releasing a research preview of Heaviside in Atlas RF Studio, an interactive agentic sandbox where you describe the EM behavior you want and the model generates the physical structure that produces it. @arenaphysica , we believe the implications of this class of model extend well beyond RF, as the frontier of exquisite hardware is electromagnetically-governed: wireless communication, radar, power delivery, high-speed computing, and the interconnects inside every chip on earth. In the months ahead, we’re excited to scale up Heaviside to broader frequency ranges, design spaces, and to support silicon-level designs, and deploy it with our closest partners and collaborators in service of their biggest design challenges. If you’ve read our thesis, this is just Step 2 in our pursuit of electromagnetic superintelligence. Read the full announcement and try Atlas RF Studio…tell us what you think: https://t.co/oCOsJQvF1h

Introducing Veo 3.1 Lite, now available via the Gemini API and @GoogleAIStudio. Veo 3.1 Lite supports both Text-to-Video and Image-to-Video, and is less than half the cost of Veo 3.1 Fast. https://t.co/9Wtw3avHDW
My 2026 I/O https://t.co/3NSHBVXv4M


My 2026 I/O https://t.co/3NSHBVXv4M


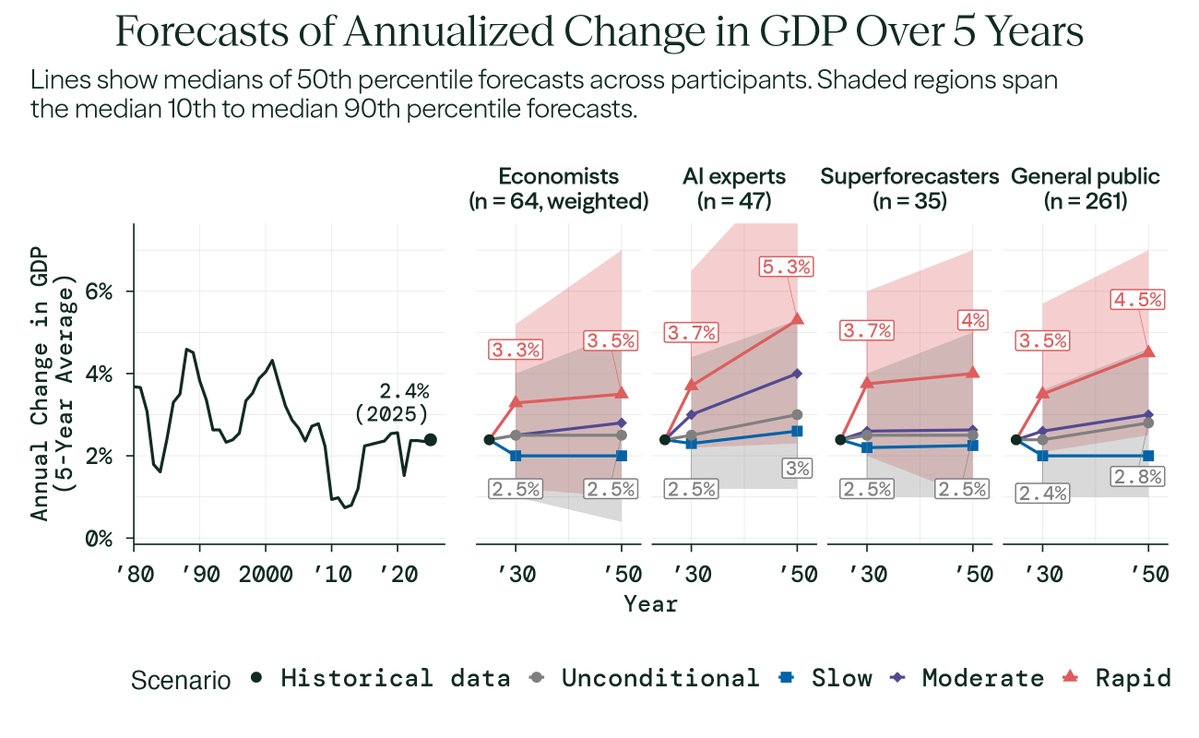
We completed the most comprehensive study of how economists and AI experts think AI will affect the U.S. economy. They predict major AI progress—but no dramatic break from economic trends: GDP growth rates similar to today's and a moderate decline in labor force participation. However, when asked to consider what would happen in a world with extremely rapid progress in AI capabilities by 2030, they predict significant economic impacts by 2050: • Annualized GDP growth of 3.5% (compared to 2.4% in 2025) • A labor force participation rate of 55% (roughly 10 million fewer jobs) • 80% of wealth held by the top 10% (highest since 1939) 🧵 Here's what we found: