@eliebakouch
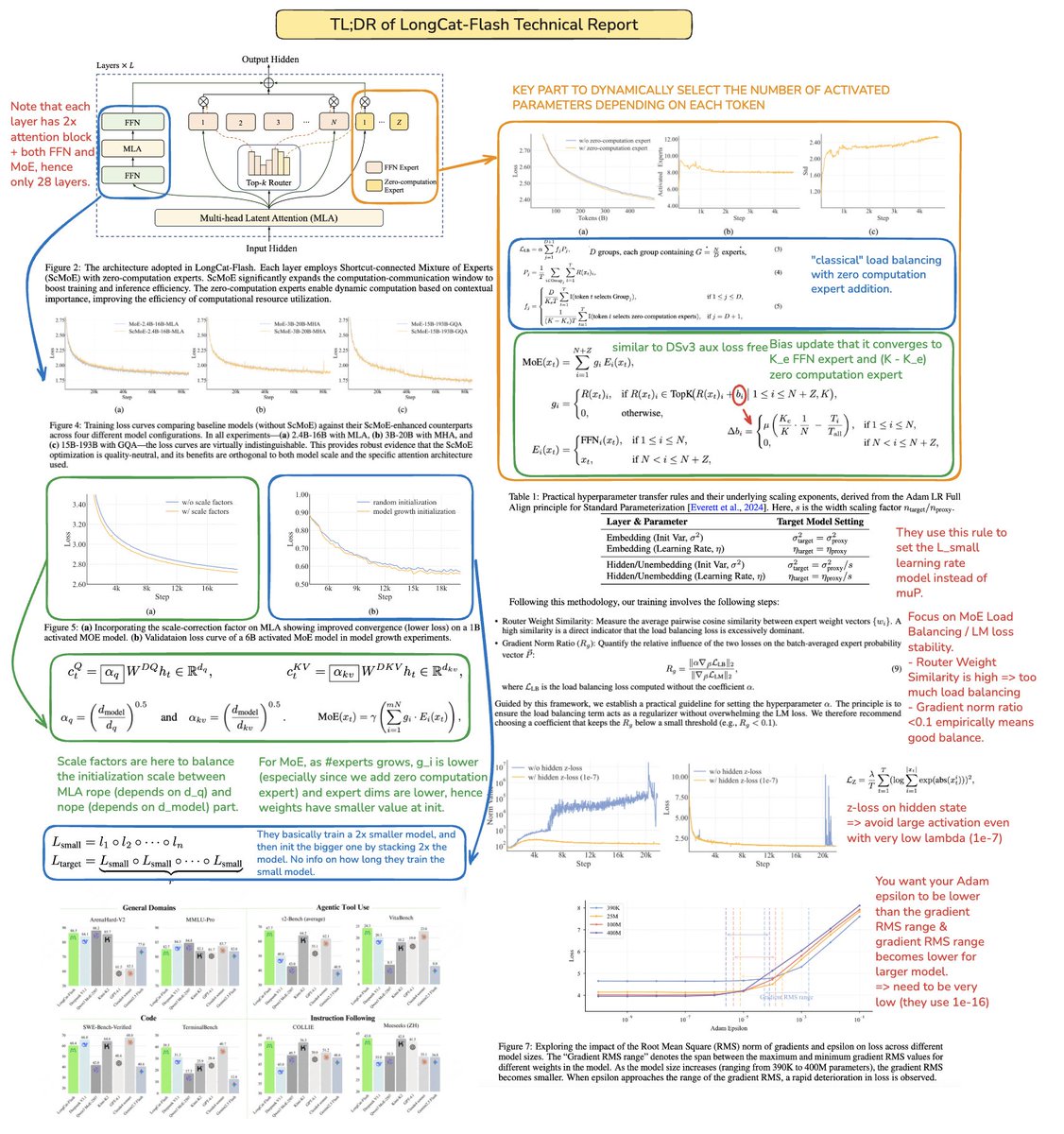
The technical report of @Meituan_LongCat LongCat-Flash is crazy good and full of novelty. The model is a 560B passive ~27B active MoE with adaptive number of active parameters depending on the context thanks to the Zero-Computational expert. 1) New architecture > Layers have 2 Attention blocks and both FFN and MoE, that way you can overlap the 2 all-to-all coms. (also it's only 28 layers but you have to take into account the 2 attention blocks). > They add the zero-computational expert that tokens can choose and do nothing, kinda like a "sink" for easy tokens. > For load balancing, they have a dsv3-like aux loss free to set the average real/fake expert per token. They apply a decay schedule to this bias update. They also do loss balance control. 2) Scaling > They made changes to MLA/MoE to have variance alignment at init. The gains are pretty impressive in Figure 5, but i don't know to what extent this has impact later on. > Model growth init is pretty cool, they first train a 2x smaller model and then "when it's trained enough" (a bit unclear here how many B tokens) they init the final model by just stacking the layers of the smaller model. > They used @_katieeverett @Locchiu and al. paper to have hyperparameter transfer with SP instead of muP for the 2x smaller model ig. 3) Stability > They track Gradient Norm Ratio and cosine similarity between experts to adjust the weight of the load balancing loss (they recommend Gradient Norm Ratio <0.1). > To avoid large activations, they apply a z-loss to the hidden state, with a pretty small coef (another alternative to qk-clip/norm). > They set Adam epsilon to 1e-16 and show that you want it to be lower than the gradient RMS range. 4) Others > They train on 20T tokens for phase 1, "multiple T of tokens" for mid training on STEM/code data (70% of the mixture), 100B for long context extension without yarn (80B for 32k, 20B for 128k). The long context documents represent 25% of the mixture (not sure if it's % of documents or tokens, which changes a lot here). > Pre-training data pipeline is context extraction, quality filtering, dedup. > Nice appendix where they show they compare top_k needed for different benchmarks (higher MMLU with 8.32, lower GSM8K with 7.46). They also compare token allocation in deep/shallow layers. > They release two new benchmarks Meeseeks (multi-turn IF) and VitaBench (real-world business scenario). > Lots of details in the infra/inference with info on speculative decoding acceptance, quantization, deployment, kernel optimization, coms overlapping, etc. > List of the different relevent paper in thread 🧵