Your curated collection of saved posts and media
@embirico https://t.co/IoNlALqPPL

Asmongold explains Keir Starmer's resignation using a WoW raid strategy and it makes perfect sense "Labour just performed a tank swap. Starmer had too many debuffs so they pulled him out and brought in a new tank." "The new guy is going to do the same thing for the same raid. They're tanking the same boss in the same way." "You're Onyxia. Don't fall for the tank swap. He's not the organization. You didn't win, they just reset your aggro."
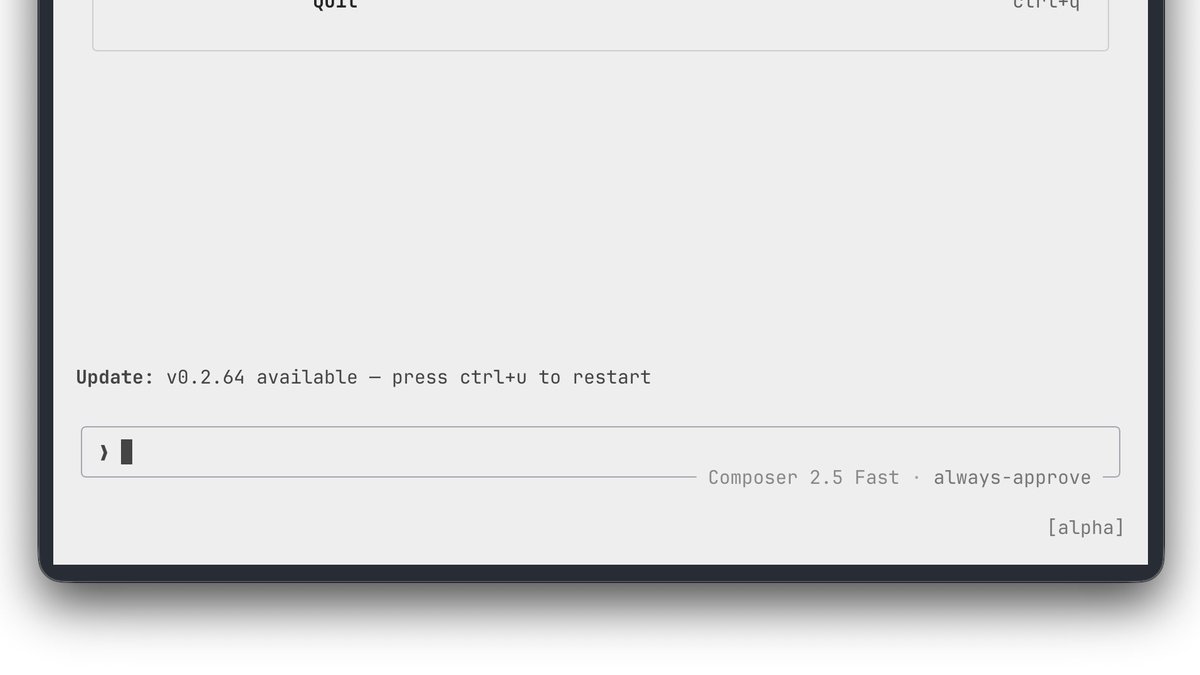
Grok Build just got another update with many improvements Release Notes: v0.2.64 — 2026-06-24 Features: • Dashboard now displays the current directory and branch; click or press Ctrl+L to change location, or Ctrl+W to dispatch new agents into fresh git worktrees. • /recap now appears as a collapsible tool-style block with a loading spinner while generating. Bug Fixes: • Dashboard arrow keys open agent details and exit overlays; closing an agent now selects the neighboring row. • /usage command and credit warnings are now hidden for API-key authentication. • MCP servers from your user config no longer appear labeled as project-scoped when running from your home directory.
Grok Build just got another update with many new features, improvements, and bug fixes Release Notes: 0.2.61 – 2026-06-22 Features: • Closing a terminal tab with a running process now shows a confirmation dialog instead of killing it immediately. • /usage now shows prepaid cred
@Exogynous @BrianRoemmele Come to the discord and we'll help make sure that works! https://t.co/5EoJ4EBecb

A single app model and a simplified local run loop. This Open Source Friday, we'll learn about @aspiredotdev: a code-first orchestration and observability layer for distributed apps, with a built-in dashboard for logs, traces, and metrics. Set a reminder 🔔 https://t.co/5FR2c6pKT0

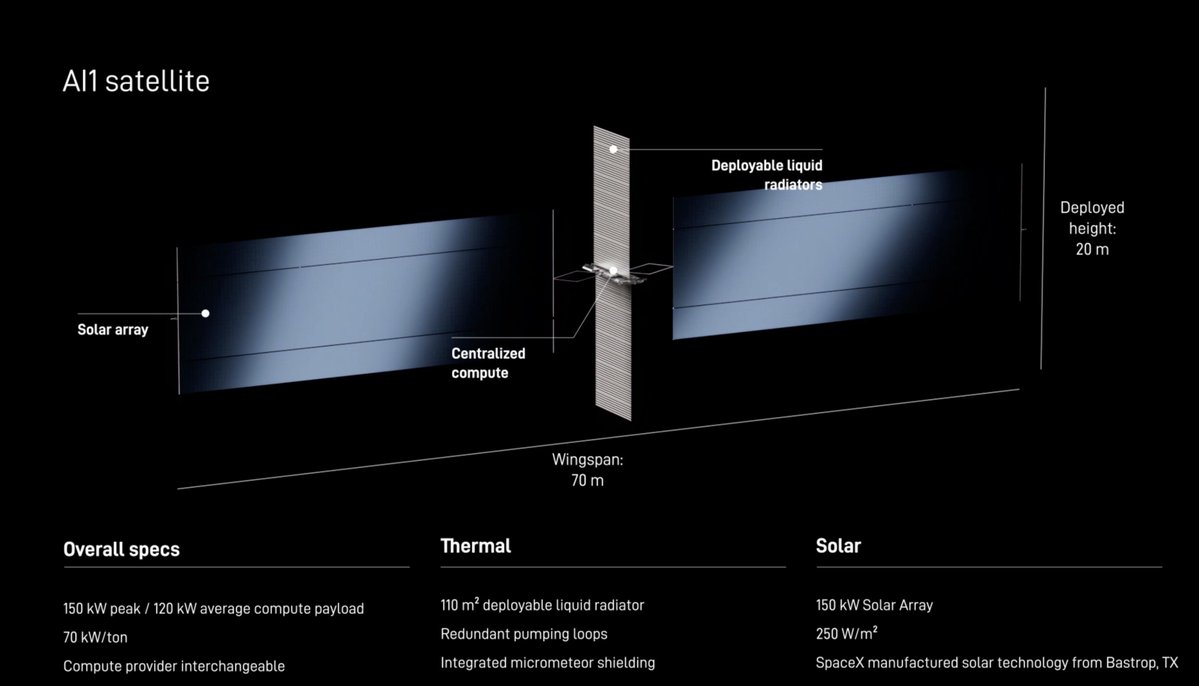
Elon Musk just confirmed that ‘Starmind’ will be the official name of the SpaceX AI satellite constellation https://t.co/nwkRsIb4eq
People who are complaining that he spends the first half of the movie murdering white people not migrants fail to understand that it’s hammering home an important premise. “Always hang a traitor before you shoot an enemy” https://t.co/M3XkVmVlGu

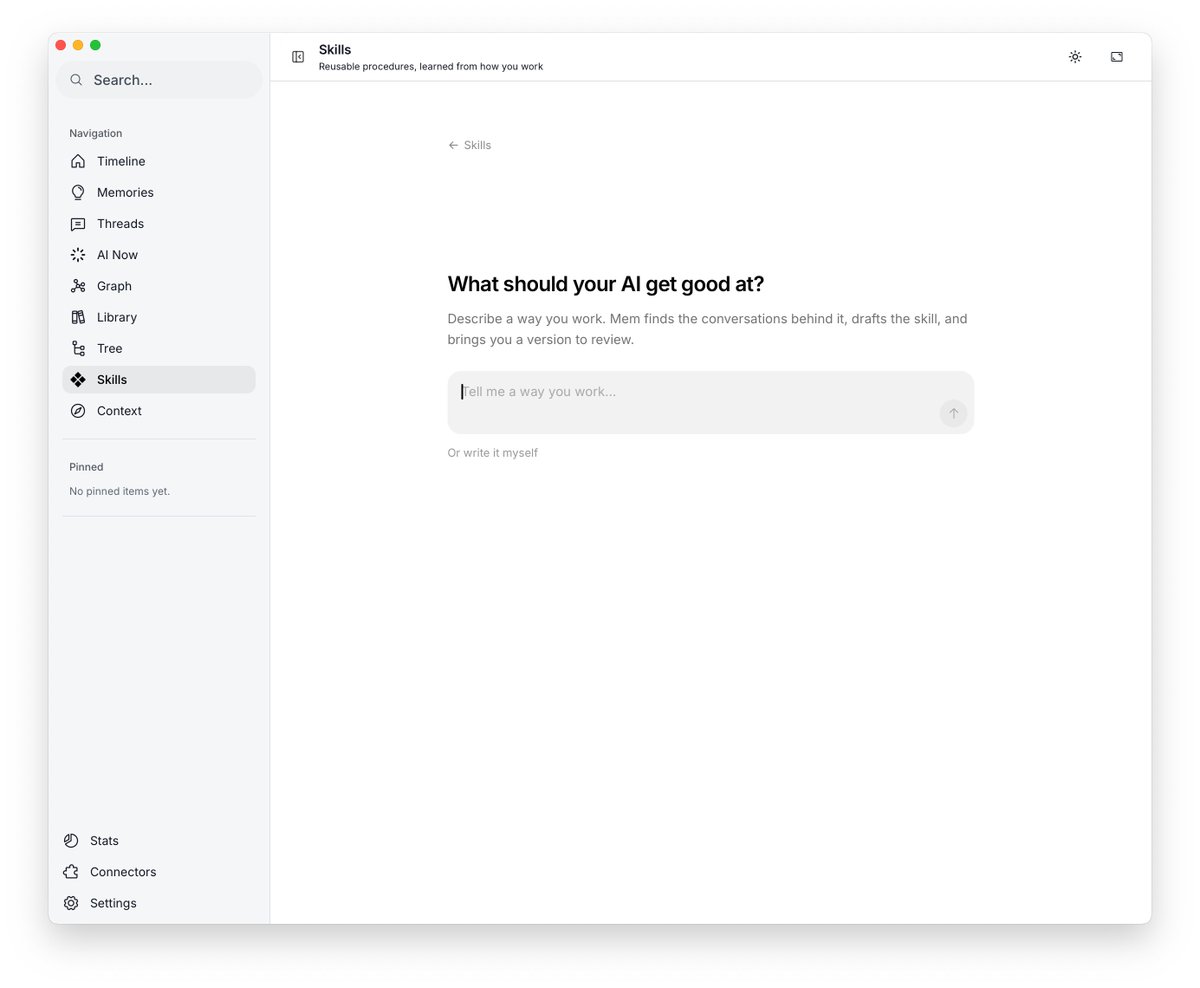
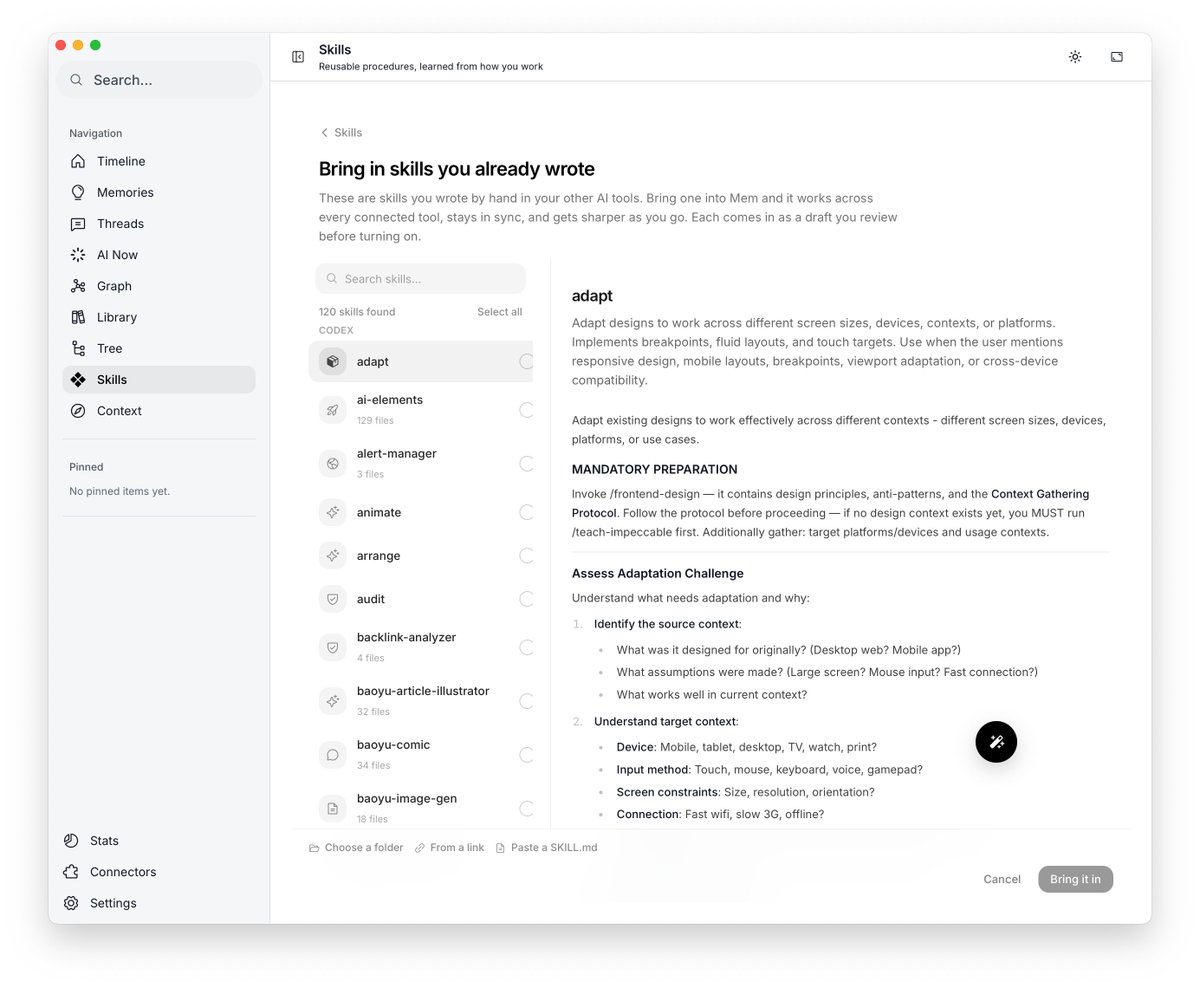
Hermes 引入了 /learn 从任何 input 习得可复用的技能🫡 Nowledge Mem 的 Skills 也有一样的能力 除了默默主动从历史上下文里摸索出可能潜在构成 skills 的机会提示给用户,用户激活之后可以在所有 agent 里调用,并且随着调用还会不断自优化、演进外; GUI 里的 Skill Creator 允许我们主动创建 Skill,它会自动找到相关的历史上下文进行创建和自优化。 其次我们根据用户老师们的建议,闭环了这个主动 flow,增加了 cli 和 ai-now 里的主动创建 Skills 的入口
Hermes can now LEARN from any source or set of sources, build a skill, test it live, and crystallize new learnings. Just run /learn and pass it sources, past sessions, URLs, docs, whatever you think will help it learn, and it'll go from 0 to 1 to create you a skill!
Made in London with AWS: Justina Chung, VP, @BessemerVP. Based in Bessemer’s London office, Chung discusses the AI advantage for startups looking to launch and build a business in the city. Through the company's partnership with AWS, she is able to help founders access infrastructure, compute, and expertise.
@jxnlco LinkedIn is starting to find it https://t.co/Sy4aMmbmqa
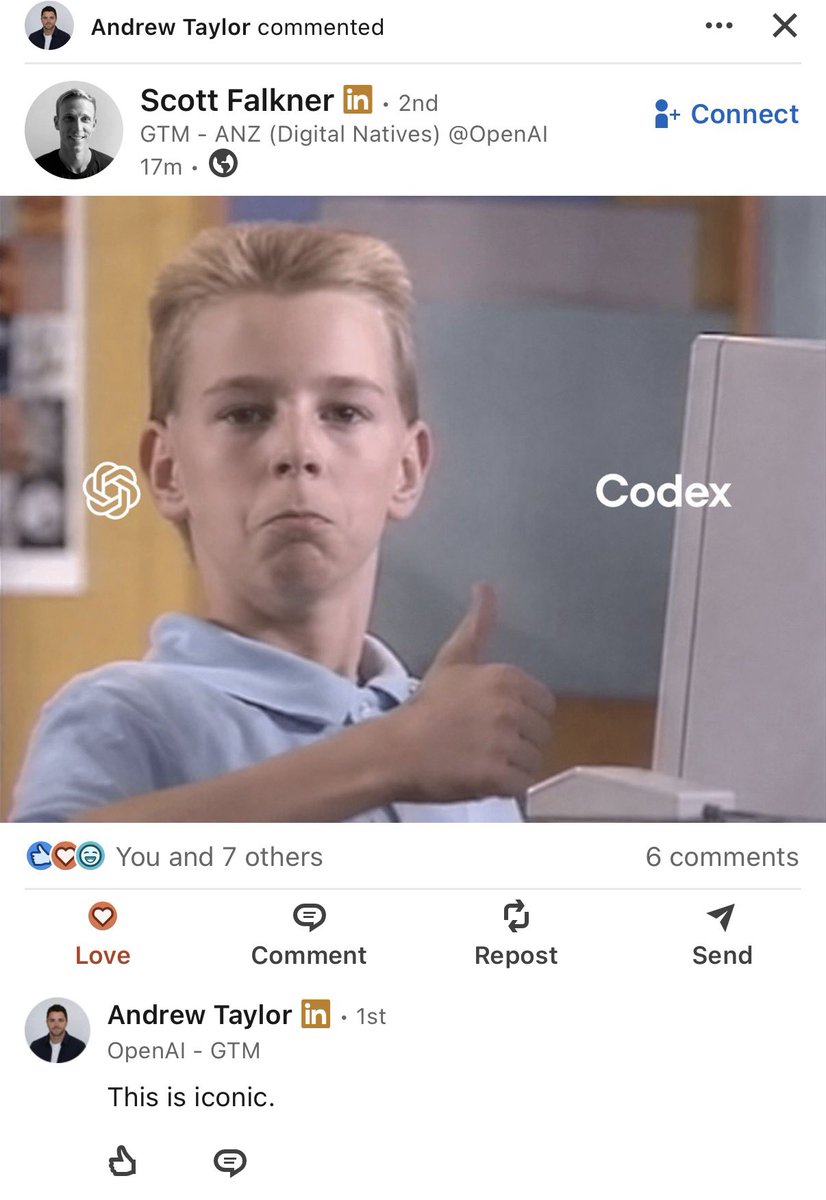
@jxnlco LinkedIn is starting to find it https://t.co/Sy4aMmbmqa
today, we release the open weights of Krea 2. welcome Krea 2 Raw and Krea 2 Turbo, an undistilled model from mid-training meant to be fine-tuned, and a fast distilled version with a wide aesthetic diversity. read the details below 👇 https://t.co/3ymzUL2bxv
@TheZachMueller Don’t let the polls do this to you 🤣 https://t.co/9OHRTU1J9I

JUST IN🚨: A quantum computer just performed 2.6 billion years of computation in 4 minutes https://t.co/Zy4ZI6yDis


JUST IN🚨: A quantum computer just performed 2.6 billion years of computation in 4 minutes https://t.co/Zy4ZI6yDis


💯 https://t.co/RltSC8fg9b

@NousResearch Hey Hermes, /learn Kung Fu https://t.co/PcyRLbkaIX

@NousResearch Hey Hermes, /learn Kung Fu https://t.co/PcyRLbkaIX

Learned good things from the most recent test! The 'gear ratio' between the syringe bore vs the 1/16' tube vs the 0.1mm wide channels on the chip is hard to wrap my head around. I think tomorrow I'll stop building from my head and see how other people do microfluidics haha. https://t.co/GvrCiXFUuW

Qwen-AgentWorld: Language World Models for General Agents "We introduce Qwen-AgentWorld-35B-A3B and QwenAgentWorld-397B-A17B, the first language world models capable of simulating agentic environments covering 7 domains via long chain-of-thought reasoning." "We explore two complementary strategies for applying world modeling to enhance language agents (mainly using the 35B-A3B model as agent): Decouple and Unify , where the world model serves as the environment simulator and agent foundation model, respectively."
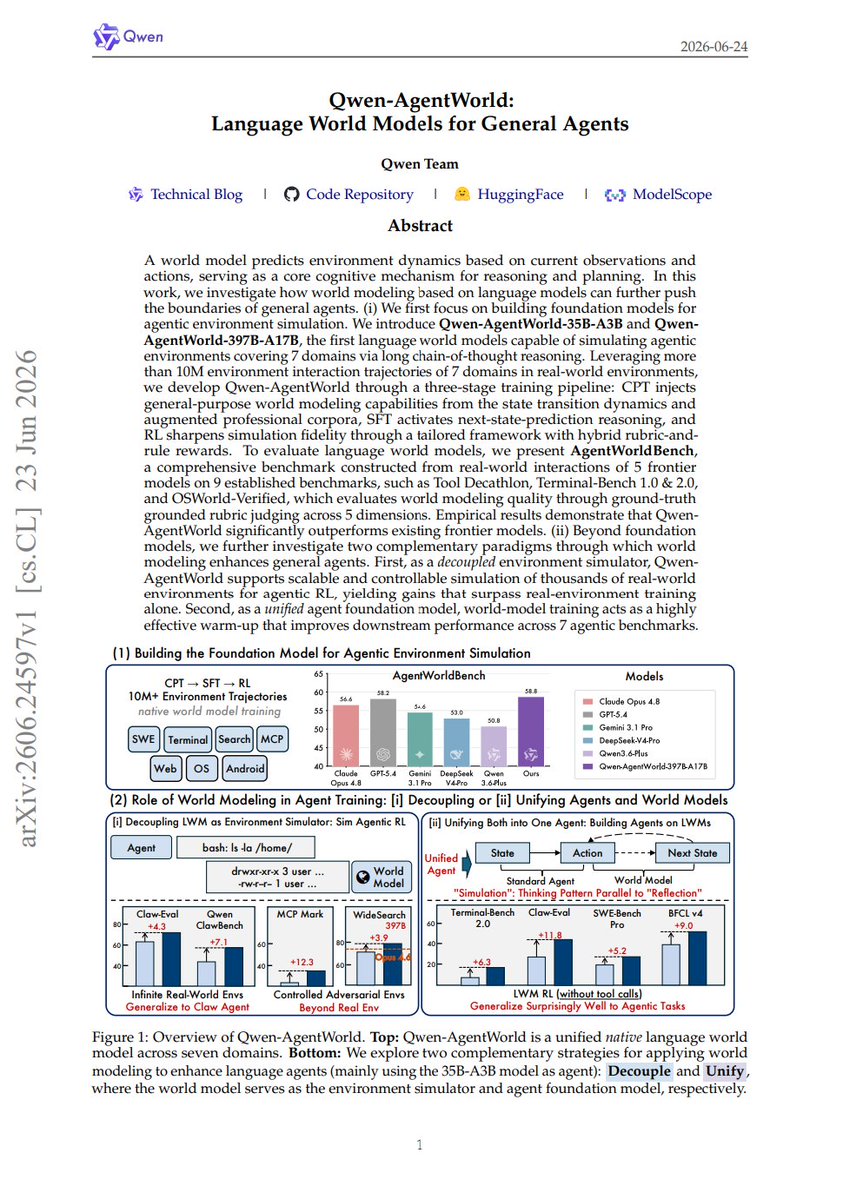
blog: https://t.co/qLAINM9ozD code: https://t.co/EqmJlMtB8C huggingface: https://t.co/yPbcomSzwq abs: https://t.co/2VZCXCO6gC

OpenThoughts-Agent: Data Recipes for Agentic Models "a fully open data curation pipeline for training agentic models" "more than 100 controlled ablation experiments to systematically investigate each stage of the pipeline" Key findings: • As with reasoning data, the choice of instructions is among the most important factors in our data pipeline. • The strongest model by benchmark performance does not necessarily make the best teacher. • Filtering training data to retain the execution traces with more model turns improves the resulting training sets. • Repeating the top few sources leads to diminishing returns in our largest training runs, and we therefore expand the set of data sources to increase diversity. "We then assemble a training set of 100K examples from our pipeline and fine-tune Qwen3-32B on this dataset, which yields an average accuracy of 44.8% across seven agentic benchmarks"

Try this great Unlimited-OCR demo from @_akhaliq: https://t.co/IhXb2Kyf5O
Baidu just released Unlimited-OCR https://t.co/oxvNrDg1SC

Try this great Unlimited-OCR demo from @_akhaliq: https://t.co/IhXb2Kyf5O

Elon confirms "Starmind" will be the official name of @SpaceX's AI satellite constellation. Earlier this year, SpaceX filed a request with the FCC to launch and operate a constellation of 1 million AI satellites. SpaceX's AI1 satellite: https://t.co/BrssGvX6Ub
@xdNiBoR @xai Yes
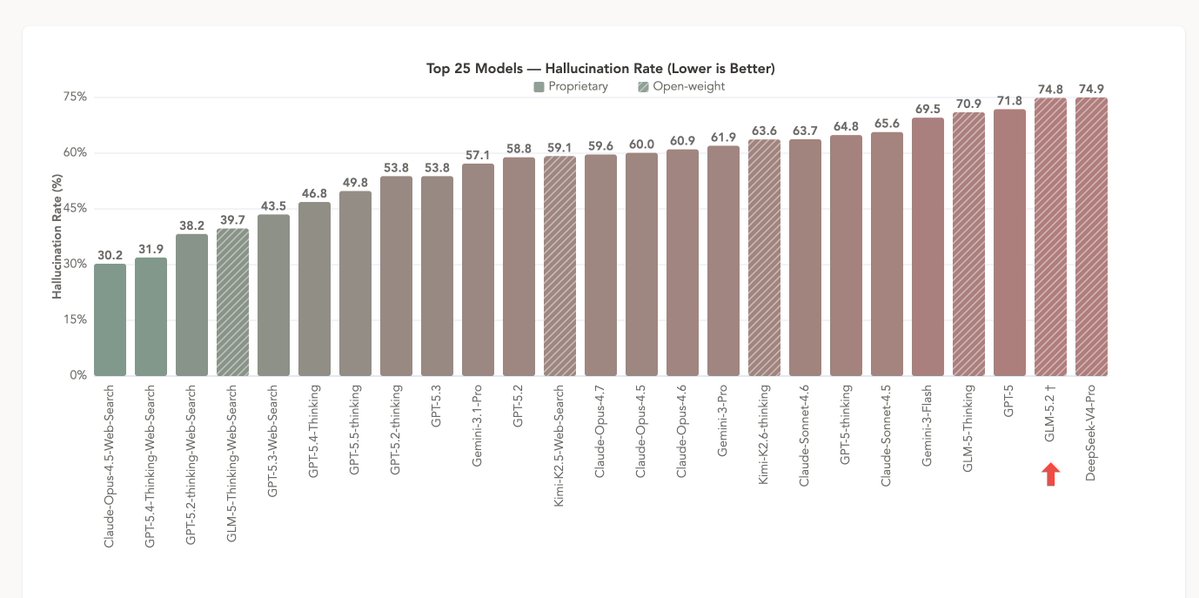
HalluHard update: We’ve added GLM-5.2, using adaptive thinking with maximum reasoning effort, to our leaderboard. Despite its impressive performance on other benchmarks, GLM-5.2 still hallucinates frequently on our challenging multiturn benchmark. https://t.co/xbppFeo7Pd
A lot of people talk about AI's impact on jobs. Oracle just put some numbers behind that discussion, cutting 21,000 roles while accelerating its AI push. The transition from AI experimentation to AI implementation is well underway. https://t.co/45VKOcl5RI

https://t.co/dHeVhIcLe5

https://t.co/6eqLRsyvV3 @itsjessyin project!

https://t.co/6eqLRsyvV3 @itsjessyin project!
