@omarsar0
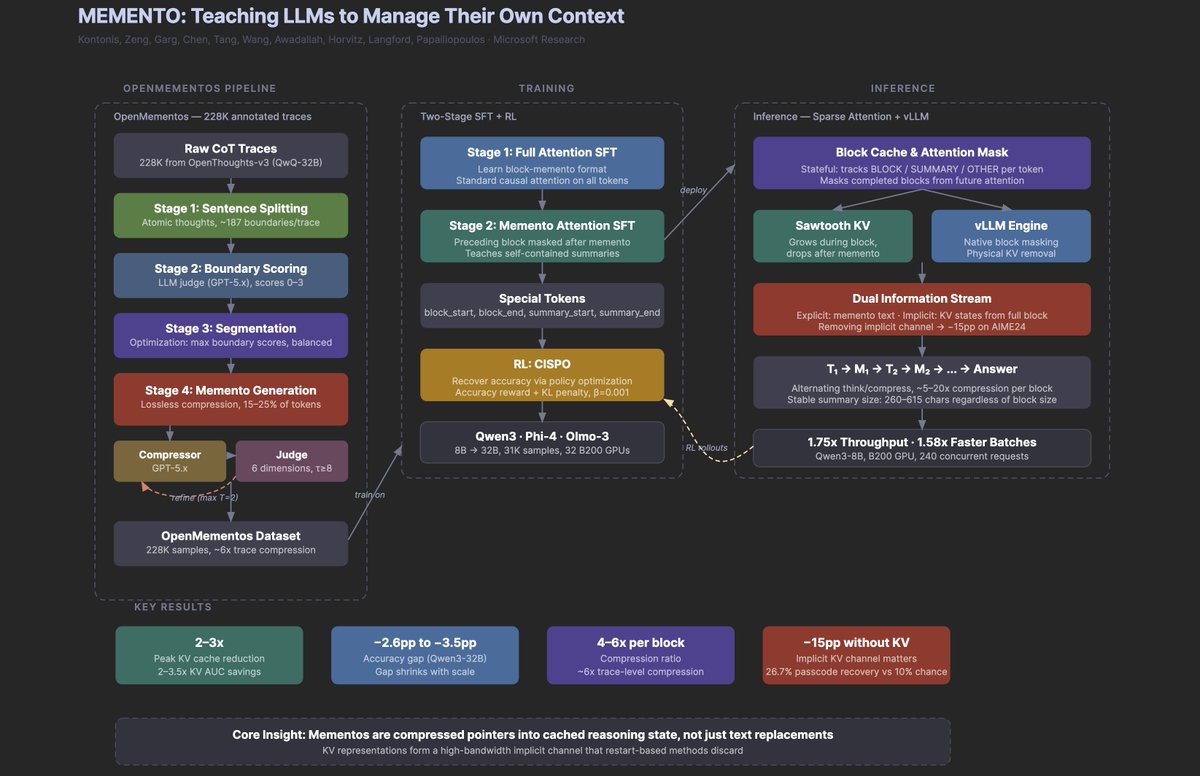
Another banger paper from Microsoft. Why it's a big deal: It teaches reasoning models to compress their own chain-of-thought mid-generation. The most interesting finding isn't the 2-3x memory savings or the doubled throughput. It's that when the model erases a reasoning block after summarizing it, the deleted information keeps leaking forward through the KV cache representations, forming an implicit second channel that accounts for 15 pp of accuracy. The model is, in some meaningful sense, remembering things it can no longer see. If context management turns out to be a teachable skill (and 30K training examples seem to be enough), then the bottleneck for long-horizon agents may be less about architecture and more about the right training data, which is a very different kind of problem than most people are working on. If it helps, below is my research agent's visual summary of the paper (at least highlighting the key parts).