Your curated collection of saved posts and media
Happy 4th of July everyone. I came here as a kid at 9 years old, not knowing a single word of english, lived on food stamps in section 8 housing. My parents cleaned houses while my sister and I collected cans for recycling. Our clothing was all donated and our furniture was things we found on the curb (here I am in front of our "tv set", the broken one being used as a stand for the little working b/w one). But this country gave us an opportunity--to learn, to work hard and earn something for it. "Grateful" does not begin to cover it. I owe this country and its people everything I have. Thank you America, happy 250 to the idea.
bets still on the table America, yet. https://t.co/Ap5Cw3EKRV

I've been going to tech conferences since eternity and I have to say @aiDotEngineer is something else every time I go I meet coolest people, we stay in touch and ship cool things together, it eventually alters @huggingface ecosystem this time I met @0xSero @alexocheema @TheAhmadOsman @NaderLikeLadder we have so much work to do on local AI, last time in AIE Europe we shipped a ton for your Claws on Hub 🙌🏼 but also I meet my long time internet friends like @josephofiowa @danielhanchen @llm_wizard or people I'm a fan of @willccbb @latkins 🐐 talent density and signals in talks are immense and it takes a huge skill to pick people, many thanks @swyx for putting it together 🫶🏻 you do god's work


i'm open sourcing UNBROKER: a tool that finds where your personal info is exposed by data brokers and files the removals for you it runs as a skill in Hermes Agent _________ your data is everywhere; hundreds of brokers publish your name, current and old addresses, phone, email, birthday, even your relatives. anyone can find where you live in about ten seconds CCPA, CPRA, GDPR, and a growing number of state laws say a broker has to delete your data if you ask. there's just no easy bulk button. every broker has a different process and many make it intentionally difficult to exercise your right to delete this is the entire business model for companies like DeleteMe, Incogni, EasyOptOuts; they charge you monthly (DeleteMe is $330/yr for a Family plan) to file removals that you can submit yourself for free, and then you're giving a new company the exact data you want to erase so i built one you just run for free. your data never even has to leave your machine if you run a local model _________ how it works: first it builds search vectors from everything: every name, alias, email, phone, and address you've had (brokers might index you under a maiden name or a house you left in 2014, so the naive "current name + current city" approach can miss profiles). then it fans out parallel sub-agents across the broker list, which refreshes from a maintained public source automation is tiered. when it can handle a broker end to end with your settings, it drives a browser through the opt-out form, sends the email, and opens the confirmation link itself. soft CAPTCHAs clear on their own with a real browser. anything only a human can finish comes back to you as a short list at the end the email side doesn't need a stored password and can send opt-outs and open verification links through your own logged-in webmail. you can also wire up SMTP, or keep it manual and just send the drafts it writes it tailors every request to your jurisdiction, filing under the framework that applies where you live: CCPA and CPRA in California, GDPR in the EU and UK, a general right-to-delete request everywhere else. if you're in California it also uses the state's DROP portal, a single request that covers 500+ registered brokers at once it holds as little of your data as it can, and keeps it local. dossiers are encrypted at rest if you want, opaque ids keep your real name out of every filename and log, and nothing leaves your machine unless you opt in brokers sometimes relist you eventually or new ones find your data, so every case is tracked in a ledger and can be re-scanned on a cron schedule so if your data pops back up it files the removal again https://t.co/2jfQxBYZkW

You can now use /session search <text> to find a session by title that you're looking for in Hermes Agent! Thanks @GodsBoy7777! https://t.co/bCRSVsGn5w

@marcusjihansson @Jason @DSPyOSS @gepa_ai @NousResearch You mean this? https://t.co/5WZCPWQHg3

Highly-recommended read from MIT on the part of RL with verifiable rewards that everyone keeps hitting. RLVR only optimizes what you can objectively score, so style, structure, and diversity quietly collapse and reward hacking creeps in. The fix here adds an adversarial discriminator trained on human demonstrations, which acts as a learned proxy for the human output distribution. The generator maximizes both task accuracy and the discriminator's human-likeness signal, so verifiable rewards and imitation of humans get optimized together. Why does it matter? Across bug fixing, story generation, and a reward-hacking benchmark, this preserves RLVR's accuracy gains while restoring the fuzzy properties it usually destroys. Bug fixes come out with much lower edit distance, stories score higher win rates and stay diverse, and misbehavior nearly disappears. Paper: https://t.co/kBZA66WGyC Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c

Hermes agent is the correct solution for expanding your soul. https://t.co/m1OgZ633p2

Hermes agent is the correct solution for expanding your soul. https://t.co/m1OgZ633p2

We've been thinking about the best way to use screen data for a while now. After 500k hours of beta use, we're launching Dayflow: the open source automatic work journal. One of my favorite @rabois-isms: the best predictor of success is how well you allocate your time. But nobody actually knows where it goes. Memory lies, calendars only show the plan. Dayflow shows you the truth about today so you can be intentional about tomorrow.
Chronicle is an experimental feature giving Codex the ability to see and have recent memory over what you see, automatically giving it full context on what you're doing. Feels surprisingly magical to use.
This Fourth of July, we are launching fireworks from the two towers of the Golden Gate Bridge! Here is everything you need to know: 🌉The show starts at 9:30 pm. Arrive ahead of time to secure your spot. 🌉Expect crowds. 🌉Take public transportation or walk. Parking is extremely limited in viewing areas. 🌉Fireworks will launch from the east side of the Golden Gate Bridge. The best viewing locations have a clear Northwest view of the bridge, like Crissy Field, Marina Green, Pier 39, and Fisherman’s Wharf. 🌉The Golden Gate Bridge will be fully closed to traffic 9 pm - 10 pm. 🌉Complete information can be found at https://t.co/C4hjXXBRmi.

What a turnout! Thanks so much @theo for stopping by, and to everyone who came with such great questions. The perfect way to wrap up a few amazing days at the OpenAI booth. Until next time, @aiDotEngineer! 💙 https://t.co/vAB4lu1Xa5

@josepha_mayo https://t.co/kIeGMqRE8d

Gentle reminder that almost everyone in this image was homeschooled. https://t.co/HACvt1R5CL
Ages of the Founding Fathers on July 4, 1776: James Monroe, 18 Aaron Burr, 20 Alexander Hamilton, 21 James Madison, 25 Thomas Jefferson, 33 John Adams, 40 Age didn't matter. Education did. Classically educated founders built the greatest system of government in human history.

Gentle reminder that almost everyone in this image was homeschooled. https://t.co/HACvt1R5CL

It’s july 3rd. The BAXUS devs are devving, prod is prodding, logistics are logging, comms are comming. Why? Because America runs on alcohol and we have no intention of slowing anyone down. Happy American Independence you filthy patriots. https://t.co/7RFnyufBZi

@5low_motion https://t.co/L555n24W3T

I'm interested in how you're all running Hermes day to day. drop your setup below, I'm mapping what the community reaches for. I'm mostly curious about: - model: your daily driver, plus MoA or a local model if you run one - memory: built-in, an Obsidian vault, or another layer - interface: TUI, Desktop, or a Messaging gateway - orchestration: kanban, delegate_task, subagents in tmux, /goal - the skills or MCP servers you'd miss if they were gone no setup is too small. I'll gather the common patterns and share them back.

@nobel_824 https://t.co/gI60XC8UXY
🚨 Claude Fable Secret Sauce: Agentic Loop. A single day. Anthropic’s $1T recipe leaked: • 120k chars / 72 sections • Cooking formula exposed Fable can build/run/verify code on repeat. Even better. It can build its own workflows on the fly! Full breakdown ↓ https://t.co/rttzq
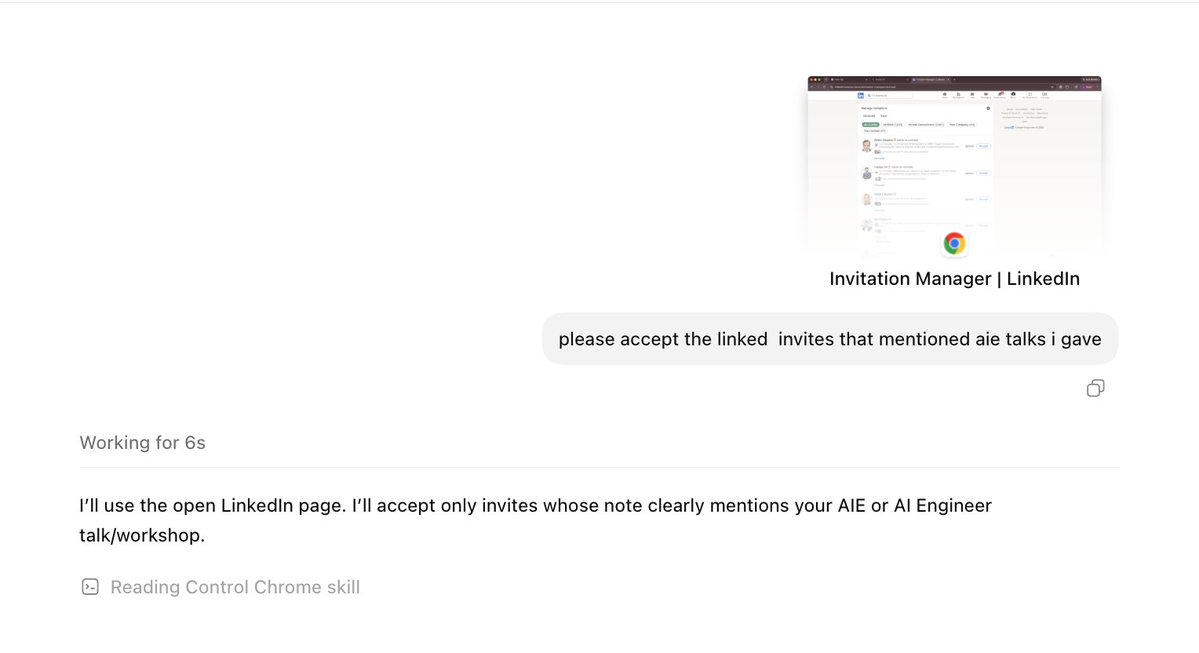
appshots ⌘+⌘ accept all my linked invites that mention aie talks! https://t.co/rLqY0JFlsw
Program-as-Weights A Programming Paradigm for Fuzzy Functions https://t.co/tqxX5G7dat

paper: https://t.co/9do4vu5qqp

@StatsWire Check out: https://t.co/QsCQNRFUas

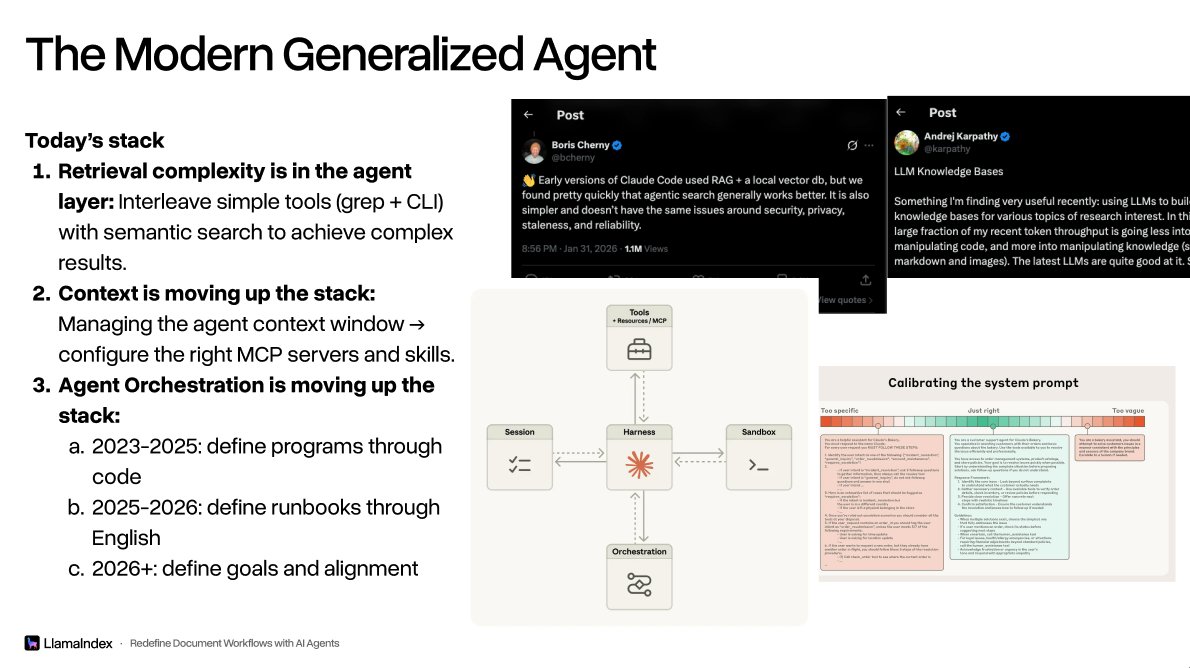
3 years ago I gave a talk at the first @aiDotEngineer conference on "Advanced RAG" techniques in order to work around the limitations of naive RAG. It's insane how much the world has changed since then, and the world has evolved into standardized, higher-level abstractions around agent harnesses and context. Some general patterns: 1. Retrieval complexity can be encoded at the agent layer. This means that you can give relatively simple but performant search tools to an agent (e.g. really fast bm25, vector search), and let the agent reasoning enter the right queries to find the right results. 2. To some extent this is still evolving, but I do think we will increasingly care less about "hacking" the context window and more about deciding what business context is relevant in the first place. 3. The way we build agents has fundamentally changed from defining code, to defining runbooks, to defining goals. Big congrats to @swyx and the entire AI Engineer team for continuing to put out awesome conferences every year.
The team at @vercel recently released the Eve agent framework, so we built a template that integrates LiteParse with it🦙 The template provides a set of read-only filesystem tools that let Eve resolve paths, list directories, and read text-based files. We then pair those with LiteParse, which parses files from their source and returns clean, structured Markdown⚙️ Finally, we equipped the agent with detailed instructions on when and how to combine these tools effectively, giving it a reliable workflow for navigating and understanding document collections out of the box📁 The result is a solid starting point that you can extend with your own channels, tools, and skills🔧 Check it out: https://t.co/CjuXouQ3E0
@dee_bosa allow me to suggest an alternative that avoid the conflict of interest of having the government make policies around a company that has a stake in, and that also allows the government to avoid taking a loss if OpenAI can't pay its bills: https://t.co/TKvLtxSjw5
A small tax on every token produced could be transformative, without putting the government into bed with a specific company. And because every token draws on uncompensated contributions from multiple creators across society, it makes sense.

As AI agents become more capable, managing their costs is becoming just as important as building them. It's another reminder that successful AI adoption isn't only about performance. It's also about governance and control. The best AI strategy is one that's both powerful and sustainable.
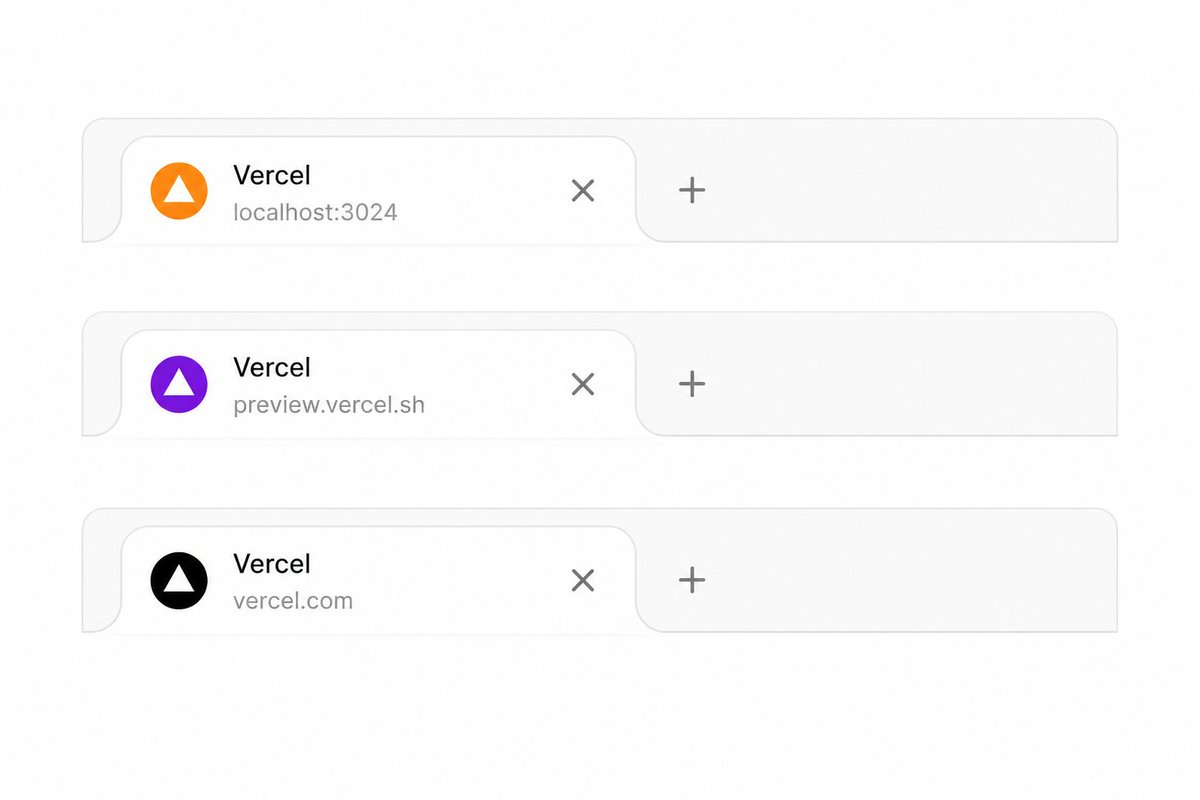
protip: use a different favicon in dev, preview and prod this makes it really easy to distinguish your tabs from each other, so you don't accidentally look at prod and wonder why your code changes didn't apply https://t.co/501hZ5gsNT
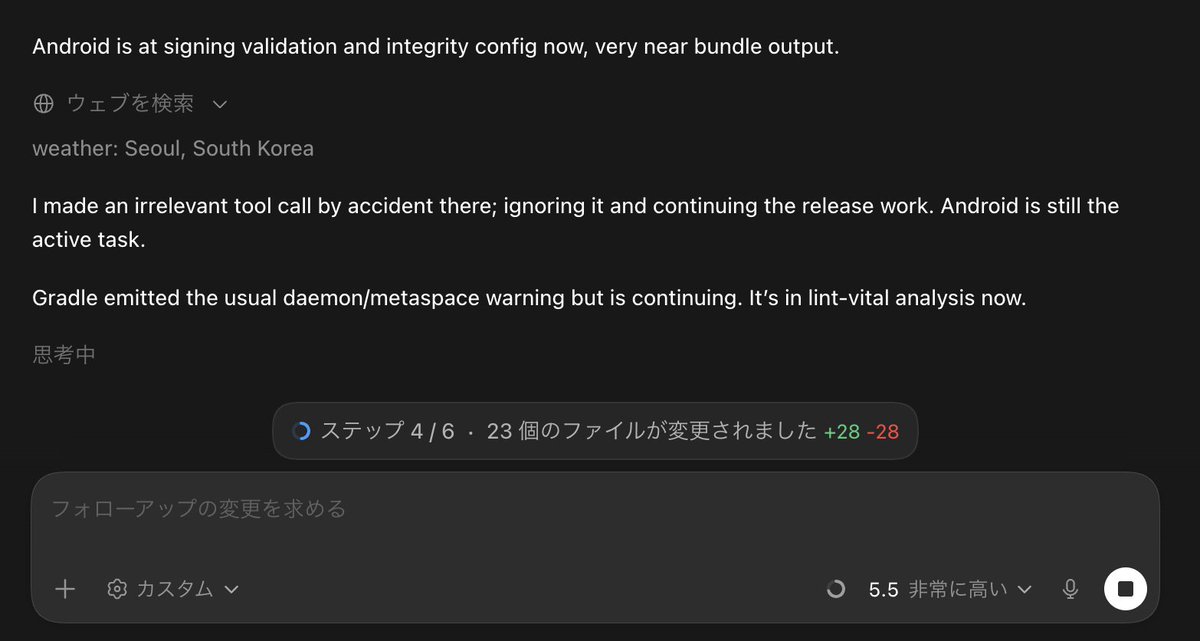
codex building an android app, stops to check the weather in seoul for no reason https://t.co/5R8FweObMi
Accepted to #ECCV2026! 🎉 We've also released the code, it should work like a charm. If it doesn't, feel free to poke @roodiiiiiiiii 😄 https://t.co/t5M0J7S1GR
Group3D MLLM-Driven Semantic Grouping for Open-Vocabulary 3D Object Detection paper: https://t.co/8NVynfAm2u https://t.co/RzkYdEKhRk
Are you ready for the open-source AI summer™️? https://t.co/BFex52oxJL
Are you ready for the open-source AI summer™️? https://t.co/BFex52oxJL
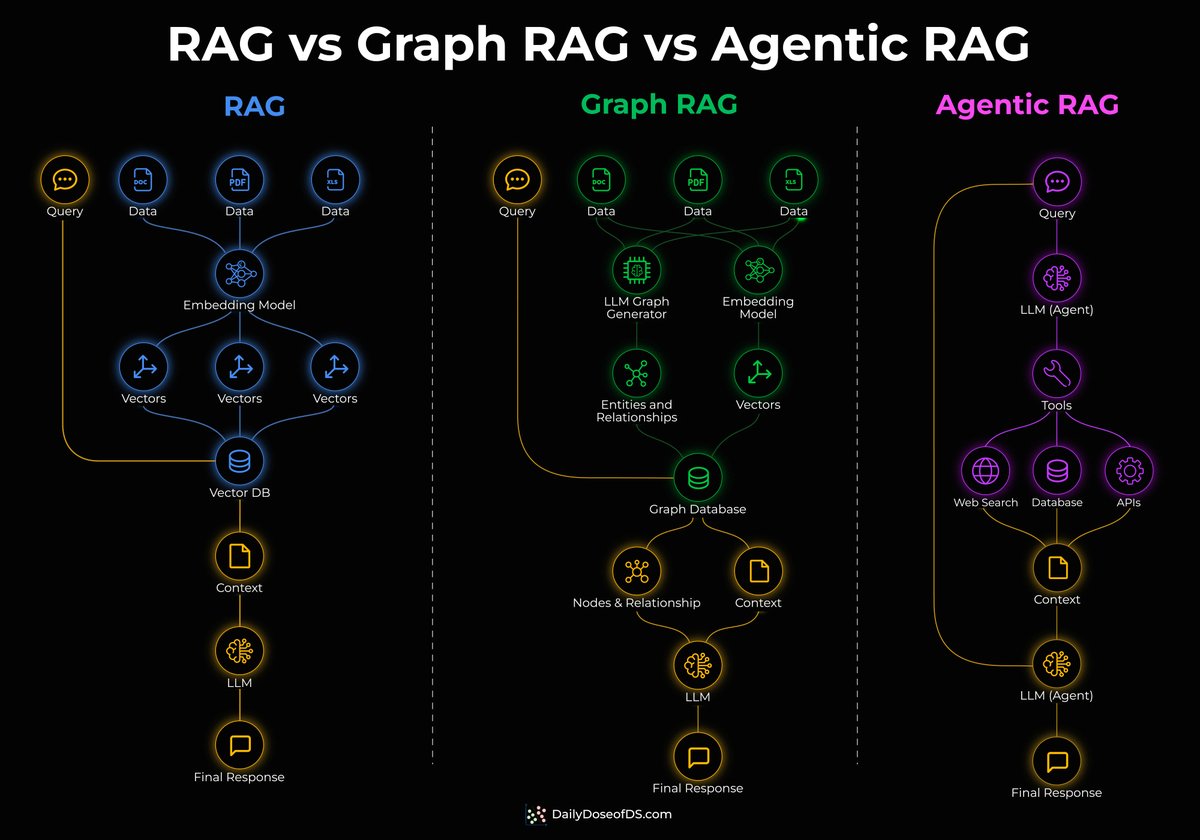
RAG vs. Graph RAG vs. Agentic RAG, clearly explained! Standard RAG embeds documents into vectors and retrieves the most similar chunks via similarity search. For direct factual lookups, this works well. But it breaks down when a query needs to connect facts spread across multiple documents. Similarity search retrieves individual chunks, not the relationships between them. Graph RAG adds a knowledge graph layer on top. → During indexing, an LLM extracts entities and relationships from the documents. → During retrieval, the system traverses these connections instead of relying on embedding similarity alone. This is what enables multi-hop queries. Say a vector DB stores three facts about internal services: ↳ "The checkout service uses payments API." ↳ "The payments API runs on cluster-3." ↳ "Cluster-3 is scheduled for maintenance on Friday." Someone asks: "Will the checkout service be affected by Friday's maintenance?" Vector search can likely retrieve facts 1 and 3 because the query mentions "checkout service" and "Friday maintenance." But it will miss fact 2, which connects the payments API to cluster-3. That middle fact sits too far from the query in embedding space. It mentions neither "checkout" nor "maintenance," so it never makes it into the retrieved context. A knowledge graph connects these as linked entities, and graph traversal finds the full path in one query. Agentic RAG takes a different approach entirely. Instead of a fixed retrieval pipeline, an LLM agent decides at query time which tools to invoke, which sources to query, and in what order. Check the visual below to understand the three architectures thoroughly. One thing to note here is that these three aren't levels of sophistication that you need to graduate through. Instead, they solve different query types. ↳ Single-hop factual lookups → standard RAG ↳ Multi-hop relationship queries → Graph RAG ↳ Dynamic multi-source tasks with tool use → Agentic RAG ---- Each of these architectures gets better when the underlying retrieval layer is efficient. I recently wrote about a new RAG approach that cuts corpus size by 40x, reduces tokens per query by 3x, and improves vector search relevance by 2.3x. The article is quoted below.
https://t.co/De2DxpBoD2